

Java基础补缺2
1)多线程调度:
每个对象都可以调用 Object 的 wait/notify 方法来实现等待/通知机制。
public class WaitNotifyDemo {
public static void main(String[] args) {
Object lock = new Object();
new Thread(() -> {
synchronized (lock) {
System.out.println("线程1:我要等待");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1:我被唤醒了");
}
}).start();
new Thread(() -> {
synchronized (lock) {
System.out.println("线程2:我要唤醒");
lock.notify();
System.out.println("线程2:我已经唤醒了");
}
}).start();
}
}
在大多数情况下,由于线程1先被启动,它会先获得锁。以下是详细的执行序列:
- 主线程启动:
- •主线程创建了一个共享对象
lock作为监视器锁。 - •主线程启动线程1。线程1进入
Runnable状态,等待CPU调度。 - •主线程立即启动线程2。线程2也进入
Runnable状态。
- •主线程创建了一个共享对象
- 线程1获得锁并进入等待:
- •线程1获得CPU时间片,并成功获取
lock上的同步锁,进入synchronized代码块。 - •线程1打印:
"线程1:我要等待"。 - •线程1执行
lock.wait()。这个方法调用会导致以下关键操作:- •线程1释放其持有的
lock锁。 - •线程1的状态由
RUNNABLE变为WAITING,并被放入与lock对象关联的等待队列中。
- •线程1释放其持有的
- •此时,
lock的锁被释放,其他线程可以竞争它。
- •线程1获得CPU时间片,并成功获取
- 线程2获得锁并发出通知:线程1被唤醒并继续执行:
- •线程2获得CPU时间片,并成功获取到已空闲的
lock锁,进入其synchronized代码块。 - •线程2打印:
"线程2:我要唤醒"。 - •线程2执行
lock.notify()。这个方法调用会引发以下操作:- •JVM将线程1从
lock的等待队列移送到同步队列(或锁的阻塞队列)。线程1的状态由WAITING变为BLOCKED,因为它现在需要重新竞争锁才能继续执行。 - •请注意:
notify()调用本身并不会释放锁,线程2会继续持有锁并执行后续代码。
- •JVM将线程1从
- •线程2打印:
"线程2:我已经唤醒了"。 - •线程2执行到其
synchronized代码块的结束处},这时它会释放lock锁。
- •线程2获得CPU时间片,并成功获取到已空闲的
- •
lock锁被释放后,在同步队列中等待的线程1开始尝试重新获取该锁。 - •线程1成功获取锁后,从其
wait()方法处恢复执行。 - •线程1打印:
"线程1:我被唤醒了"。 - •线程1执行到其
synchronized代码块的结束处},释放锁。程序随后结束。
线程1:我要等待
线程2:我要唤醒
线程2:我已经唤醒了
线程1:我被唤醒了
潜在风险:竞态条件(Race Condition)
这段代码存在一个典型的竞态条件问题。如果线程调度器让线程2先于线程1执行,将会发生以下情况:
- 线程2先获得
lock锁。 - 线程2调用
lock.notify()。但此时,线程1尚未执行到wait()方法,即等待队列是空的。因此,这次notify()调用相当于一次空操作,没有任何线程会被唤醒。 - 线程2执行完毕,释放锁。
- 之后,线程1获得锁,执行
lock.wait()并进入等待状态。 - 由于已经没有任何其他线程会再次调用
lock.notify(),线程1将永远等待下去,程序无法正常终止。
2)Java包
Java 定义了一种名字空间,称之为包:package。一个类总是属于某个包,类名(比如Person)只是一个简写,真正的完整类名是包名.类名。
在 Java 虚拟机执行的时候,JVM 只看完整类名,因此,只要包名不同,类就不同。
要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系。
在写import的时候,可以使用*,表示把这个包下面的所有class都导入进来(但不包括子包的class)。我们一般不推荐这种写法,因为在导入了多个包后,很难看出Arrays类属于哪个包。
还有一种import static的语法,它可以导入一个类的静态字段和静态方法。import static很少使用。
package main;
// 导入System类的所有静态字段和静态方法:
import static java.lang.System.*;
public class Main {
public static void main(String[] args) {
// 相当于调用System.out.println(…)
out.println("Hello, world!");
}
}
Java 编译器最终编译出的.class文件只使用 完整类名,因此,在代码中,当编译器遇到一个class名称时:
- 如果是完整类名,就直接根据完整类名查找这个
class; - 如果是简单类名,按下面的顺序依次查找:
- 查找当前
package是否存在这个class; - 查找
import的包是否包含这个class; - 查找
java.lang包是否包含这个class。
- 查找当前
如果按照上面的规则还无法确定类名,则编译报错。
编写 class 的时候,编译器会自动帮我们做两个 import 动作:
- 默认自动
import当前package的其他class; - 默认自动
import java.lang.*。
注意:自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入。
如果有两个class名称相同,例如,mr.jun.Arrays和java.util.Arrays,那么只能import其中一个,另一个必须写完整类名。
3)可变参数
可变参数是 Java 1.5 的时候引入的功能,它允许方法使用任意多个、类型相同(is-a)的值作为参数。
public static void print(String... strs) {
for (String s : strs)
System.out.print(s);
System.out.println();
}
阿里巴巴开发手册一条规约,尽量不要使用可变参数,如果要用的话,可变参数必须要在参数列表的最后一位
当使用可变参数的时候,实际上是先创建了一个数组,该数组的大小就是可变参数的个数,然后将参数放入数组当中,再将数组传递给被调用的方法。
public static void main(String[] args) {
print(new String[]{"沉"});
print(new String[]{"沉", "默"});
print(new String[]{"沉", "默", "王"});
print(new String[]{"沉", "默", "王", "二"});
}
public static void print(String... strs) {
for (String s : strs)
System.out.print(s);
System.out.println();
}
当一个方法需要处理任意多个相同类型的对象时,就可以定义可变参数。Java 中有一个很好的例子,就是 String 类的 format() 方法
%d 表示将整数格式化为 10 进制整数,%s 表示输出字符串。
System.out.println(String.format("年纪是: %d", 18));
System.out.println(String.format("年纪是: %d 名字是: %s", 18, "沉默王二"));
要避免重载带有可变参数的方法——这样很容易让编译器陷入自我怀疑中
4)构造方法
构造方法不能是抽象的(abstract)、静态的(static)、最终的(final)、同步的(synchronized)。多个线程不会同时创建内存地址相同的同一个对象,所以用 synchronized 关键字修饰没有必要。
如果用 void 声明构造方法的话,编译时不会报错,但 Java 会把这个所谓的“构造方法”当成普通方法来处理。
构造方法的调用是隐式的,通过编译器完成。如果没有明确提供无参构造方法,编译器会提供。而普通方法任何情况下都不由编译器提供。
复制对象有几种方法
4.1)通过构造函数
public class CopyConstrutorPerson {
private String name;
private int age;
public CopyConstrutorPerson(CopyConstrutorPerson person) {
this.name = person.name;
this.age = person.age;
}
public static void main(String[] args) {
CopyConstrutorPerson p1 = new CopyConstrutorPerson("沉默王二",18);
p1.out();
CopyConstrutorPerson p2 = new CopyConstrutorPerson(p1);
p2.out();
}
}
4.2)通过Object类的clone()方法
public class ClonePerson implements Cloneable {
private String name;
private int age;
public ClonePerson(String name, int age) {
this.name = name;
this.age = age;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public void out() {
System.out.println("姓名 " + name + " 年龄 " + age);
}
public static void main(String[] args) throws CloneNotSupportedException {
ClonePerson p1 = new ClonePerson("沉默王二",18);
p1.out();
ClonePerson p2 = (ClonePerson) p1.clone();
p2.out();
}
}
通过 clone() 方法复制对象的时候,ClonePerson 必须先实现 Cloneable 接口的 clone() 方法,然后再调用 clone() 方法(ClonePerson p2 = (ClonePerson) p1.clone())。
5)初始代码块
public class Car {
Car() {
System.out.println("构造方法");
}
{
System.out.println("代码初始化块");
}
public static void main(String[] args) {
new Car();
}
}
等价于
public class Car {
Car() {
{
System.out.println("代码初始化块");
}
System.out.println("构造方法");
}
}
结果
代码初始化块
构造方法
- 类实例化的时候执行代码初始化块;
- 实际上,代码初始化块是放在构造方法中执行的,只不过比较靠前;
- 代码初始化块里的执行顺序是从前到后的。
在默认情况下,子类的构造方法在执行的时候会主动去调用父类的构造方法。
public class Example {
// 静态变量
public static int staticVar = 1;
// 实例变量
public int instanceVar = 2;
// 静态初始化块
static {
System.out.println("执行静态初始化块");
staticVar = 3;
}
// 实例初始化块
{
System.out.println("执行实例初始化块");
instanceVar = 4;
}
// 构造方法
public Example() {
System.out.println("执行构造方法");
}
public static void main(String[] args) {
System.out.println("执行main方法");
Example e1 = new Example();
Example e2 = new Example();
System.out.println("e1的静态变量:" + e1.staticVar);
System.out.println("e1的实例变量:" + e1.instanceVar);
System.out.println("e2的静态变量:" + e2.staticVar);
System.out.println("e2的实例变量:" + e2.instanceVar);
}
}
结果
执行静态初始化块 执行main方法 执行实例初始化块 执行构造方法 执行实例初始化块 执行构造方法 e1的静态变量:3 e1的实例变量:4 e2的静态变量:3 e2的实例变量:4
静态初始化块在类加载时执行,只会执行一次,并且优先于实例初始化块和构造方法的执行;
实例初始化块在每次创建对象时执行,在构造方法之前执行。
6)抽象类
抽象类是不能实例化的
抽象类中既可以定义抽象方法,也可以定义普通方法
假设现在有一个文件,里面的内容非常简单,只有一个“Hello World”,现在需要有一个读取器将内容从文件中读取出来,最好能按照大写的方式,或者小写的方式来读。
/**
* 抽象类,定义了一个读取文件的基础框架,其中 mapFileLine 是一个抽象方法,具体实现需要由子类来完成
*/
abstract class BaseFileReader {
protected Path filePath; // 定义一个 protected 的 Path 对象,表示读取的文件路径
/**
* 构造方法,传入读取的文件路径
* @param filePath 读取的文件路径
*/
protected BaseFileReader(Path filePath) {
this.filePath = filePath;
}
/**
* 读取文件的方法,返回一个字符串列表
* @return 字符串列表,表示文件的内容
* @throws IOException 如果文件读取出错,抛出该异常
*/
public List<String> readFile() throws IOException {
return Files.lines(filePath) // 使用 Files 类的 lines 方法,读取文件的每一行
.map(this::mapFileLine) // 对每一行应用 mapFileLine 方法,将其转化为指定的格式
.collect(Collectors.toList()); // 将处理后的每一行收集到一个字符串列表中,返回
}
/**
* 抽象方法,子类需要实现该方法,将文件中的每一行转化为指定的格式
* @param line 文件中的每一行
* @return 转化后的字符串
*/
protected abstract String mapFileLine(String line);
}
-
filePath 为文件路径,使用 protected 修饰,表明该成员变量可以在需要时被子类访问到。
-
readFile()方法用来读取文件,方法体里面调用了抽象方法mapFileLine()——需要子类来扩展实现大小写的不同读取方式。
BaseFileReader 类设计的就非常合理,并且易于扩展,子类只需要专注于具体的大小写实现方式就可以了。
小写方式
class LowercaseFileReader extends BaseFileReader {
protected LowercaseFileReader(Path filePath) {
super(filePath);
}
@Override
protected String mapFileLine(String line) {
return line.toLowerCase();
}
}
大写方式
class UppercaseFileReader extends BaseFileReader {
protected UppercaseFileReader(Path filePath) {
super(filePath);
}
@Override
protected String mapFileLine(String line) {
return line.toUpperCase();
}
}
从文件里面一行一行读取内容的代码被子类复用了。与此同时,子类只需要专注于自己该做的工作,LowercaseFileReader 以小写的方式读取文件内容,UppercaseFileReader 以大写的方式读取文件内容。
public class FileReaderTest {
public static void main(String[] args) throws URISyntaxException, IOException {
URL location = FileReaderTest.class.getClassLoader().getResource("helloworld.txt");
Path path = Paths.get(location.toURI());
BaseFileReader lowercaseFileReader = new LowercaseFileReader(path);
BaseFileReader uppercaseFileReader = new UppercaseFileReader(path);
System.out.println(lowercaseFileReader.readFile());
System.out.println(uppercaseFileReader.readFile());
}
}
在 resource 目录下的文件可以通过 ClassLoader.getResource() 的方式获取到 URI 路径,然后就可以取到文本内容了。
输出结果如下所示:
[hello world]
[HELLO WORLD]
7)接口
7.1)接口特性
接口中定义的变量会在编译的时候自动加上 public static final 修饰符。接口的本意是对方法进行抽象,而常量接口会对子类中的变量造成命名空间上的“污染”
没有使用 private、default 或者 static 关键字修饰的方法是隐式抽象的
从 Java 8 开始,接口中允许有静态方法,静态方法无法由(实现了该接口的)类的对象调用,它只能通过接口名来调用
接口中允许定义 default 方法也是从 Java 8 开始的,比如说上例中的 printDescription() 方法,它始终由一个代码块组成,为实现该接口而不覆盖该方法的类提供默认实现。既然要提供默认实现,就要有方法体,换句话说,默认方法后面不能直接使用“;”号来结束——编译器会报错
“为什么要在接口中定义默认方法呢?”
允许在接口中定义默认方法的理由很充分,因为一个接口可能有多个实现类,这些类就必须实现接口中定义的抽象类,否则编译器就会报错。假如我们需要在所有的实现类中追加某个具体的方法,在没有 default 方法的帮助下,我们就必须挨个对实现类进行修改。
接口不允许直接实例化,否则编译器会报错。
接口可以是空的,既可以不定义变量,也可以不定义方法。
不要在定义接口的时候使用 final 关键字,否则会报编译错误
接口的抽象方法不能是 private、protected 或者 final,否则编译器都会报错。
7.2)多态
多态可以通过继承(extends)的关系实现,也可以通过接口的形式实现。
多态存在的 3 个前提:
- 1、要有继承关系,比如都实现了接口。
- 2、子类要重写父类的方法
- 3、父类引用指向子类对象,circleShape 和 squareShape 的类型都为 Shape,但前者指向的是 Circle 对象,后者指向的是 Square 对象。
也就意味着,尽管在 for 循环中,shape 的类型都为 Shape,但在调用 name() 方法的时候,它知道 Circle 对象应该调用 Circle 类的 name() 方法,Square 对象应该调用 Square 类的 name() 方法。
7.3)接口三种模式
7.3.1)策略模式
策略模式的思想是,针对一组算法,将每一种算法封装到具有共同接口的实现类中,接口的设计者可以在不影响调用者的情况下对算法做出改变。
// 接口:教练
interface Coach {
// 方法:防守
void defend();
}
// 何塞·穆里尼奥
class Hesai implements Coach {
@Override
public void defend() {
System.out.println("防守赢得冠军");
}
}
// 德普·瓜迪奥拉
class Guatu implements Coach {
@Override
public void defend() {
System.out.println("进攻就是最好的防守");
}
}
public class Demo {
// 参数为接口
public static void defend(Coach coach) {
coach.defend();
}
public static void main(String[] args) {
// 为同一个方法传递不同的对象
defend(new Hesai());
defend(new Guatu());
}
}
7.3.2)适配器模式
适配器模式的思想是,针对调用者的需求对原有的接口进行转接。
interface Coach {
void defend();
void attack();
}
// 抽象类实现接口,并置空方法
abstract class AdapterCoach implements Coach {
public void defend() {};
public void attack() {};
}
// 新类继承适配器
class Hesai extends AdapterCoach {
public void defend() {
System.out.println("防守赢得冠军");
}
}
public class Demo {
public static void main(String[] args) {
Coach coach = new Hesai();
coach.defend();
}
}
Coach 接口中定义了两个方法(defend() 和 attack()),如果类直接实现该接口的话,就需要对两个方法进行实现。
如果我们只需要对其中一个方法进行实现的话,就可以使用一个抽象类作为中间件,即适配器(AdapterCoach),用这个抽象类实现接口,并对抽象类中的方法置空(方法体只有一对花括号),这时候,新类就可以绕过接口,继承抽象类,我们就可以只对需要的方法进行覆盖,而不是接口中的所有方法。
7.3.3)工厂模式
// 教练
interface Coach {
void command();
}
// 教练学院
interface CoachFactory {
Coach createCoach();
}
// A级教练
class ACoach implements Coach {
@Override
public void command() {
System.out.println("我是A级证书教练");
}
}
// A级教练学院
class ACoachFactory implements CoachFactory {
@Override
public Coach createCoach() {
return new ACoach();
}
}
// C级教练
class CCoach implements Coach {
@Override
public void command() {
System.out.println("我是C级证书教练");
}
}
// C级教练学院
class CCoachFactory implements CoachFactory {
@Override
public Coach createCoach() {
return new CCoach();
}
}
public class Demo {
public static void create(CoachFactory factory) {
factory.createCoach().command();
}
public static void main(String[] args) {
// 对于一支球队来说,需要什么样的教练就去找什么样的学院
// 学院会介绍球队对应水平的教练。
create(new ACoachFactory());
create(new CCoachFactory());
}
}
有两个接口,一个是 Coach(教练),可以 command()(指挥球队);另外一个是 CoachFactory(教练学院),能 createCoach()(教出一名优秀的教练)。然后 ACoach 类实现 Coach 接口,ACoachFactory 类实现 CoachFactory 接口;CCoach 类实现 Coach 接口,CCoachFactory 类实现 CoachFactory 接口。当需要 A 级教练时,就去找 A 级教练学院;当需要 C 级教练时,就去找 C 级教练学院。
8)抽象类和接口的区别
接口与抽象类的不同之处在于:
- 1、抽象类可以有方法体的方法,但接口没有(Java 8 以前)。
- 2、接口中的成员变量隐式为
static final,但抽象类不是的。 - 3、一个类可以实现多个接口,但只能继承一个抽象类。
- 4、接口是隐式抽象的,所以声明时没有必要使用
abstract关键字; - 5、接口的每个方法都是隐式抽象的,所以同样不需要使用
abstract关键字; - 6、接口中的方法都是隐式
public的。
抽象类是对一种事物的抽象,即对类抽象,继承抽象类的子类和抽象类本身是一种 is-a 的关系。而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类 Airplane,将鸟设计为一个类 Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。
此时可以将 飞行 设计为一个接口 Fly,包含方法 fly(),然后 Airplane 和 Bird 分别根据自己的需要实现 Fly 这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承 Airplane 即可,对于鸟也是类似的,不同种类的鸟直接继承 Bird 类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
在实际开发中,你可以根据以下核心原则来决定使用抽象类还是接口:
- 优先考虑使用接口:当你的主要目的是定义行为契约,而不关心具体实现细节时。这尤其适用于需要多重继承的场景,或者希望实现组件解耦,提高系统灵活性和可扩展性时。面向接口编程而非实现,是重要的设计原则。
- 选择抽象类的情况:当你在多个紧密相关的类之间发现共享的代码逻辑或状态(成员变量) 时。抽象类非常适合用于定义算法的骨架(如模板方法模式),将不变的部分封装在抽象类中,让子类去实现可变的部分。
🌟 进阶应用:结合使用与设计模式
在实际项目中,接口和抽象类并非互斥,而是可以协同工作。
- 组合使用:一种常见的模式是使用接口定义核心契约,同时提供一个抽象类(适配器)实现该接口并给出部分默认实现。这样,其他类既可以直接实现接口获得完全的控制权,也可以选择继承抽象类来减少需要重写的方法数量。
- 在设计模式中的应用:
- 接口常用于策略模式、工厂模式等,用于定义可插拔的行为。
- 抽象类是模板方法模式的核心,它定义了操作的基本步骤,允许子类在不改变结构的前提下重定义某些步骤。
💎 总结与最佳实践
简单来说,选择的关键在于你的设计意图:
- 需要定义行为规范或实现多重继承? → 选择接口。
- 需要在密切相关的类之间共享代码和状态? → 选择抽象类。
此外,随着Java版本演进,接口功能不断增强(如默认方法),但其不能拥有状态(非静态成员变量)和构造方法的本质没有改变。因此,在大多数情况下,应优先考虑使用接口以保持最大的灵活性,当明确需要代码复用或状态管理时,再引入抽象类。
9)封装继承多态
9.1)
封装从字面上来理解就是包装的意思,专业点就是信息隐藏,是指利用抽象将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。
封装确实可以使我们更容易地修改类的内部实现,而无需修改使用了该类的代码。
封装可以对成员变量进行更精确的控制。
Java 虽然不支持多继承,但是 Java 有三种实现多继承效果的方式,分别是内部类、多层继承和实现接口。
如果子类的构造方法中没有显示地调用父类构造方法,则系统默认调用父类无参数的构造方法。
9.2)
方法重写也就是子类中出现和父类中一模一样的方法(包括返回值类型,方法名,参数列表),它建立在继承的基础上。你可以理解为方法的外壳不变,但是核心内容重写。
方法重载:如果有两个方法的方法名相同,但参数不一致,那么可以说一个方法是另一个方法的重载。
Java 子类重写继承的方法时,不可以降低方法的访问权限,子类继承父类的访问修饰符作用域不能比父类小,也就是更加开放。
继承当中子类抛出的异常必须是父类抛出的异常或父类抛出异常的子异常。子类方法抛出的异常范围不可以比父类范围更大。
final 变量一旦赋值后,不能被重新赋值。被 final 修饰的实例变量必须显式指定初始值(即不能只声明)。final 修饰符通常和 static 修饰符一起使用来创建类常量。
父类中的 final 方法可以被子类继承,但是不能被子类重写。声明 final 方法的主要目的是防止该方法的内容被修改。
有抽象方法的类必须是抽象类。
9.3)
向下转型 : 通过父类对象(大范围)实例化子类对象(小范围),在书写上父类对象需要加括号()强制转换为子类类型。但父类引用变量实际引用必须是子类对象才能成功转型。
向上转型 : 通过子类对象(小范围)实例化父类对象(大范围),这种属于自动转换。
Object object=new Integer(666);//向上转型
Integer i=(Integer)object;//向下转型Object->Integer,object的实质还是指向Integer
String str=(String)object;//错误的向下转型,虽然编译器不会报错但是运行会报错
9.4)
在 Java 继承中,父子类初始化先后顺序为:
- 父类中静态成员变量和静态代码块
- 子类中静态成员变量和静态代码块
- 父类中普通成员变量和代码块,父类的构造方法
- 子类中普通成员变量和代码块,子类的构造方法
总的来说,就是静态>非静态,父类>子类,非构造方法>构造方法。同一类别(例如普通变量和普通代码块)成员变量和代码块执行从前到后,需要注意逻辑。
静态变量也称类变量,可以看成一个全局变量,静态成员变量和静态代码块在类加载的时候就初始化,而非静态变量和代码块在对象创建的时候初始化。所以静态快于非静态初始化。
class Father{
public Father() {
System.out.println(++b1+"父类构造方法");
}//父类构造方法 第四
static int a1=0;//父类static 第一 注意顺序
static {
System.out.println(++a1+"父类static");
}
int b1=a1;//父类成员变量和代码块 第三
{
System.out.println(++b1+"父类代码块");
}
}
class Son extends Father{
public Son() {
System.out.println(++b2+"子类构造方法");
}//子类构造方法 第六
static {//子类static第二步
System.out.println(++a1+"子类static");
}
int b2=b1;//子类成员变量和代码块 第五
{
System.out.println(++b2 + "子类代码块");
}
}
public class test9 {
public static void main(String[] args) {
Son son=new Son();
}
}
结果
1父类static
2子类static
3父类代码块
4父类构造方法
5子类代码块
6子类构造方法
9.5)
多态的前提条件有三个:
- 子类继承父类
- 子类重写父类的方法
- 父类引用指向子类的对象
由于编译器只有一个 Wanger 引用,它怎么知道究竟该调用父类 Wanger 的 write() 方法,还是子类 Wangxiaoer 的 write() 方法呢?答案是在运行时根据对象的类型进行后期绑定,编译器在编译阶段并不知道对象的类型,但是 Java 的方法调用机制能找到正确的方法体。
在构造方法中调用多态方法,会产生一个奇妙的结果。
在构造方法中调用可重写方法是不推荐的做法,因为子类字段可能尚未初始化,导致意外行为。这种情况下,子类方法访问的字段值可能是默认值而非预期值。
public class Wangxiaosan extends Wangsan {
private int age = 3;
public Wangxiaosan(int age) {
this.age = age;
System.out.println("王小三的年龄:" + this.age);
}
public void write() { // 子类覆盖父类方法
System.out.println("我小三上幼儿园的年龄是:" + this.age);
}
public static void main(String[] args) {
new Wangxiaosan(4);
// 上幼儿园之前
// 我小三上幼儿园的年龄是:0
// 上幼儿园之后
// 王小三的年龄:4
}
}
class Wangsan {
Wangsan () {
System.out.println("上幼儿园之前");
write();
System.out.println("上幼儿园之后");
}
public void write() {
System.out.println("老子上幼儿园的年龄是3岁半");//本例中这个代码不会执行
}
}
- 动态绑定导致子类方法被调用
- 虽然父类构造方法在执行,但
write()方法已被子类重写 - Java的动态绑定机制会根据对象的实际类型(
Wangxiaosan)调用子类的write()方法 - 此时子类构造方法尚未执行,
age字段仍为默认值0
字段初始化时机
- 在父类构造方法执行时,子类的实例字段
private int age = 3尚未初始化 - 字段初始化发生在父类构造方法调用之后、子类构造方法体执行之前
- 因此子类
write()方法中的this.age为0
9.6)多态与向下转型
向下转型是指将父类引用强转为子类类型;这是不安全的,因为有的时候,父类引用指向的是父类对象,向下转型就会抛出 ClassCastException,表示类型转换失败;但如果父类引用指向的是子类对象,那么向下转型就是成功的。
public class Wangxiaosi extends Wangsi {
public void write() {
System.out.println("记住仇恨,表明我们要奋发图强的心智");
}
public void eat() {
System.out.println("我不喜欢读书,我就喜欢吃");
}
public static void main(String[] args) {
Wangsi[] wangsis = { new Wangsi(), new Wangxiaosi() };
// wangsis[1]能够向下转型,实际对象本身就是目标类型Wangxiaosi的实例
((Wangxiaosi) wangsis[1]).write();
// wangsis[0]不能向下转型,实际对象就是父类Wangsi,与目标类型不兼容
((Wangxiaosi)wangsis[0]).write();
}
}
class Wangsi {
public void write() {
System.out.println("勿忘国耻");
}
public void read() {
System.out.println("每周读一本好书");
}
}
理解向下转型的关键
- 向下转型 (
Downcasting) 指将父类引用转换为子类引用。这个过程需要显式进行,并且Java虚拟机在运行时会对转换进行类型检查。 - 它的安全性完全取决于堆内存中对象的实际类型。只有当父类引用实际指向的是一个子类对象时,向下转型才是安全且成功的。你的
wangsis[1]就符合这种情况。 - 如果父类引用实际指向的就是父类对象本身(如你的
wangsis[0]),那么强制向下转型到一个不相干的子类型就会导致ClassCastException。
🛡️ 安全进行向下转型的建议
在实际编码中,为了确保向下转型的安全性,强烈建议在转换前使用 instanceof关键字进行类型检查。
if (wangsis[0] instanceof Wangxiaosi) { ((Wangxiaosi) wangsis[0]).write(); // 安全了 } else { System.out.println("类型不匹配,无法安全转换。"); }
10)this和super
10.1)在java类的无参构造函数内部调用有参构造函数,为什么调用有参构造函数一定要放在第一行?
主要基于对象初始化的完整性和安全性考虑。
| 原因 | 详细解释 |
|---|---|
| 确保父类先初始化 | 在调用本类其他构造器(通过this())时,必须先保证父类构造器已经执行。Java通过强制将this()或super()放在首行来确保这一点。如果未显式调用,编译器会自动在首行加上super()。 |
| 避免重复初始化 | 一个对象在它的生命周期内只应被初始化一次。如果允许在构造器内多次或在不同位置调用this()或super(),可能导致对象状态混乱或重复初始化,破坏其完整性。 |
| 维持构造器链的顺序性 | 构造器的调用形成了一条链。从最顶层的父类(通常是Object)开始,自上而下依次执行,确保每个部分都被正确初始化后,再执行子类的逻辑。将调用放在首行是维持这种顺序的最直接方式。 |
深入理解执行顺序
对象的创建过程遵循一个明确的“构造器链”(Constructor Chaining)。当你执行 new MyClass()时,其内部顺序如下:
- 分配内存:首先为对象分配内存空间。
- 沿继承链向上调用:从子类到父类,递归地调用构造器,直到最终的
Object类。这确保了父类的初始化在子类之前完成。 - 执行初始化代码:在控制权沿着构造器链返回的过程中,依次执行各构造器中的代码。这包括:
- 显式初始化语句(例如
private String name = "Java";)。 - 构造器体中
this()或super()调用之后的代码。
- 显式初始化语句(例如
💡 实际应用与重要提醒
this()和super()不可兼得:在同一个构造器中,你不能同时使用this()和super(),因为它们都必须占据第一行的位置。你只能选择其中一个。- 字段初始化时机:实例字段的显式初始化(如
private int age = 10;)发生在调用父类构造器(super())之后,但在执行当前类构造器体剩余代码之前。这解释了为什么在父类构造器中调用可被重写的方法是危险的,因为子类的字段可能还未被初始化。 - 推荐做法:在无参构造器中调用有参构造器是一种很好的编程实践,可以为参数提供默认值,实现代码复用。
11)static
静态变量只会获取一次内存空间
静态方法不能访问非静态变量和调用非静态方法
静态内部类
常见的内部类有四种,成员内部类、局部内部类、匿名内部类和静态内部类。
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
public static final Singleton instance = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.instance;
}
}
第一次加载 Singleton 类时并不会初始化 instance,只有第一次调用 getInstance() 方法时 Java 虚拟机才开始加载 SingletonHolder 并初始化 instance,这样不仅能确保线程安全,也能保证 Singleton 类的唯一性。不过,创建单例更优雅的一种方式是使用枚举。
需要注意的是。第一,静态内部类不能访问外部类的所有成员变量;第二,静态内部类可以访问外部类的所有静态变量,包括私有静态变量。第三,外部类不能声明为 static。
静态内部类是 Java 中一种定义在另一个类内部的、使用 static关键字修饰的嵌套类。它的核心特征在于不依赖于外部类的实例,可以独立存在和访问,主要用于逻辑分组、提高封装性和代码可读性 。下面这个表格能帮你快速抓住静态内部类的核心特性和应用考量:
| 特性/方面 | 静态内部类 | 普通内部类(非静态) |
|---|---|---|
| 依赖关系 | 不依赖外部类实例,可独立创建 | 必须依赖外部类实例才能创建 |
| 访问权限 | 只能直接访问外部类的静态成员 | 可以直接访问外部类的所有成员(静态和非静态) |
| 内存考虑 | 不隐式持有外部类引用,内存开销相对较小 | 隐式持有外部类引用,可能增加内存泄漏风险 |
实际应用场景
- 实现 Builder 模式 当需要构建一个拥有多个可选参数的复杂对象时,静态内部类可以实现优雅的 Builder 模式。这种方式使得对象构造过程更清晰,也支持链式调用 。
- 实现线程安全的单例模式 利用静态内部类可以实现一种既简洁又线程安全的延迟加载单例 。
- 作为辅助类或工具类 当一个类仅用于辅助外部类,或者与外部类关系紧密但不需要访问外部类实例成员时,可以将其定义为静态内部类。这有助于代码的模块化和组织 。例如,在实现某个数据结构时,可以用静态内部类来表示节点。
- 实现特定接口或类 静态内部类可以独立地实现接口或继承类。当外部类已经继承了一个类,但又需要拥有另一个类或接口的能力时,可以通过静态内部类来间接实现,这在一定程度上提供了类似多重继承的灵活性 。
如何选择:静态内部类 vs. 普通内部类
选择的关键在于内部类是否需要访问外部类的实例变量或方法。
- 如果需要直接访问外部类的实例状态,或者内部类对象与外部类对象生命周期强关联,则使用普通内部类。
- 如果不需要访问外部类的实例成员,或者内部类需要独立于外部类实例使用,优先选择静态内部类。这通常是更安全、内存效率更高的选择,尤其是在内部类不需要与外部类实例绑定时 。
12)instanceof
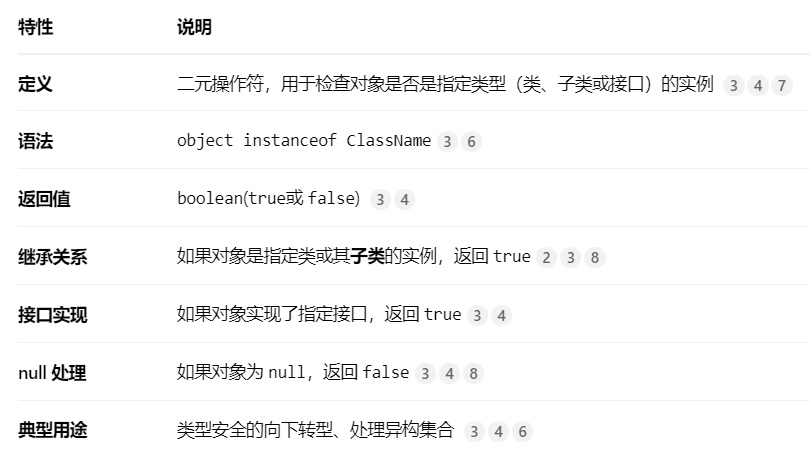
🎯 核心应用场景
- 类型安全的向下转型(Type-safe Downcasting) 这是
instanceof最常见的用途。在进行强制类型转换前,先用instanceof检查,可以避免运行时抛出ClassCastException。 - 处理多态集合 当集合(如
List<Object>)中存放了不同类型的对象时,可以使用instanceof来区分处理 。
✨ Java 16 模式匹配
从 Java 16 开始,instanceof引入了模式匹配(Pattern Matching)功能 。它允许在检查的同时直接声明一个类型转换后的变量,让代码更加简洁。
⚖️ 替代方案比较
虽然 instanceof很方便,但有时其他方法更合适:
| 方法 | 特点 | 与 instanceof的区别 |
|---|---|---|
getClass()方法 |
精确检查对象的实际类 | instanceof考虑继承(子类也会返回 true),getClass()只检查确切类型 。 |
Class.isInstance() |
功能与 instanceof类似,但通过反射实现 |
行为一致,但语法不同:String.class.isInstance(obj)。 |
💡 最佳实践与注意事项
- 优先使用多态设计:过度或不当使用
instanceof可能意味着代码设计可以优化,应优先考虑利用多态、策略模式等面向对象特性 。 - 检查
null的安全性:instanceof在处理null时直接返回false,无需额外进行null检查 。 - 不可用于基本数据类型:
instanceof的操作数必须是对象,不能用于基本数据类型(如int,char)。对于基本数据类型的包装类(如Integer),则可以正常使用。
合理地运用 instanceof能让你的代码更安全灵活,尤其是在处理未知类型或进行类型转换时。但也要注意评估是否可以通过更好的设计来减少其使用。
13)不可变类
一个类的对象在通过构造方法创建后如果状态不会再被改变,那么它就是一个不可变(immutable)类。它的所有成员变量的赋值仅在构造方法中完成,不会提供任何 setter 方法供外部类去修改。
Java 标准库中的 String、基本类型的包装类(如 Integer、Long)、BigInteger等都是经典的不可变类。
要实现一个严格的不可变类,通常需要遵循以下核心规则:
- 将类声明为
final:防止类被继承,避免子类重写方法改变其行为。 - 将所有成员变量声明为
private final:private确保外部不能直接访问,final保证引用不会改变(对于基本类型则值不变)。 - 不提供修改状态的方法:即不提供
setter等任何可能修改成员变量值的方法。 - 通过构造函数深度初始化所有状态:确保对象在创建时状态就完全确定。
- 保护性拷贝(Defensive Copy):这是处理可变成员变量的关键。如果类持有可变对象(如
List、Date或自定义的可变类)的引用,需要:- 在构造函数中:传入可变对象时,应创建其副本并存储该副本的引用,而不是直接存储外部引用。
- 在
getter方法中:返回可变成员时,应返回其副本,而不是原始引用。
下面的代码对比了处理可变成员的正误方式。
// 正确示例:包含保护性拷贝的不可变类
import java.util.Date;
import java.util.List;
import java.util.ArrayList;
import java.util.Collections;
public final class ImmutableExample {
private final Date createDate;
private final List<String> items;
// 构造函数中的保护性拷贝
public ImmutableExample(Date date, List<String> list) {
// 拷贝日期对象,而非直接引用
this.createDate = new Date(date.getTime());
// 创建列表的副本
this.items = new ArrayList<>(list);
}
// Getter方法中的保护性拷贝
public Date getCreateDate() {
return new Date(createDate.getTime()); // 返回副本
}
public List<String> getItems() {
return new ArrayList<>(items); // 返回副本
// 或者返回不可修改的视图:
// return Collections.unmodifiableList(new ArrayList<>(items));
}
}
// 错误示例:直接暴露内部可变对象的引用(破坏不可变性)
public final class MutableExample {
private final Date createDate; // final 只能保证引用不变,但对象内容可能被修改
private final List<String> items;
public MutableExample(Date date, List<String> list) {
this.createDate = date; // 直接存储外部引用,危险!
this.items = list; // 直接存储外部引用,危险!
}
public Date getCreateDate() {
return createDate; // 直接返回内部引用,外部代码可以修改其内容!
}
public List<String> getItems() {
return items; // 直接返回内部引用,外部代码可以修改其内容!
}
}
不可变类的优势与代价
不可变类之所以被广泛使用,是因为它具有以下显著优点:
- 线程安全:这是不可变类最大的优势之一。因为状态不变,所以多个线程并发访问同一对象时,无需额外的同步(如加锁)操作,天然避免了数据竞争问题,简化了并发编程的复杂性。
- 易于设计和理解:对象的状态在创建后固定不变,这使得代码的逻辑更清晰,更容易推理,减少了因状态变化而引入的潜在错误。
- 适合作为缓存键和集合元素:由于对象的
hashCode()值在其生命周期内不会改变,可以安全地用作HashMap的键或HashSet的元素,无需担心因其状态的改变导致哈希值变化,从而破坏集合的结构。 - 便于缓存:可以缓存创建后的实例。例如,
String类的字符串常量池就是基于此特性的优化。
当然,不可变类也非万能,其主要代价在于:
- 可能产生大量临时对象:每次"修改"(实际上是创建新对象)都会产生新对象,可能增加垃圾回收(Garbage Collection)的压力。在需要频繁修改状态的场景下,性能开销可能较大。为此,Java 为
String类提供了可变的搭档StringBuilder和StringBuffer。
🛠️ 不可变类的实际应用场景
了解特性后,我们来看看在实际项目中哪些地方会用到不可变类:
- 值对象和配置类:非常适合表示诸如 配置信息(Configuration)、数据传输对象(DTO)、领域模型中的值对象 等。这些对象通常在系统初始化或数据传入时创建,之后便不应再被修改,保证了核心数据的稳定性和一致性。
- 并发编程场景:在多线程环境下,将共享数据设计为不可变对象,可以极大简化线程同步的复杂度,避免昂贵的锁开销,提高程序性能并降低死锁风险。
- 缓存键和集合元素:由于其
hashCode的稳定性,非常适合用作HashMap等哈希表的键(Key),或者作为HashSet中的元素。 - 函数式编程风格:函数式编程强调无副作用和不可变性。使用不可变类符合函数式编程的原则,能使代码更简洁、可预测。
💎 总结
不可变类通过其状态不变性,在代码的安全性、简洁性和并发性方面带来了显著优势。虽然可能在频繁"修改"场景下产生一些对象创建开销,但在大多数情况下,其利远大于弊。在设计系统,尤其是涉及并发处理、数据传递和核心模型时,充分考虑并使用不可变类,能有效提升代码质量。
14)方法重写
如果一个方法是 static 的,也不允许重写,因为静态方法可用于父类以及子类的所有实例。重写的目的在于根据对象的类型不同而表现出多态,而静态方法不需要创建对象就可以使用。没有了对象,重写所需要的“对象的类型”也就没有存在的意义了。
重写的方法不能使用限制等级更严格的权限修饰符。
🧠 核心原因:维护“是一个”的关系与多态
这个规则最根本的目的是为了维护面向对象中子类“是一个”父类的“is-a”关系,以及由此衍生的多态性 。
- 保证多态性不失效:多态允许我们使用父类类型的引用来指向子类对象。例如
Animal myAnimal = new Dog();。接下来,当我们调用myAnimal.eat()时,实际执行的是Dog类中重写的eat方法。这里的关键在于,编译时类型是Animal,而运行时类型是Dog。遵循里氏替换原则(LSP):这条规则是里氏替换原则的具体体现之一。该原则规定,子类对象必须能够替换掉所有父类对象,且程序的行为不变。如果子类重写的方法权限更严格,就意味着子类对象无法在父类对象能工作的所有场景下无缝替换,从而破坏了这一原则。- 如果允许缩小权限:假设
Animal.eat()是public的,这意味着在任何地方都可以通过Animal引用调用eat方法。但如果Dog类将eat方法重写为protected,那么在某些地方(比如另一个包中)通过Animal引用调用eat方法就会导致编译错误!因为编译器只知道myAnimal是Animal类型,它检查后发现Animal.eat()是public,认为调用是合法的,但实际上运行时对象Dog的eat方法访问权限却更小,可能无法访问。这会造成混乱和不确定性。 - 因此,Java通过此规则将风险遏制在编译期:它强制要求子类方法的访问范围不能窄于父类方法。这样就确保了,凡是能使用父类的地方,其子类对象也一定能以相同的方式被使用,而不会出现因权限问题导致的调用失败。
- 如果允许缩小权限:假设
重写后的方法不能抛出比父类中更高级别的异常。
如果父类中的方法抛出的是 IOException,那么子类中重写的方法不能抛出 Exception,可以是 IOException 的子类或者不抛出任何异常。
可以在子类中通过 super 关键字来调用父类中被重写的方法。
构造方法不能被重写。
synchronized 关键字对重写规则没有任何影响。
synchronized 关键字用于在多线程环境中获取和释放监听对象,因此它对重写规则没有任何影响,这就意味着 synchronized 方法可以去重写一个非同步方法。
strictfp 关键字对重写规则没有任何影响。
15)注解
注解的生命周期有 3 种策略,定义在 RetentionPolicy 枚举中。
1)SOURCE:在源文件中有效,被编译器丢弃。
2)CLASS:在编译器生成的字节码文件中有效,但在运行时会被处理类文件的 JVM 丢弃。
3)RUNTIME:在运行时有效。这也是注解生命周期中最常用的一种策略,它允许程序通过反射的方式访问注解,并根据注解的定义执行相应的代码。
普通注释(如//, /* */)是给人看的,编译器会忽略。注解是给编译器、工具或运行时环境看的,可以被处理并打包到class文件中。
注解的实际应用场景
注解在现代Java开发中无处不在,特别是在各种框架和工具里。
- 框架配置与依赖注入:Spring等框架大量使用注解来简化配置。例如,
@Component,@Service标记一个类为Spring管理的Bean;@Autowired实现依赖的自动注入。 - 数据校验:在POJO(普通Java对象)的字段上使用校验注解,如JSR 303 Bean Validation的
@NotNull,@Size,可以方便地在控制器层进行数据有效性验证。 - 面向切面编程(AOP):结合自定义注解和AOP,可以优雅地实现横切关注点。例如,定义一个
@Loggable注解,通过AOP在标记的方法执行前后自动记录日志,而无需修改原方法代码。 - 对象关系映射(ORM):JPA规范使用注解(如
@Entity,@Table,@Column)将Java对象映射到数据库表结构。 - 测试:JUnit等测试框架通过注解(如
@Test)来标识和配置测试方法。 - 代码生成与简化:Lombok库通过注解(如
@Data,@Getter)在编译时自动生成getter、setter、构造方法等样板代码。 - 序列化与API文档:Jackson库用注解(如
@JsonIgnore,@JsonProperty)控制JSON序列化行为。Swagger通过注解生成RESTful API文档。
🧠 理解注解的工作原理
注解的强大功能依赖于对其信息的处理:
- 编译时处理:注解处理器(Annotation Processor)在编译时扫描注解,可用于生成额外代码、资源文件或进行编译检查。Lombok和许多Android库的
@BindView就是典型例子。 - 运行时处理:通过Java的反射机制,在运行时读取类、方法、字段上的注解信息,然后动态执行相应逻辑。Spring框架的
@Autowired依赖注入就是这样实现的。
下面是一个简单的自定义注解应用,用于方法级别的权限检查:
// 1. 定义自定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME) // 必须为RUNTIME,运行时才能通过反射读取
public @interface Permission {
String[] value(); // 需要的权限数组
}
// 2. 在Service方法上使用注解
public class UserService {
@Permission({"admin", "user_manager"}) // 该方法需要'admin'或'user_manager'权限
public void deleteUser(Long userId) {
// 删除用户的业务逻辑
}
}
// 3. 通过AOP或拦截器处理注解(简化示例)
@Aspect
@Component
public class PermissionAspect {
@Around("@annotation(permission)") // 环绕通知,拦截带有@Permission注解的方法
public Object checkPermission(ProceedingJoinPoint joinPoint, Permission permission) throws Throwable {
HttpServletRequest request = ... // 获取当前请求
String currentUserRole = getCurrentUserRole(request); // 获取当前用户角色
// 检查当前用户角色是否在注解要求的权限范围内
if (Arrays.asList(permission.value()).contains(currentUserRole)) {
return joinPoint.proceed(); // 有权限,继续执行原方法
} else {
throw new SecurityException("权限不足!"); // 无权限,抛出异常
}
}
}
总结与建议
Java注解通过提供声明式的元数据机制,将配置信息与代码本身紧密结合,极大地提升了代码的简洁性、可读性和可维护性。其核心价值在于约定优于配置,使框架能够智能地处理许多通用逻辑。在实际开发中,你需要:
- 理解生命周期:明确你的注解是需要编译时处理还是运行时反射,从而正确设置
@Retention。 - 明确目标:使用
@Target指定注解可应用的元素类型。 - 善用框架注解:优先学习并使用成熟框架(如Spring, JPA, JUnit)提供的注解。
- 审慎自定义:当需要解耦特定业务逻辑或创建通用组件时,再考虑自定义注解,通常结合AOP或拦截器使用。
16)枚举
表示一种特殊类型的类,继承自 java.lang.Enum
public enum PlayerType {
TENNIS,
FOOTBALL,
BASKETBALL
}
反编译后的字节码
public final class PlayerType extends Enum
{
public static PlayerType[] values()
{
return (PlayerType[])$VALUES.clone();
}
public static PlayerType valueOf(String name)
{
return (PlayerType)Enum.valueOf(com/cmower/baeldung/enum1/PlayerType, name);
}
private PlayerType(String s, int i)
{
super(s, i);
}
public static final PlayerType TENNIS;
public static final PlayerType FOOTBALL;
public static final PlayerType BASKETBALL;
private static final PlayerType $VALUES[];
static
{
TENNIS = new PlayerType("TENNIS", 0);
FOOTBALL = new PlayerType("FOOTBALL", 1);
BASKETBALL = new PlayerType("BASKETBALL", 2);
$VALUES = (new PlayerType[] {
TENNIS, FOOTBALL, BASKETBALL
});
}
}
既然枚举是一种特殊的类,那它其实是可以定义在一个类的内部的,这样它的作用域就可以限定于这个外部类中使用
public class Player {
private PlayerType type;
public enum PlayerType {
TENNIS,
FOOTBALL,
BASKETBALL
}
public boolean isBasketballPlayer() {
return getType() == PlayerType.BASKETBALL;
}
public PlayerType getType() {
return type;
}
public void setType(PlayerType type) {
this.type = type;
}
}
EnumSet 是一个专门针对枚举类型的 Set 接口的实现类,它是处理枚举类型数据的一把利器,非常高效。从名字上就可以看得出,EnumSet 不仅和 Set 有关系,和枚举也有关系。
因为 EnumSet 是一个抽象类,所以创建 EnumSet 时不能使用 new 关键字。不过,EnumSet 提供了很多有用的静态工厂方法。
使用 noneOf() 静态工厂方法创建了一个空的 PlayerType 类型的 EnumSet;使用 allOf() 静态工厂方法创建了一个包含所有 PlayerType 类型的 EnumSet。
public class EnumSetTest {
public enum PlayerType {
TENNIS,
FOOTBALL,
BASKETBALL
}
public static void main(String[] args) {
EnumSet<PlayerType> enumSetNone = EnumSet.noneOf(PlayerType.class);
System.out.println(enumSetNone);
EnumSet<PlayerType> enumSetAll = EnumSet.allOf(PlayerType.class);
System.out.println(enumSetAll);
}
}
《Effective Java》这本书里还提到了一点,如果要实现单例的话,最好使用枚举的方式
单例(Singleton)用来保证一个类仅有一个对象,并提供一个访问它的全局访问点,在一个进程中。因为这个类只有一个对象,所以就不能再使用 new 关键字来创建新的对象了。
“Java 标准库有一些类就是单例,比如说 Runtime 这个类。”
Runtime runtime = Runtime.getRuntime();Runtime 类可以用来获取 Java 程序运行时的环境。
实现单例并非易事
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
要用到 volatile、synchronized 关键字等等,但枚举的出现,让代码量减少到极致。”
public enum EasySingleton{
INSTANCE;
}枚举默认实现了 Serializable 接口,因此 Java 虚拟机可以保证该类为单例,这与传统的实现方式不大相同。传统方式中,我们必须确保单例在反序列化期间不能创建任何新实例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号