requests 爬取微博评论
涉及到的准备操作请移步上一篇,这里主要记录headers的获取以及每页评论真实url的获取
Requests设置请求头Headers
1.设置headers 目的
headers 是解决request请求的一种反爬机制,对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
2. headers 位置以及获取
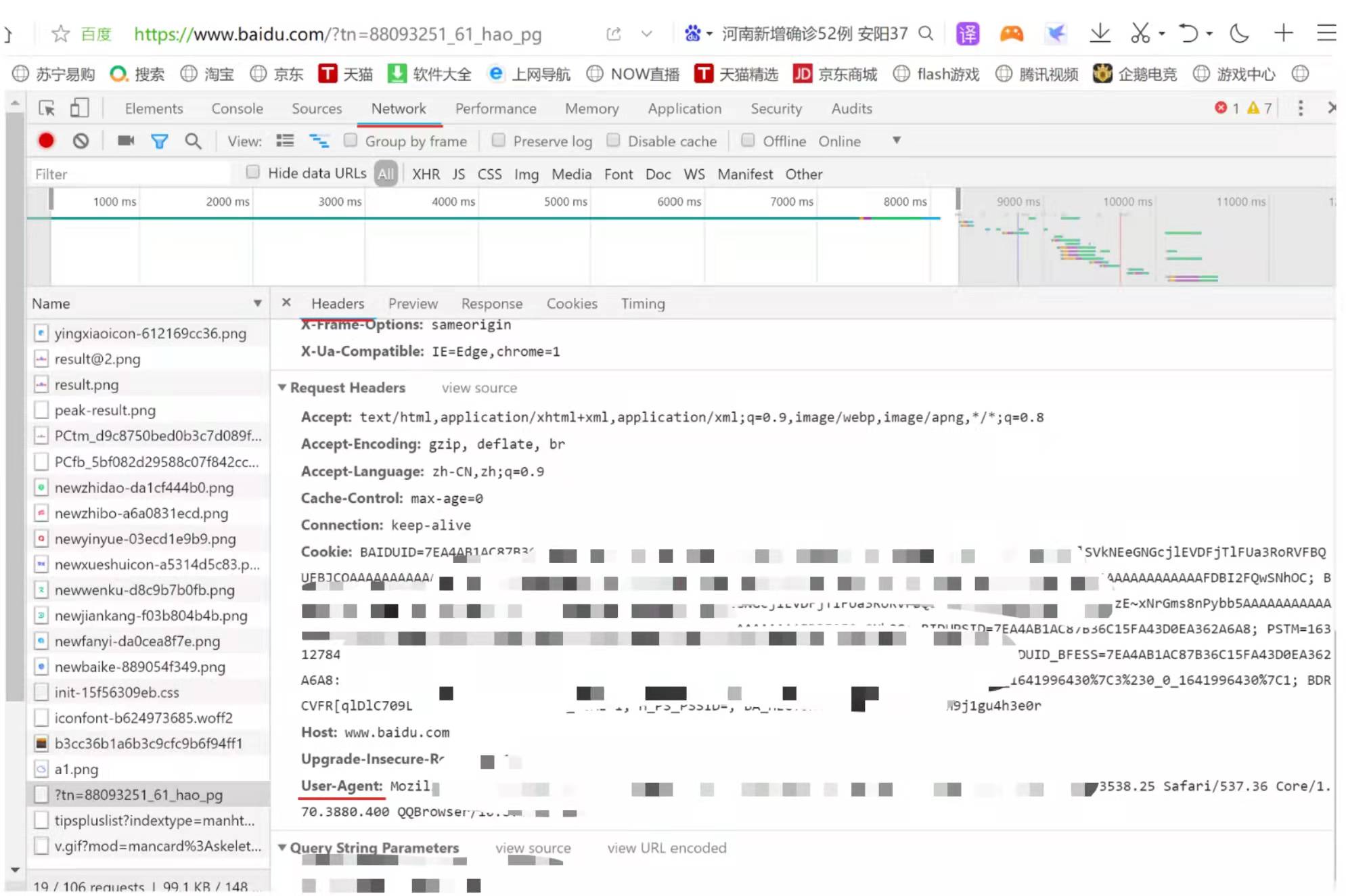
打开浏览器,进入百度页面,右击鼠标选择“检查”—>“Network”—>F5 进行刷新—>左侧“Name”中内容—>“Headers”
爬取前微博到达登录页面—> "检查"—>“Network”—> 勾选perserve log(登录后抓包相关内容)—>登录—>F5 进行刷新—>左侧“Name”中内容—>“Headers"
确定微博每页评论的url
微博的网页属于Ajax渲染,当向下滑动的时候会显示的评论,地址栏的URL不变,需要找到实际的请求URL。
获取第一页url
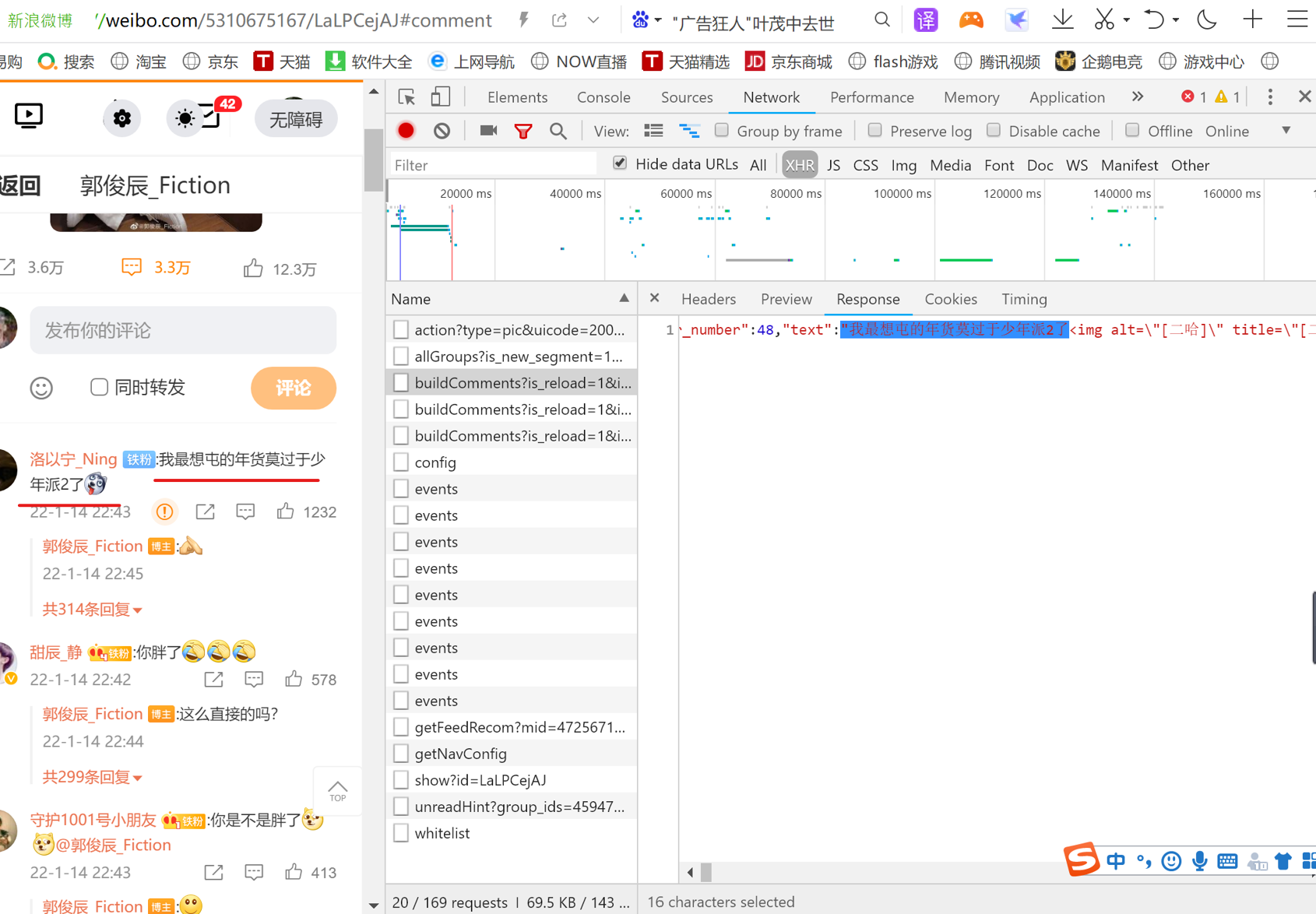
获取第二页url

从第二页开始的URL地址多的部分是max_id,刚好这个参数的值是前一页的返回内容:(网页版url)
1 url1=https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4725671483411905&is_show_bulletin=2&is_mix=0&count=10&uid=5310675167 2 url2=https://weibo.com/ajax/statuses/buildCommentsis_reload=1&id=4725671483411905&is_show_bulletin=2&is_mix=0&max_id=143942267179153&count=20&uid=5310675167 3 url3=https://weibo.com/ajax/statuses/buildCommentsis_reload=1&id=4725671483411905&is_show_bulletin=2&is_mix=0&max_id=162771403606240&count=20&uid=5310675167
移动端url
1 url1=https://m.weibo.cn/comments/hotflow?id=4725671483411905&mid=4725671483411905&max_id_type=0 2 url2=https://m.weibo.cn/comments/hotflow?id=4725671483411905&mid=4725671483411905&max_id=146553607181687&max_id_type=0 3 url3=https://m.weibo.cn/comments/hotflow?id=4725671483411905&mid=4725671483411905&max_id=142430438614853&max_id_type=0
新手还是爬移动端来的开心(是我太菜啦55),下面分别是三页url的获取
第一页
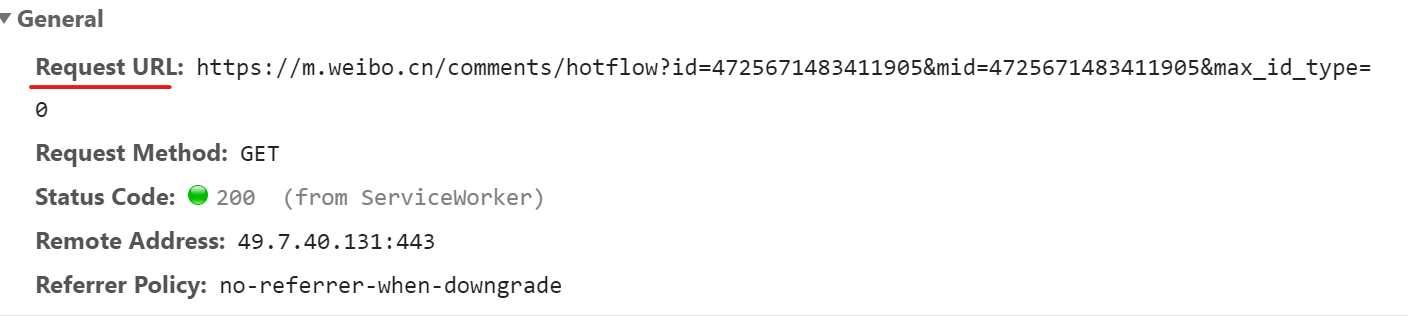
第一页的“max_id”

第二页url
![]()
第二页“max_id”
![]()
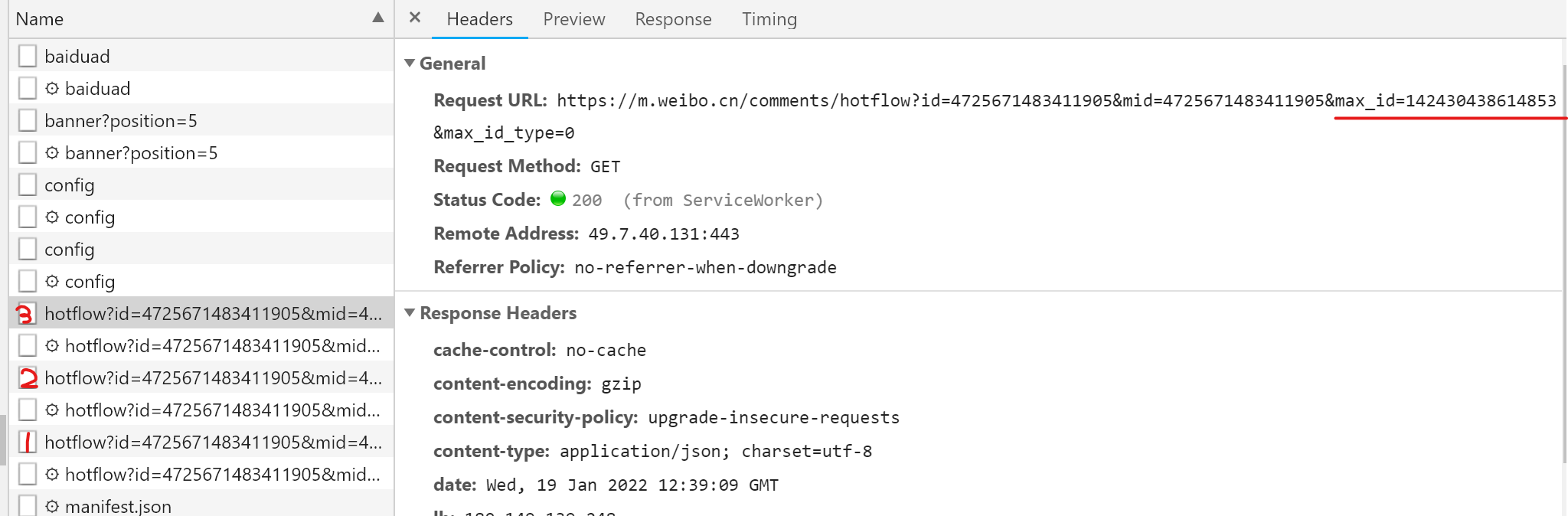
具体代码尝试
1.获取第一页评论中网页的全部内容
1 import requests 2 import json 3 url1 = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4725671483411905&is_show_bulletin=2&is_mix=0&count=10&uid=5310675167' 4 headers = { 5 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400' 6 } 7 response = requests.get(url = url1,headers=headers) 8 result = response.content.decode('utf8') 9 content = json.loads(result) 10 print(content)
运行结果(一小部分)
注意headers请求中‘User Agent’ 信息里不能有空格,否则会出现以下报错

设置规则和方法获得相关数据
1 for i in comment_data['data']:#提取某一页网页内容中的相关信息 2 screen_name = i['user']['screen_name'] #一个个标签逐一进行匹配 3 i_d = i['user']['id'] 4 #网页相关内容复制:"user":{"id":5310675167,"screen_name":"\u90ed\u4fca\u8fb0_Fiction", 5 created_at = i['created_at'] #点赞 6 text = ''.join(re.findall('[\u4e00-\u9fa5]', i['text'])) #评论
将所得数据进行保存
1)存入到本地为text/json 格式的文件中去
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'created_at': [created_at],'text': [text]})#呈现出来的格式
df = pd.concat([df, data_json])
2)搭建数据库服务,将数据存入库中(继续学习)
#代码
print("早点睡觉不然会死掉!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号