redis介绍
# 介绍 c s 架构的软件
redis:非关系型数据库【存数据的地方】nosql数据库,内存存储,速度非常快,可以持久化【数据从内存同步到硬盘】,数据类型丰富【5大数据类型:字符串,列表,哈希(字典),集合,有序集合】,key-value形式存储【根本没有表的结构,相当于咱们的字典】
-nosql:指非关系型数据库:1 不限于SQL 2 没有sql
# redis 为什么这么快
-1 高性能的网络模型:IO多路复用的epoll模型,承载住非常高的并发量
-2 纯内存操作,避免了很多io
-3 单线程架构,避免了线程间切换的消耗
-6.x之前:单线程,单进程
-6.x以后,多线程架构,数据操作还是使用单线程,别的线程做数据持久化,其他操作
# redis 应用场景(了解)
1 当缓存数据库使用,接口缓存,提高接口响应速度
-请求进到视图---》去数据查询[多表查询,去硬盘取数据:速度慢]----》转成json格式字符串---》返回给前端
-请求进到视图---》去redis[内存]----》取json格式字符串---》返回给前端
2 做计数器:单线程,不存在并发安全问题
-统计网站访问量
-个人站点浏览量
-文章阅读量
3 去重操作:集合
4 排行榜:有序集合
-阅读排行榜
-游戏金币排行榜
5 布隆过滤器
6 抽奖
7 消息队列
python操作redis
# pip3 install redis
from redis import Redis
conn=Redis( host="localhost",port=6379)
# conn.set('name','xxx')
print(conn.get('name'))
conn.close()
redis连接池
POOL.py
import redis
pool = redis.ConnectionPool(max_connections=200, host='127.0.0.1', port=6379)
redis.py
from threading import Thread
import time
import redis
from POOL import pool
def get_value():
# 在文件创建连接池以保证单列模式全局只有一个pool对象
# 每执行一次从池中获取一个连接如果没有则等待
coon = redis.Redis(connection_pool=pool)
res = coon.get('name')
print(res.decode())
coon.close()
for i in range(100): # 连接池不够则报错
t = Thread(target=get_value)
t.start()
import time
time.sleep(10)
redis五大数据类型的使用
字符串的使用
import redis
from POOL import pool
conn = redis.Redis(connection_pool=pool, decode_responses=True) # decode_responses=True修改编码
# conn.set('name','老男孩') # 设置键值对
# conn.set('name','老男孩',ex=4) # ex过期时间秒
# conn.set('name','老男孩',px=3000) # px过期时间毫秒
# conn.setnx('name','飞飞') # 设置值,只有name不存在时,执行设置操作(添加),如果存在,不会修改实现分布式锁
# conn.setex('age', 3, '三秒过期')
# conn.psetex('text', 6000, '4秒过期')
# conn.set('age',18,xx=True) # 存在才会设置不存在不执行
# conn.mset({'name':'老男孩','age':18,'address':'北京'}) # 批量设置字符串
# print(conn.get('name').decode('utf-8'))
# print(str(conn.get('name'),encoding='utf8'))
# print(conn.mget(['name', 'age'])) # 批量获取[b'\xe8\x80\x81\xe7\x94\xb7\xe5\xad\xa9q', b'18']
# print(conn.strlen('name')) # 统计字节
# conn.incr('age') # 自增
# conn.decr('age',2) # 自减
哈希操作
# conn.hset('userinfo',mapping={'name':'tony','age':15}) # 设置哈希值字典的形式
# print(conn.hget('userinfo','name')) # 获取一个值b'tony'
# print(conn.hmget('userinfo', ['name', 'age'])) # 批量取值[b'tony', b'15']
# print(conn.hgetall('userinfo')) # 获取所有造成阻塞生产中不要随意用{b'name': b'tony', b'age': b'15'}
# print(conn.hlen('userinfo')) # 获取键值对数 ---->2
# print(conn.hkeys('userinfo')) # 获取键 [b'name', b'age']
# print(conn.hvals('userinfo')) # 取出value值[b'tony', b'15']
# print(conn.hexists('userinfo', 'name')) # 判断键里是否有name键
# conn.hdel('userinfo','age') # 删除age键值对
# conn.hincrby('userinfo','age') #自增
# print(conn.hscan('userinfo', cursor=0, count=1)) # 分片取值分批
# print(conn.hscan_iter('userinfo')) # <generator object ScanCommands.hscan_iter at 0x108382580>
# count = 1
# for i in conn.hscan_iter('text', count=10): # 生成器for循环分批取值取完再取总数据100条每次取10条取10次执行完毕
# count += 1
# print('我执行了%s次' % (count // 10))
# print(i)
# for i in range(100):
# conn.hset('text',mapping={f'name{i}':f'女友{i}'}) # 插入多条数据键需要改变否则就是一直在改一个键值对的数据
列表
# 列表
# conn.lpush('girls','王宝强') # 左侧插入在顶部
# conn.lpush('girls','黄渤')
# conn.rpush('girls','刘寡妇') # 右侧插入在最下面
# conn.lpushx('boys','老八') # 无法插入键需存在才能插入
# conn.rpushx('boys','老八') # 无法插入键需存在才能插入
# print(conn.llen('girls')) # 查看列表长度
# conn.linsert('girls',where='after',refvalue='王寡妇',value='张寡妇') # 将王寡妇放在张寡妇前面
# conn.linsert('girls',where='before',refvalue='王寡妇',value='老王') # 将老王插入在王寡妇前
# conn.lset('girls',0,'郭德纲') # 按索引修改值
# conn.lrem('girls',1,'王寡妇') # 1表示删除左边第一个 0 表示全删 -1 表示右边第一
# conn.lpop('girls') # 左侧弹出
# print(conn.lindex('girls', 2)) # 获取索引对应的数据
# print(conn.lrange('girls', 0, 2)) # 范围获取数据 前闭后闭
# conn.ltrim('girls',0,2) # 修减除了 0-2 其他都不要了
# conn.rpoplpush('girls','boys') # 从第一个列表弹出追加到第二个列表
# conn.blpop('boys') # 阻塞弹出,列表中没有值等待有值后在弹出程序卡住 可以做消息队列timeout 参数控制时间一直没有None
其它操作
# 根据删除redis中的任意数据类型
delete(*names)
# 检测redis的name是否存在
exists(name)
# 根据模型获取redis的name
keys(pattern='*')
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
# 为某个redis的某个name设置超时时间
expire(name ,time)
# 对redis的name重命名为
rename(src, dst)
# 将redis的某个值移动到指定的库下
move(name, db))
# 随机获取一个redis的name(不删除)
randomkey()
# 获取name对应值的类型
type(name)
# 同字符串操作,用于增量迭代获取key
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
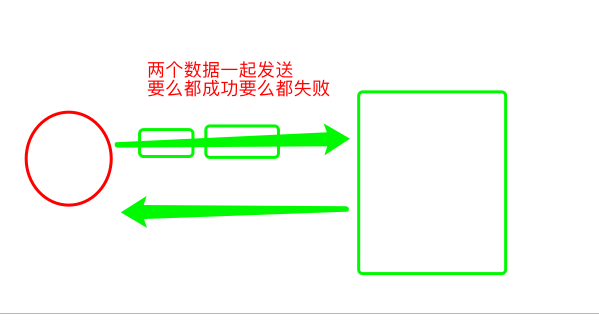
redis管道
import redis
conn = redis.Redis()
pipeline_redis = conn.pipeline(transaction=True) # 开启管道实现部分事物都功能,同时成功一个失败另一个也失败
pipeline_redis.decr('tony',2) # 减2
# raise Exception('我没了') # 失败
pipeline_redis.incr('jason',2) # 加2
pipeline_redis.execute()
conn.close()
![image]()
# mysql事务:四大特性 事务的隔离级别 mysql5.7 默认的隔离级别是什么
# redis:redis数据库,是否支持事务?
-支持
-不支持
# redis事务机制可以保证一致性和隔离性,无法保证持久性,但是对于redis而言,本身是内存数据库,所以持久化不是必须属性。原子性需要自己进行检查,尽可能保证
# redis 不像mysql一样,支持强事务,事务的四大特性不能全部满足,但是能满足一部分,通过redis的管道实现的
# redis本身不支持事务,但是可以通过管道,实现部分事务
# redis 通过管道,来保证命令要么都成功,要么都失败,完成事务的一致性,但是管道只能用在单实例,集群环境中,不支持pipline
django中集成redis
# 方式一:直接使用
from user.POOL import pool
import redis
def index(request):
conn = redis.Redis(connection_pool=pool)
conn.incr('page_view')
res = conn.get('page_view')
return HttpResponse('被你看了%s次' % res)
# 方式二:使用第三方模块:django-redis
-下载
-配置文件配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "123",
}
}
}
-使用
from django_redis import get_redis_connection
def index(request):
conn = get_redis_connection(alias="default") # 每次从池中取一个链接
conn.incr('page_view')
res = conn.get('page_view')
return HttpResponse('被你看了%s次' % res)
# 方式三:借助于django的缓存使用redis
-如果配置文件中配置了 CACHES ,以后django的缓存,数据直接放在redis中
-以后直接使用cache.set 设置值,可以传过期时间
-使用cache.get 获取值
-强大之处在于,可以直接缓存任意的python对象,底层使用pickle实现的
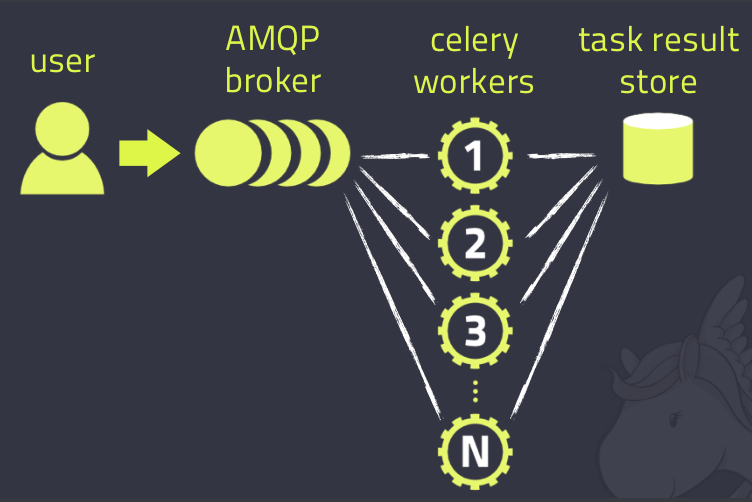
celery介绍
# celery:翻译过来叫芹菜,它是一个 分布式的异步任务 框架
# celery有什么用?
1 完成异步任务:可以提高项目的并发量,之前开启线程做,现在使用celery做
2 完成延迟任务
3 完成定时任务
# 架构
-消息中间件:broker 提交的任务(函数)都放在这里,celery本身不提供消息中间件,需要借助于第三方:redis,rabbitmq
-任务执行单元:worker,真正执行任务的地方,一个个进程,执行函数
-结果存储:backend,函数return的结果存储在这里,celery本身不提供结果存储,借助于第三方:redis,数据库,rabbitmq
![image]()
轮播图缓存获取
# 重写获取轮播图对象方法
# 如果缓存中有值则直接使用缓存的数据如果没有才走数据库查询并且将查询之后的数据存入缓存中下次来判断是否有值有值则直接使用
# 过滤没有被删除的,并且可以显示的,按orders做排序
from django.core.cache import cache
from django.db.models.query import QuerySet
def get_queryset(self):
res = cache.get('banner')
if res:
print('没走数据库')
queryset = res
else:
print('我走了数据库')
queryset = Banner.objects.all().filter(is_delete=False, is_show=True).order_by('orders')[
:settings.BANNER_COUNT]
cache.set('banner', queryset)
if isinstance(queryset, QuerySet):
queryset = queryset.all()
return queryset

 浙公网安备 33010602011771号
浙公网安备 33010602011771号