面向对象设计与构造 第一单元总结
第一次作业
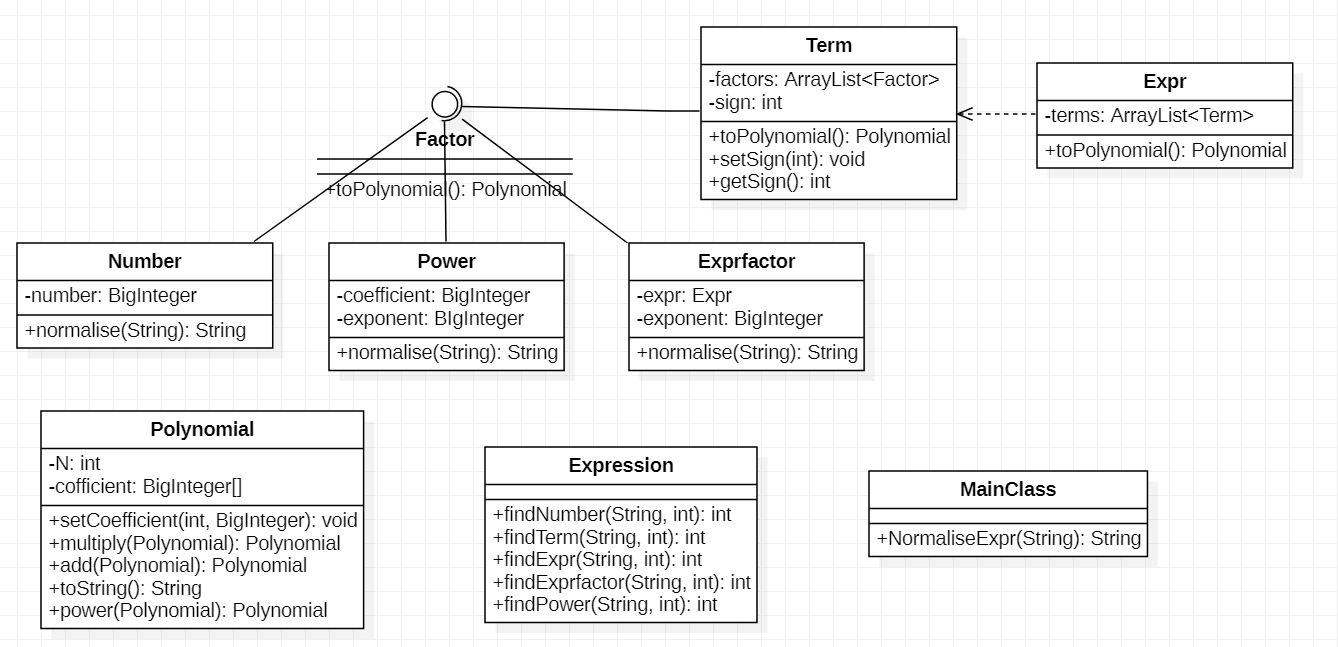
UML类图
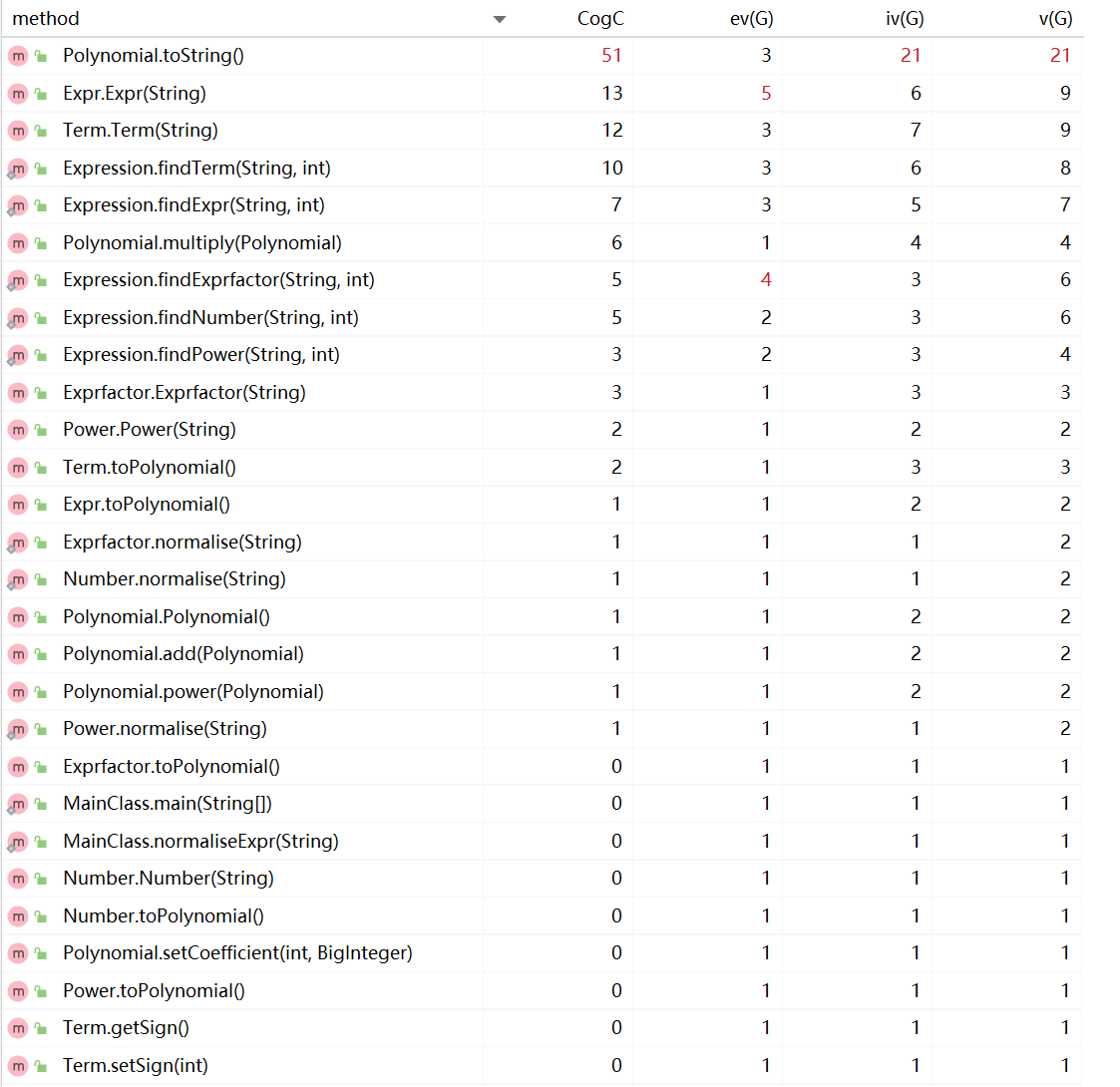
复杂度分析
(仅展示部分复杂度较高的方法)
设计架构
采用因子\(\rarr\)项\(\rarr\)表达式(对应类:Factor,Term,Expr)的结构存储数据,多项式运算处理表达式的化简、合并、输出结果,Expression类对输入字符串进行解析。
优点
1、架构简单,编码难度低。
2、基本达到了高内聚,低耦合的要求。
缺点
1、toString方法的复杂度过高,主要原因是为了缩短最终输出表达式的长度,判断了很多不同的情况,也许应该将其拆分为若干个方法,比如系数的toString和\(x^i\)的toString。
2、用数组存储多项式,可拓展性差。
3、在Factor的每个类中都实现了相同的方法normalise,应该将其放在一个工具类中实现以避免代码冗余。
4、每个类的构造函数传入的参数都为字符串,新建对象时依然需要对字符串进行解析,造成构造函数与Expression类中有较多重复代码。
自己与他人程序的BUG
第一次作业较为简单,没有进行太多测试,在强测获得了\(100\)分,互测中也没有被发现有BUG。
由于感觉第一次作业比较简单加上偷懒,没怎么找别人程序的BUG。
第二次作业
UML类图
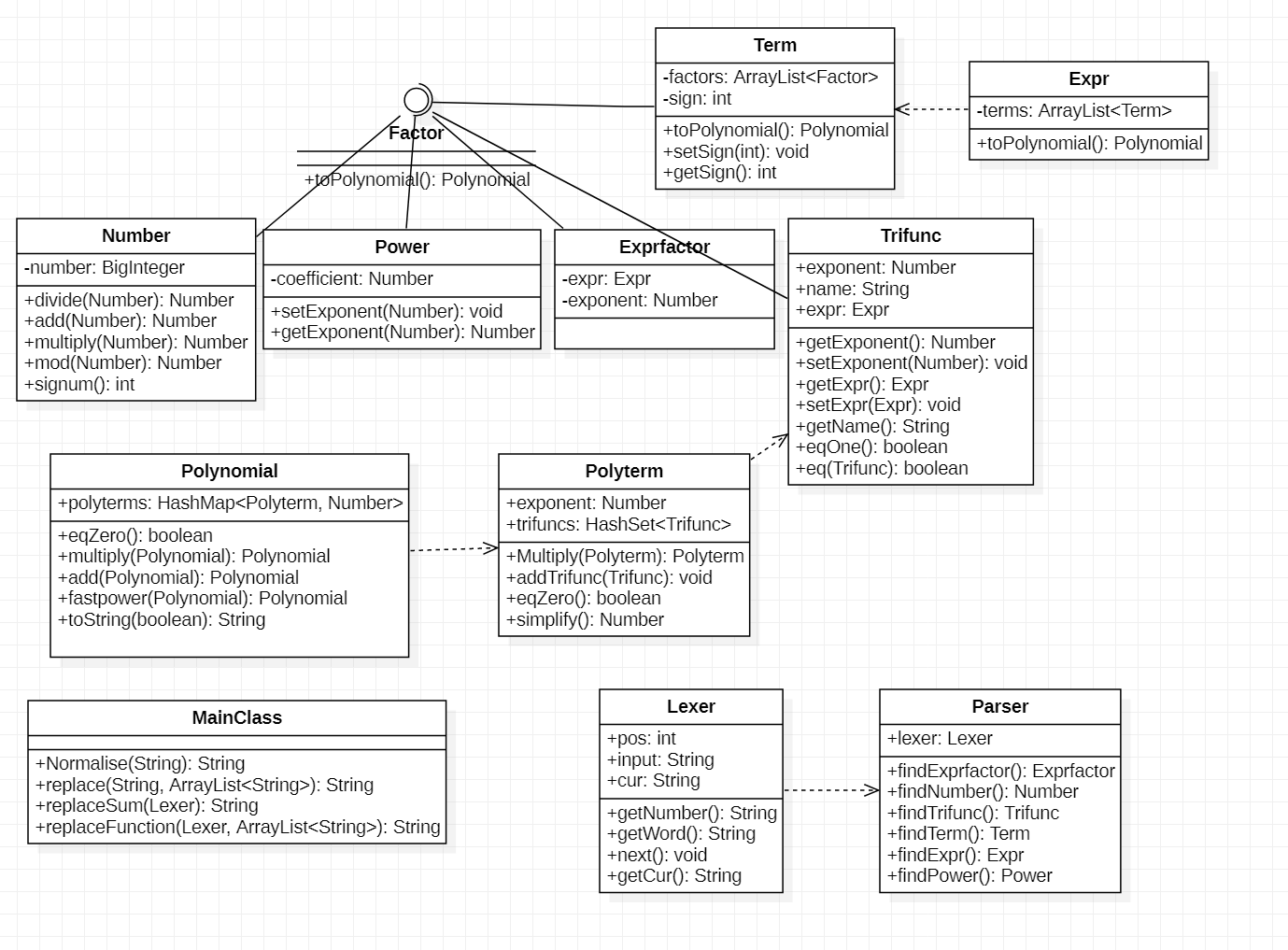
(省略了部分toString方法,以及为了解决深浅拷贝问题设计的copy方法,和为了HashMap、HashSet而重写的equals和hashCode方法)
复杂度分析
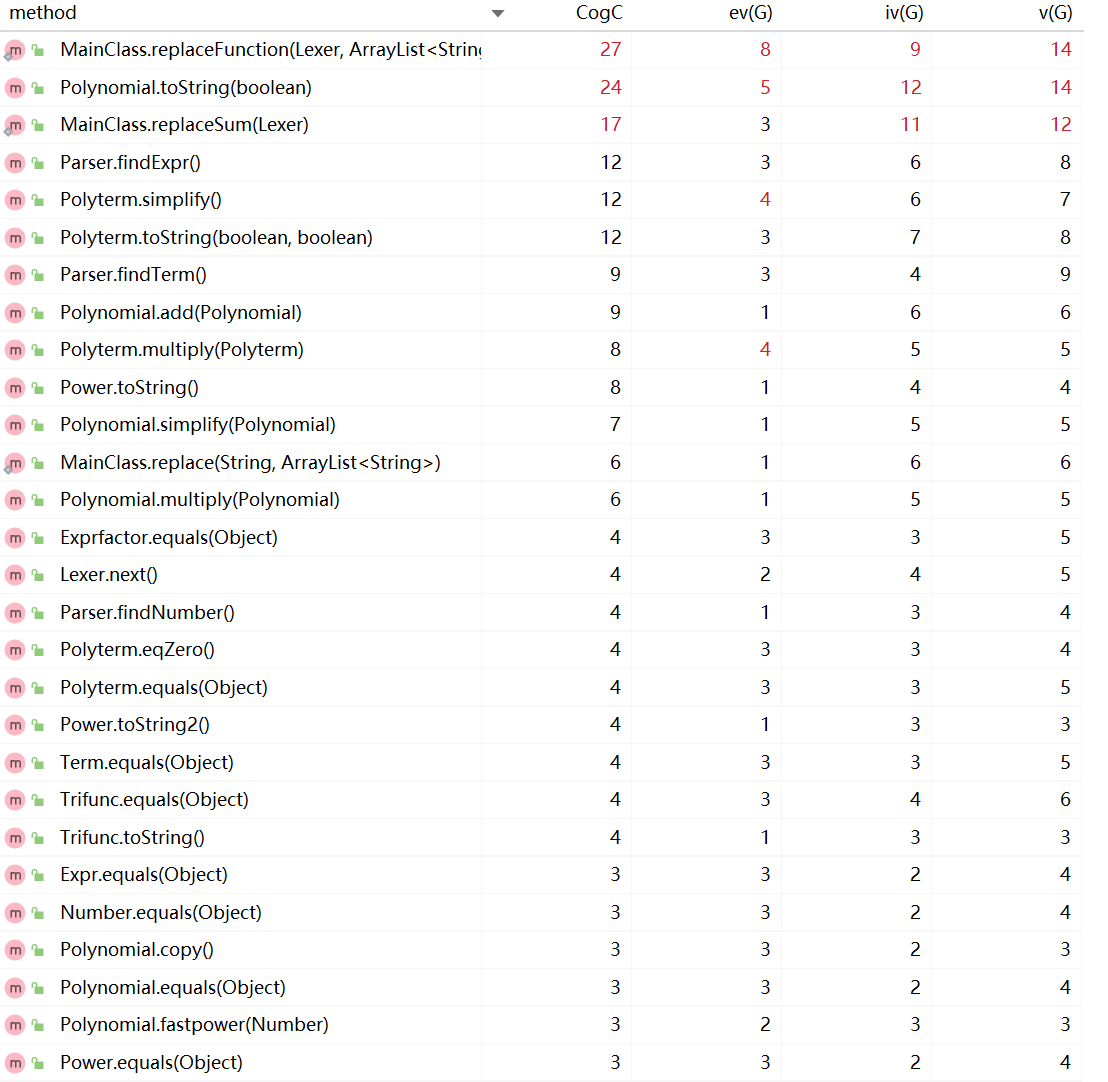
(仅展示部分复杂度较高的方法)
设计架构
进行表达式运算的基本框架保持不变,主要是模仿助教提供的代码,重写了解析表达式的部分,Lexer类将字符串拆解为多个Token,配合Parser类进行解析。
针对这次作业多出的三角函数,重新设计了多项式的表示方法:将多项式视作一个由多项式项(Polyterm)作为key,其系数作为value的HashMap,便于进行合并化简;对于多项式项,将其视作若干个三角函数构成的HashSet和一个幂函数组成的类。
对于sum函数和自定义函数,在输入完成后将其替换为仅含\(x\)的表达式。
在优化性能方面,做了\(sin(0),cos(0)\)和针对三角函数中负号的优化。
缺点
1、从复杂度分析图可以看出,作业一中的问题依然存在,为了简化输出结果toString方法特判了太多情况。
2、替换函数的方法复杂度过高,原因是没有对方法进行拆分,以及不善运用正则表达式。BUG也正是出现在该方法中。
3、类之间的依赖关系有些混乱,耦合度过高。
自己与他人程序的BUG
强测中出现的BUG:没有考虑sum函数的求和上下限带有符号的问题,一旦有符号就会出错。互测没有被发现有BUG。
BUG出现原因:一是做测试不够充分:我自己的测试没有测试求和函数的自定义函数,和同学的对拍数据生成器有恰好没有给sum中的数加符号;二是没有仔细阅读形式化表述。
第三次作业
这次作业我几乎没有改动代码,仅简略修改了将函数替换为表达式的方法:为处理函数嵌套,每次选择最内层的函数进行替换,之后再进行外层函数的替换,将函数一层层替换为表达式。故不再展示UML类图和复杂度分析。
自己与他人程序的BUG
强测中出现的BUG:因化简表达式的方法效率过低,如果三角函数的嵌套过多就会TLE。互测没有出现BUG。
发现其他同学的BUG:一个是sum函数中用int存储求和上下限的问题,因为水群里有人说了这个;一个是sum函数中形如\(i**k\)这样的表达式,在一些写法中可能替换出现问题。发现这个是由于上次互测无法测sum,这次随手测了一下就发现了问题。
架构成型过程
第一单元作业我总共写了三个版本:
第一个版本:我一开始写的是表达式求值的一种经典思路:转为后缀表达式求值。代码十分简洁,但考虑到学习内容的是面向对象,再加上这样的架构可能难以在后续进行迭代开发,于是放弃了这个版本。
第二个版本:在大概了解了解析字符串的两种方法:递归下降和正则表达式处理后,我选用了递归下降,并根据自己的理解写了出来。化简方面,用的是数组存多项式每一项的系数(第一次作业\(x\)的次数不超过\(8\))。
第三个版本:第二次作业时加入了三角函数,\(x\)的次数也没有了限制,原先用数组存多项式的思路作废,改为使用HashMap存储多项式。除此之外,在与助教给出的递归下降代码比对后,发现我自己写的不够优美,有很多冗余部分,于是参考助教的代码又修改了用递归下降解析字符串的部分。
测试方法
参照大多数同学的方法,借助Python的sympy包进行对拍。构造数据的方法就是参照形式化表述,逐层地随机生成。
心得体会
首先是对于Java语言特性的一点思考。在第二次作业中,我被深拷贝浅拷贝和引用传递折磨得很惨。由于意识到这个问题的时候已经写了很多代码,积重难返,因而没有重构代码,现在看来,可能下定决心重构会更好。在阅读其他同学的博客后,我认识到尽量设计不可变对象也许是一种比较优秀的解决方案。首先它很好地解决了深浅拷贝的问题;其次它可以很方便的作为Hashmap的key和HashSet的element,而不需要重写equals和hashCode方法;最后,不可变对象也有利于并行。
其次是程序运行效率的重要性。在第三次作业中,我本以为强测不会出问题,万万没想到最后会因为优化写得太差而TLE。其实TLE在弱测的时候已经出现过,当时优化了一部分,以为已经足够了,没有引起足够的重视。我又重新审视了一下自己的程序,由于输入字符串的长度较短,我在实现的时候几乎没有考虑运行时间的问题,怎么方便怎么来,导致很多方法的效率不尽人意。这启发我无论如何都不能轻视运行效率的问题。
最后是对于个人态度的一点反思。回顾整个第一单元作业,很多问题都是因为自己的懒惰而产生。比如我其实在第一单元已经考虑到了后续作业\(x\)的次数可能很大,第一个版本用数组存储多项式的方法可能不方便拓展,但为了贪图一时的方便,还是采用了该方法,加重了后续重构的负担。再如第二次作业,只要稍微认真读一遍指导书的形式化表述就能发现的BUG,最终导致强测损失惨重。又如前两次作业的互测环节,我都没有积极参加。在之后的作业中,需要投入更多的精力,克服懒惰的坏毛病。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号