


Python基础语法
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 \ 来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠 \,例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
数据类型和变量
complex (复数) - 复数由实部和虚部组成,形式为 a + bj,其中 a 是实部,b 是虚部,j 表示虚数单位。如 1 + 2j、 1.1 + 2.2j
对于很大的数,例如10000000000,很难数清楚0的个数。Python允许在数字中间以_分隔,因此,写成10_000_000_000和10000000000是完全一样的。十六进制数也可以写成0xa1b2_c3d4。
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!'
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,可以自己试试:
>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以自己试试:
>>> print('''line1
... line2
... line3''')
line1
line2
line3
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
在Python中,有两种除法,一种除法是/:/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数。
还有一种除法是//,称为地板除,两个整数的除法仍然是整数,结果为数值解的向下取整
可以使用 bool() 函数将其他类型的值转换为布尔值。以下值在转换为布尔值时为 False:None、False、零 (0、0.0、0j)、空序列(如 ''、()、[])和空映射(如 {})。其他所有值转换为布尔值时均为 True。
# 布尔类型的整数表现
print(int(True)) # 1
print(int(False)) # 0
# 使用 bool() 函数进行转换
print(bool('')) # False
print(bool('Python')) # True
print(bool([])) # False
print(bool([1, 2, 3])) # True
字符串
- Python 中单引号 ' 和双引号 " 使用完全相同。
- 使用三引号(''' 或 """)可以指定一个多行字符串。
- 反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。 如 r"this is a line with \n" 则 \n 会显示,并不是换行。
- 字符串可以用 + 运算符连接在一起,用 * 运算符重复。
- Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python 中的字符串不能改变。
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串切片 str[start:end],其中 start(包含)是切片开始的索引,end(不包含)是切片结束的索引。
- 字符串的切片可以加上步长参数 step,语法格式如下:str[start:end:step]
- Python 字符串不能被改变。向一个索引位置赋值,比如 word[0] = 'm' 会导致错误。
实例:
str='123456789'
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第六个的字符(不包含)
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2)
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
对于可变对象,比如list,对list进行操作,list内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']而对于不可变对象,比如str,对str进行操作呢:
>>> a = 'abc'
>>> a.replace('a', 'A')
'Abc'
>>> a
'abc'虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc',应该怎么理解呢?
我们先把代码改成下面这样:
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'要始终牢记的是,a是变量,而'abc'才是字符串对象!有些时候,我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc':
┌───┐ ┌───────┐
│ a │────▶│ 'abc' │
└───┘ └───────┘
当我们调用a.replace('a', 'A')时,实际上调用方法replace是作用在字符串对象'abc'上的,而这个方法虽然名字叫replace,但却没有改变字符串'abc'的内容。相反,replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了:
┌───┐ ┌───────┐
│ a │────▶│ 'abc' │
└───┘ └───────┘
┌───┐ ┌───────┐
│ b │────▶│ 'Abc' │
└───┘ └───────┘
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
print('%5d-%03d' % (3, 1)) #%2d表示整个数占5个位置,右边对齐,多余的空格补全。%03d表示整个数占3个位置,右边对齐,多余的0补全
print('%.2f' % 3.1415926) #保留小数点后两位
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
f-string
最后一种格式化字符串的方法是使用以f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
>>> r = 2.5
>>> s = 3.14 * r ** 2
>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle with radius 2.5 is 19.62
上述代码中,{r}被变量r的值替换,{s:.2f}被变量s的值替换,并且:后面的.2f指定了格式化参数(即保留两位小数),因此,{s:.2f}的替换结果是19.62。
Python可以通过 type() 函数查看变量的类型,也可以通过isinstance(var,class)判断是否同一种类型
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
数值运算中,a ** b表示a的b次方
count()方法
该方法返回子字符串在字符串中出现的次数。
str.count(sub, start= 0,end=len(string))
- sub -- 搜索的子字符串
- start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
str="www.runoob.com"
sub='o'
print ("str.count('o') : ", str.count(sub))
sub='run'
print ("str.count('run', 0, 10) : ", str.count(sub,0,10))
结果
str.count('o') : 3
str.count('run', 0, 10) : 1
find()方法
find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.find(str2))
print (str1.find(str2, 5))
print (str1.find(str2, 10))
结果
7
7
-1
index()方法
index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。如果包含子字符串返回开始的索引值。
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.index(str2))
print (str1.index(str2, 5))
print (str1.index(str2, 10))
结果
7
7
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (str1.index(str2, 10))
ValueError: substring not found
list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
变量classmates就是一个list。用len()函数可以获得list元素的个数:
>>> len(classmates)
3
用索引来访问list中每一个位置的元素,索引是从0开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'
以此类推,可以获取倒数第2个、倒数第3个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除list末尾的元素,用pop()方法:
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'
>>> classmates
['Michael', 'Sarah', 'Tracy']
list里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]
list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4
要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']
要拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
>>> L = []
>>> len(L)
0
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ] # 定义一个列表
tinylist = [123, 'runoob']
print(list[:]) #打印list所有元素
print (tinylist * 2) # 打印tinylist列表两次
print (list + tinylist) # 打印两个列表拼接在一起的结果
对于列表a,如果a[2:6] = [ ] ,表示直接删除列表a中第3个到第6个元素
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | len(list) 列表元素个数 |
| 2 | max(list) 返回列表元素最大值 |
| 3 | min(list) 返回列表元素最小值 |
| 4 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)
如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()
但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1
定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
这个tuple定义的时候有3个元素,分别是'a','b'和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
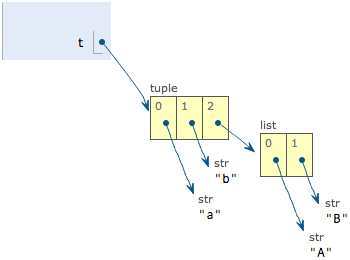
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
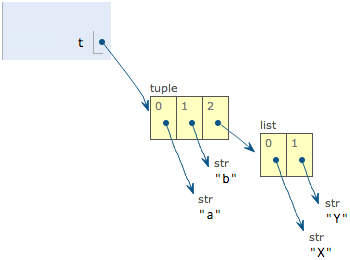
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
set
Python 中的集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
在 Python 中,集合使用大括号 {} 表示,元素之间用逗号 , 分隔。
另外,也可以使用 set() 函数创建集合。
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
要创建一个set,用{x,y,z,...}列出每个元素:
>>> s = {1, 2, 3}
>>> s
{1, 2, 3}或者提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉
# 成员测试
if 'Runoob' in sites :
print('Runoob 在集合中')
else :
print('Runoob 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
x 可以有多个,用逗号分开。
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.update({1,3})
>>> print(thisset)
{1, 3, 'Google', 'Taobao', 'Runoob'}
>>> thisset.update([1,4],[5,6])
>>> print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'Runoob'}
>>>
通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}
还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
也可以设置随机删除集合中的一个元素,多次执行测试结果都不一样。
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
语法格式如下:
s.pop()
Dictionary
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
在同一个字典中,键(key)必须是唯一的。
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
构造函数 dict() 可以直接从键值对序列中构建字典如下:
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False
二是通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -114514)
-114514
注意:返回None的时候Python的交互环境不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
fromkeys() 方法
字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
- seq -- 字典键值列表。
- value -- 可选参数, 设置键序列(seq)对应的值,默认为 None。
seq = ('name', 'age', 'sex')
tinydict = dict.fromkeys(seq)
print ("新的字典为 : %s" % str(tinydict))
tinydict = dict.fromkeys(seq, 10)
print ("新的字典为 : %s" % str(tinydict))
结果:
新的字典为 : {'age': None, 'name': None, 'sex': None}
新的字典为 : {'age': 10, 'name': 10, 'sex': 10}
copy()方法
字典 copy() 函数返回一个字典的浅复制。
dict1 = {'user':'runoob','num':[1,2,3]}
dict2 = dict1 # 浅拷贝: 引用对象
dict3 = dict1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,子对象是引用
# 修改 data 数据
dict1['user']='root'
dict1['num'].remove(1)
# 输出结果
print(dict1)
print(dict2)
print(dict3)
实例中 dict2 其实是 dict1 的引用(别名),所以输出结果都是一致的,dict3 父对象进行了深拷贝,不会随dict1 修改而修改,子对象是浅拷贝所以随 dict1 的修改而修改。
{'user': 'root', 'num': [2, 3]}
{'user': 'root', 'num': [2, 3]}
{'user': 'runoob', 'num': [2, 3]}
get() 方法
字典 get() 函数返回指定键的值。
- key -- 字典中要查找的键。
- value -- 可选,如果指定键的值不存在时,返回该默认值。
tinydict = {'Name': 'Runoob', 'Age': 27}
print ("Age : ", tinydict.get('Age'))
# 没有设置 Sex,也没有设置默认的值,输出 None
print ("Sex : ", tinydict.get('Sex'))
# 没有设置 Salary,输出默认的值 114.0
print ('Salary: ', tinydict.get('Salary', 114.0))
结果
Age : 27
Sex : None
Salary: 114.0
get() 方法 Vs dict[key] 访问元素区别
get(key) 方法在 key(键)不在字典中时,可以返回默认值 None 或者设置的默认值。
dict[key] 在 key(键)不在字典中时,会触发 KeyError 异常。
setdefault() 方法
字典 setdefault() 方法和 get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
tinydict = {'Name': 'Runoob', 'Age': 7}
print ("Age 键的值为 : %s" % tinydict.setdefault('Age', None))
print ("Sex 键的值为 : %s" % tinydict.setdefault('Sex', None))
print ("新字典为:", tinydict)
结果:
Age 键的值为 : 7
Sex 键的值为 : None
新字典为: {'Age': 7, 'Name': 'Runoob', 'Sex': None}
popitem() 方法
字典 popitem() 方法随机返回并删除字典中的最后一对键和值,以元组的形式。如果字典已经为空,却调用了此方法,就报出 KeyError 异常。
返回最后插入键值对(key, value 形式),按照 LIFO(Last In First Out 后进先出法) 顺序规则,即最末尾的键值对。
pop() 方法
Python 字典 pop() 方法删除字典 key(键)所对应的值,返回被删除的值。如果键不存在,则可以选择返回一个默认值(如果提供了)。
site= {'name': '菜鸟教程', 'alexa': 10000, 'url': 'www.runoob.com'}
element = site.pop('nickname', '不存在的 key')
print('删除的元素为:', element)
print('字典为:', site)
结果
删除的元素为: 不存在的 key
字典为: {'name': '菜鸟教程', 'alexa': 10000, 'url': 'www.runoob.com'}
Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(x) != id(y)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
a = 20
b = 20
if ( a is b ):
print ("1 - a 和 b 有相同的标识")
else:
print ("1 - a 和 b 没有相同的标识")
if ( id(a) == id(b) ):
print ("2 - a 和 b 有相同的标识")
else:
print ("2 - a 和 b 没有相同的标识")
# 修改变量 b 的值
b = 30
if ( a is b ):
print ("3 - a 和 b 有相同的标识")
else:
print ("3 - a 和 b 没有相同的标识")
if ( a is not b ):
print ("4 - a 和 b 没有相同的标识")
else:
print ("4 - a 和 b 有相同的标识")
结果
1 - a 和 b 有相同的标识
2 - a 和 b 有相同的标识
3 - a 和 b 没有相同的标识
4 - a 和 b 没有相同的标识
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
>>>a = [1, 2, 3]
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True
数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 返回以e为底的对数。如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) |
返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 (a,b) = math.modf(114.514),则a = 0.514,b = 114.0 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) |
返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。 其实准确的说是保留值将保留到离上一位更近的一端。 |
| sqrt(x) | 返回数字x的平方根。 |
随机数函数
Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) |
从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 print ("从 range(100) 返回一个随机数 : ",random.choice(range(100))) |
| randrange ([start,] stop [,step]) |
从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 # 从 1-100 中选取一个奇数 print ("randrange(1,100, 2) : ", random.randrange(1, 100, 2)) # 从 0-99 选取一个随机数 print ("randrange(100) : ", random.randrange(100)) |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) |
改变随机数生成器的种子seed。 random.seed(10) random.seed("hello",2) |
| shuffle(lst) |
将序列的所有元素随机排序 list = [20, 16, 10, 5]; random.shuffle(list) print ("随机排序列表 : ", list) |
| uniform(x, y) |
随机生成下一个实数,它在[x,y]范围内。 random.uniform(x, y)
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号