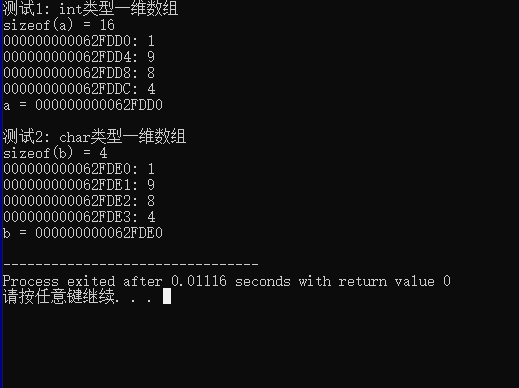
#include <stdio.h>
#define N 4
void test1() {
int a[N] = {1, 9, 8, 4};
int i;
// 输出数组a占用的内存字节数
printf("sizeof(a) = %d\n", sizeof(a));
// 输出int类型数组a中每个元素的地址、值
for (i = 0; i < N; ++i)
printf("%p: %d\n", &a[i], a[i]);
// 输出数组名a对应的值
printf("a = %p\n", a);
}
void test2() {
char b[N] = {'1', '9', '8', '4'};
int i;
// 输出数组b占用的内存字节数
printf("sizeof(b) = %d\n", sizeof(b));
// 输出char类型数组b中每个元素的地址、值
for (i = 0; i < N; ++i)
printf("%p: %c\n", &b[i], b[i]);
// 输出数组名b对应的值
printf("b = %p\n", b);
}
int main() {
printf("测试1: int类型一维数组\n");
test1();
printf("\n测试2: char类型一维数组\n");
test2();
return 0;
}
![]()
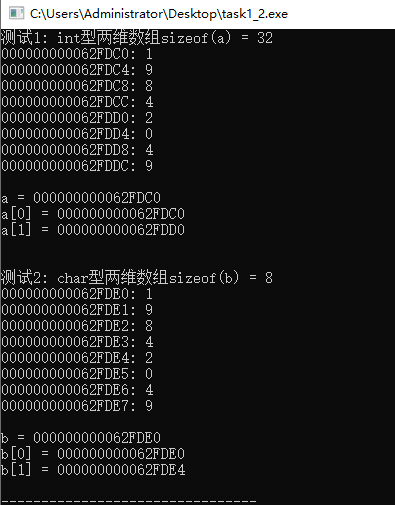
#include <stdio.h>
#define N 2
#define M 4
void test1() {
int a[N][M] = {{1, 9, 8, 4}, {2, 0, 4, 9}};
int i, j;
// 输出int类型二维数组a占用的内存字节数
printf("sizeof(a) = %d\n", sizeof(a));
// 输出int类型二维数组a中每个元素的地址、值
for (i = 0; i < N; ++i)
for (j = 0; j < M; ++j)
printf("%p: %d\n", &a[i][j], a[i][j]);
printf("\n");
// 输出int类型二维数组名a, 以及,a[0], a[1]的值
printf("a = %p\n", a);
printf("a[0] = %p\n", a[0]);
printf("a[1] = %p\n", a[1]);
printf("\n");
}
void test2() {
char b[N][M] = {{'1', '9', '8', '4'}, {'2', '0', '4', '9'}};
int i, j;
// 输出char类型二维数组b占用的内存字节数
printf("sizeof(b) = %d\n", sizeof(b));
// 输出char类型二维数组b中每个元素的地址、值
for (i = 0; i < N; ++i)
for (j = 0; j < M; ++j)
printf("%p: %c\n", &b[i][j], b[i][j]);
printf("\n");
// 输出char类型二维数组名b, 以及,b[0], b[1]的值
printf("b = %p\n", b);
printf("b[0] = %p\n", b[0]);
printf("b[1] = %p\n", b[1]);
}
int main() {
printf("测试1: int型两维数组");
test1();
printf("\n测试2: char型两维数组");
test2();
return 0;
}
![]()
#include <stdio.h>
#include <string.h>
#define N 80
void swap_str(char s1[N], char s2[N]);
void test1();
void test2();
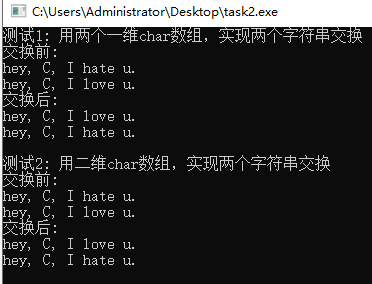
int main() {
printf("测试1: 用两个一维char数组,实现两个字符串交换\n");
test1();
printf("\n测试2: 用二维char数组,实现两个字符串交换\n");
test2();
return 0;
}
void test1() {
char views1[N] = "hey, C, I hate u.";
char views2[N] = "hey, C, I love u.";
printf("交换前: \n");
puts(views1);
puts(views2);
swap_str(views1, views2);
printf("交换后: \n");
puts(views1);
puts(views2);
}
void test2() {
char views[2][N] = {"hey, C, I hate u.",
"hey, C, I love u."};
printf("交换前: \n");
puts(views[0]);
puts(views[1]);
swap_str(views[0], views[1]);
printf("交换后: \n");
puts(views[0]);
puts(views[1]);
}
void swap_str(char s1[N], char s2[N]) {
char tmp[N];
strcpy(tmp, s1);
strcpy(s1, s2);
strcpy(s2, tmp);
}
![]()
2. 去掉了不必要的中间变量
*/
#include <stdio.h>
#define N 80
int count(char x[]);
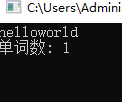
int main() {
char words[N+1];
int n;
while(gets(words) != NULL) {
n = count(words);
printf("单词数: %d\n\n", n);
}
return 0;
}
int count(char x[]) {
int i;
int word_flag = 0; // 用作单词标志,一个新单词开始,值为1;单词结束,值为0
int number = 0; // 统计单词个数
for(i = 0; x[i] != '\0'; i++) {
if(x[i] == ' ')
word_flag = 0;
else if(word_flag == 0) {
word_flag = 1;
number++;
}
}
return number;
}
![]()
/*
输入一行英文文本,统计最长单词,并打印输出。
为简化问题,只考虑单词之间用空格间隔的情形。
相较于教材例5.24,做了以下改动:
1. 增加了多组输入,因此,一些变量初始化放到了第一层循环里面
2. 微调了代码书写逻辑和顺序
*/
#include <stdio.h>
#define N 1000
int main() {
char line[N];
int word_len; // 记录当前单词长度
int max_len; // 记录最长单词长度
int end; // 记录最长单词结束位置
int i;
while(gets(line) != NULL) {
word_len = 0;
max_len = 0;
end = 0;
i = 0;
while(1) {
// 跳过连续空格
while(line[i] == ' ') {
word_len = 0; // 单词长度置0,为新单词统计做准备
i++;
}
// 在一个单词中,统计当前单词长度
while(line[i] != '\0' && line[i] != ' ') {
word_len++;
i++;
}
// 更新更长单词长度,并,记录最长单词结束位置
if(max_len < word_len) {
max_len = word_len;
end = i; // end保存的是单词结束的下一个坐标位置
}
// 遍历到文本结束时,终止循环
if(line[i] == '\0')
break;
}
// 输出最长单词
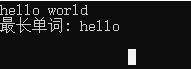
printf("最长单词: ");
for(i = end - max_len; i < end; ++i)
printf("%c", line[i]);
printf("\n\n");
}
return 0;
}
![]()
#include <stdio.h>
#define N 100
void dec_to_n(int x, int n); // 函数声明
int main() {
int x;
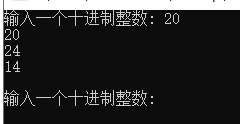
printf("输入一个十进制整数: ");
while(scanf("%d", &x) != EOF) {
dec_to_n(x, 2); // 函数调用: 把x转换成二进制输出
dec_to_n(x, 8); // 函数调用: 把x转换成八进制输出
dec_to_n(x, 16); // 函数调用: 把x转换成十六进制输出
printf("\n输入一个十进制整数: ");
}
return 0;
}
void dec_to_n(int x, int n){
if(n==2){
printf("%d\n",x);
}
else if(n==8){
printf("%o\n",x);
}
else
printf("%x\n",x);
}
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号