GraphRAG为什么能提升RAG检索准确率
1、传统RAG检索的问题
在 https://www.cnblogs.com/twosedar/p/19036833 中讲述了为什么RAG技术可以缓解大模型知识固化和幻觉问题。
但是传统RAG技术存在一个天然缺陷,即信息检索可能不准确或者不全面。具体原因可以通过下图中一个简化的例子来看一下:
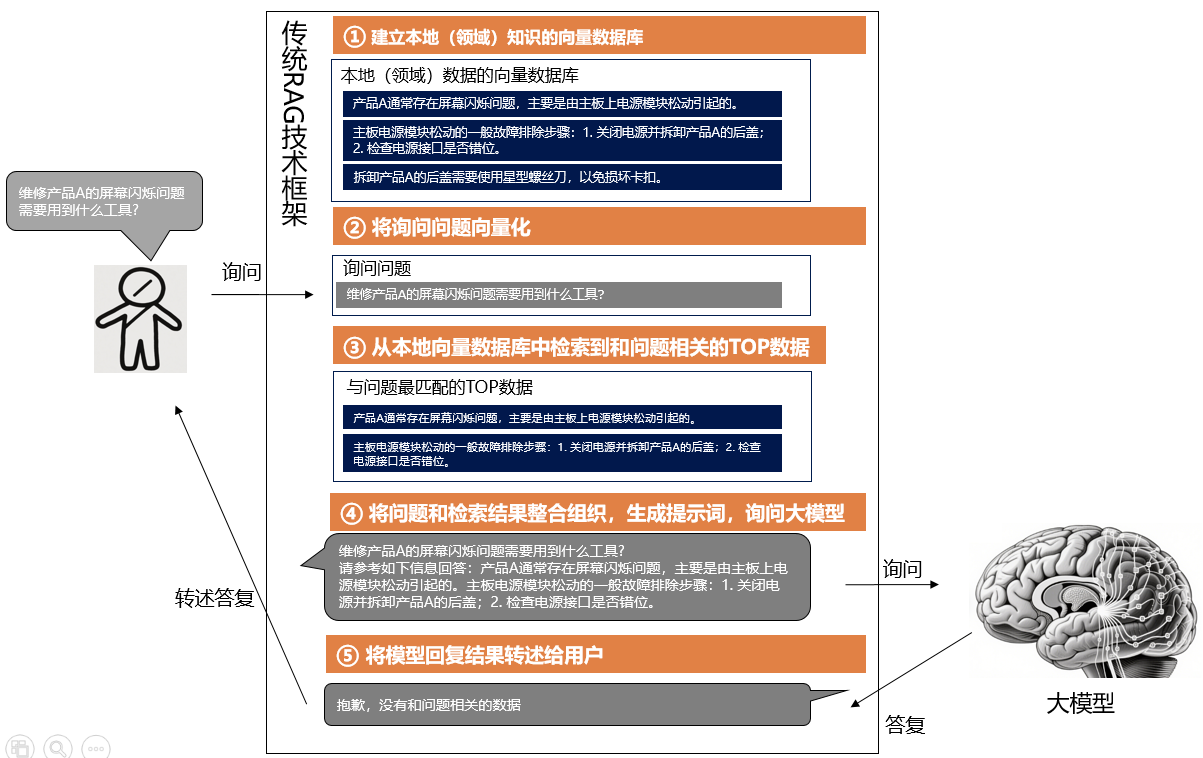
第①步: 对领域化的知识进行向量条目化处理后,包括以下三条知识:
“产品A通常存在屏幕闪烁问题,主要是由主板上电源模块松动引起的。”
“主板电源模块松动的一般故障排除步骤:1. 关闭电源并拆卸产品A的后盖;2. 检查电源接口是否错位。”
“拆卸产品A的后盖需要使用星型螺丝刀,以免损坏卡扣。”
第②步: 用户询问了一个问题:“维修产品A的屏幕闪烁问题需要用到什么工具?”
第③步: 根据询问的问题,RAG技术从实时信息向量数据库中检索与问题相关的TOP数据。
问题是,根据文本的向量化比较,真正的答案和问题在向量空间上可能距离较远。
从文字上看,“维修产品A的屏幕闪烁问题需要用到什么工具”和“拆卸产品A的后盖需要使用星型螺丝刀,以免损坏卡扣”这两句话的相似度确实不高。
结果就是真正的答案就没有被检索出来。
第④步: 然后将一组和问题关系不大的问题和数据整合组织,生成提示词,询问大模型。
第⑤步: 大模型要么虚构给出一个答案,要么回答“抱歉,没有和问题相关的数据”。
所以对于传统RAG技术,很容易回答答案存储在某个信息片段中的这类具体问题,但是对于需要对总体知识又把控的情况的问题,回答效果不好。
2、为什么GraphRAG可以提升检索准确率
那么GraphRAG如何解决这个问题呢?参考下图:
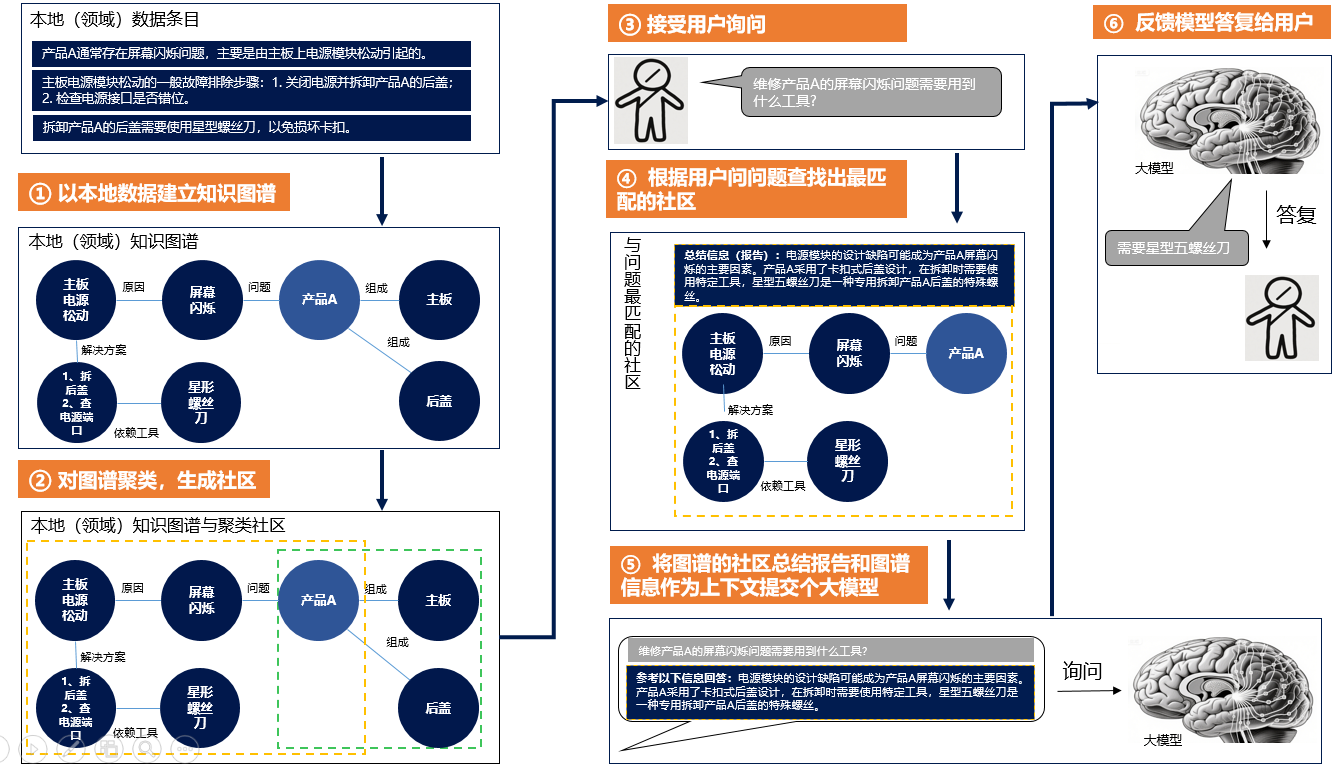
第①步: GraphRAG会先将本地数据条目作为输入,构建一个本地知识图谱。所谓知识图谱,就是以图的方式,把现实中各种事物之间的相互关系连接起来的一张知识网。知识图谱主要由实体(节点)和关系(节点之间的连线)组成。
例如上图中,本地的三句话知识经过图谱抽取后,就形成了由7个节点组成的图谱。
第②步: 由于数据量庞大,生成的知识图谱会非常大,显得杂乱。于是GraphRAG把杂乱的知识先分组,这样方便知识检索者能够快速找到最相关的一小堆信息用于回答。
第③步: 在第①、②步完成后,GraphRAG就可以接受用户询问了。
第④步: GraphRAG会根据问题先找到最匹配的社区。
第⑤步: 将社区的总结信息,GraphRAG称之为“报告”,作为上下文信息,一起发送给大模型进行询问。
第⑥步: 大模型给予回复。
从上面的示例可以看出,由于GraphRAG将碎片化的信息通过知识图谱连接起来,所以就解决了知识碎片化的问题,让回答更为准确、合理。
3、GraphRAG是什么?
GraphRAG是由微软研究院在2023年末提出的一种新技术,其开发目的是解决传统RAG在应对复杂、全局性查询时的不足。并于2024年4月份发表了论文:https://arxiv.org/abs/2404.16130
4、GraphRAG具体做了什么?
① 利用大模型构建知识图谱。
② 利用(此处原句缺失动词,推测为“利用大模型”)生成知识图谱摘要。
③ 将摘要和图谱信息作为上下文的一部分,提交给大模型,获取答案。
备注: 以上部分涉及GraphRAG技术细节,所以上名图中并没有体现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号