模块导入与开发目录规范

昨日内容
- 索引取值雨迭代取值的差异
- 索引取值:可以随意反复取值,但是对于无序的容器类型无法取值
- 迭代取值:提供一种不依赖索引的取值方式,可以对无序的容器类型取值一旦开始取值只能往前无法回退
两种取值方式各有各的优势和劣势,具体使用看具体情况结合实际情况使用
- 模块的简介
- 模块的概念:可以实现一系列功能的结合体
- 模块的作用:使用模块就相当于拥有这个结合体内的所有功能
- 模块的分类:内置模块,自定义模块,第三方模块
- 模块的来源:基于网络上存在的地方模块自定义模块与第三方模块可以互通
简称拿来主义
- 导入模块的语句
import ... 优点是不容易名字冲突可以使用所有名字,但有时候不想让人使用到所有的名字
from ... import ... 容易报错名字与执行文件中名字冲突,不需要加前缀使用
导入模块:首先产生执行文件的名称空间产生导入模块的名称空间并运行导入模块获取所有名字存储在导入模块的名称空间,执行名称空间中产生一个名字指向导入模块名称空间,可以通过点的方式用到导入模块名称空间中的所有名字
- 导入模块补充知识
- 起别名 impoer as 别名
- 多个模块的概念
from... import* 一次性导入所有名字 可以在导入模块中控制能用到的数据 all =[填写数据] 针对🌟的方式
- 循环导入
尽量不要循环导入问题,否则容易报错,无法避免的情况下提前准备好名字即可 - 模块的查找顺序
1.内存
2.内置模块
3.执行程序环境变量- 自定义模块名切记不可与内置模块名冲突,否则无法使用且容易报错
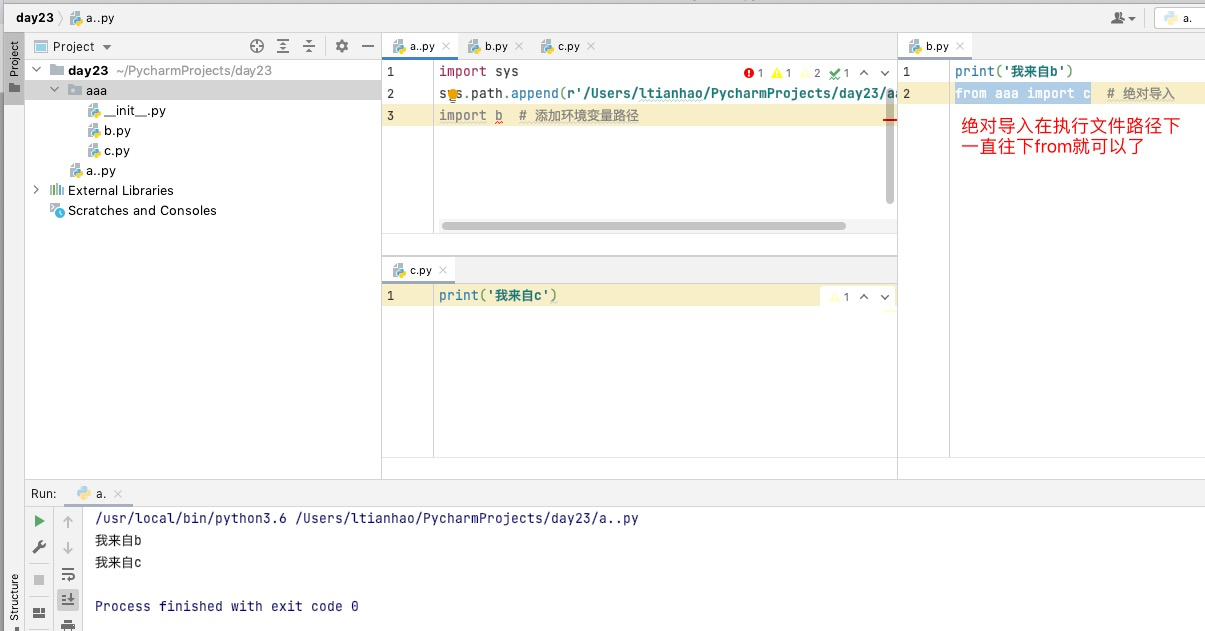
- 如何解决模块文件与执行文件不在一个sys.path的问题:
1.添加sys.path即可(添加执行程序环境变量)
2.from... import...(用绝对导入即可)
![image]()

今日内容
绝对导入与相对导入
"""
只要涉及模块的导入,那么sys.path永远以执行文件未准
"""
1.绝对导入:
其实就是以执行文件所在的sys.path为起始路径往下一层层导
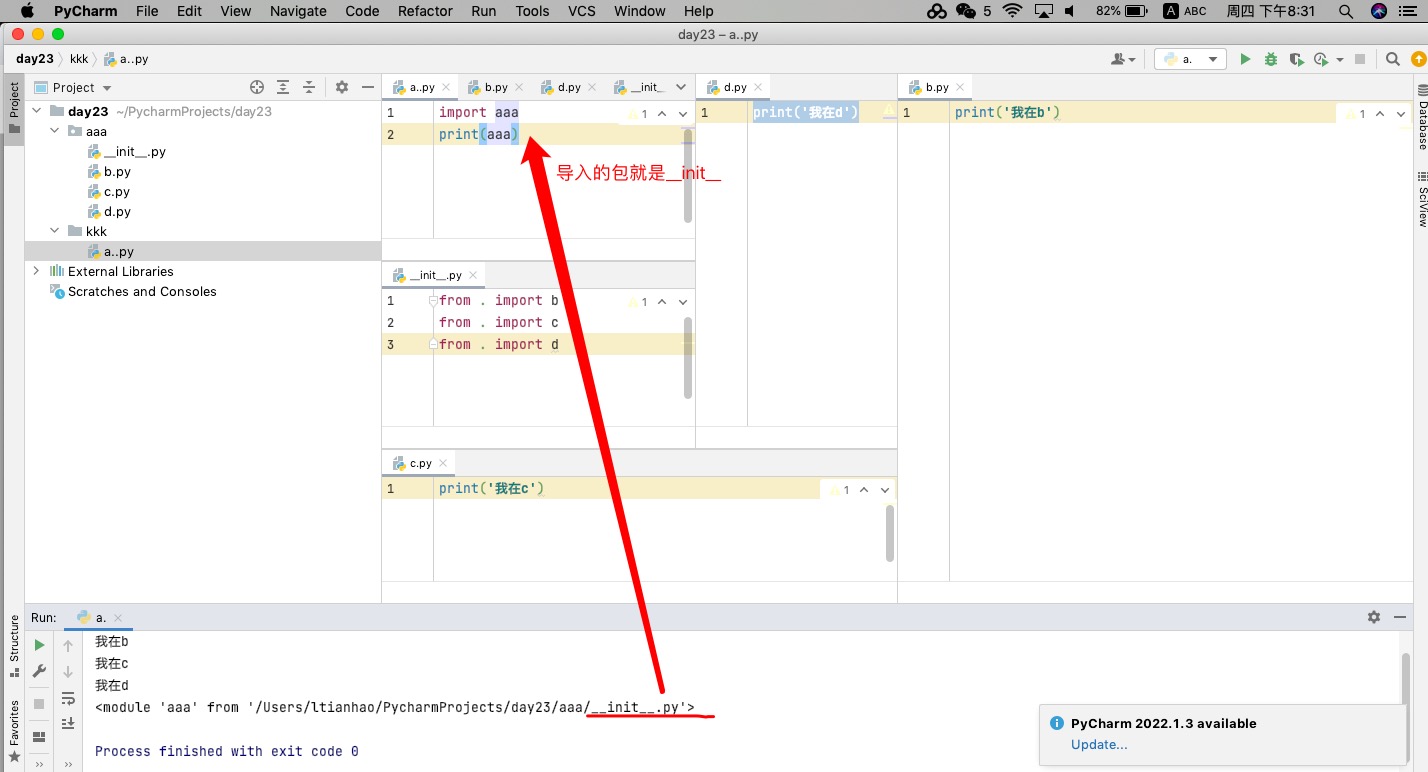
from aaa import c
from aaa.bbb.ccc import a
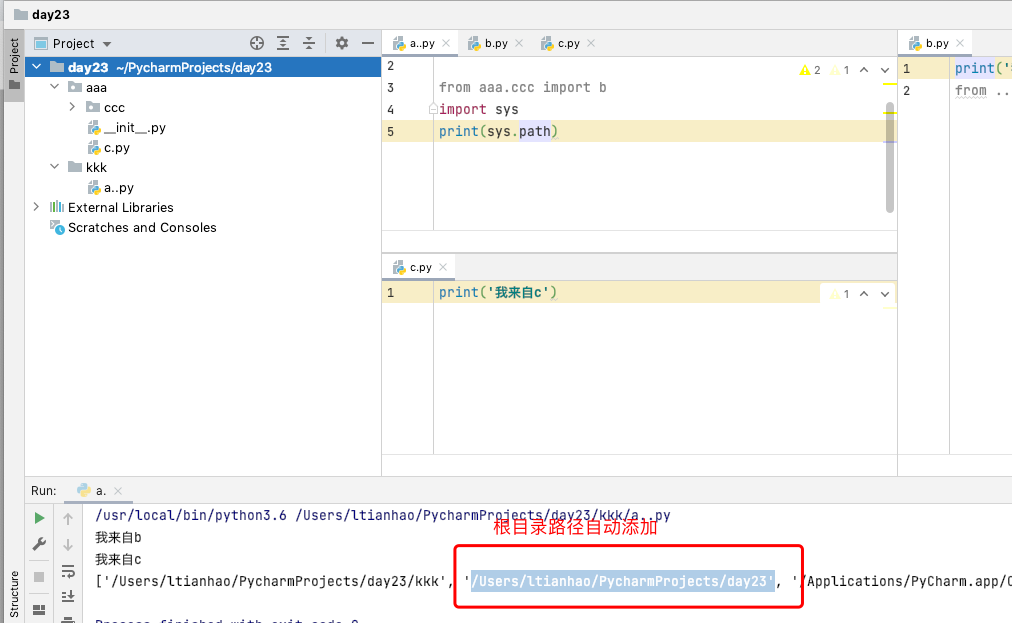
ps:由于pycharm会自动将根目录添加到sys.path中所以查找模块不报错的方法就是永远从根路径往下找
如果不是用pycharm运行需要将根目录添加到sys.path中(针对根目录有模块可以获取>>>os)
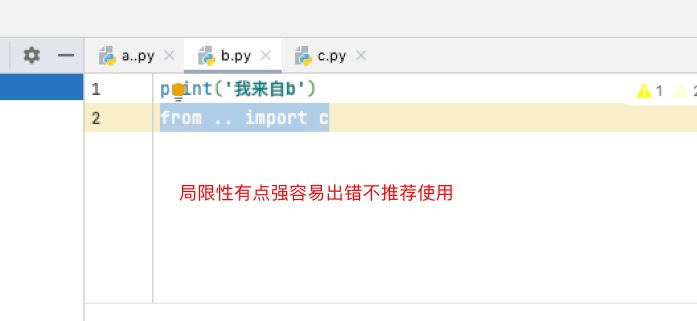
2.相对导入
符号在路径中的意思
. 在当前路径
..在上一层路径
../..在上上层路径
相对路径导入使用点的方式
from . import c # 导入模块的当前路径
from .. import c # 导入模块的上一层路径
from ../.. import c # 导入模块的上两层路径
"""
相对导入只能在模块中使用不能在执行文件中使用
相对导入在项目复杂的情况下容易出错
推荐使用绝对导入,不推荐使用相对导入
"""
- 执行文件的程序环境变量pycharm会自动把根目录添加到执行文件的sys.path中所以可以直接使用from导不再同一路径的文件
![image]()
包的概念
1.如何理解包
内部含有__init__.py的文件夹
直观就是一个文件夹
2.包的作用
内部存放多个py文件,模块文件,便于管理文件,分类存放
3.如何创建包
1.直接创建文件夹 内部创建__init__
2.直接创建包 Python Package
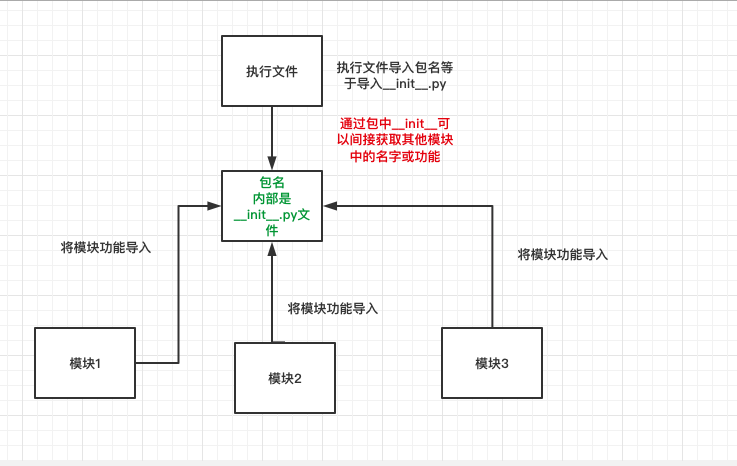
4.如何使用包内的模块
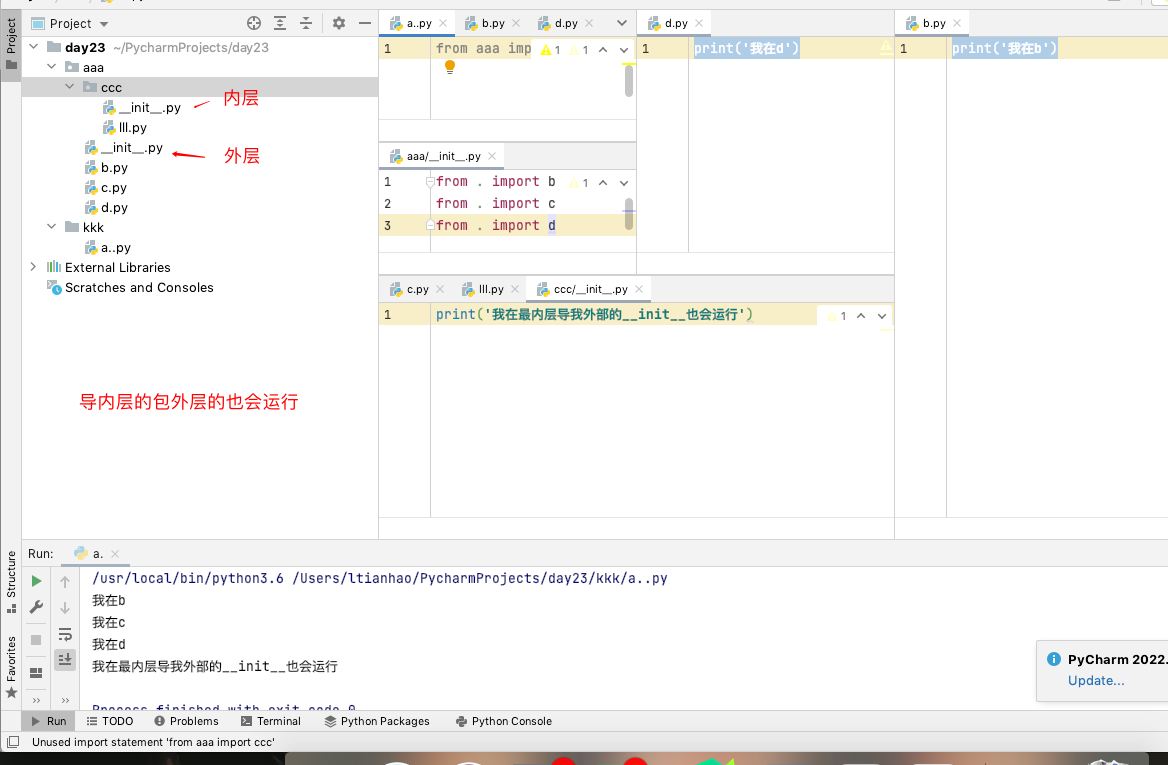
导入包然后将包内的模块导入__init__文件中利用此文件帮助我们控制其他模块简介使用其他模块的功能,也可以跨包导内部模块文件
代码:
print('我在d')
print('我在c')
print('我在b')
from . import b
from . import c
from . import d
import aaa
print(aaa)
越过包导内部文件:
from aaa import b
"""
导包的内部文件时只要经过包那么包内部的__init__就会运行一次
"""
针对python3 文件夹下有没有__init__.py有没有都无所谓
python2 文件夹中必须有__init__.py才能被当作包
此处细节鸡哥没讲

编程思想的转变
1.小白阶段
按照需求从上往下堆叠代码 单文件
2.函数阶段
将代码按照功能的不同封装称不同的函数 单文件
3.模块阶段
根据功能的不同拆分不同的模块文件 多文件
将所有的文件全部存储在c盘,将所有的文件在c盘中分类,将所有文件按照功能不同分类到其他盘中
作用高效的管理资源
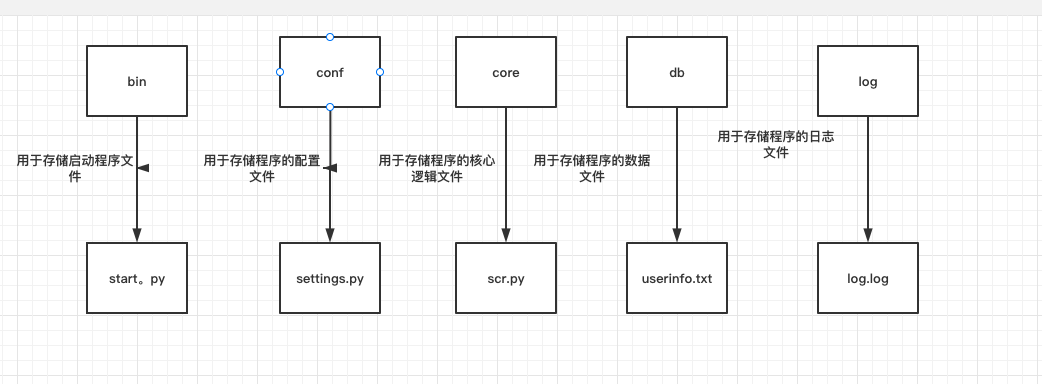
软件开发目录规范
针对模块阶段,分模块文件之后还需要有文件夹
我们所使用的所有程序目录都有一定的规范(多个文件夹)
1.bin 文件夹 用于存储程序的启动文件 start.py 可以不创直接放根目录
2.conf文件夹 用于存储程序的配置文件 settings.py
3.core文件夹 用于存储程序的核心逻辑 src.py
4.lib文件夹 用于存储程序的公共功能 common.py
5.da文件夹 用于存储程序的数据文件 userinfo.py
6.log文件夹 用于存储程序的日志文件 log.log
7.interface文件夹 用于存储程序借口的文件 user.py
8.readme文件夹 说明书 文本文件
编写的时候可以不按照上述名称创建,只需要提现出分门别类就行了
代码展示
def register():
print('注册功能')
def login():
print('登陆功能')
def tansfer():
print('转账功能')
def withdraw():
print('提现功能')
func_dict = {'1':register, '2':login, '3':tansfer, '4':withdraw}
def run():
while True:
print('''
1.注册功能
2.登陆功能
3.转账功能
4.提现功能
''')
choine = input('输入功能选项>>>:').strip()
if choine in func_dict:
func_dict.get(choine)()
else:
print('没有此功能') # 以上代码写在core文件夹src.py核心逻辑下列代码写在启动文件中
from core import src
if __name__ == '__main__':
src.run()
常见内置模块
collections 包名
1.namedtuple 具名元组
from collections import namedtuple
point = namedtuple(二维'坐标系',['x','y'])
print(point)
res = point(1,2)
print(res) # 坐标系(x=1, y=2)
print(res.x) # 1单独拿一个点就行
from collections import namedtuple
point = namedtuple('三坐标系',['x','y','z'])
print(point)
res = point(1,2,3) # 传三个参数即可
print(res) # 坐标系(x=1, y=2)
print(res.x) # 1单独拿一个点就行
扑克牌
2.from collections import namedtuple
name = namedtuple('扑克',['花色','点数'])
res = name('♥️','皮蛋')
res1 = name('♠️','皮蛋')
print(res,res1)
from collections import deque
list =deque()
list.append(123)
list.append(123)
list.append(123)
list.append(123)
print(list)
'''双端队列可以两边进两边出'''
队列先进先出,堆栈先进后出
from collections import OrderedDict #将字典转成有序的按照插入顺序排列
dict = OrderedDict([('1','A'),('2','B')])
print(dict)
3.
res = 'asdasfasfasgasfafasd'
new_list = {}
for i in res :
if i not in new_list:
new_list[i] = 1
else:
new_list[i] += 1
print(new_list)
from collections import Counter
k = Counter(res)
print(k)

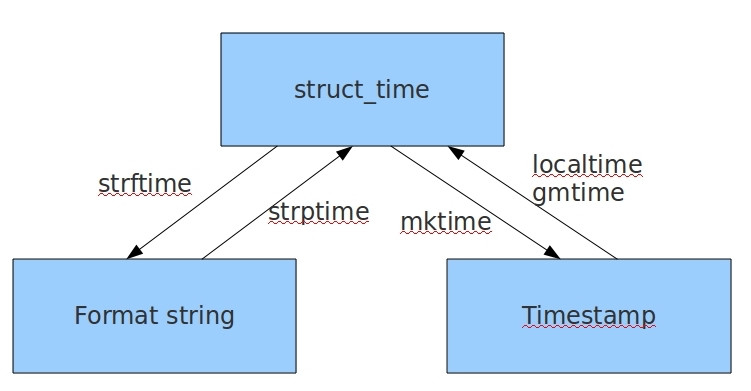
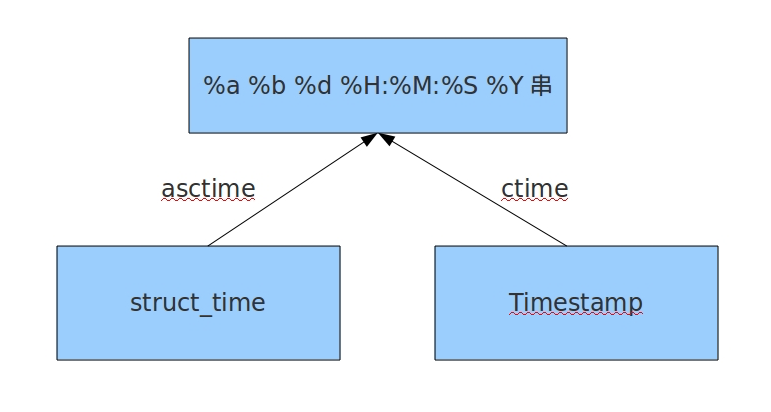
时间模块
时间的三种格式
# 1.时间戳
import time
print(time.time()) #时间戳 1970年1月1日零时零秒
# 2.结构化时间
print(time.gmtime()) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=14, tm_min=24, tm_sec=21, tm_wday=3, tm_yday=195, tm_isdst=0)
# 格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S'))
print(time.strftime('%Y-%m-%d %X'))
格式化时间的对应字符
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
时间可以互相转换未深入了解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号