文件简介和文件操作

昨日内容回顾
垃圾回收机制
```Python会帮我们自动申请和优化内存空间```
1.引用计数
当数据值身上引用计数不为0 时说明该数据还有用不会被删除,反之就会被删除
引用计数就是数据值被变量绑定或者数据值间接绑定的次数
比如name = jason
name1 = name
那么此时Jason 的引用计数就是2
当我们解除name1 的时候jason的引用计数就会减一
但会有个缺点叫循环引用 就是数据值与数据值间接引用此时没有变量绑定但引用次数不为0不会被删除
2.标记清除
针对循环引用开发了标记清除每隔一段时间对所有数据扫描一次对没有变量名绑定的数据打上标记然后一次性清楚
3.分代回收
针对标记清除又开发了分代回收机制,分为三代每隔一段时间对所有数据扫描浪费会损耗较多资源,会把使用对于使用多次的数据放入第二代降低扫描频率,对于使用频率高的放入地三代比第二代扫描频率更低,越往后频率越低
字符编码
1.只有文本文件才有字符编码的概念
2.计算机内部存取数据的本质二进制,因为计算机只认识0和1
3.编码的本质就是把人类的字符转换成计算机能看懂的数字
1.解码本质就是把计算机的数字转换成人类能看懂的字符
2.将计算机能看的数字按照指定的编码表转换成人类能看懂的字符
3.我们可以在计算机打出不同国家的文字,因为人类发现计算机无法直接识别人类的字符所有开发了一个可以让人类字符与数字对应的编码表
4. 编码的发展史
1.计算机是由美国人发明的,美国需要让计算机识别英文字符,发明了一套叫ASCII的编码表
英文所有字符加起来不超过127个是2的七次方足够代表英文的所有字符但美国人考虑到以后肯能还需要添加所以增加了一位以备不时之需
2的八次方
ASCII内部只记录了英文字符与数字的对应关系
用一个字节来存储字符
此时计算机只能识别英文字符不能识别其他文字
存储单位字节:bytes
2. 多国开始使用计算机
每个使用计算机的国家都需要计算机能识别自身国家的文字所以每个国家都开发了一套可以识别自己国家文字的编码表
中文编码表:GBK码
内不记录了中文字符英文字符与数字的相对应关系
存储中文需要用两个字节起步
英文字符一个字节
韩文编码表:Euc_kr码
让计算机可以识别韩文与英文与数字的对应关系
日文编码表:shift-JIS内不记录了日文英文与数字的对应关系
此时各国计算机文本文件无法直接交互,会出现乱码现象
3.针对乱码的问题开发了一套万国码
unicode 兼容万国文字
所有字符全部以两个字节起步(bytes)存储
后来对于unicode做出了优化
开发了utf家族utf8
英文使用一个字节其他文字统一使用三个字节(bytes)
内存使用的是unicode 硬盘使用utf8
##
字符编码实操
'''只有字符串可以参与编码其他数据类型需要转为字符串才可以
'''
1.解决乱码
当初用什么码编的便用什么码解即可
2.编码与解码
编码:
s1 = 'jason下午好'
res = s1.encode('gbk')
print(res)
在python中bytes可以直接看成二进制
解码:
res1 = res.decode('gbk')
print(res1)
3.解释器
python2 默认使用ASCII编码
1文字开头需要
# coding:utf8
2.定义字符串需要在字符串前面加u
python3默认使用utf8 编码
文件的简单操作
文件操作简介
1.操作文件
通过编写代码自动操作文件读写
2.什么是文件
文件就是操作系统给用户操作极速啊机硬盘的快捷方式之
一
双击文件图标就是从硬盘加载数据到内存
写完文件之后保存就是从内存把数据刷到硬盘
3.如何操作文件
open(文件路径,读写的模式,字符编码)
方式1
f = open()
f.close()
有个缺点就是打开之后需要通过编写代码将其关闭
方式2
with open(文件路径,读写模式,字符编码)as 变量:
子代码运行之后自动调用关闭close()方法
4.针对文件路径需要注意有特殊含义的字符串需要在字符串前方加r取消其特殊含义
昨日作业讲解
1.统计列表中每个数据值出现的次数并组织成字典战士
1.统计列表中每个数据值出现的次数并组织成字典战士 eg: l1 = ['jason','jason','kevin','oscar'] 结果:{'jason':2,'kevin':1,'oscar':1} 真实数据 l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
# 1.统计列表中每个数据值出现的次数并组织成字典战士
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
dict = {}
for name in l1: # 循环获取列表中的每一个数据
if name not in dict: # 如果字典里没有则新增一对键值对
dict[name] = 1 # 第一次出现v值为一
else:
dict[name] += 1 # 获取相应的值并自增1
print(dict)
data_dict = {}
#1.先搭建功能框架
while True:
print('''
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
''')
#2.获取用户输入
fncu_id = input('plase input id >>>:').strip()
if fncu_id == '1':
emd_id = input('输入员工编号').strip()# 3.获取用户输入的信息
if emd_id in data_dict: # 判断员工是否已存在如果存在则提示然后结束本次录入
print('员工已存在请重新录入')
continue
emd_name = input('输入员工姓名').strip()
emd_age = input('输入员工年龄').strip()
emd_job = input('输入员工工作').strip()
emd_salary =input('输入员工薪资').strip()
emd_dict = {} # 创建小字典将员工输入的信息录入小字典
emd_dict['emd_id'] = emd_id
emd_dict['emd_age'] = emd_age
emd_dict['emd_name'] = emd_name
emd_dict['emd_job'] = emd_job
emd_dict['emd_salary'] = emd_salary
print(f'员工{emd_name}添加成功') # 提示完成录入
data_dict[emd_id] = emd_dict # 将小字典统一录入打字大字典 {'1': {} }
elif fncu_id == '2':
target_emd_id = input('输入员工编号').strip() # 1.获取想要修改的员工编号
if target_emd_id not in data_dict: # 2.判断员工编号是否存在
print('员工不存在无法修改')
continue
emd_data = data_dict.get(target_emd_id) # 根据员工编号获取小字典的数据{'1'{}}
new_salary = input('输入员工新的薪资').strip() # 获取员工的新工资
emd_data['emd_salary'] = new_salary # 修改员工小字典内的数据值
data_dict[target_emd_id] = emd_data # 将修改后的小字典换到大字典中
print(f'员工编号:{target_emd_id} \n员工姓名:{emd_data.get("emd_name")}薪资修改成功')
elif fncu_id == '3':
target_emd_id = input('输入员工编号').strip() # 获取员工编号
if target_emd_id not in data_dict:
print('员工编号不存在')
continue
emd_data = data_dict.get(target_emd_id)
print(f"""
--------------------emp of info------------------
编号:{emd_data.get('emd_id')}
姓名:{emd_data.get('emd_name')}
年龄:{emd_data.get('emd_age')}
岗位:{emd_data.get('emd_job')}
薪资:{emd_data.get('emd_salary')}
-------------------------------------------------""")
elif fncu_id == '4':
all_daca = data_dict.values()
for emd_data in all_daca:
print(f"""
--------------------emp of info------------------
编号:{emd_data.get('emd_id')}
姓名:{emd_data.get('emd_name')}
年龄:{emd_data.get('emd_age')}
岗位:{emd_data.get('emd_job')}
薪资:{emd_data.get('emd_salary')}
-------------------------------------------------""")
elif fncu_id == '5':
target_delate_id = input('输入员工编码').strip()
if target_delate_id not in data_dict:
print('员工编号不存在')
continue
data_dict.pop(target_delate_id)
print(f'员工编号{target_delate_id}数据删除成功')
else:
print('没有此功能')
今日内容概要
文件读写模式
"""补充知识
1.with 语法支持一次次打开多个文件
with open(r'a.txt','r',encoding='utf8')as f1,open(r'b.txt','r',encoding='utf8')as f2,open () as f3
2.补全python语法 但是不执行任何操作
pass 推荐使用
... 不推荐使用
3. 通常情况下英语单词的结尾如果跟able是具备什么能力
readable 具备读取内容的能力
wittable 具备填写内容的能力
"""
r 只读模式 默认的模式
使用r模式只能读取内容不能做其他操作
使用该模式打开的文件内容只能读取内容,不能做其他操作(写)
文件路径不存在:r模式会直接报错
with open (r'文件路径打开方式','模式= r读 w写 a加') as f;
pass
print(f.read()) ps:只看模式
f.write('中文')
w模式文件路径不存在会直接创建新的文件
with open(r'a.txt', 'w',encoding = 'utf8') as
f:
f.write('写啥都行') ps:写
with open(r'b.txt', 'a', encoding = 'utf8') as f:
print(f.write()) ps:只追加模式
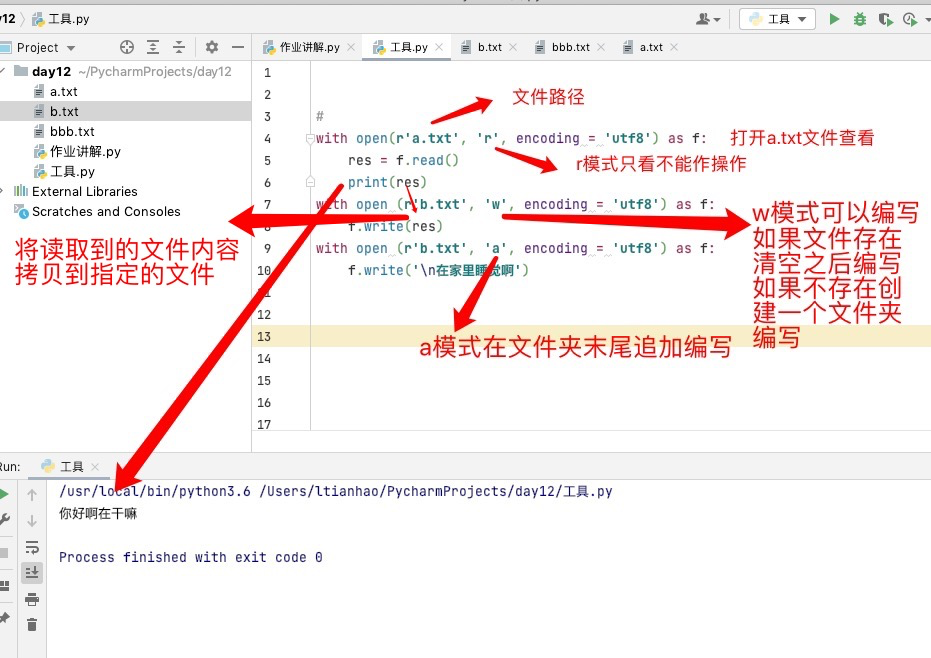
with open(r'b.txt', 'r', encoding= 'utf8') as f:
p = f.read()
print(p)
with open(r'/Users/ltianhao/Desktop/bbb.txt','w',encoding='utf8') as f:
print(f.write(p))
2.文件的操作模式
- 文本模式
r rt
w wt
a at
1.只能操作文本
2.必须用encoding=‘utf8’才能使用
3.读写都是以字符串为单位
- 二进制模式
rb
wb
ab
1.能操作所有类型的文件
2.不需要制定编码
3.读写都是以字节为单位bytes
3.文件操作的其他方法
使用句点符可以点出文件其他操作方法
-
read
-
一次性读取文件内容光标会停留在文件末尾继续则读取不到内容,内容为空
-
当读去文件数据内容较大时不推荐一次性读取,可使用for循环
-
-
readline ()一次只读一行内容
-
readlines()读取所有内容然后制成列表返回
-
writable()判断当前文件是否写
-
readable()判断当前文件是否可读
-
write()写内容
with open(r'b.txt', 'w', encoding = 'utf8') as f:
f.write('中文编写')
with open(r'b.txt', 'r', encoding='utf8') as j:
a= j.read()
print(a)
- 文本拷贝功能
with open(r'a.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'aaa.txt', 'w', encoding='utf8') as f:
f.write(data)
作业
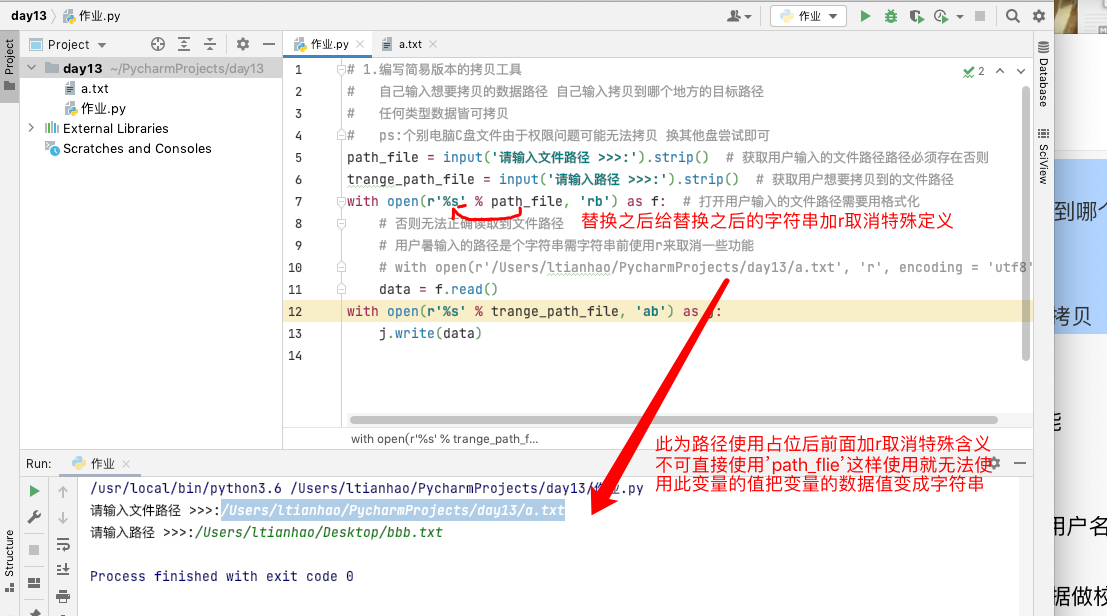
# 1.编写简易版本的拷贝工具
# 自己输入想要拷贝的数据路径 自己输入拷贝到哪个地方的目标路径
# 任何类型数据皆可拷贝
# ps:个别电脑C盘文件由于权限问题可能无法拷贝 换其他盘尝试即可
path_file = input('请输入文件路径 >>>:').strip() # 获取用户输入的文件路径路径必须存在否则
trange_path_file = input('请输入路径 >>>:').strip() # 获取用户想要拷贝到的文件路径
with open(r'%s' % path_file, 'rb') as f: # 打开用户输入的文件路径需要用格式化
# 否则无法正确读取到文件路径
# 用户暑输入的路径是个字符串需字符串前使用r来取消一些功能
# with open(r'/Users/ltianhao/PycharmProjects/day13/a.txt', 'r', encoding = 'utf8')
data = f.read()
with open(r'%s' % trange_path_file, 'ab') as j:
j.write(data)
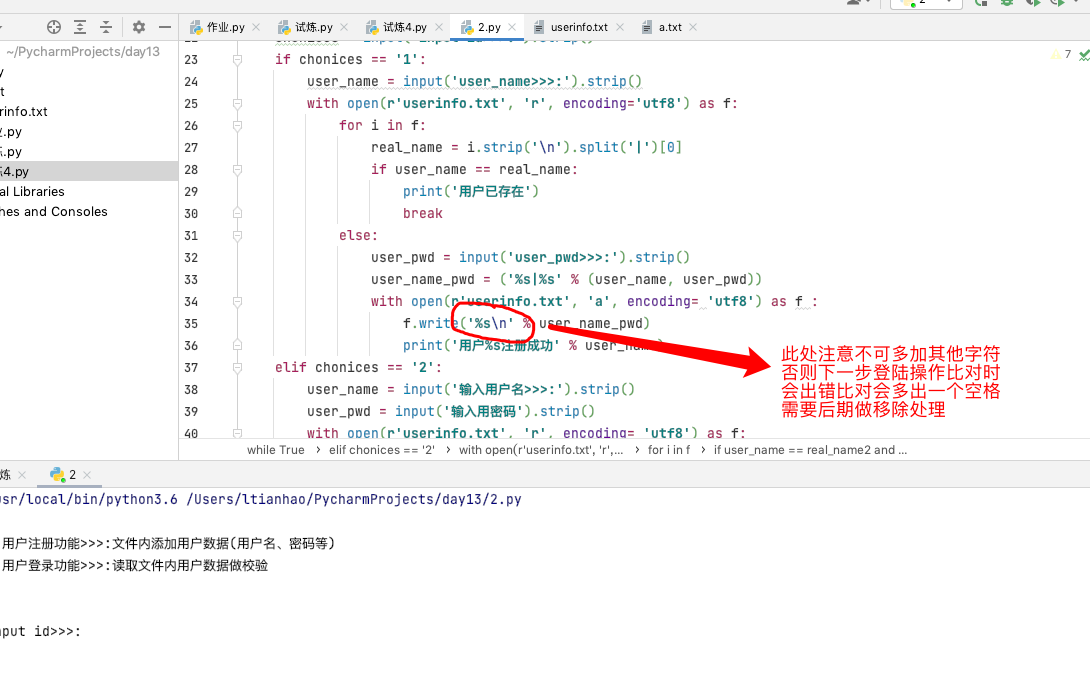
while True:
print('''
1.用户注册功能>>>:文件内添加用户数据(用户名、密码等)
2.用户登录功能>>>:读取文件内用户数据做校验
''')
chonices = input('input id>>>:').strip()
if chonices == '1':
user_name = input('user_name>>>:').strip()
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for i in f:
real_name = i.strip('\n').split('|')[0]
if user_name == real_name:
print('用户已存在')
break
else:
user_pwd = input('user_pwd>>>:').strip()
user_name_pwd = ('%s|%s' % (user_name, user_pwd))
with open(r'userinfo.txt', 'a', encoding= 'utf8') as f :
f.write('%s\n' % user_name_pwd)
print('用户%s注册成功' % user_name)
elif chonices == '2':
user_name = input('输入用户名>>>:').strip()
user_pwd = input('输入用密码').strip()
with open(r'userinfo.txt', 'r', encoding= 'utf8') as f:
for i in f:
# print(i)
real_name1 = i.strip('\n') # jason|123
real_name2,realpwd4 = real_name1.split('|')
# print((real_name2,realpwd4)) #
if user_name == real_name2 and user_pwd == realpwd4:
print('登陆成功')
break
# if user_name == real_name and user_pwd ==real_pwd:
# print('登陆成功')
# break
else:
print('用户%s登陆失败' % user_name)
elif chonices == '3':
break
else:
print('输入未知选项暂无此功能')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号