redis
cache:读缓存,是为了调节速度不一致的两个或多个不同物质的速度。例如cpu先从内存读,内存没有再读磁盘。
buffer:写缓冲,先将数据写入自己最近的地方,,例如cpu写数据会先写入内存。后续由内核写入磁盘
缓存保存位置及分层结构
用户层:浏览器DNS,应用程序DNS,操作系统DNS缓存
代理层:CDN,反向代理缓存
web层:web服务器缓存,解释器opcache
应用层:页面静态化
数据层:分布式缓存,数据库
系统层:操作系统cache
物理层:磁盘cache,raid cache
cache特性
自动过期 缓存数据有实效,超过时间自动删除
强制过期 源网站更新内容后CDN不会自动更新,需要强制让缓存过期
命中率 缓存的读取命中率
浏览器缓存过期机制
1 最后修改时间 last-modified。浏览器请求文件时,会获取last-modified和本地浏览器缓存的文件修改时间比较,如果一样,那么就会返回304,从缓存中读取内容。如果不一样,那么就会重新请求。需要向服务器发起请求才可以使用缓存
2 etag标记:是httpheader中代表资源的标签,在服务器端生成。如果有etag,下一次发送带有etag的请求事,etag没有变化将返回304。需要向服务器发起请求才可以使用缓存
3 过期失效时间expires:由服务端设置,在expires内都不会http请求,直接读取缓存。强制刷新除外。默认过期时间为30天。如果设置过期时间为1年,资源的失效是从客户端请求开始计算往后1年失效。
4 混合使用
last-modified和expire混合使用
etag和expire混合使用:判断expire,过期则发起http请求,然后根据etag返回200或者304
三者混合使用:先判断expire,过期发送http请求,先判断last-modified,如果一致,再判断etag,还是一致,才能返回304
nosql数据库类别
临时性键值存储 memcached,redis
永久性键值存储 roma,redis
面向文档的数据库 mongob,couchdb
面向列的数据库 cassandra ,hbase
rbdms和nosql的对比
特点
| 关系型数据库 | nosql | |
| 特点 |
数据关系基于关系模型,结构化存储,完整性约束 基于二维表及其之间的联系 采用结构化的查询语言做数据读写 操作需要数据的一致性,需要事务甚至是强一致性 |
非结构化的存储 基于多维关系模型 具有特有的使用场景 |
| 优点 |
保持数据的一致性(事务处理) 可以进行join等复杂查询 通用性,技术成熟 |
高并发,大数据下读写能力较强 基于支持分布式,易于扩展,可伸缩 简单,弱结构化存储 |
| 缺点 |
数据读写必须经过sql解析,大量数据,高并发下读写性能不足 对数据读写,或修改诗句结构时需要加锁,影响并发操作 无法适应非结构化存储 扩展困难 复杂 |
jion等复杂操作能力弱 事务支持弱 通用性差 无完整约束复杂场景支持较差 |
redis对比memcached
支持数据的持久化:能将内存中的数据保存在磁盘中,重启redis服务或者服务器可以从备份文件中恢复数据到内层中继续使用
支持更多的数据类型:string,hash,list,set,zset
支持数据的备份:可以实现类似于数据的master-slave模式的数据备份,也支持使用快照和aof
支持更大的value数据:memcache单个key value最大只支持1mb,redis最大支持512mb,生产不建议超过2m
在redis6版本前,redis是单线程,memcache是多线程,单机情况下并发不高,但是支持分布式集群可以实现数万并发
都是基于c语言开发
redis典型应用场景
session共享:常见于web集群中的tomcat
缓存:数据查询,电商网站商品信息,新闻内容
计数器:访问排行榜,浏览数等和次数相关的数值统计场景
微博微信:共同好友,粉丝数,关注,点赞评论等
消息队列:elk的日志缓存
地理位置:摇一摇,附近的人,外卖等
编译安装redis
---------------------------------------------------------
yum -y install gcc jemalloc-devel 下载依赖
wget http://download.redis.io/releases/redis-5.0.3.tar.gz
tar xvf redis-5.0.3.tar.gz
cd redis-5.0.3/
make PREFIX=/apps/redis install 安装目录自定义
echo 'PATH=/apps/redis/bin:$PATH' > /etc/profile.d/redis.sh
. /etc/profile.d/redis.sh
mkdir /apps/redis/{etc,log,data,run} 创建配置文件,日志,数据等
cp /app/redis-5.0.3/redis.conf /apps/redis/etc/ 将redis.conf拷贝到安装目录etc下
redis-server redis.conf 前台启动redis
------------------------------------
可以开启redis多实例
redis-server --port 6380
chown -R redis.redis /apps/redis/ 很重要
-----------------------------------------------
解决启动时的警告
1.vim /etc/sysctl.conf
net.core.somaxconn=1024
vm.overcommit_memory=1
2.echo 'echo nerver' > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
---------------------------------------------------
编辑redis的systemd启动文件,复制yum安装的进行修改路径
验证redis启动
systemctl daemon-reload systemctl enable --now redis
-----------------------------------------------------
多实例部署
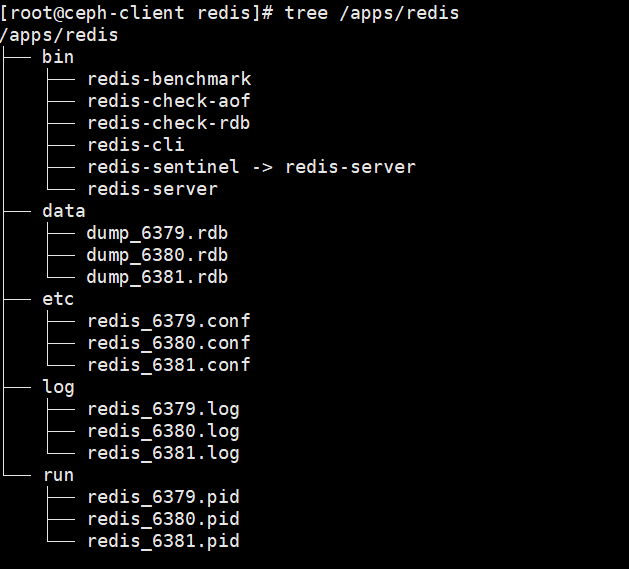
将原来的redis.conf修改redis_6379.conf,红色为修改部分
bind 0.0.0.0
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
supervised no
pidfile /apps/redis/run/redis_6379.pid
loglevel notice
logfile "/apps/redis/log/redis_6379.log"
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /apps/redis/data/
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly no
appendfilename "appendonly_6379.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
修改完后复制成redis_6380.conf ,redis_6381.conf。对应的systemd启动文件复制修改(改下对应的配置文件名字即可)。其他的不需要动。data,log,pid会自动生成。


启动!!!systemctl daemon-reload systemctl enable --now redis_6379 redis_6380 redis_6381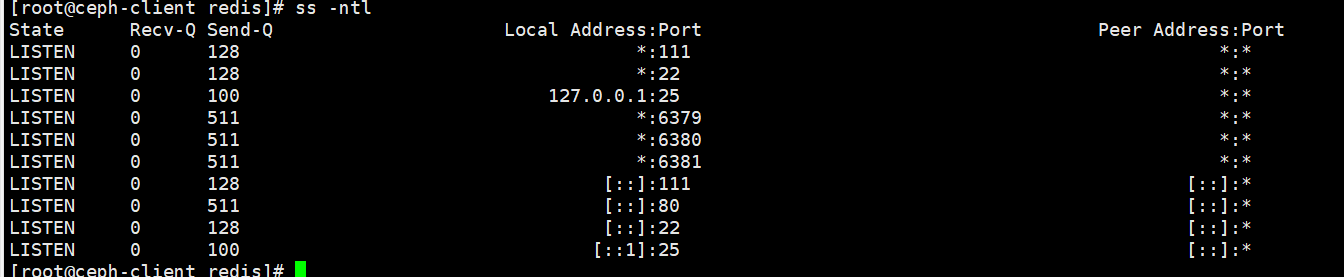
redis持久化
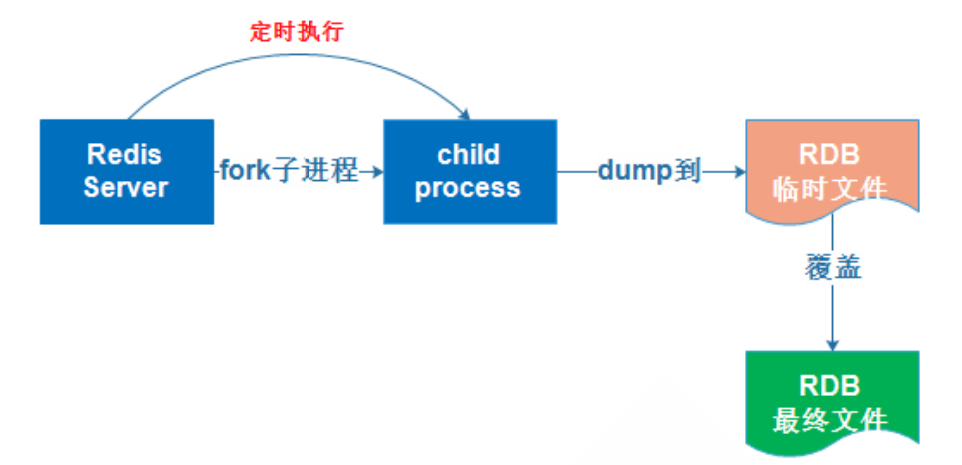
rdb:基于时间的快照,保留最新的一次快照文件。可能会丢失上次快照到当前没有快照的数据。当数据量非常大的时候,父进程fork出来的子进程将内容保存到rdb文件需要时间,取决于磁盘IO性能。数据量大会造成fork耗时大,服务器会在一定时间内停止处理客户端请求
实现rdb方式 save(同步)
bgsave(异步) --------------redis-cli bgsave 生产使用最多,可以通过脚本执行bgsave命令生成多个备份。如下图
自动:制定规则,自动执行
AOF:顺序添加内容到制定日志文件。默认为每秒同步一次,即保存到AOF当中。可以设置同步策略always,边同步边接受请求。由于写入采用的append模式,即使宕机也不会影响数据。如果写入一般出现系统崩溃,可以通过redis-check-aof工具解决数据一致性问题。重复操作也会记录,aof文件大于rdb,大数据量恢复速度也比rdb慢,bug多。
同时启用rdb和aof时,aof优先级高。由于aof默认是关闭的,当开启后重启服务,会导致所有数据丢失。
启动AOF:生成aof文件
redis-cli
127.0.0.1:6379> config set appendonly yes

redis数据类型
字符串string
列表list
集合set
有序集合sorted set
哈希hash
消息队列
消息队列:把要传输的数据放在队列里
功能:实现多个系统的解耦,异步,限流等
常见消息队列:kafka,rabbitmq,redis
队列模式
1生产者消费者模式:多个消费者同时监听一个队列,消息任务是一次性读取和处理。一个消息只能被消费一次。
2发布者订阅者模式:发布者将消息发布到指定的channel中,凡是监听这channel都会收到消息,类似广播。
此模式常用群聊天,通知等
publisher:发布者 subsriber:订阅者 channel:频道
redis集群与高可用
---------------------------------------------------
主从复制特点
一个master可以有多个slave,一个slave只能有一个master,数据流是单向的,master到slave
主从复制实现
不光master要开启数据持久化,slave也要开启持久化,因为slave会有提升为master的可能,slave切换成master同步后会丢失所有数据,持久化可以恢复数据。
一旦某个slave称为一个master的slave,slave会清空自己数据,把master的数据导入,但是如果只是断开同步关系后,则不会删除自己数据。
假设a为master,b和c都是slave。a关闭持久化后,a崩溃后,自动拉起重启a后,a数据为空,b和c从a复制数据,因为a为空,所以b和c把自己数据都删了
a 192.168.89.130 master
b 192.168.89.131 slave
c 192.168.89.132 slave
为了简化过程,同一yum isntall -y redis
a 设置key1值v1为master

b设置key1值为slave1
c设置key2值为slave2
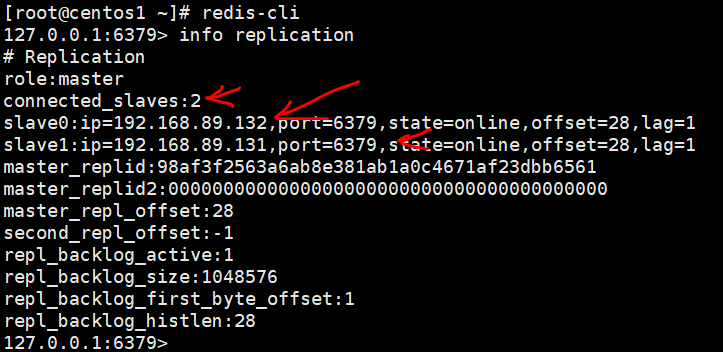
此时a,b,c均为master。配置b,c的redis.conf -----------bind 0.0.0.0,replicaof 192.168.89.130 6379 a的redis.conf----bind 0.0.0.0
如此成功建立主从,a有两个slave,slave同步a的数据。如下图

删除主从同步,只断开与master的联系,但是不会删除自身已有的数据。---- 在slave执行replicaof no one
此时slave只读无法写入数据

主从搭建时常见故障现象: master_link_status:down
原因1:密码不一致
原因2:master与bind没有修改0.0.0.0,无法互相监听
主从复制故障恢复
slave节点故障和恢复
client指向另一个从节点即可,并及时修复故障从节点
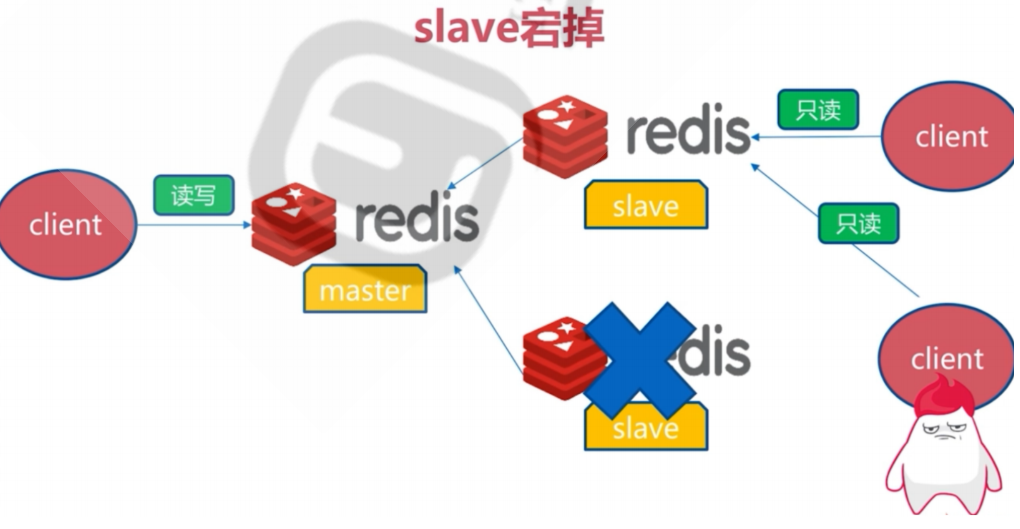
master节点故障和恢复
手动提升一个slave作为新的master,不支持自动切换。master的切换导致master_replid变化,slave之前的master_replid和当前master不一致就会引起所有slave的全量同步。
举例 a master,b和c和d都为slave。当a挂掉后,手动将b提升为master。那么b作为a的slave的master_replid和b变成master的master_replid不同,c和d都要重新指向b生成新的master_replid并且同步b的数据。
配置如下
a systemctl stop redis
b replicaof no one→set key6 bbbb bind 0.0.0.0不要忘记
c,d replicaof <b的ip> 6379 bind 0.0.0.0不要忘记
实现redis的级联复制
配置依旧那么简单。还是abcd四兄弟,a作为master,b作为a的slave,作为c和d的smater。
a 啥都不需要配 bind 0.0.0.0 不要忘记
b replicaof <a的ip> 6379 bind 0.0.0.0不要忘记
c,d replicaof <b的ip> 6379 bind 0.0.0.0不要忘记
主从复制优化
全量复制过程:从服务器从主服务器同步数据,从服务器还可以有从服务器。当主服务器收到从服务器同步请求时,fork出子进程执行bgsave,将数据写入rdb中,把rdb文件给slave。然后缓冲区的内容以redis协议格式再给slave。slave先删除旧数据,然后将rdb放入内存,再加载缓冲区内容,从而完成全量同步。
增量复制过程:全量之后再次同步时,从服务器发送当前的offset位置给主服务器,让后主服务器把offset之后的数据给slave。
所说的缓冲区需要配置-----开启即可。一个是设置缓冲区大小,一个是设置slave没有同步需求,可以释放环形队列

避免全量复制
1 第一次全量必不可少,后续在业务低峰时全量
2节点进行ID不匹配:master重启导致runid变化,可能触发全量复制,可以利用哨兵或者集群
3 缓冲区不足:master生成的新数据大于缓冲区大小,从节点恢复和主节点连接后,会导致全量,解决方法调大缓冲区大小
避免复制风暴
1.单master复制风暴:主节点重启,所有从节点重新复制。解决思路:从节点建立从节点,master---slave---slave的slave
2.单机器复制风暴:宕机后,大量全量复制。解决思路:多个master
优化配置
repl-diskless-sync no 不用无盘同步rdb,先保存在磁盘在发送slave
repl-diskless-sync-delay 5 diskless时复制服务器等待的延迟时间
repl-ping-slave-period 10 slave向server端发送ping的时间间隔
repl-timeout 60 主从连接超时时间
repl-disable-tcp-nodelay no no是master立即发送同步数据,没有延迟,数据一致。yes是合并小tcp包节省带宽,会增加同步延迟,数据会不一致。
repl-backlog-size 1mb master的写入数据缓冲区,计算公式=每秒写入大小*允许从节点最大中断时间
repl-backlog-ttl 3600 slave没有连接到master的时间,repl-backlog-size 释放。值为0,永不释放
slave-priority 100 当master故障时选择slave来进行恢复,数字越小优先级越高。如果值为0,那么不会被选择
min-replicas-to-write 1 一个master的可用slave不能少于多少个,否则master无法写入
min-slaves-max-lag 20 有多少数量的slave延迟大于多少秒是,master不接受写入
redis哨兵(sentinel)
主从架构问题:1主从无法故障无法自动切换,用户无感知不影响业务2主从无法横向扩展的并行写入性能
redis集群实现方式:
客户端分片:由应用决定将不同的key发送到不同redis服务器上
代理分片:有代理决定将不同的key发送到不同redis服务器上
redis cluster:多个master
sentinel原理
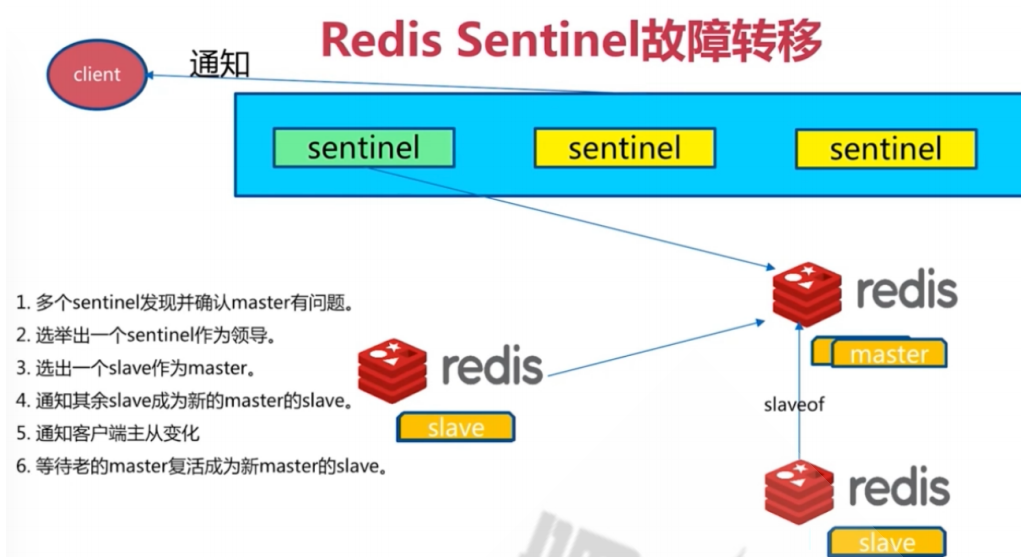
开始部署哨兵服务器☺----sentinel就是个特殊的redis服务器,所以一般和redis部署在一起(可以分开,配置指向redis就可以啦)。因为需要依靠redis主从,所以就用上面的主从架构
a,b,c sed -i 's#127.0.0.1 6379 2#192.168.89.130 6379 2#g' /etc/redis-sentinel.conf
a,b,c systemctl enable --now redis-sentinel.service
搞定了是不是很简单,现在验证下端口(哨兵端口26379)
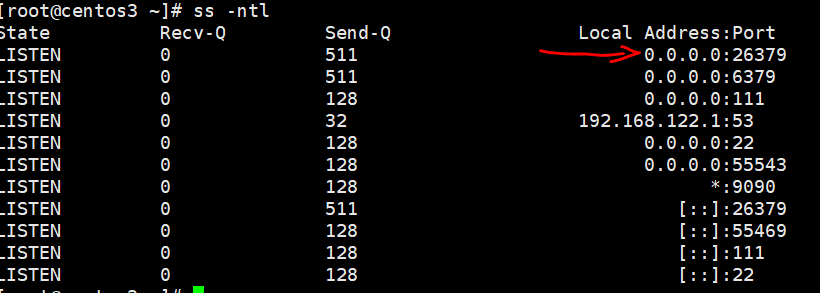
可以查看日志-----cat /var/log/redis/sentinel.log
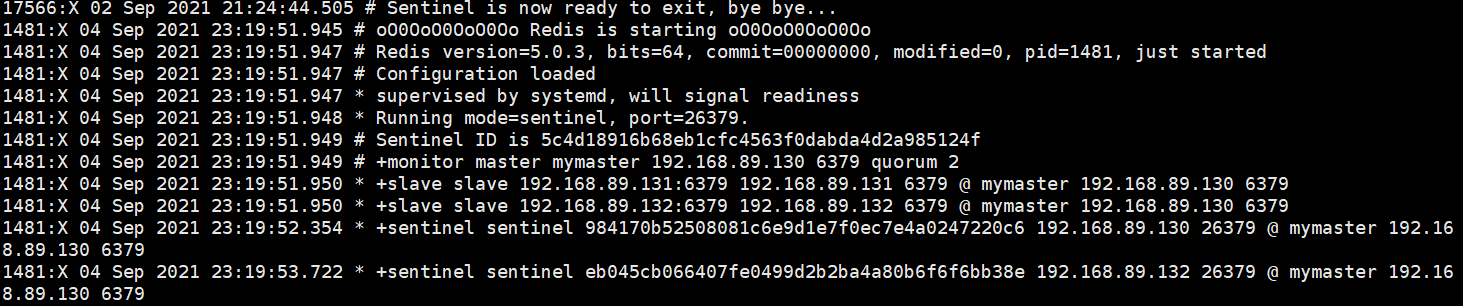
测试redis master故障能够转移
a killall redis-server
再次查看 /var/log/redis/sentinel.log
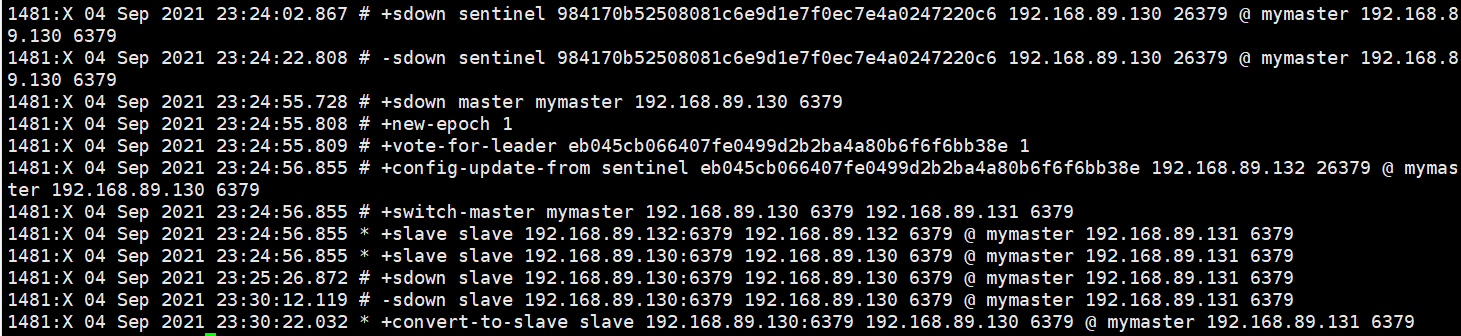
可以看到redis master变化了,将a的服务再起来,a变成了slave,b变成了master,c指向了b
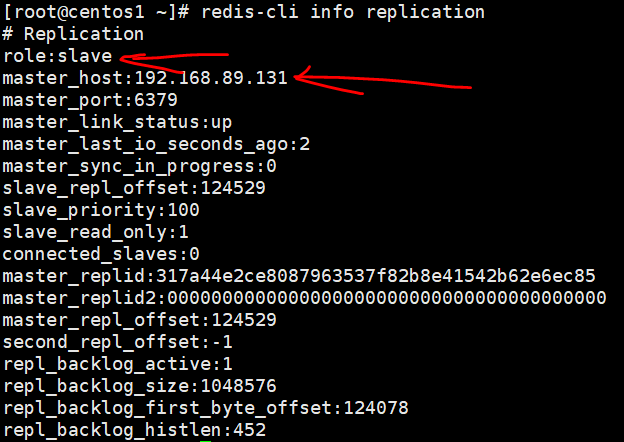
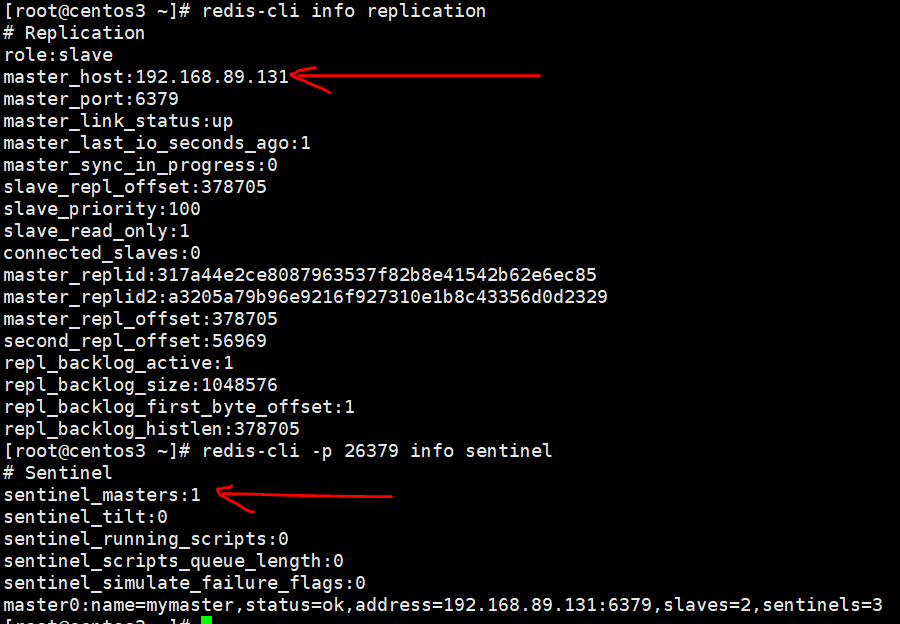
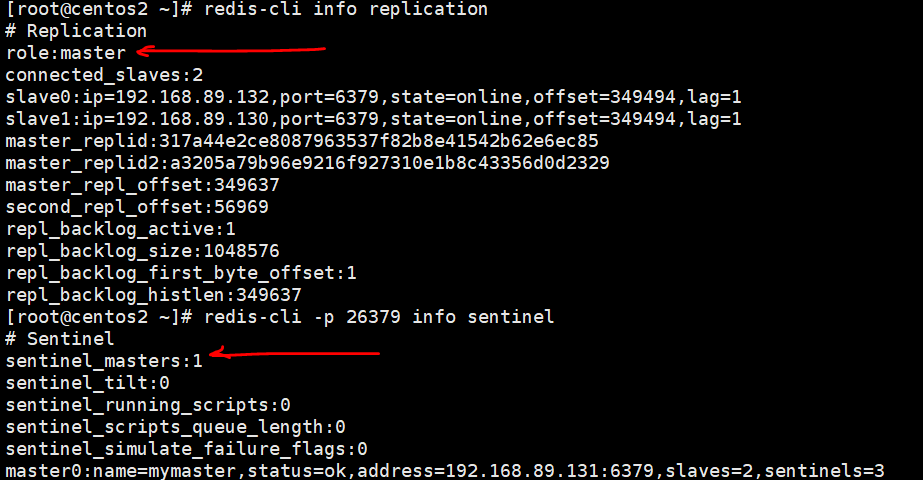
sentinel运维

1.这个在前面介绍过了,值越小优先变成master
2.redis-cli -p 26379 sentinel failover mymaster
java连接sentinel(我不会哈哈)
https://github.com/redis/jedis/blob/master/pom.xml
python连接sentinel
yum install python3 python3-redis
vim /etc/sentinel_test.py
#!/usr/bin/python3
import redis
from redis.sentinel import Sentinel
sentinel = Sentinel([('192.168.89.130',26379),('192.168.89.130',26379),('192.168.89.130',26379)],socket_timeout=1)
master = sentinel.discover_master('mymaster')
print(master)
slave = sentinel.discover_slaves('mymaster')
print(slave)
master = sentinel.master_for('mymaster',socket_timeout=1,db=0)
w_ret = master.set('name','zhangsan')
slave = sentinel.slave_for('mymaster',socket_timeout=1,db=0)
r_ret = slave.get('name')
print(r_ret)
~

redis cluster
sentinel虽然解决了master故障自动将slave提升为master,但是无法解决redis单机写入的瓶颈问题。
cluster特点
1.所有redis节点ping互联
2.集群中某个节点的是否失效,由集群超过半数的节点检测都失效才算真正的失效
3.客户端不需要proxy即可直接连接redis,应用程序需要配置全部的redis服务器ip
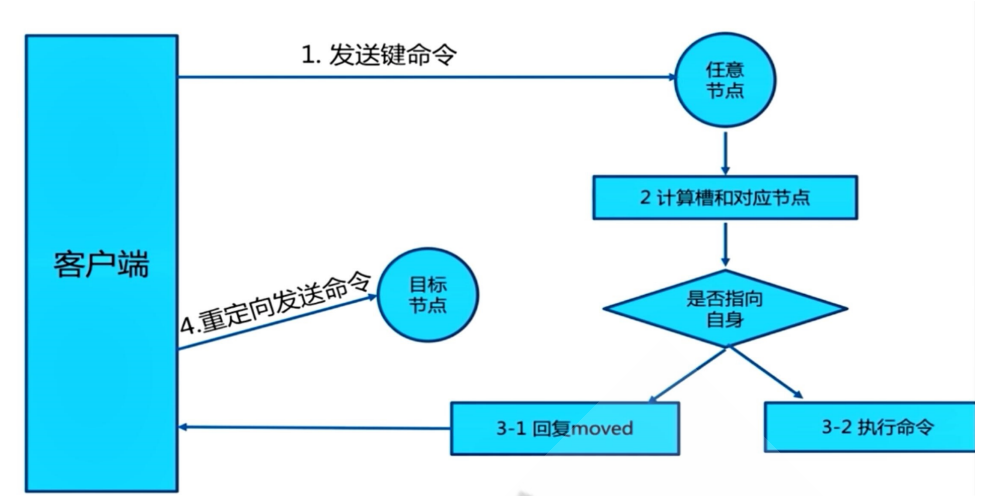
4.redis cluster把所有的redis node平均映射到0-16383个槽位上(slot),读写需要到指定的node上进行操作,相当于有多少个redis node就等于redis并发扩展了多少倍,每个redis node承担16384/N个slot
5.redis cluster月线分配16384个slot,当需要在集群写入一个key-value时,会使用key mod 16384之后的值,决定将key写入至哪个slot从而决定写入哪个node,从而解决单机瓶颈
简单架构如下
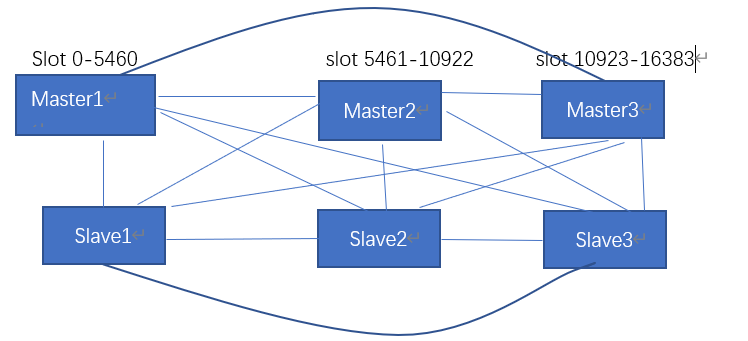
redis cluster部署有3种方式-------------------------基于5版本
1 原生命令安装 生产不适用
2 官网工具安装
3 自主研发
--------------------------------------
重点官方工具安装
--------------6个节点 192.168.89.140-145
→1 vim /etc/redis.conf配置
bind 0.0.0.0
masterauth 123456
requirepass 123456
cluster-enabled yes 开启
cluster-config-file nodes-6379.conf 集群状态文件
cluster-require-full-coverage no
→2创建集群 每个master对应一个slave
[root@]# redis-cli -a 123456 --cluster create 192.168.89.140:6379 192.168.89.141:6379 192.168.89.142:6379 192.168.89.143:6379 192.168.89.144:6379 192.168.89.145:6379 --cluster-replicas 1
→3验证集群
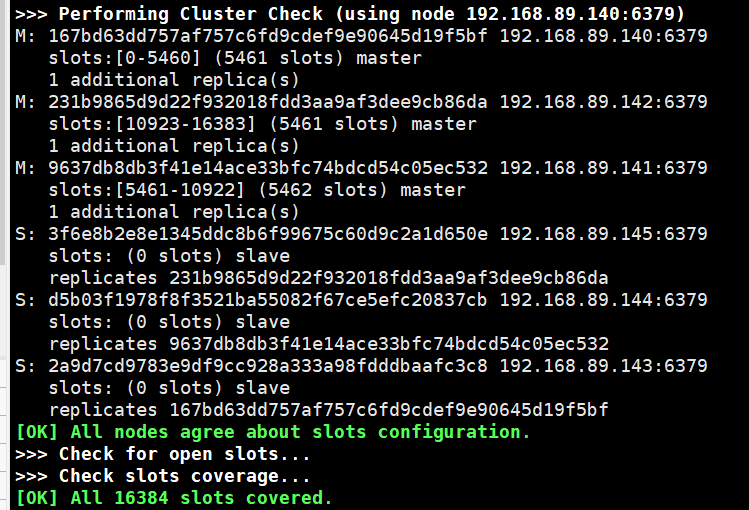
→4查看主从关系
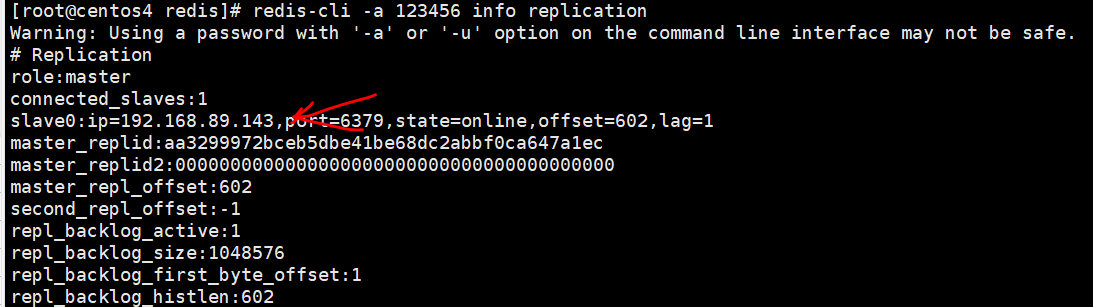
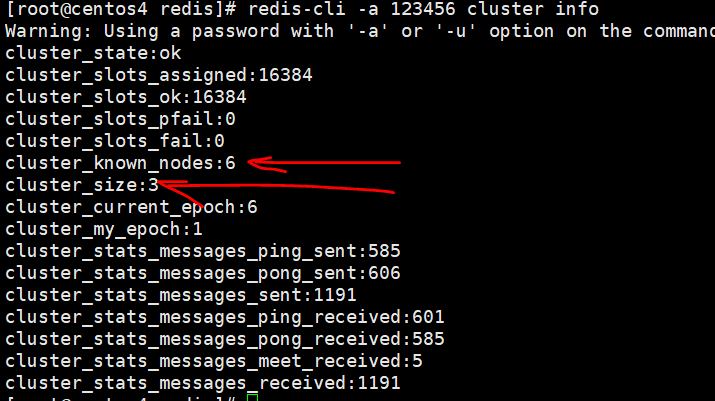
→5验证集群写入key

→6计算key的slot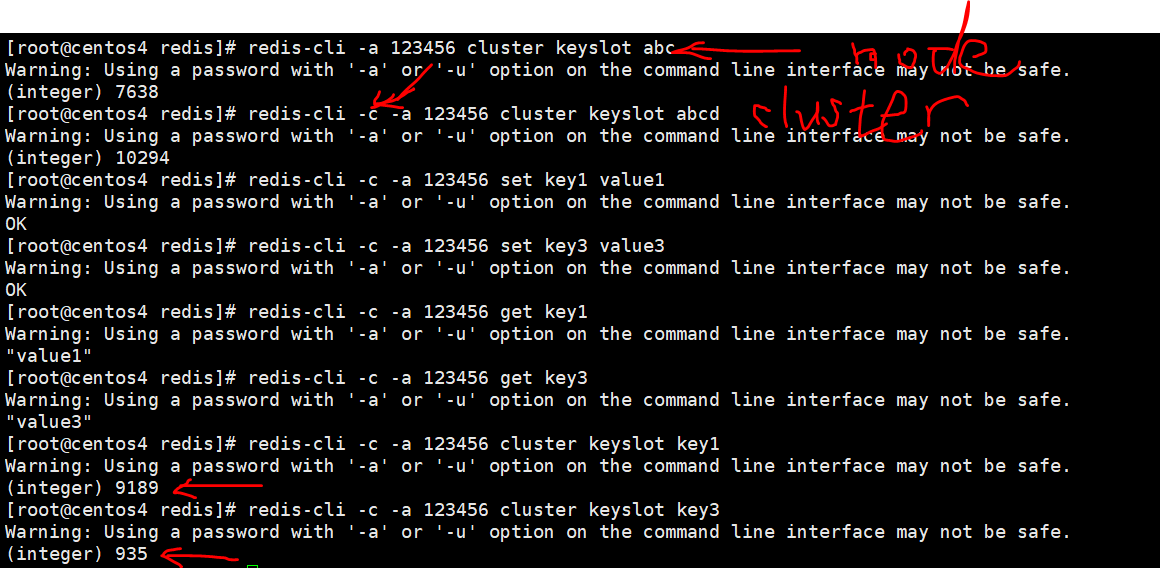
→7故障测试 (192.168.89.140关闭redis,对应的slave节点143状态变化),192.168.89.140重启redis后两节点之间的变化


集群维护
→1集群动态扩容。可以在任何节点添加比如添加146节点。配置需要和已有节点一样,不再重复讲了
[root :]redis-cli -a 123456 --cluster add-node 192.168.89.146:6379 192.168.89.141:6379
###新添加的master没有槽位,所以需要重新分配,但是注意重新分slot会清空数据,请先备份
[root :]redis-cli -a 123456 --cluster reshard 192.168.89.141:6379 这里可以为集群的任何节点
how many slots do you want to move(from 1 to 16384)? 新分配多少slot=16384/master个数 这里就是4096
what is the receiving node ID?新的master ID 241b1730bfaba6e63171069e391ff301ef4ac078
source node #1: all
do you want to proceed with the proposed reshard plan (yes/no) yes
##吧新的节点147作为146的slave加入集群
redis-cli -a 123456 --cluster add-node 192.168.89.147:6379 192.168.89.141:6379 --cluster-slave --cluster-master-id 241b1730bfaba6e63171069e391ff301ef4ac078
→2集群动态缩容。首先将被删除的node上的slot迁移到其他node上,然后删除被迁移的mater必须没有数据,否则报错并强制终端
##选择将147节点的slot平均分给3个master-(140,141,142)
redis-cli -a 123456 --cluster reshard 192.168.89.147:6379 将147的1365个slot分给master141
how many slots do you want to move(from 1 to 16384)?1356
what is the receiving node ID? 9637db8db3f41e14ace33bfc74bdcd54c05ec532
do you want to proceed with the proposed reshard plan (yes/no) yes
redis-cli -a 123456 --cluster del-node 192.168.89.146:6379 241b1730bfaba6e63171069e391ff301ef4ac078

 浙公网安备 33010602011771号
浙公网安备 33010602011771号