Linux常用命令大全
系统信息
arch 显示机器的处理器架构
uname -m 显示机器的处理器架构
uname -r 显示正在使用的内核版本
dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI)
hdparm -i /dev/hda 罗列一个磁盘的架构特性
hdparm -tT /dev/sda 在磁盘上执行测试性读取操作
cat /proc/cpuinfo 显示CPU info的信息
cat /proc/interrupts 显示中断
cat /proc/meminfo 校验内存使用
cat /proc/swaps 显示哪些swap被使用
cat /proc/version 显示内核的版本
cat /proc/net/dev 显示网络适配器及统计
cat /proc/mounts 显示已加载的文件系统
lspci -tv 罗列 PCI 设备
lsusb -tv 显示 USB 设备
date 显示系统日期
cal 2007 显示2007年的日历表
date 041217002007.00 设置日期和时间 - 月日时分年.秒
clock -w 将时间修改保存到 BIOS
关机 (系统的关机、重启以及登出 )
shutdown -h now 关闭系统
init 0 关闭系统
telinit 0 关闭系统
shutdown -h hours:minutes & 按预定时间关闭系统
shutdown -c 取消按预定时间关闭系统
shutdown -r now 重启
reboot 重启
logout 注销
文件和目录
cd /home 进入 '/ home' 目录'
cd .. 返回上一级目录
cd ../.. 返回上两级目录
cd 进入个人的主目录
cd ~user1 进入个人的主目录
cd - 返回上次所在的目录
pwd 显示工作路径
ls 查看目录中的文件
ls -F 查看目录中的文件
ls -l 显示文件和目录的详细资料
ls -a 显示隐藏文件
ls *[0-9]* 显示包含数字的文件名和目录名
tree 显示文件和目录由根目录开始的树形结构
lstree 显示文件和目录由根目录开始的树形结构
mkdir dir1 创建一个叫做 'dir1' 的目录'
mkdir dir1 dir2 同时创建两个目录
mkdir -p /tmp/dir1/dir2 创建一个目录树
rm -f file1 删除一个叫做 'file1' 的文件'
rmdir dir1 删除一个叫做 'dir1' 的目录'
rm -rf dir1 删除一个叫做 'dir1' 的目录并同时删除其内容
rm -rf dir1 dir2 同时删除两个目录及它们的内容
mv dir1 new_dir 重命名/移动 一个目录
cp file1 file2 复制一个文件
cp dir/* . 复制一个目录下的所有文件到当前工作目录
cp -a /tmp/dir1 . 复制一个目录到当前工作目录
cp -a dir1 dir2 复制一个目录
ln -s file1 lnk1 创建一个指向文件或目录的软链接
ln file1 lnk1 创建一个指向文件或目录的物理链接
touch -t 0712250000 file1 修改一个文件或目录的时间戳 - (YYMMDDhhmm)
file file1 outputs the mime type of the file as text
iconv -l 列出已知的编码
iconv -f fromEncoding -t toEncoding inputFile > outputFile creates a new from the given input file by assuming it is encoded in fromEncoding and converting it to toEncoding.
find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; batch resize files in the current directory and send them to a thumbnails directory (requires convert from Imagemagick)
文件搜索
find / -name file1 从 '/' 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 'user1' 的文件和目录
find /home/user1 -name \*.bin 在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
find / -name \*.rpm -exec chmod 755 '{}' \; 搜索以 '.rpm' 结尾的文件并定义其权限
find / -xdev -name \*.rpm 搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备
locate \*.ps 寻找以 '.ps' 结尾的文件 - 先运行 'updatedb' 命令
whereis halt 显示一个二进制文件、源码或man的位置
which halt 显示一个二进制文件或可执行文件的完整路径
挂载一个文件系统
mount /dev/hda2 /mnt/hda2 挂载一个叫做hda2的盘 - 确定目录 '/ mnt/hda2' 已经存在
umount /dev/hda2 卸载一个叫做hda2的盘 - 先从挂载点 '/ mnt/hda2' 退出
fuser -km /mnt/hda2 当设备繁忙时强制卸载
umount -n /mnt/hda2 运行卸载操作而不写入 /etc/mtab 文件- 当文件为只读或当磁盘写满时非常有用
mount /dev/fd0 /mnt/floppy 挂载一个软盘
mount /dev/cdrom /mnt/cdrom 挂载一个cdrom或dvdrom
mount /dev/hdc /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount /dev/hdb /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount -o loop file.iso /mnt/cdrom 挂载一个文件或ISO镜像文件
mount -t vfat /dev/hda5 /mnt/hda5 挂载一个Windows FAT32文件系统
mount /dev/sda1 /mnt/usbdisk 挂载一个usb 捷盘或闪存设备
mount -t smbfs -o username=user,password=pass //WinClient/share /mnt/share 挂载一个windows网络共享
磁盘空间
df -h 显示已经挂载的分区列表
ls -lSr |more 以尺寸大小排列文件和目录
du -sh dir1 估算目录 'dir1' 已经使用的磁盘空间'
du -sk * | sort -rn 以容量大小为依据依次显示文件和目录的大小
rpm -q -a --qf '%10{SIZE}t%{NAME}n' | sort -k1,1n 以大小为依据依次显示已安装的rpm包所使用的空间 (fedora, redhat类系统)
dpkg-query -W -f='${Installed-Size;10}t${Package}n' | sort -k1,1n 以大小为依据显示已安装的deb包所使用的空间 (ubuntu, debian类系统)
用户和群组
groupadd group_name 创建一个新用户组
groupdel group_name 删除一个用户组
groupmod -n new_group_name old_group_name 重命名一个用户组
useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 "admin" 用户组的用户
useradd user1 创建一个新用户
userdel -r user1 删除一个用户 ( '-r' 排除主目录)
usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
passwd 修改口令
passwd user1 修改一个用户的口令 (只允许root执行)
chage -E 2005-12-31 user1 设置用户口令的失效期限
pwck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的用户
grpck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的群组
newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
文件的权限 - 使用 "+" 设置权限,使用 "-" 用于取消
ls -lh 显示权限
ls /tmp | pr -T5 -W$COLUMNS 将终端划分成5栏显示
chmod ugo+rwx directory1 设置目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限
chmod go-rwx directory1 删除群组(g)与其他人(o)对目录的读写执行权限
chown user1 file1 改变一个文件的所有人属性
chown -R user1 directory1 改变一个目录的所有人属性并同时改变改目录下所有文件的属性
chgrp group1 file1 改变文件的群组
chown user1:group1 file1 改变一个文件的所有人和群组属性
find / -perm -u+s 罗列一个系统中所有使用了SUID控制的文件
chmod u+s /bin/file1 设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限
chmod u-s /bin/file1 禁用一个二进制文件的 SUID位
chmod g+s /home/public 设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的
chmod g-s /home/public 禁用一个目录的 SGID 位
chmod o+t /home/public 设置一个文件的 STIKY 位 - 只允许合法所有人删除文件
chmod o-t /home/public 禁用一个目录的 STIKY 位
文件的特殊属性 - 使用 "+" 设置权限,使用 "-" 用于取消
chattr +a file1 只允许以追加方式读写文件
chattr +c file1 允许这个文件能被内核自动压缩/解压
chattr +d file1 在进行文件系统备份时,dump程序将忽略这个文件
chattr +i file1 设置成不可变的文件,不能被删除、修改、重命名或者链接
chattr +s file1 允许一个文件被安全地删除
chattr +S file1 一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘
chattr +u file1 若文件被删除,系统会允许你在以后恢复这个被删除的文件
lsattr 显示特殊的属性
打包和压缩文件
bunzip2 file1.bz2 解压一个叫做 'file1.bz2'的文件
bzip2 file1 压缩一个叫做 'file1' 的文件
gunzip file1.gz 解压一个叫做 'file1.gz'的文件
gzip file1 压缩一个叫做 'file1'的文件
gzip -9 file1 最大程度压缩
rar a file1.rar test_file 创建一个叫做 'file1.rar' 的包
rar a file1.rar file1 file2 dir1 同时压缩 'file1', 'file2' 以及目录 'dir1'
unrar x file1.rar 解压rar包
tar -cvf archive.tar file1 创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar 显示一个包中的内容
tar -xvf archive.tar 释放一个包
tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp目录下
tar -cvfj archive.tar.bz2 dir1 创建一个bzip2格式的压缩包
tar -jxvf archive.tar.bz2 解压一个bzip2格式的压缩包
tar -cvfz archive.tar.gz dir1 创建一个gzip格式的压缩包
tar -zxvf archive.tar.gz 解压一个gzip格式的压缩包
zip file1.zip file1 创建一个zip格式的压缩包
zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
unzip file1.zip 解压一个zip格式压缩包
RPM 包 - (Fedora, Redhat及类似系统)
rpm -ivh package.rpm 安装一个rpm包
rpm -ivh --nodeeps package.rpm 安装一个rpm包而忽略依赖关系警告
rpm -U package.rpm 更新一个rpm包但不改变其配置文件
rpm -F package.rpm 更新一个确定已经安装的rpm包
rpm -e package_name.rpm 删除一个rpm包
rpm -qa 显示系统中所有已经安装的rpm包
rpm -qa | grep httpd 显示所有名称中包含 "httpd" 字样的rpm包
rpm -qi package_name 获取一个已安装包的特殊信息
rpm -qg "System Environment/Daemons" 显示一个组件的rpm包
rpm -ql package_name 显示一个已经安装的rpm包提供的文件列表
rpm -qc package_name 显示一个已经安装的rpm包提供的配置文件列表
rpm -q package_name --whatrequires 显示与一个rpm包存在依赖关系的列表
rpm -q package_name --whatprovides 显示一个rpm包所占的体积
rpm -q package_name --scripts 显示在安装/删除期间所执行的脚本l
rpm -q package_name --changelog 显示一个rpm包的修改历史
rpm -qf /etc/httpd/conf/httpd.conf 确认所给的文件由哪个rpm包所提供
rpm -qp package.rpm -l 显示由一个尚未安装的rpm包提供的文件列表
rpm --import /media/cdrom/RPM-GPG-KEY 导入公钥数字证书
rpm --checksig package.rpm 确认一个rpm包的完整性
rpm -qa gpg-pubkey 确认已安装的所有rpm包的完整性
rpm -V package_name 检查文件尺寸、 许可、类型、所有者、群组、MD5检查以及最后修改时间
rpm -Va 检查系统中所有已安装的rpm包- 小心使用
rpm -Vp package.rpm 确认一个rpm包还未安装
rpm2cpio package.rpm | cpio --extract --make-directories *bin* 从一个rpm包运行可执行文件
rpm -ivh /usr/src/redhat/RPMS/`arch`/package.rpm 从一个rpm源码安装一个构建好的包
rpmbuild --rebuild package_name.src.rpm 从一个rpm源码构建一个 rpm 包
YUM 软件包升级器 - (Fedora, RedHat及类似系统)
yum install package_name 下载并安装一个rpm包
yum localinstall package_name.rpm 将安装一个rpm包,使用你自己的软件仓库为你解决所有依赖关系
yum update package_name.rpm 更新当前系统中所有安装的rpm包
yum update package_name 更新一个rpm包
yum remove package_name 删除一个rpm包
yum list 列出当前系统中安装的所有包
yum search package_name 在rpm仓库中搜寻软件包
yum clean packages 清理rpm缓存删除下载的包
yum clean headers 删除所有头文件
yum clean all 删除所有缓存的包和头文件
DEB 包 (Debian, Ubuntu 以及类似系统)
dpkg -i package.deb 安装/更新一个 deb 包
dpkg -r package_name 从系统删除一个 deb 包
dpkg -l 显示系统中所有已经安装的 deb 包
dpkg -l | grep httpd 显示所有名称中包含 "httpd" 字样的deb包
dpkg -s package_name 获得已经安装在系统中一个特殊包的信息
dpkg -L package_name 显示系统中已经安装的一个deb包所提供的文件列表
dpkg --contents package.deb 显示尚未安装的一个包所提供的文件列表
dpkg -S /bin/ping 确认所给的文件由哪个deb包提供
APT 软件工具 (Debian, Ubuntu 以及类似系统)
apt-get install package_name 安装/更新一个 deb 包
apt-cdrom install package_name 从光盘安装/更新一个 deb 包
apt-get update 升级列表中的软件包
apt-get upgrade 升级所有已安装的软件
apt-get remove package_name 从系统删除一个deb包
apt-get check 确认依赖的软件仓库正确
apt-get clean 从下载的软件包中清理缓存
apt-cache search searched-package 返回包含所要搜索字符串的软件包名称
查看文件内容
cat file1 从第一个字节开始正向查看文件的内容
tac file1 从最后一行开始反向查看一个文件的内容
more file1 查看一个长文件的内容
less file1 类似于 'more' 命令,但是它允许在文件中和正向操作一样的反向操作
head -2 file1 查看一个文件的前两行
tail -2 file1 查看一个文件的最后两行
tail -f /var/log/messages 实时查看被添加到一个文件中的内容
假设存在日志文件 hrun.log,查询的关键字为"新增用户":
根据关键字查看日志
cat hrun.log | grep "新增用户"
根据关键字查看后10行日志
cat hrun.log | grep "新增用户" -A 10
根据关键字查看前10行日志
cat hrun.log | grep "新增用户" -B 10
根据关键字查看前后10行日志,并显示出行号
cat -n hrun.log | grep "新增用户" -C 10
查看日志前 50 行
cat hrun.log | head -n 50
查看日志后 50 行,并显示出行号
cat -n hrun.log | tail -n 50
文本处理
cat file1 file2 ... | command <> file1_in.txt_or_file1_out.txt general syntax for text manipulation using PIPE, STDIN and STDOUT
cat file1 | command( sed, grep, awk, grep, etc...) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中
cat file1 | command( sed, grep, awk, grep, etc...) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
grep Aug /var/log/messages 在文件 '/var/log/messages'中查找关键词"Aug"
grep ^Aug /var/log/messages 在文件 '/var/log/messages'中查找以"Aug"开始的词汇
grep [0-9] /var/log/messages 选择 '/var/log/messages' 文件中所有包含数字的行
grep Aug -R /var/log/* 在目录 '/var/log' 及随后的目录中搜索字符串"Aug"
sed 's/stringa1/stringa2/g' example.txt 将example.txt文件中的 "string1" 替换成 "string2"
sed '/^$/d' example.txt 从example.txt文件中删除所有空白行
sed '/ *#/d; /^$/d' example.txt 从example.txt文件中删除所有注释和空白行
echo 'esempio' | tr '[:lower:]' '[:upper:]' 合并上下单元格内容
sed -e '1d' result.txt 从文件example.txt 中排除第一行
sed -n '/stringa1/p' 查看只包含词汇 "string1"的行
sed -e 's/ *$//' example.txt 删除每一行最后的空白字符
sed -e 's/stringa1//g' example.txt 从文档中只删除词汇 "string1" 并保留剩余全部
sed -n '1,5p;5q' example.txt 查看从第一行到第5行内容
sed -n '5p;5q' example.txt 查看第5行
sed -e 's/00*/0/g' example.txt 用单个零替换多个零
cat -n file1 标示文件的行数
cat example.txt | awk 'NR%2==1' 删除example.txt文件中的所有偶数行
echo a b c | awk '{print $1}' 查看一行第一栏
echo a b c | awk '{print $1,$3}' 查看一行的第一和第三栏
paste file1 file2 合并两个文件或两栏的内容
paste -d '+' file1 file2 合并两个文件或两栏的内容,中间用"+"区分
sort file1 file2 排序两个文件的内容
sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq -u 删除交集,留下其他的行
sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm -1 file1 file2 比较两个文件的内容只删除 'file1' 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 'file2' 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
字符设置和文件格式转换
dos2unix filedos.txt fileunix.txt 将一个文本文件的格式从MSDOS转换成UNIX
unix2dos fileunix.txt filedos.txt 将一个文本文件的格式从UNIX转换成MSDOS
recode ..HTML < page.txt > page.html 将一个文本文件转换成html
recode -l | more 显示所有允许的转换格式
文件系统分析
badblocks -v /dev/hda1 检查磁盘hda1上的坏磁块
fsck /dev/hda1 修复/检查hda1磁盘上linux文件系统的完整性
fsck.ext2 /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck -j /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.ext3 /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.vfat /dev/hda1 修复/检查hda1磁盘上fat文件系统的完整性
fsck.msdos /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
dosfsck /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
初始化一个文件系统
mkfs /dev/hda1 在hda1分区创建一个文件系统
mke2fs /dev/hda1 在hda1分区创建一个linux ext2的文件系统
mke2fs -j /dev/hda1 在hda1分区创建一个linux ext3(日志型)的文件系统
mkfs -t vfat 32 -F /dev/hda1 创建一个 FAT32 文件系统
fdformat -n /dev/fd0 格式化一个软盘
mkswap /dev/hda3 创建一个swap文件系统
SWAP文件系统
mkswap /dev/hda3 创建一个swap文件系统
swapon /dev/hda3 启用一个新的swap文件系统
swapon /dev/hda2 /dev/hdb3 启用两个swap分区
备份
dump -0aj -f /tmp/home0.bak /home 制作一个 '/home' 目录的完整备份
dump -1aj -f /tmp/home0.bak /home 制作一个 '/home' 目录的交互式备份
restore -if /tmp/home0.bak 还原一个交互式备份
rsync -rogpav --delete /home /tmp 同步两边的目录
rsync -rogpav -e ssh --delete /home ip_address:/tmp 通过SSH通道rsync
rsync -az -e ssh --delete ip_addr:/home/public /home/local 通过ssh和压缩将一个远程目录同步到本地目录
rsync -az -e ssh --delete /home/local ip_addr:/home/public 通过ssh和压缩将本地目录同步到远程目录
dd bs=1M if=/dev/hda | gzip | ssh user@ip_addr 'dd of=hda.gz' 通过ssh在远程主机上执行一次备份本地磁盘的操作
dd if=/dev/sda of=/tmp/file1 备份磁盘内容到一个文件
tar -Puf backup.tar /home/user 执行一次对 '/home/user' 目录的交互式备份操作
( cd /tmp/local/ && tar c . ) | ssh -C user@ip_addr 'cd /home/share/ && tar x -p' 通过ssh在远程目录中复制一个目录内容
( tar c /home ) | ssh -C user@ip_addr 'cd /home/backup-home && tar x -p' 通过ssh在远程目录中复制一个本地目录
tar cf - . | (cd /tmp/backup ; tar xf - ) 本地将一个目录复制到另一个地方,保留原有权限及链接
find /home/user1 -name '*.txt' | xargs cp -av --target-directory=/home/backup/ --parents 从一个目录查找并复制所有以 '.txt' 结尾的文件到另一个目录
find /var/log -name '*.log' | tar cv --files-from=- | bzip2 > log.tar.bz2 查找所有以 '.log' 结尾的文件并做成一个bzip包
dd if=/dev/hda of=/dev/fd0 bs=512 count=1 做一个将 MBR (Master Boot Record)内容复制到软盘的动作
dd if=/dev/fd0 of=/dev/hda bs=512 count=1 从已经保存到软盘的备份中恢复MBR内容
光盘
cdrecord -v gracetime=2 dev=/dev/cdrom -eject blank=fast -force 清空一个可复写的光盘内容
mkisofs /dev/cdrom > cd.iso 在磁盘上创建一个光盘的iso镜像文件
mkisofs /dev/cdrom | gzip > cd_iso.gz 在磁盘上创建一个压缩了的光盘iso镜像文件
mkisofs -J -allow-leading-dots -R -V "Label CD" -iso-level 4 -o ./cd.iso data_cd 创建一个目录的iso镜像文件
cdrecord -v dev=/dev/cdrom cd.iso 刻录一个ISO镜像文件
gzip -dc cd_iso.gz | cdrecord dev=/dev/cdrom - 刻录一个压缩了的ISO镜像文件
mount -o loop cd.iso /mnt/iso 挂载一个ISO镜像文件
cd-paranoia -B 从一个CD光盘转录音轨到 wav 文件中
cd-paranoia -- "-3" 从一个CD光盘转录音轨到 wav 文件中(参数-3)
cdrecord --scanbus 扫描总线以识别scsi通道
dd if=/dev/hdc | md5sum 校验一个设备的md5sum编码,例如一张 CD
网络 - (以太网和WIFI无线)
ifconfig eth0 显示一个以太网卡的配置
ifup eth0 启用一个 'eth0' 网络设备
ifdown eth0 禁用一个 'eth0' 网络设备
ifconfig eth0 192.168.1.1 netmask 255.255.255.0 控制IP地址
ifconfig eth0 promisc 设置 'eth0' 成混杂模式以嗅探数据包 (sniffing)
dhclient eth0 以dhcp模式启用 'eth0'
route -n show routing table
route add -net 0/0 gw IP_Gateway configura default gateway
route add -net 192.168.0.0 netmask 255.255.0.0 gw 192.168.1.1 configure static route to reach network '192.168.0.0/16'
route del 0/0 gw IP_gateway remove static route
echo "1" > /proc/sys/net/ipv4/ip_forward activate ip routing
hostname show hostname of system
host www.example.com lookup hostname to resolve name to ip address and viceversa
nslookup www.example.com lookup hostname to resolve name to ip address and viceversa
ip link show show link status of all interfaces
mii-tool eth0 show link status of 'eth0'
ethtool eth0 show statistics of network card 'eth0'
netstat -tup show all active network connections and their PID
netstat -tupl show all network services listening on the system and their PID
tcpdump tcp port 80 show all HTTP traffic
iwlist scan show wireless networks
iwconfig eth1 show configuration of a wireless network card
hostname show hostname
host www.example.com lookup hostname to resolve name to ip address and viceversa
nslookup www.example.com lookup hostname to resolve name to ip address and viceversa
whois www.example.com lookup on Whois database
JPS工具
jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上简单察看当前java进程的一些简单情况。
我想很多人都是用过unix系统里的ps命令,这个命令主要是用来显示当前系统的进程情况,有哪些进程,及其 id。 jps 也是一样,它的作用是显示当前系统的java进程情况,及其id号。我们可以通过它来查看我们到底启动了几个java进程(因为每一个java程序都会独占一个java虚拟机实例),和他们的进程号(为下面几个程序做准备),并可通过opt来查看这些进程的详细启动参数。
使用方法:在当前命令行下打 jps(需要JAVA_HOME,没有的话,到改程序的目录下打) 。
jps存放在JAVA_HOME/bin/jps,使用时为了方便请将JAVA_HOME/bin/加入到Path.
$> jps
23991 Jps
23789 BossMain
23651 Resin
比较常用的参数:
-q 只显示pid,不显示class名称,jar文件名和传递给main 方法的参数
$> jps -q
28680
23789
23651
-m 输出传递给main 方法的参数,在嵌入式jvm上可能是null
$> jps -m
28715 Jps -m
23789 BossMain
23651 Resin -socketwait 32768 -stdout /data/aoxj/resin/log/stdout.log -stderr /data/aoxj/resin/log/stderr.log
-l 输出应用程序main class的完整package名 或者 应用程序的jar文件完整路径名
$> jps -l
28729 sun.tools.jps.Jps
23789 com.asiainfo.aimc.bossbi.BossMain
23651 com.caucho.server.resin.Resin
-v 输出传递给JVM的参数
$> jps -v
23789 BossMain
28802 Jps -Denv.class.path=/data/aoxj/bossbi/twsecurity/java/trustwork140.jar:/data/aoxj/bossbi/twsecurity/java/:/data/aoxj/bossbi/twsecurity/java/twcmcc.jar:/data/aoxj/jdk15/lib/rt.jar:/data/aoxj/jd
k15/lib/tools.jar -Dapplication.home=/data/aoxj/jdk15 -Xms8m
23651 Resin -Xss1m -Dresin.home=/data/aoxj/resin -Dserver.root=/data/aoxj/resin -Djava.util.logging.manager=com.caucho.log.LogManagerImpl -
Djavax.management.builder.initial=com.caucho.jmx.MBeanServerBuilderImpl
sudo jps看到的进程数量最全
jps 192.168.0.77
列出远程服务器192.168.0.77机器所有的jvm实例,采用rmi协议,默认连接端口为1099
(前提是远程服务器提供jstatd服务)
注:jps命令有个地方很不好,似乎只能显示当前用户的java进程,要显示其他用户的还是只能用unix/linux的ps命令。
ps -ef|grep详解
ps命令将某个进程显示出来
grep命令是查找
中间的|是管道命令 是指ps命令与grep同时执行
PS是LINUX下最常用的也是非常强大的进程查看命令
grep命令是查找,是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
以下这条命令是检查java 进程是否存在:ps -ef |grep java
下面对命令选项进行说明:
-e 显示所有进程。
-f 全格式。
-h 不显示标题。
-l 长格式。
-w 宽输出。
a 显示终端上的所有进程,包括其他用户的进程。
r 只显示正在运行的进程。
u 以用户为主的格式来显示程序状况。
x 显示所有程序,不以终端机来区分。
ps -l 列出与本次登录有关的进程信息;
ps -aux 查询内存中进程信息;
ps -aux | grep *** 查询***进程的详细信息;
top 查看内存中进程的动态信息;
kill -9 pid 杀死进程。
字段含义如下:
UID PID PPID C STIME TTY TIME CMD
zzw 14124 13991 0 00:38 pts/0 00:00:00 grep --color=auto dae
UID :程序被该 UID 所拥有
PID :就是这个程序的 ID
PPID :则是其上级父程序的ID
C :CPU使用的资源百分比
STIME :系统启动时间
TTY :登入者的终端机位置
TIME :使用掉的CPU时间。
CMD :所下达的是什么指令
Linux top命令的用法详细详解
首先介绍top中一些字段的含义:
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来
DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下:
s – 改变画面更新频率
l – 关闭或开启第一部分第一行 top 信息的表示
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N – 以 PID 的大小的顺序排列表示进程列表
P – 以 CPU 占用率大小的顺序排列进程列表
M – 以内存占用率大小的顺序排列进程列表
h – 显示帮助
n – 设置在进程列表所显示进程的数量
q – 退出 top
s – 改变画面更新周期
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
top使用方法:
使用格式:
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明:
d:指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p:通过指定监控进程ID来仅仅监控某个进程的状态。
q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S:指定累计模式。
s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i:使top不显示任何闲置或者僵死进程。
c:显示整个命令行而不只是显示命令名。
常用命令说明:
Ctrl+L:擦除并且重写屏幕
K:终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i:忽略闲置和僵死进程。这是一个开关式命令。
q:退出程序
r:重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S:切换到累计模式。
s:改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F:从当前显示中添加或者删除项目。
o或者O:改变显示项目的顺序
l:切换显示平均负载和启动时间信息。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据驻留内存大小进行排序。
P:根据CPU使用百分比大小进行排序。
T:根据时间/累计时间进行排序。
W:将当前设置写入~/.toprc文件中。
查看多核CPU命令
mpstat -P ALL 和 sar -P ALL
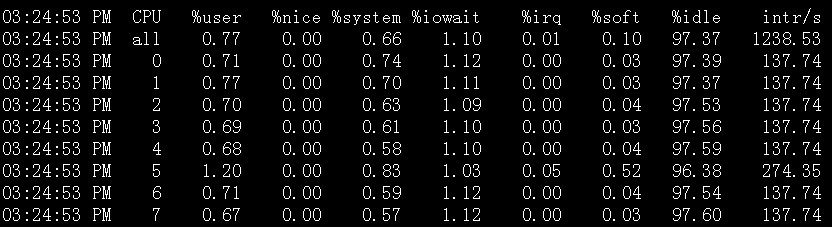
说明:sar -P ALL > aaa.txt 重定向输出内容到文件 aaa.txt
top命令经常用来监控Linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。
本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。
输入top命令
1.1 系统运行时间和平均负载:
- 当前时间
- 系统已运行的时间
- 当前登录用户的数量
- 相应最近5、10和15分钟内的平均负载。
可以使用'l'命令切换uptime的显示。
21:45:11 — 当前系统时间
0 days, 4:54 — 系统已经运行了4小时54分钟(在这期间没有重启过)
2 users — 当前有2个用户登录系统
load average:0.24, 0.15, 0.19 — load average后面的三个数分别是5分钟、10分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
- us, user: 运行(未调整优先级的) 用户进程的CPU时间
- sy,system: 运行内核进程的CPU时间
- ni,niced:运行已调整优先级的用户进程的CPU时间
- wa,IO wait: 用于等待IO完成的CPU时间
- hi:处理硬件中断的CPU时间
- si: 处理软件中断的CPU时间
- st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)。
可以使用't'命令切换显示。
1.3% us — 用户空间占用CPU的百分比。1.0% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
97.3% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.3% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。
接下来两行显示内存使用率,有点像'free'命令。第一行是物理内存使用,第二行是虚拟内存使用(交换空间)。
物理内存显示如下:全部可用内存、已使用内存、空闲内存、缓冲内存。相似地:交换部分显示的是:全部、已使用、空闲和缓冲交换空间。
内存显示可以用'm'命令切换。
509248k total — 物理内存总量(509M)495964k used — 使用中的内存总量(495M)
13284k free — 空闲内存总量(13M)
25364k buffers — 缓存的内存量 (25M)
swap交换分区
492536k total — 交换区总量(492M)
11856k used — 使用的交换区总量(11M)
480680k free — 空闲交换区总量(480M)
202224k cached — 缓冲的交换区总量(202M)
这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器“危矣”:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:
13284+25364+202224 = 240M。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
PID:进程ID,进程的唯一标识符
USER:进程所有者的实际用户名。
PR:进程的调度优先级。这个字段的一些值是'rt'。这意味这这些进程运行在实时态。
NI:进程的nice值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级
VIRT:进程使用的虚拟内存。进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES:驻留内存大小。驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR:SHR是进程使用的共享内存。共享内存大小,单位kb
S:这个是进程的状态。它有以下不同的值:
- D - 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
%CPU:自从上一次更新时到现在任务所使用的CPU时间百分比。
%MEM:进程使用的可用物理内存百分比。
TIME+:任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。
COMMAND:运行进程所使用的命令。进程名称(命令名/命令行)
还有许多在默认情况下不会显示的输出,它们可以显示进程的页错误、有效组和组ID和其他更多的信息。
交互命令
2.1 ‘h’: 帮助
可以用h或?显示交互命令的帮助菜单。
2.2 ‘<ENTER>’ 或者 ‘<SPACE>’: 刷新显示
top命令默认在一个特定间隔(3秒)后刷新显示。要手动刷新,用户可以输入回车或者空格。
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:

top视图 02
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在【top视图 01】中进程ID为14210的Java进程排在第一(cpu占用100%),进程ID为14183的java进程排在第二(cpu占用12%)。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:
1. 敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:

top视图 03
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
2. 敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:

top视图 04
可以看到,top默认的排序列是“%CPU”。
3. 通过”shift + >”或”shift + <”可以向右或左改变排序列,下图是按一次”shift + >”的效果图:

top视图 05
视图现在已经按照%MEM来排序了。
改变进程显示字段
1. 敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:

top视图 06
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:

top视图 07
2. “回车”返回基本视图,可以看到多了“CODE”和“DATA”两个字段:

top视图 08
top命令的补充
top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。
ps -eLf | grep java | wc -l
netstat -n | grep tcp | grep 侦听端口 | wc -l
上面两个命令,可改动grep的参数,来达到更细致的监控要求。
在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l
在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID
linux服务器查看项目日志命令
1、tailf mywork.log | grep --line-buffered findUserList 实时跟踪日志,这里是只要findUserList 这个方法被运行,就会将它的日志打印出来,用于跟踪特定的日志运行。 --line-buffered 是一行的缓冲区,只要这一行的缓冲区满了就会打印出来,所以可以用于实时监控日志。
2、 tailf -n 500 mywork.log 打印最后500行日志,并且持续跟踪日志。
tail -n 2000 mywork.log | more 分页查看最后2000行日志。
3、 grep '调用远程服务运行结果是' mywork.log | more 将有关 '调用远程服务运行结果是' 字符串的结果都打印出来,并且是分页打印,用于日志太多的情况。用空格翻页。
4、 cat mywork.log | grep '查看前后100行' -C 100
5、 cat mywork.log | grep '查看前100行' -B 100
6、 cat mywork.log | grep '查看后100行' -A 100
7、按照行号查看日志
wc -l mainCms.log 显示文件一共有多少行。
cat -n mywork.log | tail -n +92|head -n 20 表示先查看92行之后的日志,然后在看这92行之后的日志的前20行。也就是查看92到112行之间的日志。
sed -n '5,10p' mywork.log 查看5行到10行的日志。
8、按日期查看日志
sed -n '/2018-05-26 17:07:00/,/2018-05-26 17:06:59/p' mywork.log
sed -n '/2018-08-16 18:/p' mainCms.log | less -mN
grep -E '123|abc' mywok.log 找出包含123或者abc的行。
转载:https://www.cnblogs.com/zhoug2020/p/6336453.html
转载:https://www.cnblogs.com/yjd_hycf_space/p/7730690.html
详细情况请参考sun官方文档:http://java.sun.com/j2se/1.7.0/docs/tooldocs/share/jps.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号