2025.02 做题记录
1. CF868F Yet Another Minimization Problem
难度:1.5
首先可以很快列出方程。设 \(dp_{j,i}\) 表示考虑将 \([1,i]\) 拆成 \(j\) 段的最小代价。设 \(w[i,j]\) 表示区间 \([i,j]\) 的代价。
则有转移:
直接做是 \(O(n^2k)\),考虑优化。
感觉不太能优化?感觉斜率优化、DS优化啥的都用不了。试一试决策单调性吧。
需要证明,对于任意 \(i,j\in[1,n],j\ge i+3\):
发现很好证啊,按照定义直接拆开。要证上式,只要证:
两边一消。只要证:
真的显然成立。
所以可以用决策单调性解决。
我们先把 \(j\) 这一维循环给甩到最外面。然后考虑从 \(j-1\to j\) 的转移。设 \(k_i\) 为 \(i\) 的最优决策点。
我曾有一个疑问就是为什么不可以直接双指针线性解决?既然已经有了决策单调性了,就维护一个指针指到当前决策点,然后往后扫,直到扫到被转移点的最优决策点为止。然后发现没法判断是否是被转移点的最优决策点,遂卒。
所以考虑用分治解决。对于区间 \([l,r]\) ,我们找到他的中间点 \(mid\) 并求出 \(k_{mid}\),再分治下去。因为有决策单调性,所以有 \(k_{l-1}\le k_{mid}\le k_{r+1}\),所以只用在这个范围内枚举即可。
然后如何求出 \(w[x,mid]\),考虑用莫队动态维护。发现左右端点的移动次数都是 \(O(n\log n)\)。
所以总时间复杂度 \(O(kn\log n)\)。
2. [IOI2000] 邮局
Easy版: [IOI 2000] 邮局(原始版)
Medium版: [IOI 2000] 邮局 加强版
Hard版: [IOI 2000] 邮局 加强版 加强版
难度:0/0.5/1.5
题意是一样的,只是数据范围有差异。
先看 Easy 版,设 \(dp_{j,i}\) 表示考虑了前 \(i\) 个村庄,建设了 \(j\) 个邮局的最小代价。
则有转移:
而给出的数据是有序的,所以可以记录 \(pre_i=\sum_{i=1}^n d_i\)。设 \(mid=\lfloor\frac{l+r}{2}\rfloor\),则 \(w(l,r)=(mid-l+1)\times d_{mid}-(pre_{mid}-pre_{l-1})+(pre_r-pre_{mid})-d_{mid}\times (r-mid)\)。可以 \(O(1)\) 得到。
所以时间复杂度 \(O(n^2k)\),其中 \(n\) 为村庄个数,\(k\) 为邮局个数。可以通过 Easy 版。
现在考虑优化。发现有 建恰好k个邮局 的条件,想到wqs二分,找一找凸性质。根据打表,答案函数是一个下凸函数。
所以考虑用wqs二分优化,check 函数里类似 Easy 版的转移。时间复杂度 \(O(n^2\log k)\)。可以通过 Medium 版。
但还有另一种优化思路。重点在 \(w(l,r)\) 上。
这个东西满不满足四边形不等式呢?
也就是对于 \(l,r\in[1,n],r>l+2\) ,满足:
写成差分形式,有:
分类讨论区间长度奇偶性:
-
若 \(r-l+1\) 为奇数
设 \(mid=\frac{(l+r)}{2}\)。
则 \([l,r]\)、\([l,r-1]\)、\([l+1,r]\)、\([l+1,r-1]\) 的中位数都可以是 \(d_{mid}\)。
所以有 \(w(l,r)-w(l,r-1)=w(l+1,r)-w(l+1,r-1)=d_r-d_{mid}\)。
-
若 \(r-l+1\) 为偶数
设 \(mid=\frac{(l+r-1)}{2}\)。
则 \([l,r]\)、\([l,r-1]\) 的中位数都可以是 \(d_{mid}\)。\([l+1,r]\)、\([l+1,r-1]\) 的中位数都可以是 \(d_{mid+1}\)。
所以有 \(w(l,r)-w(l,r-1)=d_r-d_{mid},w(l+1,r)-w(l+1,r-1)=d_r-d_{mid+1}\)。
因为 \(d_r-d_{mid}\ge d_r-d_{mid+1}\),所以\(w(l,r)-w(l,r-1)\ge w(l+1,r)-w(l+1,r-1)\)。
综上得证。
然后就有决策单调性。对于上述的二维转移,则可以用分治处理。设 \(K_i\) 为 \(i\) 的最优决策点。对于一个区间,先算出 \(K_{mid}\),再递归到左右子区间。
对于区间 \(i\in[l,r]\),一定有 \(K_{l-1}\le K_i\le K_{r+1}\)。所以直接分治即可。(不用wqs二分)
时间复杂度 \(O(kn\log n)\)。
现在考虑 Hard 版。
其实发现 Medium 版的两个方法可以合并的,然后时间复杂度就是对的。
但是有一个问题。就是在上文给出的分治求决策单调性优化需要满足 转移跟枚举转移顺序无关。也就是说因为是一个二维dp,在处理 \(dp_{j,i}\) 的转移时,我们已经直到 \(dp_{j-1,k}\) 的所有值了,也就跟转移顺序无关。
但是用wqs二分时,check函数里应该是一维dp。因为没有个数限制了。
转移式子(\(val\) 是wqs二分的值):
如果还按分治的方法做,我们都不知道 \(dp_{K_i}\) ,怎么转移到 \(dp_i\) 啊。
所以考虑用 二分答案+单调队列 解决。
我们考虑动态维护更新数组 \(K\)。如一开始,我们让 \(K=\{1,1,1,...\}\),因为只能从 \(1\) 转移。但更新 \(2\) 了以后,\(K\) 的某一个后缀会全部更新成 \(2\),即 \(K=\{1,1,1,2,2,...,2\}\),以此递推。
所以考虑用单调栈维护顺序出现的所有 \(K\) 值。然后记录每一种 \(K\) 值出现的第一个位置。
然后更新时,就从队尾开始,如果队尾的 \(K\) 值的第一个位置 用新的 \(K\) 值转移更优 就把队尾删去。一直删,直到新的值更劣为止。然后再在 \([队尾的 K 值出现的第一个位置,n]\) 中二分答案,找到第一个用新的 \(K\) 转移更优的位置,记录下来。将新的 \(K\) 值放在队尾。
然后转移到 \(i\),就判断队首的后一个 \(K\) 值出现的第一个位置是否小于等于 \(i\),如果小于等于就弹出队首。然后拿新的队首转移。
这样就可以做到 \(O(n\log n)\) 的check。
所以时间复杂度 \(O(n\log n\log V)\)。然后wqs二分上界为 \(0\),下界取 \(-nV=-10^{12}\) 保险。
3. CF1031F Familiar Operations
难度:1
模拟赛没改的题,搁置了一个月,还是改了。*2800,放在T4。
考场上糊了一堆贪心,然后假了。
钦定一个阈值 \(W\),下面所有操作中的数都只讨论 \(\le W\) 的情况。
因为因子个数只跟质因数的指数有关。因为 \(因数个数=\Pi (质因数指数+1)\)。所以我们对于一个数 \(w=p_1^{r_1}p_2^{r_2}...p_k^{r_k}\) 将 \(r_i\) 提出来,再从大到小排序,从而生成一个数组。
而发现生成的数组有很多是重复的,而相同的数组的因子个数又是相同的,所以可以直接去重。去重后,发现不同的数组个数很少。当 \(w\le 10^6\) 时,只有 \(289\) 个。反正就是很少。
那么现在可以进行乘一个质数或者除以一个质因子的操作就相当于在生成这个序列中的某一个位置 \(+1\) 或 \(-1\),并且代价为 \(1\)。
那么可以考虑用图论解决。因为加一和减一是可逆的,所以就只用考虑向减一后的数组建一条边权为 \(1\) 的双向边即可。
而又想让因子个数相同。那么可以建立一些点代表这因子个数。让每一个数组被 代表它的因子个数的点 连一条边权为 \(0\) 的单向边。
再从每一个代表因子个数的点出发,跑单源最短路。
这样对于每一次查询 \((x,y)\),就可以求出 \(x\) 生成的数组 \(a\) 和 \(y\) 生成的数组 \(b\)。然后枚举代表因子个数的点 \(k\),则答案为 \(\min dis_{k,a}+dis_{k,b}\)。
大体思路确定,现在考虑实现。
处理代表数组的点的方式有点类似与AT_arc057_d 全域木 的实现方式。先用dfs求出每一个不同的数组,然后处理出它的因子个数,存下来。
求这个数组时,为了使得直接判断这个数组是否存在,即是否存在一个数 \(w\le W\) 使得 \(w\) 生成的数组是这个数组,我们只取前几个质数,让数组中的数从大到小依次成为从小到达的几个质数的指数,如果这个乘积 \(\le W\) 则存在。
然后将每一个数组的因子个数预处理出来并离散化,并编上号,要与数组的点的编号不同。
然后就是数组与数组之间的边了。为了方便,我们对于前几个质数随机一个值 \(hsh_i\),则一个数组的哈希值为 \(\sum_{i=1}^k hsh_i\times r_i\),这样就可以让数组与一个值之间建立双射。
我们要让数组内一个数减一,为了让减一后该数组还是有序的,如果有一段相同的数,我们要减只减最后一个位置。找到哈希值为原数组哈希减去该位置的 \(hsh\) 值的数组点,连一条边权为 \(1\) 的双向边。
然后就以每一个代表因子个数的点跑单源最短路。可以用01bfs或者Floyd。
那么对于查询 \((x,y)\),先将 \(x,y\) 分解质因数,然后将质因数指数从大到小排序,找到对应的数组点 \(a\) 和
\(b\)。然后枚举因子个数的点 \(p\),则答案为 \(\min dis_{p,a}+dis_{p,b}\)。
\(W\) 取 \(10^8\) 能保证正确性。此时因子个数有 \(190\) 种,数组有 \(803\) 种。
设 \(n\) 为不同数组个数,\(m\) 为不同因子个数。则时间复杂度 \(O(nm+tm\sqrt V)\)。
瓶颈在于分解质因数。改为线性筛分解质因数可以优化到 \(O(nm+tm\ln V)\)。
跑得非常快。是目前洛谷最优解&学校OJ最优解。
4. P2305 [NOI2014] 购票
难度:2.5
还是挺难的,搞了几遍才搞懂。从除夕搞到初十,也是终于会了。
这里只介绍出栈序+线段树套李超树的做法。
首先,不要读错题了,注意是从根向叶子转移,而不是从叶子向根转移。
先列出 \(dp\) 式子。记 \(dis_u\) 为 \(u\) 到根的距离。则有:
改一下,则有:
然后发现这个式子可以斜率优化,用李超树维护。
先考虑部分分吧。
性质1:构成链
考虑用线段树套李超线段树,对于 \(i\),找到它最远的祖先 \(j\) 使得 \(dis_i-dis_j\le l_i\)。然后从 \([i,j]\) 里转移。
李超树需动态开点。
时间复杂度 \(O(n\log ^2n)\),空间复杂度 \(O(n\log n)\)。
性质2:不考虑 \(l_i\) 的限制
可以考虑可持久化李超树,对于每一个节点的李超树为其父亲节点修改而成。最多只更改 $\log $ 个节点,所以可以做。
时间复杂度 \(O(n\log n)\),空间复杂度 \(O(n\log n)\)。
正解
现在有 \(l_i\) 的限制,怎么做?可能会用到树剖或者其它东西来处理。
这里就需要用出栈序了。
出栈序就是dfs中退出一个节点时将这个节点存入后形成的序列。
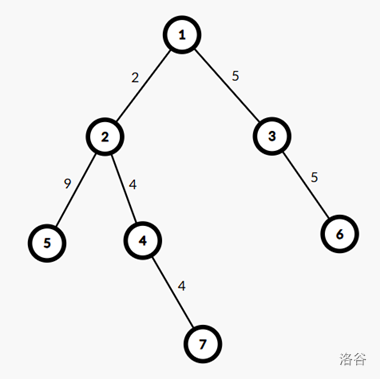
这是样例1的图。
我们以 \(1\to 2\to 5\to 4\to 7\to 3\to 6\) 的顺序dfs。
那么它的出栈序为: \(5\ 7\ 4\ 2\ 6\ 3\ 1\)。记为 \(st\) 数组。并类似性质1的方式对该式构建线段树套李超树方便转移。
现在我们要对 \(i\) 找到最远且满足要求的祖先 \(j\)。就如 \(i=5,j=1\)。
此时在出栈序中,\(st_1=5,st_7=1\),我们取区间 \([1,7]\) ,但是中间有一些数并不在 \(5\) 到 \(1\) 的路径上。这怎么办?
我们发现,如果我们按上面dfs的顺序去依次更新 \(dp\) 值,并在每一次更新完后插入对应位置的几个李超树,这样并不会对答案造成影响。
因为所有不在这条路径上的点都没有被更新过。
所以根据此结论,我们可以先处理出出栈序,并按原先dfs的顺序更新 \(dp\) 值。
更新 \(u\) 的值时,找到它最远且距离 \(\le l_u\) 的祖先 \(fa\),找到 \(u\) 和 \(fa\) 在出栈序中对应的位置,然后对该区间进行查询更新 \(dp\) 值。更新完后又更新李超树上的值。
时间复杂度 \(O(n\log^2n)\),空间复杂度 \(O(n\log n)\)。
5. P3081 [USACO13MAR] Hill Walk G
难度:2
有点绕,脑袋一时半会儿没想到。
首先不能直接李超线段树,因为李超线段树只能记录最大值。而可能会出现这样的情况:当前在 \((x1,y1,x2,y2)\) 这条线段上,但是存在一条 \((x3,y3,x4,y4)\) 满足 \(y3>>y1\),\(y4>>y2\),\(x3\le x2<x4\)。也就是在这条线段的头顶上。
显然我们不能从第一条线段到第二条线段。所以不能直接找 \(x2\) 这个位置的最大值。
可以注意到第二条线段是不可达的,无论如何。所以考虑将不可达的线段都不加入李超线段树。
如果可能能从 \((x1,y1,x2,y2)\) 到达 \((x1',y1',x2',y2')\),那么必须有 \(x1'\le x2<x2'\),且后者在 \(x=x2\) 的取值要 \(<y2\)。
而在不断往后跳线段的过程中, \(x2\) 是递增的。
所以考虑将所有线段按 \(x1\) 从小到大排序。对于 \(x1\le 当前x2\) 的线段判断是否满足上面的要求,如果满足要求再加入李超树中的 \([x1,x2-1]\)。
这样就可以直接查在 \(x=x2\) 处的最大值了。
时间复杂度 \(O(n\log^2n)\)。但是线段之间不相交,所以可以改成线段树,时间复杂度 \(O(n\log n)\)。
6. P4069 [SDOI2016] 游戏
难度:2
将 \((u,v)\) 的路径拆成 \((u,lca)\) 和 \((lca,v)\)。
记录 \(dis_u\) 为 \(u\) 到根的距离。
则对于 \((u,lca)\) 上的点 \(i\),加入的直线为 \(a\times(dis_u-dis_i)+b=-a\times dis_i+(a\times dis_u+b)\)。斜率为 \(-a\),截距为 \(a\times dis_u+b\)。
对于 \((lca,v)\) 上的点 \(i\),加入的直线为 \(a\times(dis_u+dis_i-2dis_{lca})+b=a\times dis_i+a\times (dis_u-2dis_{lca})+b\)。斜率为 \(a\),截距为 \(a\times (dis_u-2dis_{lca})+b\)。
现在考虑树剖维护。我们只对一条链进行操作,而这条链上的 \(dis\) 值是单增的,所以可以离散化为李超树的下标。
我们需要查询区间最小函数值,所以记录一个最小函数值,每一次修改都上传一下即可。
因为李超树是永久化标记,则对 \([L,R]\) 查询时需注意对于区间 \([l,r]\) 满足 \(l<L\) 或 \(r>R\) 时也要对它在 \(L\) 或 \(R\) 处的取值统计在内。因为查询的可能不是一个整链。
时间复杂度查询 \(O(n\log^2n)\),修改 \(O(n\log^3n)\)。
7. CF1303G Sum of Prefix Sums
难度:0.9
树上大量路径处理问题,考虑点分治。
设有向路径 \((k_1,k_m)\) 依次经过点 \(\{k_1,k_2,...,k_m\}\),则权值为 \(\sum_{i=1}^m i\times w_{k_i}\)。
考虑经过分治中心 \(rt\) 的路径。设 \(p\) 为 \(v\) 的祖先,且为 \(rt\) 的儿子,则可以将有向路径 \((u,v)\) 拆成 \((u,rt)\) 和 \((p,v)\) 。
分治中,对于每一个节点处理出 \(pre_u\),\(suf_u\),\(sum_u\)。
设 \((u,rt)\) 经过 \(\{k_1,k_2,...,k_m\}\),则有:
设 \(d_{u}\) 为 \(u\) 的深度(根为 \(rt\) 时),那么对于路径 \((u,v)\) 的权值就为 \(pre_u+(d_u-d_{rt}+1)\times sum_v+suf_v\)。
如下图。

考虑用 \(suf_v\) 去匹配之前的 \(u\) 从而找到最大的 \((u,v)\)。
发现上式的形式是一个直线的表达式,斜率为 \((d_u-d_{rt}+1)\),截距为 \(pre_u\)。所以考虑用李超线段树维护之前的 \(u\) 生成的直线,需要动态开点。然后找到 \(x=sum_v\) 处最大的直线,更新答案。
李超树每一次分治用完要清空。
还有一些细节要注意:因为是有向路径 \((u,v)\),则每一次分治需要从前往后和从后往前进行两次统计。然后还可能出现 \(u=rt\) 或 \(v=rt\) 的情况,需特判。
时间复杂度 \(O(n\log^2 n)\),空间复杂度 \(O(n)\)。
8. P7114 [NOIP2020] 字符串匹配
难度:1.5
自己的思路是枚举C,用KMP找出最短周期个数(AB最多能有多少个),然后对这个数找因数,再用树状数组求值。时间复杂度 \(O(nd(n)\log n)\)。只能拿 \(84\) 分。
正解的思路是枚举循环节(AB)的长度 \(i\)。
用exKMP求出 \(z\) 函数,则(AB)最多的个数为 \(1+\lfloor\frac{z_{i+1}}{i}\rfloor\)。
而C的起点可以是任意一个循环节后的一个位置。
如 \(i=3\),\(z_4=10\)。则循环周期为 \([1,3],[4,6],[7,9],[10,13]\)。那么C的起点可以是 \(4,7,10,14\)。
如果我们去枚举C的起点,再逐个计算时,时间复杂度会达到 \(O(n^2)\)。
考虑挖掘限制函数 \(F(X)\) 的性质。\(F(X)\) 是串 \(X\) 中出现奇数次的字符的个数。而C的起点在向左移时,每一次相当于增加了一个循环节,而每增加两个循环节,它的 \(F\) 值又会变回来。也就是说,循环节长度定了,\(F(C)\) 的值最多又只有两个。
可以通过计算得到这两个 \(F\) 值对应的位置个数。记 \(num=\lfloor\frac{z_{i+1}}{i}\rfloor\)。则与最靠右的C的起点的 \(F\) 值相同的点有 \(\lfloor\frac{num}{2}\rfloor+1\),与另一个 \(F\) 值相同的点有 \(\lfloor\frac{num+1}{2}\rfloor\)。
直接用树状数组计算两个 \(F\) 值得权值,并将系数乘上即可。
需要注意,C不能为空,如果最靠右的C的起点 \(>n\),则需要删掉最后一个循环节。让 \(num\gets num-1\),C起点位置 \(\gets\) C起点位置 \(-i\)。
时间复杂度 \(O(n\log n)\)。
9. P5563 [Celeste-B] No More Running
难度:0.5
zjk大佬&&学长 出的题,不过不是很难阿。
转化一下题意,也就是对于 \(u\) ,求出 \(\max_{v=1}^n (w(u,v)\% mod)\),其中 \(w(u,v)\) 为 \(u\) 到 \(v\) 的路径边权和。
大量的路径问题,考虑点分治。
以 \(O(\log n)\) 的代价,将问题加上限制:经过根节点的路径。
将 \((u,v)\) 拆成 \((u,rt)\) 和 \((v,rt)\)。
考虑如何快速合并路径的问题。如何使得取模后的值最大?参考 P6105 [Ynoi2010] y-fast trie 进行分类讨论。
设当前数为 \(a\),想找一个 \(b\),使得 \([(a+b)\% mod]\) 最大(\(0\le a,b<mod\))。
- 钦定 \(a+b\ge mod\),则答案为 \(a+b-mod\)。此时直接去找最大的 \(b\) 即可。
- 钦定 \(a+b<mod\),则答案为 \(a+b\)。找 \(<mod-a\) 且最大的 \(b\) 即可。
所以对每一个点求出它到根的路径权值和 \(\% mod\),存入树状数组。这样就可以直接查询。
时间复杂度 \(O(n\log^2n)\)。
10. UVA12161 铁人比赛 Ironman Race in Treeland
难度:0.7
没有翻译,要看英文题面。不过还是看得懂。也不算难。
题意:
一颗树,每条边有两个权值 \(cost\) 和 \(len\)。现在要找一条路径满足 \(\sum cost \le m\) 且 \(len\) 最大。输出最大的 \(len\)。
也是找路径,考虑点分治。
将 \((u,v)\) 分成 \((u,rt)\) 和 \((v,rt)\)。
枚举 \(v\) 处理出 \((v,rt)\) 的 \(cost\) 和 \(len\)。那么我们要在 \([0,m-cost]\) 的花销范围内找到最长的 \(len\)。
反过来想,以 \(len\) 为下标,开一颗线段树。每一个位置维护最小的 \(cost\)。然后查询时线段树二分,如果右儿子存在 \(<m-cost\) 的值则向右走,否则向左走。
但是有个问题,这个 \(len\) 的范围是 \(10^7\) 的,为了与当前点分治的连通块大小 \(sz\) 有关,考虑每一次点分治后先处理出当前所有的 \(len\),再离散化即可。
时间复杂度 \(O(n\log ^2n)\)。
11. P3714 [BJOI2017] 树的难题
难度:0.99
自己切的,但感觉好妙啊。
维护颜色段权值,且找权值最大且边数在 \([l,r]\) 的路径。记 \(val_i\) 为颜色 \(i\) 的权值。
同样考虑点分治。同样将 \((u,v)\) 拆成 \((u,rt)\) 和 \((v,rt)\) 并考虑合并。
以下称 \(u\) 到 \(rt\) 路径上 一个端点为 \(rt\) 的边 为 \(u\) 的顶边。记 \(len_v\) 为 \(v\) 到 \(rt\) 的边数。记路径 \((u,v)\) 的权值为 \(w(u,v)\)。
但是二者的权值不能直接相加,因为可能出现两个段合成一个段的情况,如下图一,两条橙色边合并就会变成一个段。
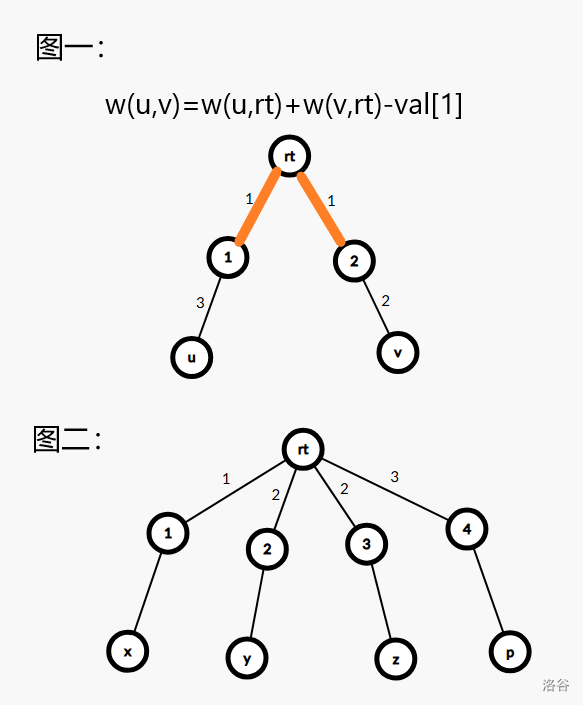
所以怎么做呢?
如图二,在对 \(z\) 进行配对时,如果配对的是 \(x\) 则权值就为 \(w(x,rt)+w(z,rt)\);但是如果配对的是 \(y\) 则权值就为 \(w(z,rt)+(y,rt)-val_2\)。二者权值计算方式有差异。
为了方便,我们用 vector 存图,并按边权排序,让颜色相同的边一起被遍历。就如图二给出的 \(rt\) 的连边,从左到右即为遍历顺序。
这样开两颗线段树 \(s1,s2\), \(s1\) 用于存储顶边颜色与当前枚举点的顶边颜色不同的子树的答案,\(s2\) 用于存储顶边颜色与当前相同的子树的答案。
两颗线段树的下标 \(i\) 上放的都是 \(\max w(u,rt)\) 满足 \(len_u=i\)。所以线段树大小就是当前连通块最大的深度,可以先处理出来。
这样进行查询时,设当前点为图二的 \(z\)。则 \(s1\) 存的是子树 \(1\) 的答案,\(s2\) 存的是子树 \(2\) 的答案。
那么与 \(z\) 匹配的最大值就是
然后如果当前顶边的颜色更变了,则需要将 \(s2\) 合并入 \(s1\) 并清空 \(s2\)。合并时,为保证时间复杂度,如果 \(s2\) 的一个儿子的最大值 \(=-inf\),则直接 return,不管它。
那么这样的时间复杂度是多少呢?大约是 \(O(sz\log sz)\),因为是 \(\sum{每颗子树大小}\times \log sz\)。
而查询又是 \(O(sz\log sz)\)。
所以总时间复杂度 \(O(n\log^2n)\)。
12. P11364 [NOIP2024] 树上查询
难度:2
考场上,自己得到了一个偏了的结论,就一直往这边想,结果没有去找其他性质。
首先一个显然的性质就是
可以用虚树的方式证明。然后我竟然没看出来?
然后就可以预处理出 \(dep[\operatorname{lca}(i,i+1)]\) 的值。
现在我们对于 \(dep[\operatorname{lca}(i,i+1)]\) 处理出极长区间 \([x_i,y_i,v_i]\),代表区间 \(dep[\operatorname{lca}[x_i,y_i]]=v_i=dep[\operatorname{lca}(i,i+1)]\)。有点类似一条线段。
这个东西用单调栈从前往后和从后往前扫一遍就可以处理。
那么查询 \([l,r,k]\) 时实际上就是找到合法且 \(v_i\) 最小的线段。
那么怎么找合法线段?进行分类讨论:
-
满足 \(r \le y_i\) 且 \(x_i\le r-k+1\)
则可以将线段对 \(y_i\) 进行排序,将询问对 \(r\) 进行排序。用线段树维护 \(x_i\) 在 \([1,r-k+1]\) 的最小 \(v_i\) 即可。
-
满足 \(l+k-1\le y_i<r\) 且 \(y_i-x_i+1\ge k\)
则可以将线段对 \(y_i-x_i+1\) 进行排序,将询问对 \(k\) 进行排序。用线段树维护 \(y_i\) 在 \([l+k-1,r-1]\) 的最小 \(v_i\) 即可。
实际上就是扫描线。
然后就做完了,挺简单的,码量也不是特别大。时间复杂度 \(O(n\log n)\)。
13. P7215 [JOISC 2020] 首都
难度:2
好像有一种树剖+线段树优化建图+缩点的做法。
就是枚举一种颜色 \(i\),如果颜色为 \(i\) 的两个点之间的路径会经过颜色 \(j\) 的点,则让 \(i\) 向 \(j\) 连边。
这个部分需要用树链剖分+线段树优化建图解决。
然后跑强连通分量缩点。则答案就是出度为 \(0\) 且大小最小的强连通分量的大小。时间复杂度 \(O(n\log^2n)\)。
不过不够优雅。
我们从链的性质入手,发现可以进行分治。考虑必须取中间这个位置时的最小代价。然后再分治到左右两边,再进行分治。
现在放在树上也一样,考虑用点分治。钦定必须选分治中心 \(u\)。先处理出该分治连通块内每个点的父亲。开一个队列维护要取的颜色,将 \(col_u\) 放入队列。
然后每一次从队列里取出一种颜色,将它的所有点判断是否都在该分治连通块内,如果不在则直接退出,因为在之前的分治已经处理过了,不优。
然后将该颜色的所有点判断它父亲的颜色是否不一样且没被放入队列过,如果没有就放入队列。
一直这样知道队列为空。则代价为队列里出现过的颜色数 \(-1\)。
然后取 \(\min\) 即可。
时间复杂度 \(O(n\log n)\)。
14. P6326 Shopping
难度:2
好题。
首先,我们最后购买东西的商店一定构成一个连通块。考虑用点分治查询连通块。
现在有分治中心 \(rt\)。将 \(rt\) 定为新树根,则问题转化为树上依赖性多重背包。
多重背包可以用二进制拆分解决。将 \(d\) 个物品拆成 \(b+\sum_{i=0}^k 2^i\) 这 \(k+1\) 个物品,\(b<2^{k+1}\)。然后进行dp,可以做到 \(O(m\log d)\) 的时间复杂度的插入物品。
但是树上背包进行合并时的时间复杂度为 \(O(m^2)\) 每次,无法接受。所以需要将合并操作转化为插入操作。
考虑对这棵树记录dfs序,在dfs序上dp。设 \(dp_{i,j}\) 表示从后往前考虑到dfs序中下标为i,总体积为 \(j\) 时的最大价值。
对于节点 \(u\),如果取 \(u\) 的物品,就由 \(dp_{dfn_u+1}\) 转移。如果不取 \(u\) 的物品,则从dfs序中“删去”这个子树,由 \(dp_{dfn_u+sz_u}\) 转移。这样就可以只用插入而不用合并操作了。
然后就可以做到 \(O(nm\log d\log n)\)。可以通过。
15. P5071 [Ynoi Easy Round 2015] 此时此刻的光辉
难度:2
lxl 的题还是有难度的。
正常来说,这道题感觉可以用莫队搞,因为序列区间查询且不带修。
但是发现单次修改是 \(O(w(n))\) 的,为 \(a_i\) 的质因子个数,也就是接近 \(O(\ln n)\)。那么总的时间复杂度是 \(O(n\sqrt n\ln n)\),还要取模,显然过不去。
如何优化?
从值域入手,\(a_i\le 10^9\)。
所以考虑,对于 \(\le 1000\) 的质因子,有 \(168\) 个,我们直接暴力判断,统计答案。这样是 \(168(n+q)\) 的运算次数。
为了加速,将乘法取模改成除法。就是这么写(不然会被卡常):
int mul(int a,int b,int m)
{
ull c=(ull)a*b-(ull)((long double)a/m*b+0.5L)*m;
if(c<(ull)m) return c;
return c+m;
}
那么对于 \(a_i\),我们就可以将它所有 \(\le 1000\) 的质因子除去了。现在剩下的 \(a_i\) 只有三种可能:
- \(a_i\) 为质数。
- \(a_i\) 为两个 \(>1000\) 且不同的质数相乘。
- \(a_i\) 为某个 \(>1000\) 的质数的平方。
但是,它们的质因子个数都 \(\le 2\)。
那么此时就可以上莫队了。
需要先用 Miller_rabin 算法判断是否为质数,再用Pollard-Rho 算法求出所有质因子。为了避免用哈希表,我们将 \(a_i\) 的质因子离散化存下。
因为值域只有 \(10^9\),所以 Miller-rabin 可以只用取 \(\{2,7,61\}\) 三个底数。此处时间复杂度为 \(O(n(V^{\frac 14}+\log n))\)。
然后莫队就直接做了,但是有几个注意事项:
-
由于是乘积,当我们乘上一个 \(0\) 时,操作是无法逆向回来的。所以需要随时保证动态区间的长度为正数。
判断 \(qr<l\) 时就先动左端点,否则就先动右端点。
-
为了减小常数以通过题目,先将 \([1,n]\) 的逆元预处理出。
然后在每一次从一个询问挪到下一个询问时,开一个桶记录下被修改出现次数的元素,这样就可以在区间挪动完毕后统一修改,而不用每一次挪动都更改而浪费大量时间。
然后就可以过了,时间复杂度 \(O(n(\sqrt n+V^{\frac 14}+\log n))\)。有点卡常,开 C++11 会更快。
16. P11675 [USACO25JAN] Photo Op G
难度:2
\(X\) 到 \(Y\) 的路径一定可以拆成 \((X,x'),(x',y'),(y',Y)\)。
赛场上想的是,对于每一个 \(x\),维护它可以到的 \([y_l,y_r]\)。想用吉司机线段树去搞。但是没想好怎么快速统答案,而且时间复杂度也不对,多了个 \(O(\log n)\)。
其实,维护 \([y_l,y_r]\) 可以用树状数组的。
对于边 \((x_i,y_i)\),将 \(x\in[1,x_i-1]\) 的上界定为 \(\min(y_r,y_i)\)。将 \(x\in[x_i+1,10^6]\) 的下界定为 \(\max(y_l,y_i)\)。维护上界就用树状数组维护后缀最小值,维护下界就用树状数组维护前缀最大值即可。
接下来需要从查询答案入手。
对于 \(x\) 的可选区间 \([y_l,y_r]\)。
- 当 \(y_l>Y\) 时,此时选 \(y_l\) 最优,权值为 \(|y_l-Y|+|x-X|+\lfloor\sqrt{y_l^2+x^2}\rfloor\)。
- 当 \(y_r<Y\) 时,此时选 \(y_r\) 最优,权值为 \(|y_r-Y|+|x-X|+\lfloor\sqrt{y_r^2+x^2}\rfloor\)。
- 当 \(y_l\le Y\le y_r\) 时,此时选 \(Y\) 最优,权值为 \(|x-X|+\lfloor\sqrt{Y^2+x^2}\rfloor\)。
现在再画出图来,并计算出每一个 \(x\) 的 \([y_l,y_r]\)。
我们可以发现,\(x\) 的上下界都是非严格单增的。所以可以把可以从中间穿过的部分视为连通块。(如下图黄色部分,图来自 @dahuiji 的题解)
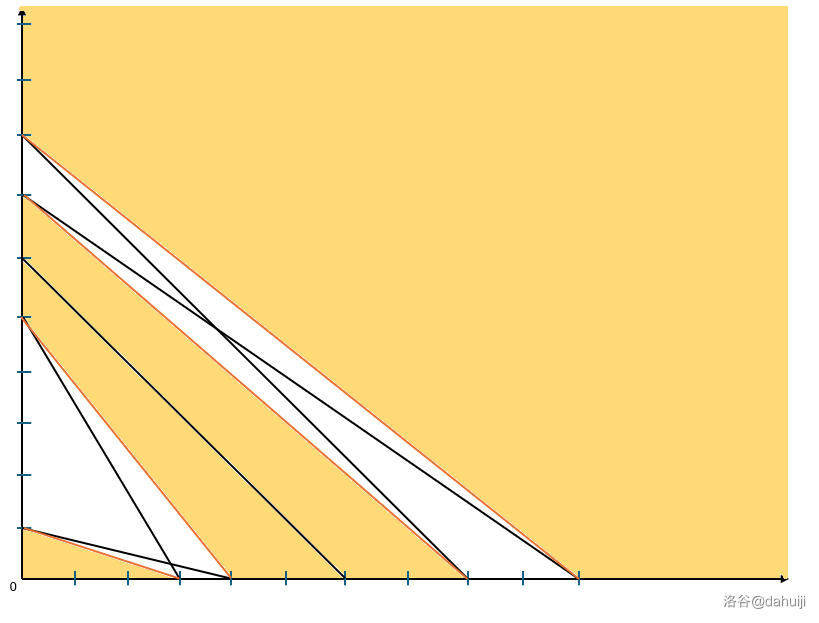
我们可以把所有 \(y_r<y_l\) 的 \(x\) 给删去。
那么可能最优的 \(x'\) 就是 \(X\) 左边(\(\le X\))第一个仍存在的 \(x\) 和 \(X\) 右边(\(>X\))第一个仍存在的 \(x\)。可以根据单调性证明。分别代入 \([y_l,y_r]\) 求值。
但是可能还不够优,就是当左边的 \(x\) 和右边的 \(x\) 的下界都 \(>Y\) 或上界都 \(<Y\) 时,此时可能存在另一个 \(x\) 使得选出的 \([y_l,y_r]\) 不同。
也就是当左边的 \(x\) 和右边的 \(x\) 的下界都 \(>Y\) 时,可能存在一个 \(x\) 的上界 \(<Y\) 或者包括 \(Y\),此时可能选新的 \(x\) 会更优。
所以同样,我们对于每一个 \(y\),需要预处理出可选区间 \([x_l,x_r]\)。然后将 \(x_l>x_r\) 的 \(y\) 删去。再将 \(Y\) 左边(\(\le Y\))第一个仍存在的 \(y\) 和 \(Y\) 右边(\(>Y\))第一个仍存在的 \(y\) 代入求值。
则答案就是上述四个值的最小值。
我们需要将 \(y_l>y_r\) 的 \(x\) 删去,需要支持删除。所以考虑用 set 维护。
时间复杂度 \(O(n\log n)\)。
17. P11673 [USACO25JAN] Median Heap G
难度:1
感觉中位数的题做法都差不多啊。
类似于AGC006D的做法,我们将 \(<m\) 的数定为 \(0\),将\(\ge m\) 的数定为 \(1\)。
因为本题要求于 \(m\) 相等,所以改一下,我们让 \(=m\) 的数为 \(1\),\(>m\) 的数为 \(2\)。
然后初始化所有数都是 \(2\)。那么可以跑一个dp。
设 \(dp_{u,0/1/2}\) 表示让 \(u\) 节点上传 \(0/1/2\) 的最小代价。
然后傻傻的我还去枚举每一种状态,再讨论。码量和思维难度大,而且还容易写错。虽然最后写对了,错的地方不在这。但是有更简便的写法。
首先,对于叶子节点,我们设给它赋的值为 \(w_u\)。则对于 \(i\neq w_u\),则初始化 \(dp_{u,i}=c_u\),让 \(dp_{u,w_u}=0\)。
然后转移就可以枚举左儿子的上传值 \(i\),右儿子的上传值 \(j\) 和自己的值 \(k\),再算出 \(i,j,k\) 的中位数更新。
int med(int i,int j,int k)//求中位数
{
return i+j+k-max({i,j,k})-min({i,j,k});
}
for(int i=0;i<3;i++)
{
for(int j=0;j<3;j++)
{
for(int k=0;k<3;k++)
{
int mid=med(i,j,k);
dp[u][mid]=min(dp[u][mid],dp[u<<1][i]+dp[u<<1|1][j]+w[u][k]);
}
}
}
然后将询问离线下来,并按权值从小到大排序。将树中的点按从小到大排序。
然后对于一次询问 \(m\),用指针维护,将 \(<m\) 的点的 \(w\) 值赋值为 \(0\),将 \(=m\) 的点的值赋值为 \(1\)。
然后将所有 \(=m\) 的询问计算完后,将所有赋值为 \(1\) 的节点赋值为 \(0\)。
因为树高只有 \(O(\log n)\)。所以时间复杂度是 \(O(n+q\log n)\)。
18. P11676 [USACO25JAN] DFS Order P
难度:1
我们可以从dfs生成树的方向去考虑。
我们发现,对于一棵dfs生成树,如果 \(u\) 和 \(v\) 之间不是祖先关系则 \((u,v)\) 之间不能有连边。否则可以有连边。
现在回到题目。先考虑原图没有边的情况。
因为要求dfs序为 \(\{1,2,...,n\}\),所以考虑倒着dp。
设 \(dp_{i,j}\) 表示使得存在一棵dfs序为 \(\{i,i+1,...,j-1,j\}\) 的生成树的最小代价。
现在枚举点 \(i\)。考虑将后面的几棵dfs生成树合并起来,让这些生成树的根成为 \(i\) 的儿子。
首先初始化 \(dp_{i,i}=0\)。因为我可以让 \(i\) 节点成为生成树的叶子。
然后先考虑合并第一棵生成树。为了满足要求,则它的树根一定是 \(i+1\)。
所以枚举 \(k\) 表示这棵生成树的dfs序为 \([i+1,k]\),然后合并成一棵 \([i,k]\) 的生成树,代价为 \(a_{i,i+1}\)。
所以有转移 \(dp_{i,k}=\min_{k=i+1}^n dp_{i+1,k}+a_{i,i+1}\)。
但是还可能继续合并,则下一棵合并的树根为 \(k+1\),然后又可以类似上述转移。
所以总的dp转移式子为:
时间复杂度 \(O(n^3)\)。
现在考虑有原边的情况。先考虑将所有原边删去,代价和 \(sum=\sum {-a_{i,j}}\times [a_{i,j}<0]\)。那么现在加这一条边的权值就是 \(a_{i,j}\),也就相当于还原了这一条边。
因为上文说了,dfs生成树当 \(u,v\) 之间有祖先关系时,二者是可以在原图上有连边的。
所以将 \([i,j-1]\) 和 \([j,k]\) 合并起来时,可以从 \(i\) 向 \([j,k]\) 的点连边。那么这中间先前就有的边就可以还原。因为必须连 \((i,j)\),所以只考虑 \(i\) 到 \([j+1,k]\) 的连边中原本存在于原图的边的权值和。
用前缀和处理即可。
时间复杂度 \(O(n^3)\)。
19. P7834 [ONTAK2010] Peaks 加强版
难度:1
首先对于从 \(u\) 开始,通过 \(\le x\) 的路径可以到达的点,考虑类似 [NOI2018] 归程 的做法。
用Kruskal重构树 将整个图变成一个有 \(2n-1\) 个点的二叉树。
现在我们要对这个树的每一个点处理它这棵子树叶子的第 \(k\) 大值。
我当时脑抽,想了个树上启发式合并+主席树的做法,时空复杂度 \(O(n\log^2n)\)。然后加强版的 128MB 空间限制给我打醒了。
其实因为只用维护叶子,所以考虑用dfs序将所有叶子排序,这样的话,一个点对应的子树叶子就是一个连续的区间了。然后就可以用主席树在序列上处理。
时间复杂度 \(O(q\log n)\)。
20. P2839 [国家集训队] middle
难度:2
设原序列为 \(A\),排完序后为 \(A'\)。
感觉可以二分,因为是求中位数。将 \(<mid\) 的位置赋值为 \(-1\),将 \(\ge mid\) 的位置赋值为 \(1\)。
然后对于一个区间 \([l,r]\),当它的和 \(\ge 0\) 时就向上二分,否则就向下二分。
现在问题是如何在 \(O(\log n)\) 的时间内求出一个区间的和。
我们将题目给的区间 \(\{a,b,c,d\}\) 分成 \([a,b-1]、[b,c]、[c+1,d]\)。那么对于区间 \([b,c]\) 就是直接求和即可。对于区间 \([a,b-1]\) 就是求最大后缀。对于区间 \([c+1,d]\) 就是求最大前缀。
因为最终二分停下的值一定是序列中存在的一个值。所以考虑将原序列排序后,按下标,在 \([1,n]\) 中二分,每一次 \(mid\) 取 \(A'_i\)。这样就可以保证二分的 \(mid\) 只有 \(n\) 个。
所以对这 \(n\) 个,每一个开一棵线段树,维护最大前后缀以及和。将 \(\ge A'_i\) 的位置赋值为 \(1\),将 \(<A'_i\) 的位置赋值为 \(-1\)。
但是 \(A'_i\) 和 \(A'_{i+1}\) 最后赋值出来的数组最多只有一个位置不同。所以考虑用主席树去优化这一过程。
时间复杂度 \(O(n\log n+q\log^2n)\),空间复杂度 \(O(n\log n)\)。
21. P7424 [THUPC 2017] 天天爱射击
难度:0.5
可以对于每一个木板,二分它什么时候会被打掉。这里可以用主席树去维护这个前缀和。
时间复杂度 \(O(n\log^2n)\),因为主席树的常数导致TLE。平均需要 3.0s,而实现只有 1.0s。
考虑用整体二分。对于每一次 \(\text{solve}(st,en,l,r)\),表示考虑第 \(l\sim r\) 次射击,对于 \(st\sim en\) 的木板是否被击碎。
注意,这里的木板下标是会随着二分而更改的。
设 \(l_i\) 和 \(r_i\) 为第 \(i\) 块木板的左右位置,\(k_i\) 为耐久。
将第 \(l\sim mid\) 次射击存入树状数组。然后枚举木板,如果 \([l_i,r_i]\) 的被射击次数 \(\ge k_i\),则将 \(i\) 归为左边;否则让 $k_i\gets k_i-[l_i,r_i]被射击次数 $,然后归为右边。
时间复杂度 \(O(n\log^2n)\)。但因为其优秀的常数,使得它能在平均300ms 跑过。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号