

大数据平台搭建目录
欢迎各位学习和借鉴搭配大数据系统
1.备注
省略了一些文件的创建,请自行创建
2.配置到大数据系统的所有配套文件
案例中所使用的版本,解决了版本适配问题
百度网盘链接:https://pan.baidu.com/s/1B5sx61Ori4U8fshHE3bJaA
提取码:6666
一.安装Lunx:centos7
安装centos7
二.使用xshell和xftp
xshell和xftp使用
三.配置hadoop
使用xshell进行配置Hadoop
四.配置Spark
Spark搭建
五.配置scala
scala搭建
六.配置anaconda
anaconda安装配置至可以使用spark
七.配置zookeeper
zookeeper安装配置
八.配置HBase
HBase安装配置
九.集群启动流程
1.启动hadoop所有应用
主节点输入命令
start-all.sh
关闭安全模式
hdfs dfsadmin -safemode leave
2.启动spark
主节点输入命令
cd /opt/apps/spark-3.1.2-bin-hadoop2.7/sbin
./start-all.sh
3.启动zookeeper
所有节点输入命令
zkServer.sh start
4.启动HBase
主节点输入命令
cd /opt/apps/hbase-2.1.0/bin
start-hbase.sh
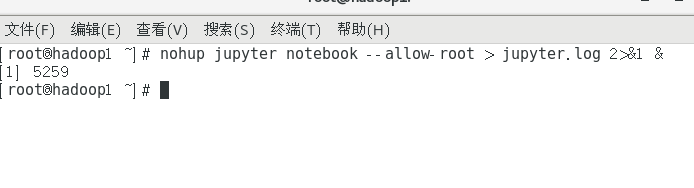
5.启动jupyter noteboo
进入vm的Hadoop1的root账号,打开终端后台启动
nohup jupyter notebook --allow-root > jupyter.log 2>&1 &
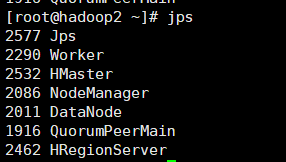
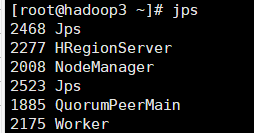
6.查看
- 主节点jps
![hadoop1]()
- 从节点jps
![hadoop2]()
![hadoop3]()
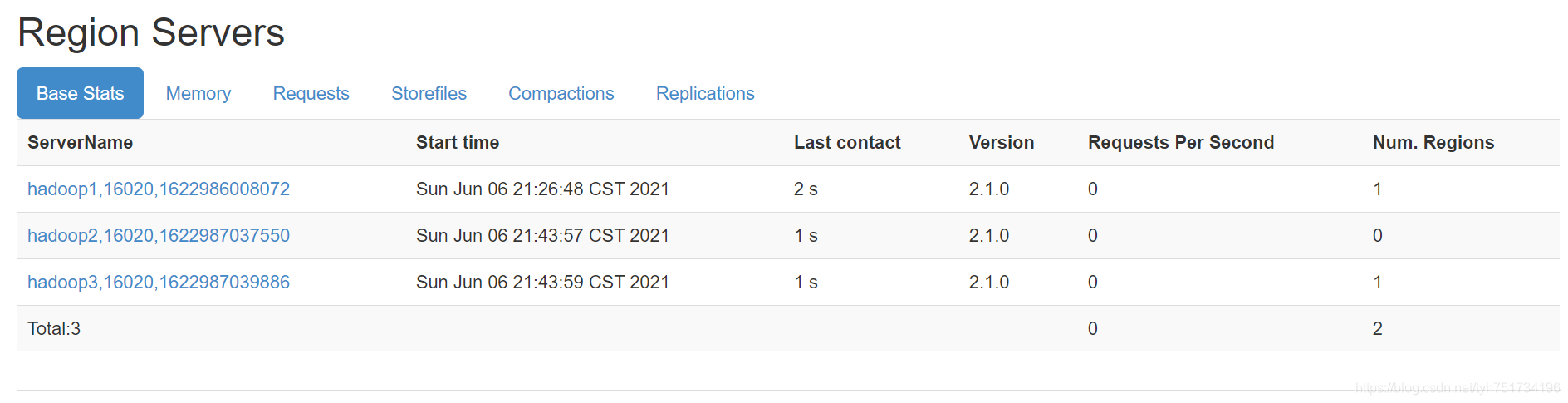
- HBase
![HBase]()
- jupyter notebook
![jupyter]()


7.对应url
| - | ip端口 |
|---|---|
| hadoop | hadoop1:50070 |
| HBase | hadoop1:16010 |
| jupyter-notebook | hadoop1:8888 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号