
编码
常见编码
-
中文编码
-
base64(base)家族
-
rot13(rot家族)
-
凯撒密码
-
栅栏密码
-
维吉尼亚密码
-
Ook!密码
-
BrainFuck密码
-
摩斯密码
-
敲击码
-
简单替换(强行爆破)
字符编码
ascii编码
unicode编码
python3默认采用Unicode编码,python2默认采用ascii编码
Unicode编码在不同的应用场合所采用的表示方式也不一样。
Unicode常见的四种表示方式:
- 源文本:中国
&#x[Hex]:中国&#[Dec]:中国\U[Hex]:\U4e2d\U56fd\U+[Hex]:\U+4e2d\U+56fd
UTF-8编码(用处广泛)

意思就是:我们看到的是(输出)UTF-8编码,电脑中读取的是Unicode编码

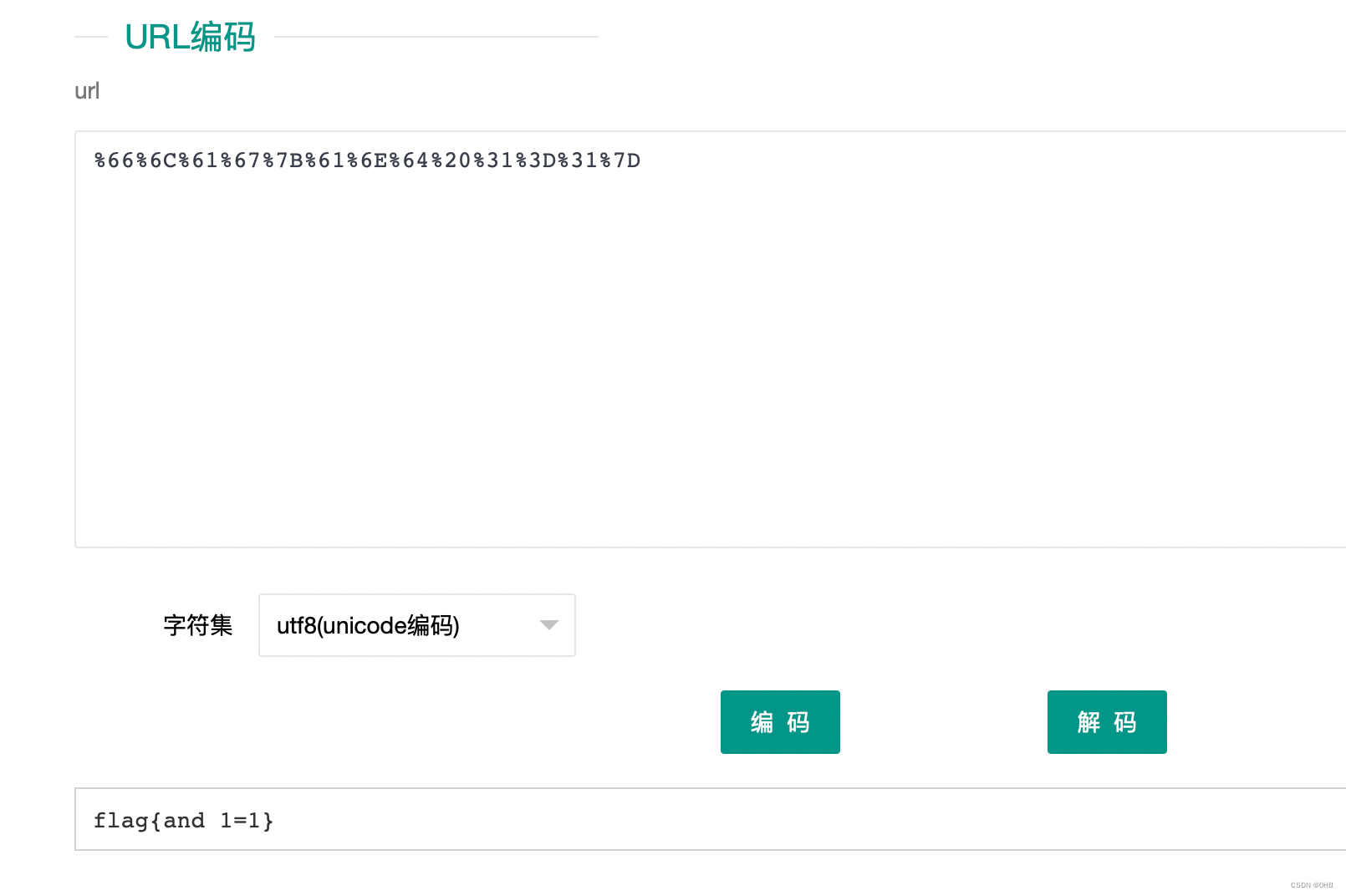
URL编码
密文格式:%66%6C%61%67%7B%61%6E%64%20%31%3D%31%7D
GBK编码
例题-ez_锟斤拷????(*)
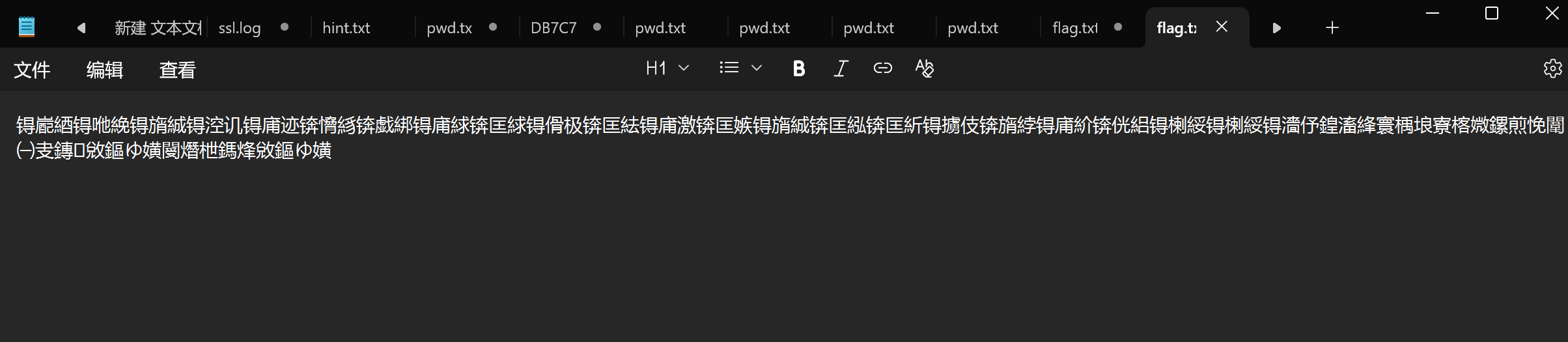
文字乱码——文字编码方向
看着像gbk编码,

由题可知是原始flag文本经过一种编码得到文本 另存为转换成gbk编码后结果输出错误
现在我们的目的寻找最开始的编码,现在,尝试所有常见编码

写个脚本挨个进行尝试
为以防万一,最开始的也遍历一下
脚本
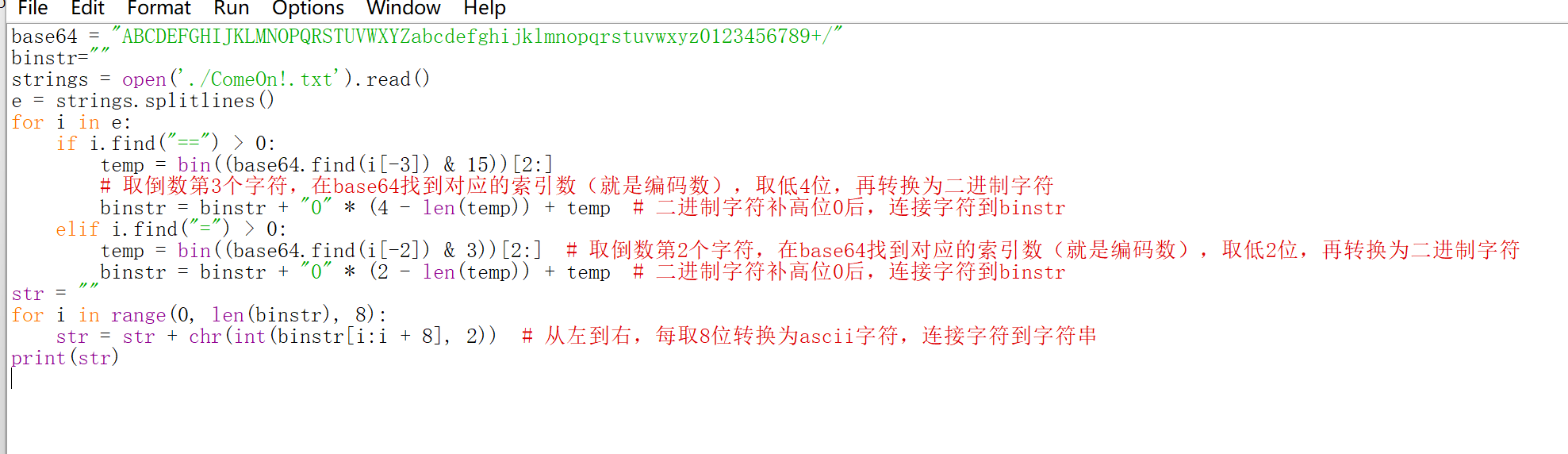
def try_fix_encoding(text):
"""尝试多种编码组合修复乱码"""
results = []
# 尝试常见编码转换组合
encodings = ['utf-8', 'gbk', 'gb2312', 'big5']
for enc in encodings:
for target_enc in encodings:
if enc == target_enc:
continue
try:
# 模拟编码错误:用enc解码再用target_enc编码
fixed = text.encode(enc, errors='replace').decode(target_enc, errors='replace')
results.append(f"{enc} → {target_enc}: {fixed}")
except:
continue
# 尝试全角半角转换(扩大范围)
full_half = []
for char in text:
code = ord(char)
# 尝试更宽范围的编码偏移
for offset in [0xFEE0, 0xfee0, 0x20, 0x80]:
if 0x20 <= (code - offset) <= 0x7E:
full_half.append(chr(code - offset))
break
else:
full_half.append(char)
results.append(f"全角半角修正: {''.join(full_half)}")
return results
if __name__ == "__main__":
problematic_text = "锝嶏綇锝咃絻锝旓絾锝涳讥锝庯迹锛愶絼锛戯綁锝庯絿锛匡絿锝傦极锛匡紶锝庯激锛匡嫉锝旓絾锛匡紭锛匡紤锝擄伎锛旓綍锝庯紒锛侊絽锝楋綏锝楋綏锝濇伃鍠滀綘寰楀埌寮楁媺鏍煎悗闈㈠叏鏄敓鏂ゆ嫹閿熸枻鎷烽敓鏂ゆ嫹"
print("原始文本:", problematic_text)
print("\n尝试修复结果:")
for res in try_fix_encoding(problematic_text):
print(res)

base家族编码
base64编码
Base64是一种用于传输8bit字节数据的编码方式
base64编码是由ascii编码组成的
编码必须是4的倍数,不够的用=填充
base64是将非ascii编码(二进制文件内容)转换成ascii编码的一种方法。
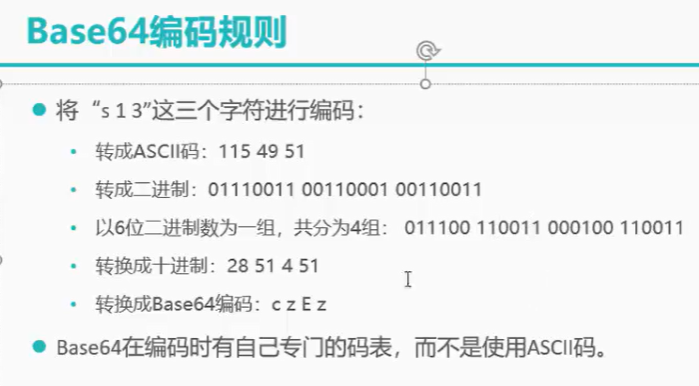
为什么使用3个字节一组呢?
因为6和8的最小公倍数为24,三个字节正好24个二进制位,每6个bit位一组,恰好能够分为4组。
编码过程:
字符--ascii码(数字)--二进制--从八位分成六位(不够的补0)------将4组二进制转换成十进制----(按照base64编码表编码)---base64编码
示例说明
以下图的表格为示例,我们具体分析一下整个过程。
第1步:“M”、“a”、”n”对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。
第2步:如图红色框,将24位每6位二进制位一组分成四组。
第3步:在上面每一组前面(首位)补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。
第4步:用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。
最后如果位数不足3位,该如何处理?
位数不足情况 上面是按照三个字节来举例说明的,如果字节数不足三个,那么该如何处理?
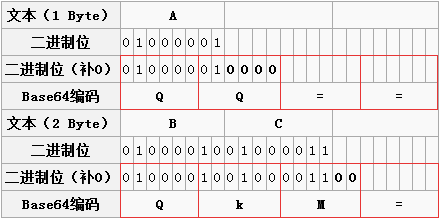
(1)两个字节:两个字节共16个二进制位,依旧按照规则进行分组。此时总共16个二进制位,每6个一组,则第三组缺少2位,用0补齐,得到三个Base64编码,第四组完全没有数据则用“=”补上。因此,上图中“BC”转换之后为“QKM=”;
(2) 一个字节:一个字节共8个二进制位,依旧按照规则进行分组。此时共8个二进制位,每6个一组,则第二组缺少4位,用0补齐,得到两个Base64编码,而后面两组没有对应数据,都用“=”补上。因此,上图中“A”转换之后为“QQ==”;
注意事项
-
大多数编码都是由字符串转化成二进制的过程,而Base64的编码则是从二进制转换为字符串。
-
与常规恰恰相反, Base64编码主要用在传输、存储、表示二进制领域,不能算得上加密,只是无法直接看到明文。也可以通过打乱Base64编码来进行加密。
-
中文有多种编码(比如:utf-8、gb2312、gbk等),不同编码对应Base64编码结果都不一样。 延伸 上面我们已经看到了Base64就是用6位(2的6次幂就是64)表示字符,因此成为Base64。
-
同理,Base32就是用5位,Base16就是用4位。大家可以按照上面的步骤进行演化一下。
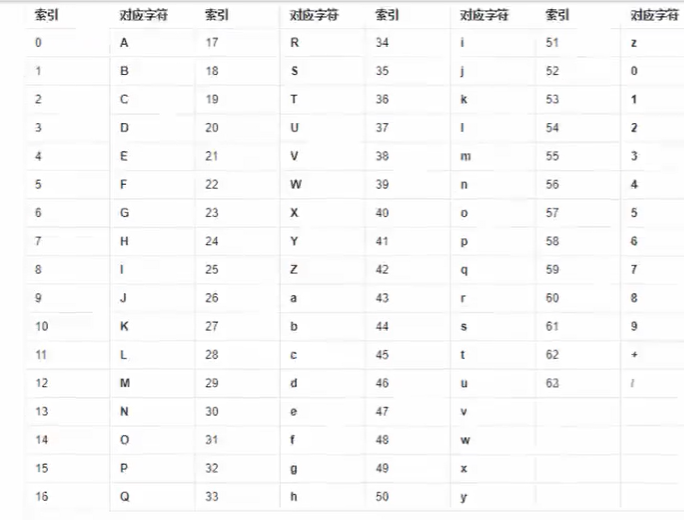
base64编码表(共64位)
从0开始(A-Z),26开始(a-z),52开始(0-9),+,/。
如何辨别是否是base64编码?

查看字符个数
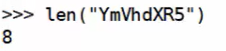
在python环境下
python2---------ascii编码
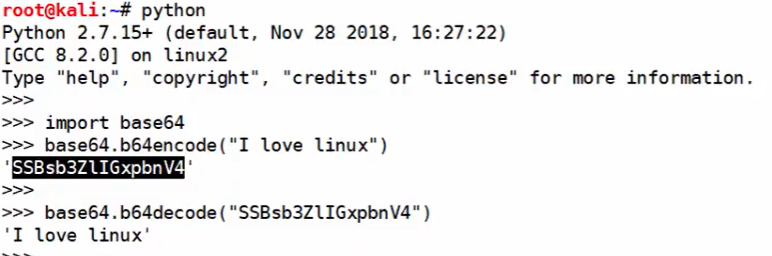
python3(必须有b)---------Unicode编码
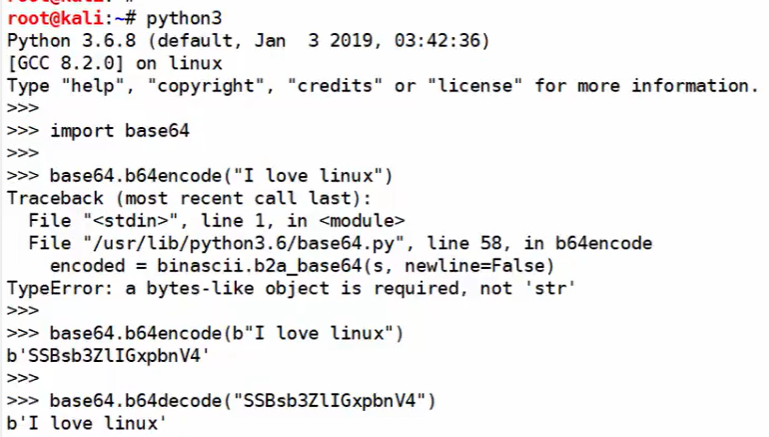
base64解码
用linux
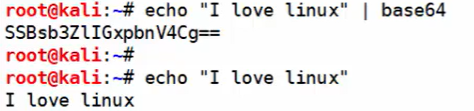
echo命令输出时自动换行,所以用base64转换并打印出来会自带一个换行符的值
要使其输出正确的值

加个-n就没有换行符了
解码:加个-d

解码的时候有没有-n不影响
简述: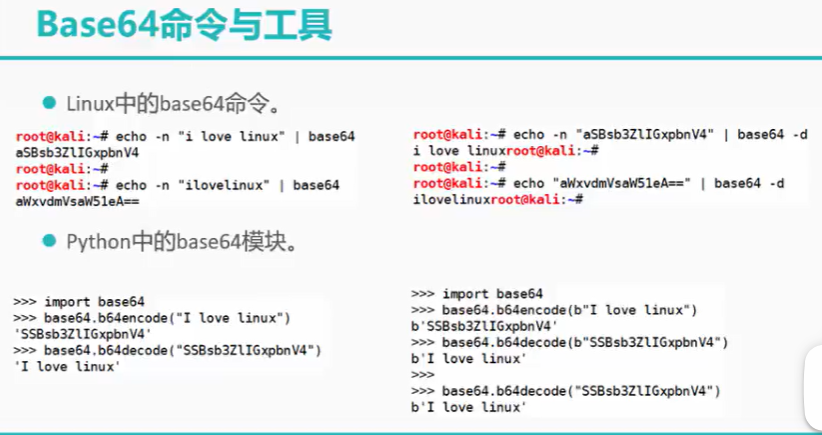
base64命令本身就是用来处理文件的,可以编码图片文件

总结
base家族编码都不算难,根据特征特点找到对应的加解密方式就可以了。下面总结一下各个base编码的特点。
- base16特征:由大写字母(A-Z)和数字(0-9)组成,通常不需要“=”填充
- base32特征:由大写字母(A-Z)和数字(2-7)组成,需要“=”填充
- base64特征:大小写字母(a-Z)和数字(0-9)以及特殊字符('+','/')不满3的倍数用“=”补齐
- base58特征:同base64相比,少了数字‘0’和字母‘O'数字’1‘和字母’I‘以及'+'和'/'符号,也没有“=”
- base85特征:有很多奇怪的符号,但一般没有“=”
- base91特征:由91个字符(0-9,a-z,A-Z,!#$%&()*+,./:;<=>?@[]^_`{|}~”)组成
- base100特征:全是emoji表情。
凯撒加密
凯撒密码最早由古罗马军事统帅盖乌斯·尤利乌斯·凯撒在军队中用来传递加密信息,故称凯撒密码。此为一种位移加密手段,只对26个(大小写)字母进行位移加密,规则相当简单,容易被破解。下面是明文字母表移回3位的对比:
明文字母表 X Y Z A B C D E F G H I J K L M N O P Q R S T U V W
密文字母表 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
然后A变成D,B变成E,Z变成C。
字母最多可移动25位(按字母表)。通常为向后移动,如果您想向前移动1位,则相当于向后移动25位,位移选择为25位。
脚本
"C:\Users\Voasem\Desktop\py脚本\caesar偏移量未知.py"
例题
BUUCTF 变异凯撒
查看题目

又因为明文flag对应afZ_,所以寻找明文和密文的规律
f-102 a-97 相差5
l-108 f-102 相差6
a-97 Z-90 相差7
g-103 _-95 相差8
可以看出每个字符的偏移量为n+4
所以依次算出各密文字符对应的明文字符求得明文为
flag{Caesar_variation}
BUUCTF 大帝的密码(凯撒密码)
题目
公元前一百年,在罗马出生了一位对世界影响巨大的人物,他生前是罗马三巨头之一。他率先使用了一种简单的加密函,因此这种加密方法以他的名字命名。
以下密文被解开后可以获得一个有意义的单词:FRPHEVGL
你可以用这个相同的加密向量加密附件中的密文,作为答案进行提交。
密文ComeChina
考点:凯撒加密
使用凯撒在线解密工具对它进行依次的移位即可,既可以一个一个试,也可以自己写一个python脚本去实现。
得到
由此我们知道偏移量为13,那么现在就对我们的密文ComeChina进行13位的凯撒解密就行了。
flag{PbzrPuvan}
栅栏密码
分为传统型与变异W型
传统栅栏密码
栅栏密码,就是把要加密的明文分成N个一组,然后把每组的第1个字连起来,形成一段无规律的话。
不过栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多。(一般不超过30个,也就是一、两句话)

"C:\Users\Voasem\Desktop\py脚本\栅栏密码全能脚本.py"
W型栅栏
·简介
W型栅栏密码加密的方法中,明文由上至下顺序写上,当到达最低部时,再回头向上,一直重复直至整篇明文写完为止。
·加解密方式:
此例子中,其包含了三栏及一段明文:‘WEAREDISCOVEREDFLEEATONCE’。如下:
W . . . E . . . C . . . R . . . L . . . T . . . E
. E . R . D . S . O . E . E . F . E . A . O . C .
. . A . . . I . . . V . . . D . . . E . . . N . .按行读取后的密文:
WECRLTEERDSOEEFEAOCAIVDEN
W型的加密密钥就不只能是字符串长度的因子,小于其长度的任何一个数都可能是其key值,所以第一步也是最重要的确定密钥。
例题
BUUCTF 篱笆墙的影子(栅栏密码)
查看题目

篱笆墙很明显联想到栅栏密码,用栅栏在线解密即可
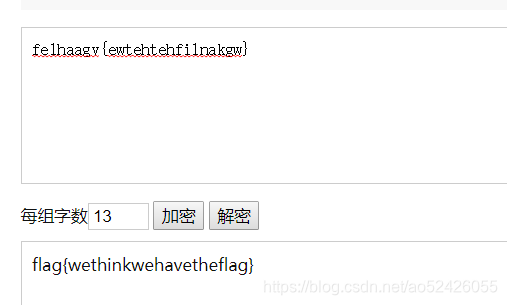
栅栏密码全能脚本
也可以用脚本,这里我做了一个通用脚本
可加密,可解密,无密钥也可破解
rot编码
ROT系列编码加密原理:
ROT5、ROT13、ROT18、ROT47 编码是一种简单的码元位置顺序替换暗码。此类编码具有可逆性,可以自我解密,主要用于应对快速浏览,或者是机器的读取,而不让其理解其意。
ROT5 是 rotate by 5 places 的简写,意思是旋转5个位置,其它皆同。下面分别说说它们的编码方式:
- ROT5:只对数字进行编码,用当前数字往前数的第5个数字替换当前数字,例如当前为0,编码后变成5,当前为1,编码后变成6,以此类推顺序循环。
- ROT13:只对字母进行编码,用当前字母往前数的第13个字母替换当前字母,例如当前为A,编码后变成N,当前为B,编码后变成O,以此类推顺序循环。
- ROT18:这是一个异类,本来没有,它是将ROT5和ROT13组合在一起,为了好称呼,将其命名为ROT18。
- ROT47:对数字、字母、常用符号进行编码,按照它们的ASCII值进行位置替换,用当前字符ASCII值往前数的第47位对应字符替换当前字符,例如当前为小写字母z,编码后变成大写字母K,当前为数字0,编码后变成符号_。用于ROT47编码的字符其ASCII值范围是33-126,具体可参考ASCII编码。
例题
BUUCTF checkln
题目描述:
密文:
dikqTCpfRjA8fUBIMD5GNDkwMjNARkUwI0BFTg==
解题思路:
1、观察密文,一眼Base64加密,使用在线工具Base64加解密,得到另一串密文。
v)*L*_F0<}@H0>F49023@FE0#@EN
2、尝试了很多方法,都没有成功。最后,根据此密文的ASCII码值都处于33 ~ 126范围,确定为ROT47加密。
3、使用在线工具ROT47加解密,得到flag。
flag:
GXY{Y0u_kNow_much_about_Rot}
摩斯密码
广泛用于音频,图片,字符
特点
- 只有
.和-; - 最多 6 位;
- 也可以使用
01串表示
敲击码
敲击码(Tap code)是一种以非常简单的方式对文本信息进行编码的方法。因该编码对信息通过使用一系列的点击声音来编码而命名,敲击码是基于5×5方格波利比奥斯方阵来实现的,不同点是是用K字母被整合到C中。
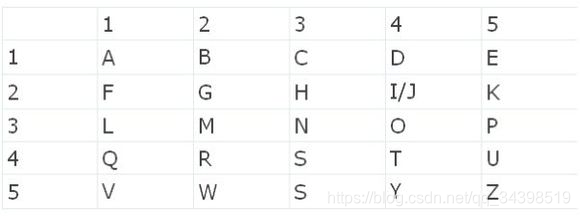
敲击码表
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | A | B | C/K | D | E |
| 2 | F | G | H | I | J |
| 3 | L | M | N | O | P |
| 4 | Q | R | S | T | U |
| 5 | V | W | X | Y | Z |
维吉尼亚密码
1.简介
维吉尼亚密码是在凯撒密码基础上产生的一种加密方法,它将凯撒密码的全部25种位移排序为一张表,与原字母序列共同组成26行及26列的字母表。另外,维吉尼亚密码必须有一个密钥,这个密钥由字母组成,最少一个,最多可与明文字母数量相等。
2.维吉尼亚密码加密方法示例如下:
明文:I’ve got it.
密钥:ok
密文:W’fs qcd wd.
加密规则:密钥长度需要与明文长度相同,如果少于明文长度,则重复拼接直到相同。本例中,明文长度为8个字母(非字母均被忽略),密钥会被程序补全为“okokokok”。
现在根据如下维吉尼亚密码表格进行加密:

注意事项:
(1)明文第一个字母是“I”,密钥第一个字母是“o”,在表格中找到“I”列与“o”行相交点,字母“W”就是密文第一个字母;同理,“v”列与“k”行交点字母是“F”;“e”列与“o”行交点字母是“S”……
(2)维吉尼亚密码只对字母进行加密,不区分大小写,若文本中出现非字母字符会原样保留。
(3)如果输入多行文本,每行是单独加密的。
键盘密码
QWE替换
简介
QWE格式密码就是QWERTYUIOP ASDFGHJKL ZXCVBNM 依次表示字母ABCDEFGHIJKLMNOQRSTUVWXYZ。
加/解密方式:对表

QWE包围
简介
解密方式:每组密文所围住的按键上的字符
例: yujnbg, 观察键盘发现这六个字母围住了h,故明文为h。
加/解密方式:观察键盘

九一
名字自己胡诌的。此类键盘密码的特征是有两种形式,重复的数字、重复的英文。
一是指键盘第一行的意思,九是指九宫格。
·[NCTF2019]Keyboard
ooo yyy ii w uuu ee uuuu yyy uuuu y w uuu i i rr w i i rr rrr uuuu rrr uuuu t ii uuuu i w u rrr ee www ee yyy eee www w tt ee
·发现密文全在键盘字母第一行,若再上一行,则会得到字母与数字的映射关系,例如:q对应1,w对映2。
·此时会发现数字全都是小于10的,对应九宫格拼音,又重复次数在四次以内,则重复次数是一宫中的行坐标。
例:ooo -> 999 -> y
·[MRCTF2020]keyboard
得到的flag用
MRCTF{xxxxxx}形式包上
都为小写字母
6
666
22
444
555
33
7
44
666
66
3
·相比于重复字母,则是少了映射的一步,直接在九宫格定位。
·例:6 -> M

cipher = input('请输入键盘密码(数字或英文):')
base = " qwertyuiop"
a = [" ", " ", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"]
dict_zm = {1: 'q', 2: 'w', 3: 'e', 4: 'r', 5: 't', 6: 'y', 7: 'u', 8: 'i', 9: 'o', 0: 'p'}
b = []
if ''.join(cipher.split(' ')).isdigit(): # 是数字时
cipher = cipher.split(' ')
for each in cipher:
b.append(dict_zm[int(each[0])]*len(each))
cipher = ' '.join(b)
for part in cipher.split(" "):
s = base.index(part[0])
count = len(part)
print(a[s][count-1], end="")

棋盘密码
1.简介
Polybius 密码又称为棋盘密码,一般是将给定的明文加密为两两组合的数字
2.加/解秘方式:对表
(1)基础版
明文:HELLO
密文:23 15 31 31 34
(2)变异版

·使用这种密码表的加密也叫作 "ADFGX 密码"(密文中只有 A D F G X)
·明文:HELLO
密文:DD XF AG AG DF
Ook!密码
将所有明文转换成Ook.?!
JSfuck密码
JSFuck 可以让你只用 6 个字符 !+ 来编写 JavaScript 程序。
[][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]][([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[!+[]+!+[]+!+[]]]]+([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]+!+[]]]]+([][[]]+[])[+[[+!+[]]]]+(![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[+!+[]]]]+([][[]]+[])[+[[+[]]]]+([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]((![]+[])[+[[+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]+(!![]+[])[+[[+[]]]]+([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[+!+[]]]+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+[+!+[]]+([][(![]+[])[+[[+[]]]]+([][[]]+[])[+[[!+[]+!+[]+!+[]+!+[]+!+[]]]]+(![]+[])[+[[!+[]+!+[]]]]+(!![]+[])[+[[+[]]]]+(!![]+[])[+[[!+[]+!+[]+!+[]]]]+(!![]+[])[+[[+!+[]]]]]+[])[+[[+!+[]]]+[[!+[]+!+[]+![]+!+[]+!+[]+!+[]]]])()
BrainFuck密码
这是一种按照“Turing complete(图灵完备)”思想设计的语言,它的主要设计思路是:用最小的概念实现一种“简单”的语言,BrainFuck 语言只有 ><±.,[] 八种符号,所有的操作都由这八种符号的组合来完成。
猪圈密码
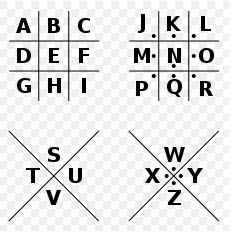

例题:BUUCTF 萌萌哒的八戒(猪圈密码)
得到一张图片,底部有猪圈编码
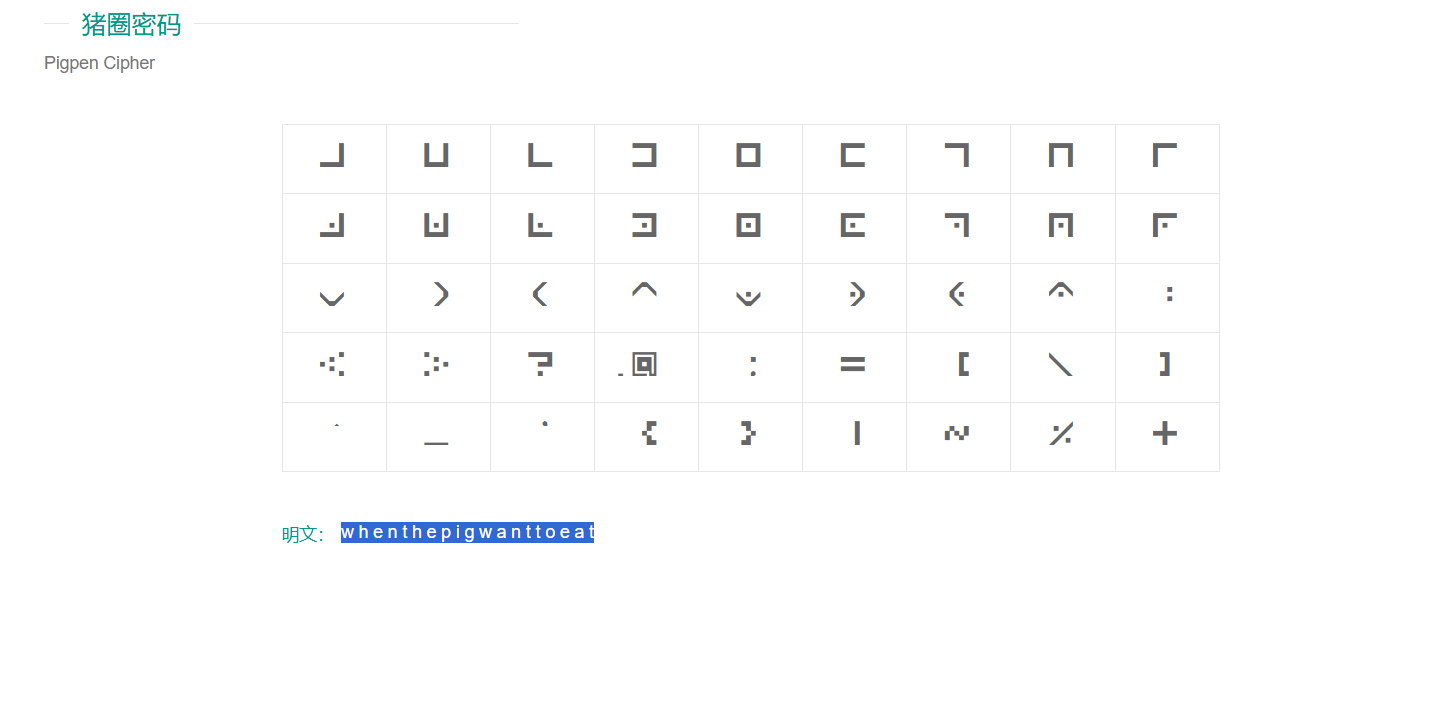
得到w h e n t h e p i g w a n t t o e a t
(记得把空格去掉)
猪圈密码变种

不常见
- 社会主义核心价值观编码
- 博多密码
- 希尔密码
- 培根密码
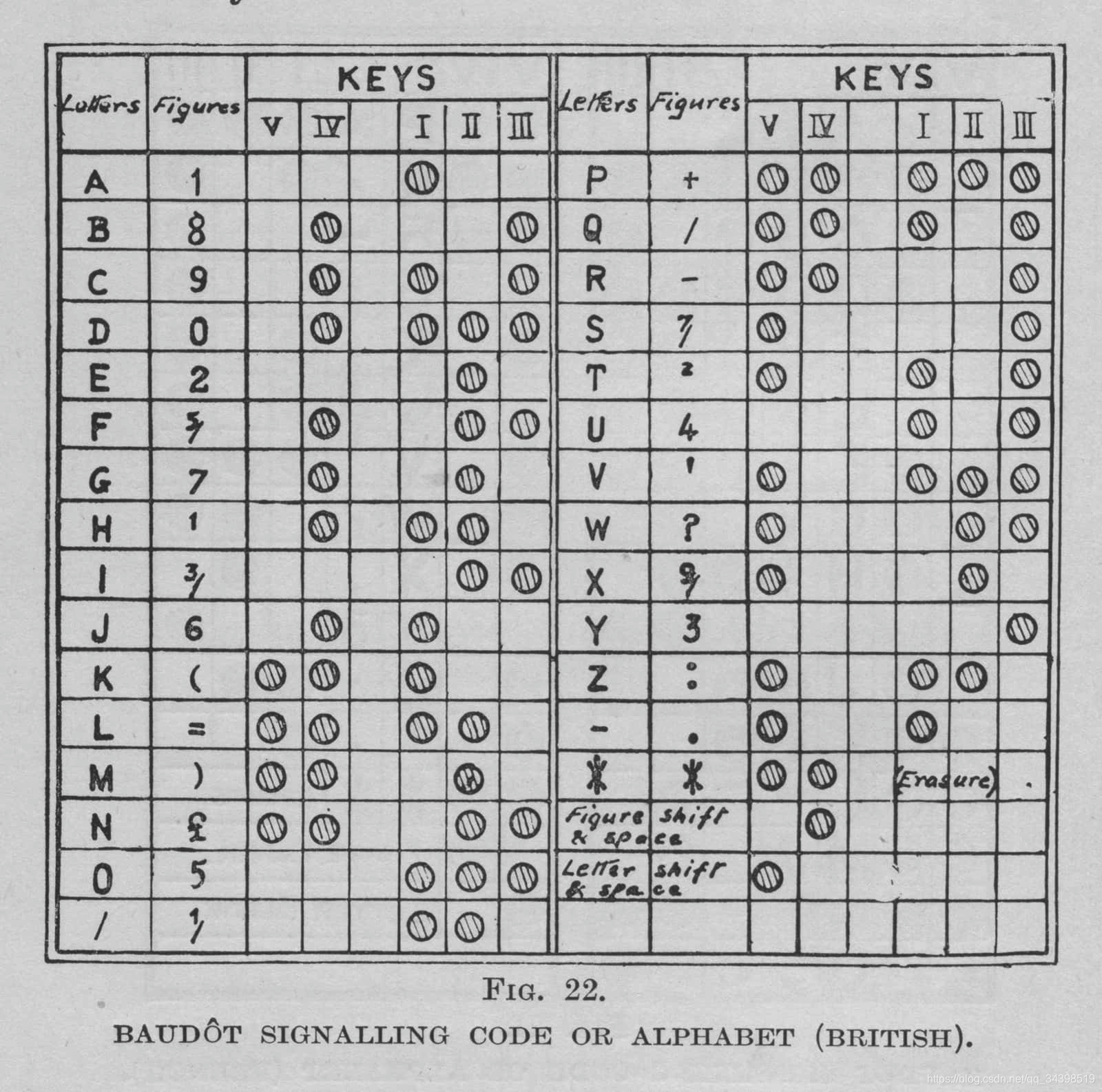
博多密码
1.简介
·博多电码是法国工程师博多于1874年推出的一种电报码。它在20世纪中期取代了莫尔斯电码被广泛应用。
·博多码,是一种5位代表一个字节的编码。在那个年代,5位的系统已经非常复杂,位数更多不切合实际,但稍加分析便可知道,5位是不可能代表26个英文字母+数字+各种符号的,而博多码并不是一个像电脑所使用的,一个8位特定的二进制数字专门地表示一个字符的编码系统,博多使用了同一组编码分别表示字母集和数字标点符号集,通过两个字符实现字符集之间的切换。因此,当报文中同时包含了英文字母和数字和符号的时候,必须加入切换字符来表示在不同的集之间的切换。博多式电报机是这样的一个样子:发报收报端各一台看上去是钢琴一般的只有5个按键的机器,按键从左到右按字母顺序排列,通过电路两两相连,两边按下键盘时,对方的纸带上会打印出相对应按键的黑点,当需要打符号的时候,只需要按照编码表上表示切换到符号集(Figures)所代表编码按下对应的按键,此后输出的都会被收报员人工判读为符号或者数字,当需要恢复到输入字母时,按下编码表上表示字母集(Letters)的按键,此后的内容都会被判读为字母。
希尔密码
·简介
希尔密码是运用基本矩阵论原理的替换密码,由Lester S. Hill在1929年发明。
每个字母当作26进制数字:A=0, B=1, C=2… 一串字母当成n维向量,跟一个n×n的矩阵相乘,再将得出的结果模26。
培根密码
表

代码实现
__autor__ = '0HB'
letters1 = [
'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z',
]
letters2 = [
'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z',
]
cipher1 = [
"aaaaa", "aaaab", "aaaba", "aaabb", "aabaa", "aabab", "aabba",
"aabbb", "abaaa", "abaab", "ababa", "ababb", "abbaa", "abbab",
"abbba", "abbbb", "baaaa", "baaab", "baaba", "baabb",
"babaa", "babab", "babba", "babbb", "bbaaa", "bbaab",
]
cipher2 = [
"AAAAA", "AAAAB", "AAABA", "AAABB", "AABAA", "AABAB", "AABBA",
"AABBB", "ABAAA", "ABAAA", "ABAAB", "ABABA", "ABABB", "ABBAA",
"ABBAB", "ABBBA", "ABBBB", "BAAAA", "BAAAB", "BAABA",
"BAABB", "BAABB", "BABAA", "BABAB", "BABBA", "BABBB",
]
def bacon1(string): # 对应小写密文
lists = []
# 分割,五个一组
for i in range(0, len(string), 5):
lists.append(string[i:i + 5])
# print(lists)
# 循环匹配,得到下标,对应下标即可
for i in range(0, len(lists)):
for j in range(0, 26):
if lists[i] == cipher1[j]:
# print(j)
print(letters1[j], end="")
print("")
def bacon2(string): # 对应大写密文
lists = []
# 分割,五个一组
for i in range(0, len(string), 5):
lists.append(string[i:i + 5])
# print(lists)
# 循环匹配,得到下标,对应下标即可
for i in range(0, len(lists)):
for j in range(0, 26):
if lists[i] == cipher2[j]:
# print(j)
print(letters2[j], end="")
print("")
if __name__ == "__main__":
c = input('请输入培根密文:')
if c.isupper():
bacon2(c)
elif c.islower():
bacon1(c)
else:
print('输入错误,请检查!')
Rabbit编码
例题:BUUCTF Rabbit
查看题目

题目叫Rabbit这是一个加密,我们直接Rabbit在线解密即可
md5编码
BUUCTF 丢失的md5
题给出了一个md5.py,运行即可得到flag
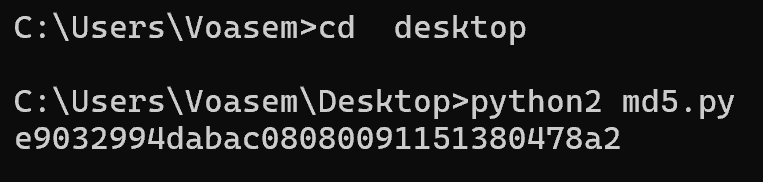
(只能用python2运行,不能用python3运行)

BUUCTf windows 系统密码
打开文件.hash,可以发现如下内容
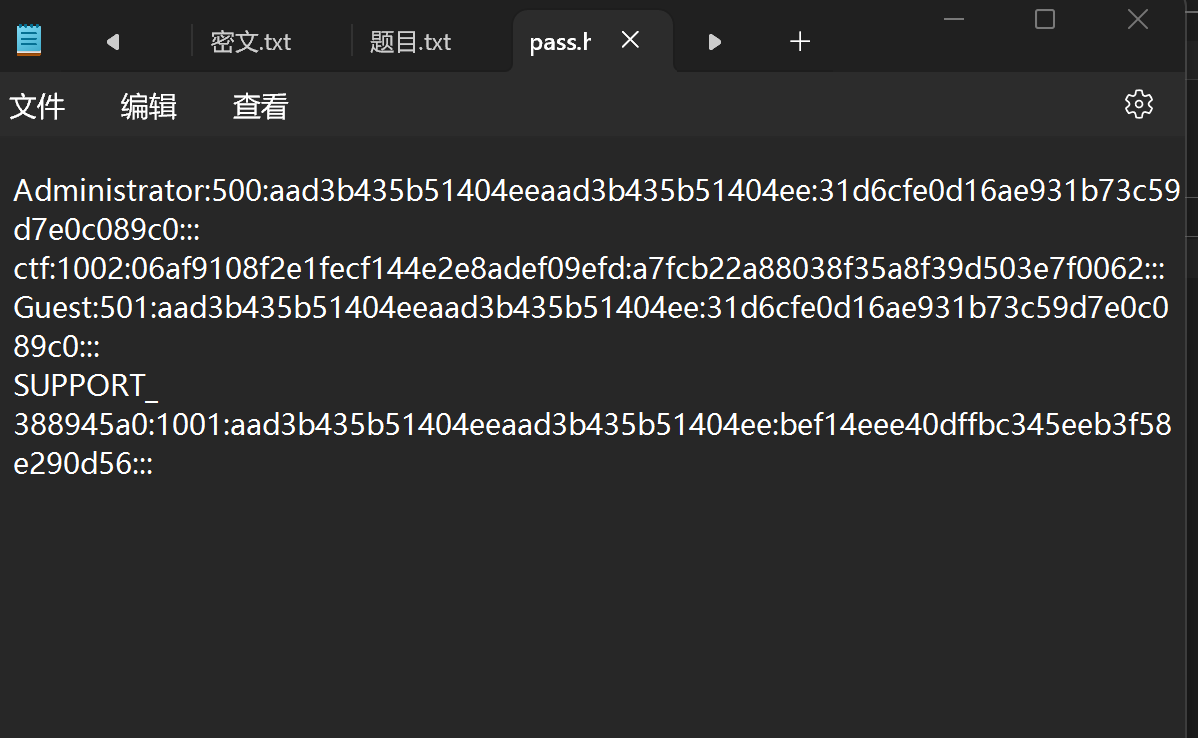
:是断口
由于文件后缀是.hash,我们想到用MD5解码,将每一串都带进MD5在线解密中,可以试出
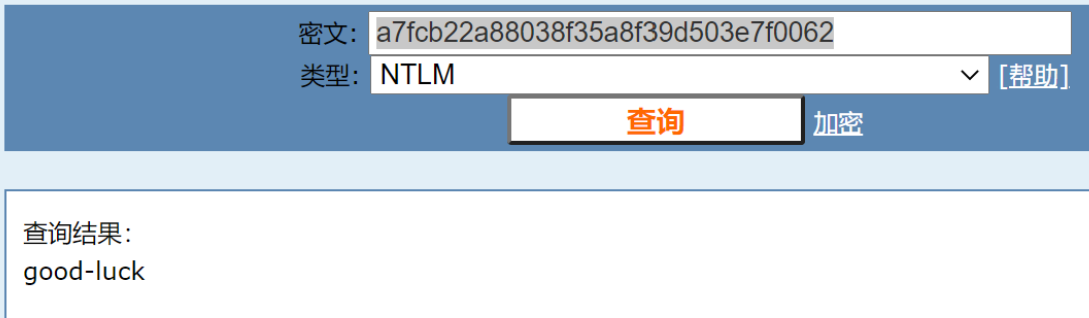
得到flag{good-luck}
BUuctf Alice与Bob
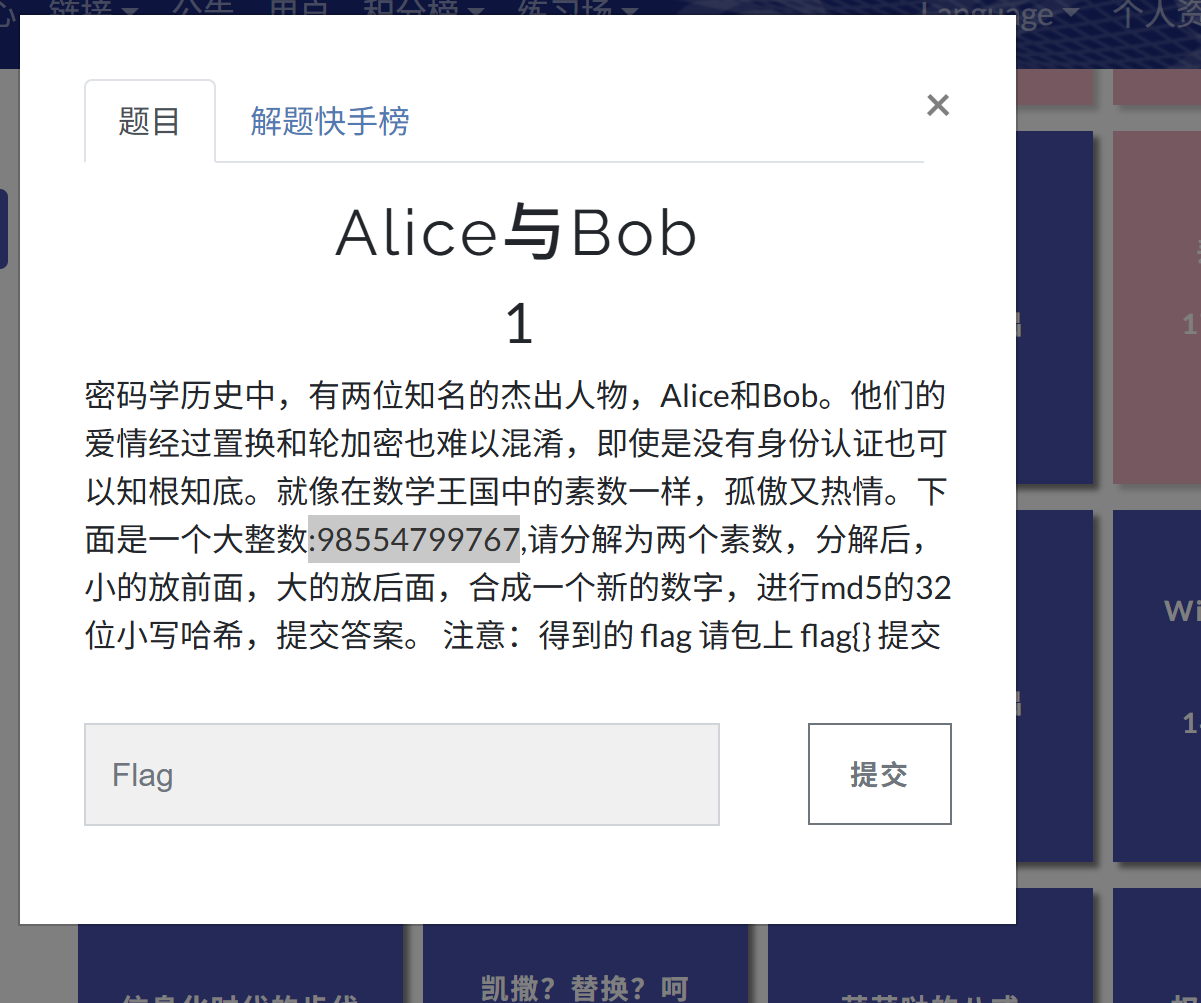
看出是把n分解为p,q
用网站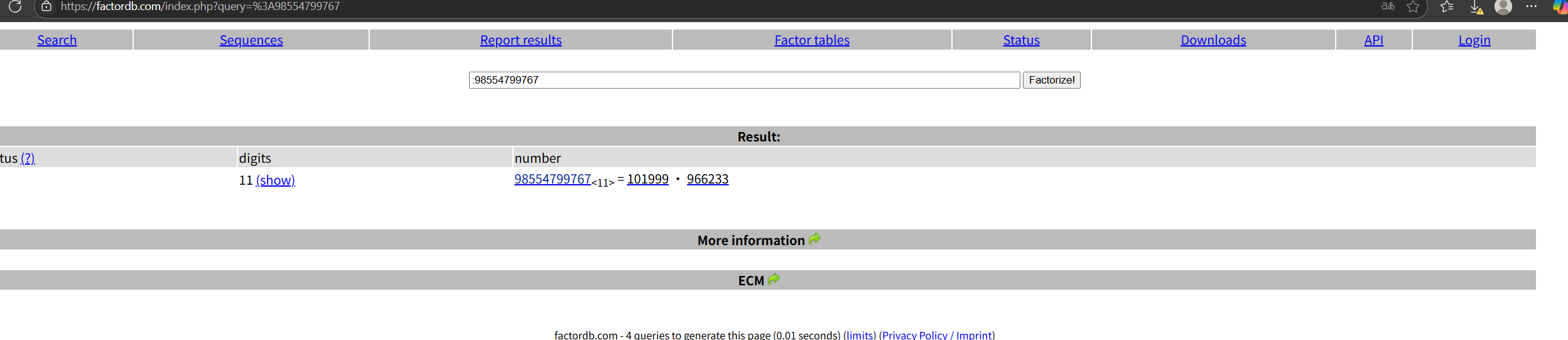
101999,966233
拼到一起101999966233
由题意得MD5哈希32位小写
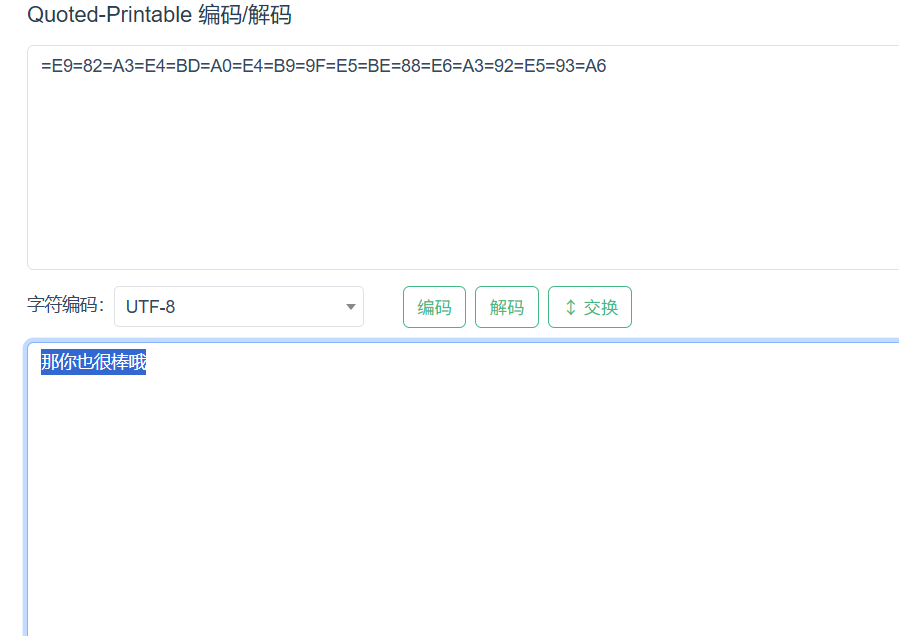
Quoted-Printable 编码
例题:BUUCTF Quoted-Printable
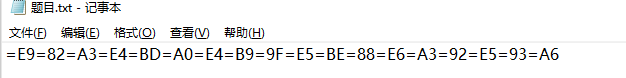
电报加密
简介
只由数字组成,经过查询是中文电码。中文电码表采用四位阿拉伯数字作代号,从0001到9999按四位数顺序排列,用四位数字表示最多一万个汉字、字母和符号。汉字先按部首,后按笔划排列。字母和符号放到电码表的最尾。后来因一万个汉字不能应付户籍管理的要求,又有第二字面汉字的出现。在香港,两个字面都采用同一编码,由输入员人手选择字面;在台湾,第二字面的汉字在开首补上“1”字,变成5个数字的编码。 然后我们可以查一下中文电码在线解密工具然后对这一串中文电码进行解密就OK了。
例题
BUUCTF 信息化时代的步伐(电报加密)
题目:
也许中国可以早早进入信息化时代,但是被清政府拒绝了。附件中是数十年后一位伟人说的话的密文。请翻译出明文(答案为一串中文!) 注意:得到的 flag 请包上 flag{} 提交
606046152623600817831216121621196386
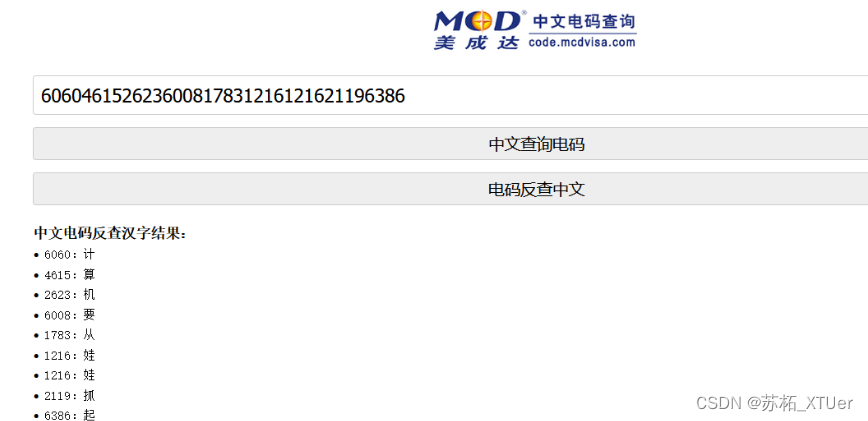
flag{计算机要从娃娃抓起}
强行爆破(简单替换)
BUUCTF 凯撒?替换?呵呵!(强行爆破又称简单替换)
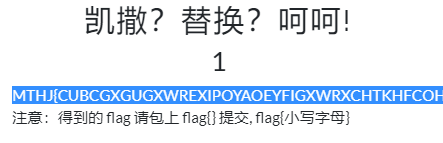
强行爆破quipqiup网站
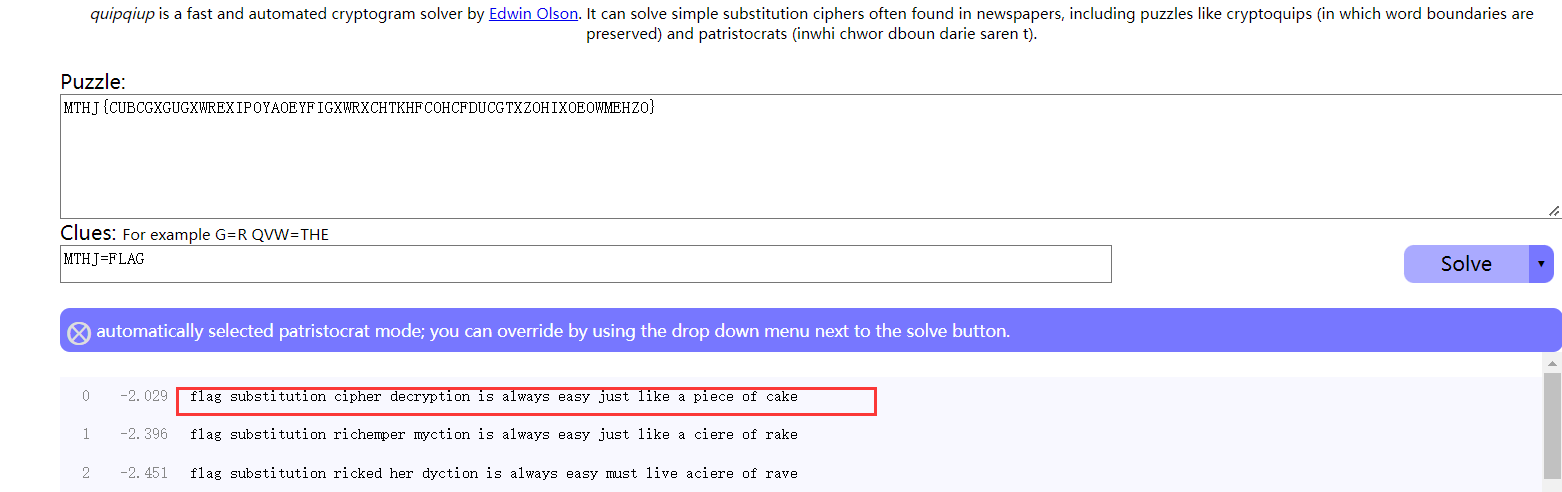
flag{substitutioncipherdecryptionisalwayseasyjustlikeapieceofcake}记得去掉空格
(附):
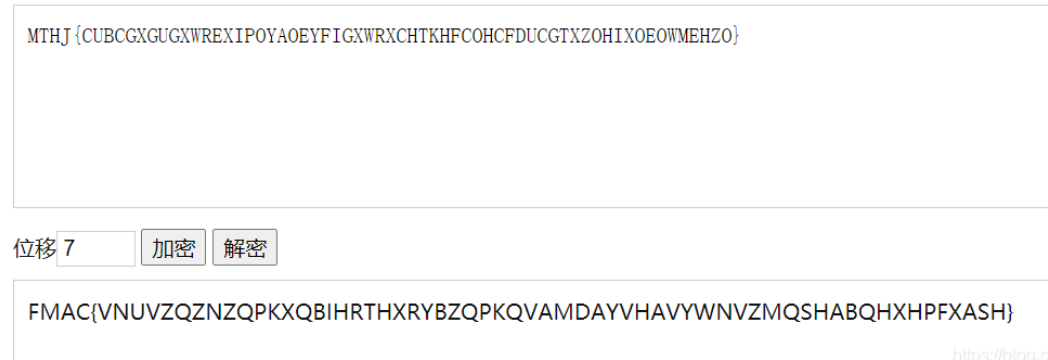
凯撒加密无果
我们首先使用凯撒加密,前四个字母得到的是FMAC而非想要的FLAG,FMAC四个字母之间也无规律可循,故尝试题目中提到的替换
BUUCTF 世上无难事(简单替换)
查看题目

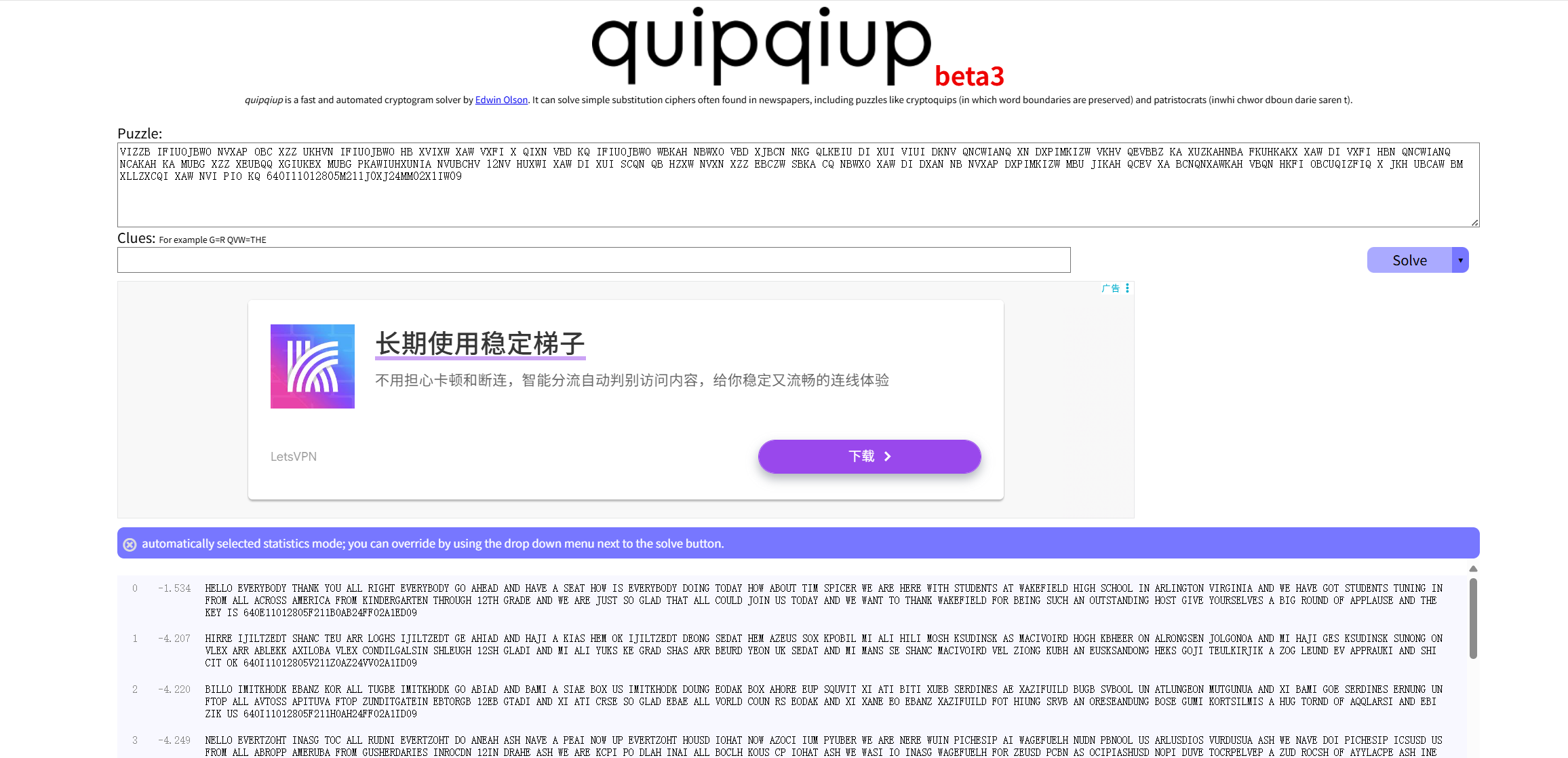
第0个就是答案
BUUCTF old-fashion同理
buuctf密码系列
BUUCTF UUencode(编码)
用工具
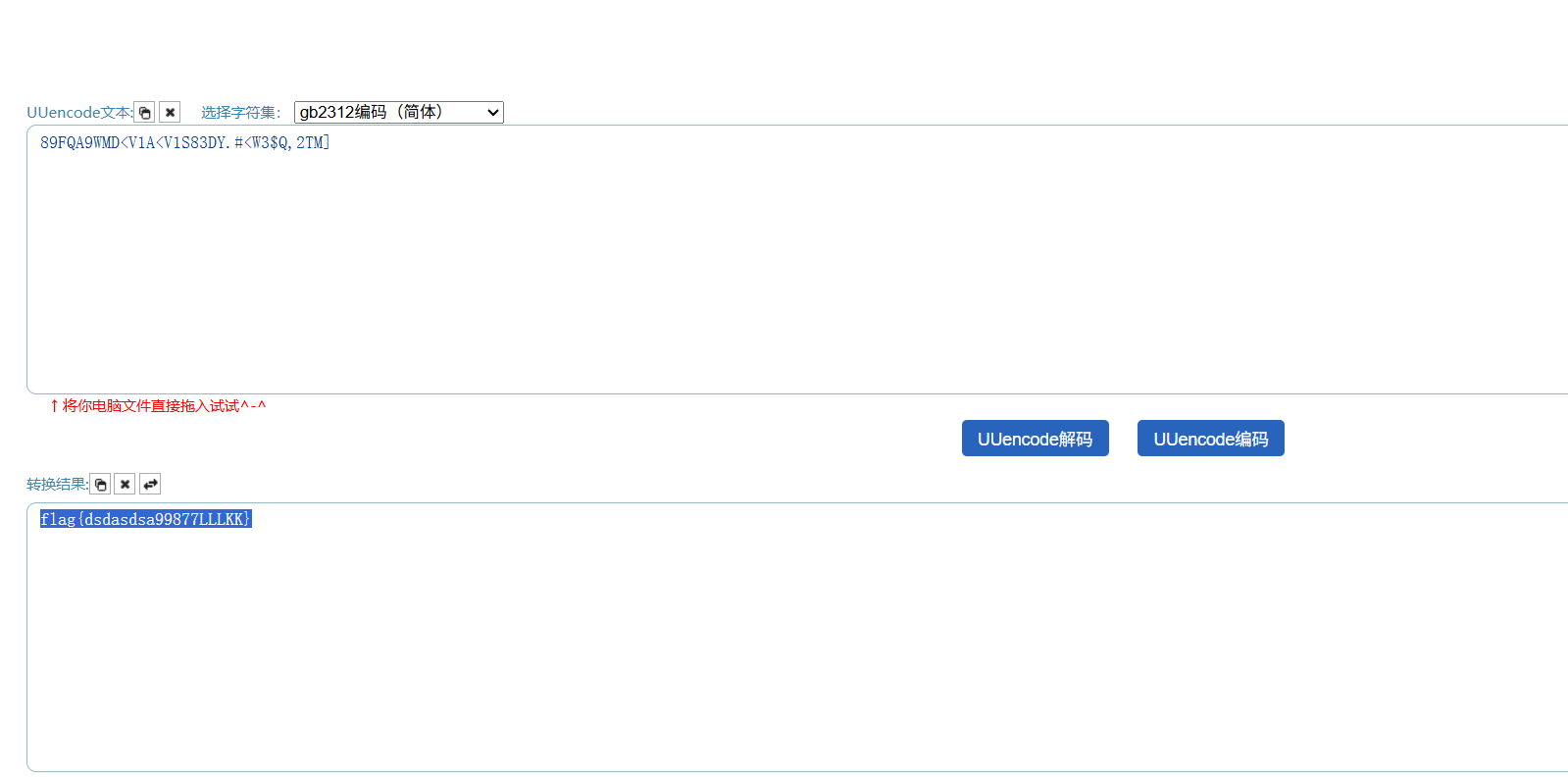
BUUCTF 还原大师
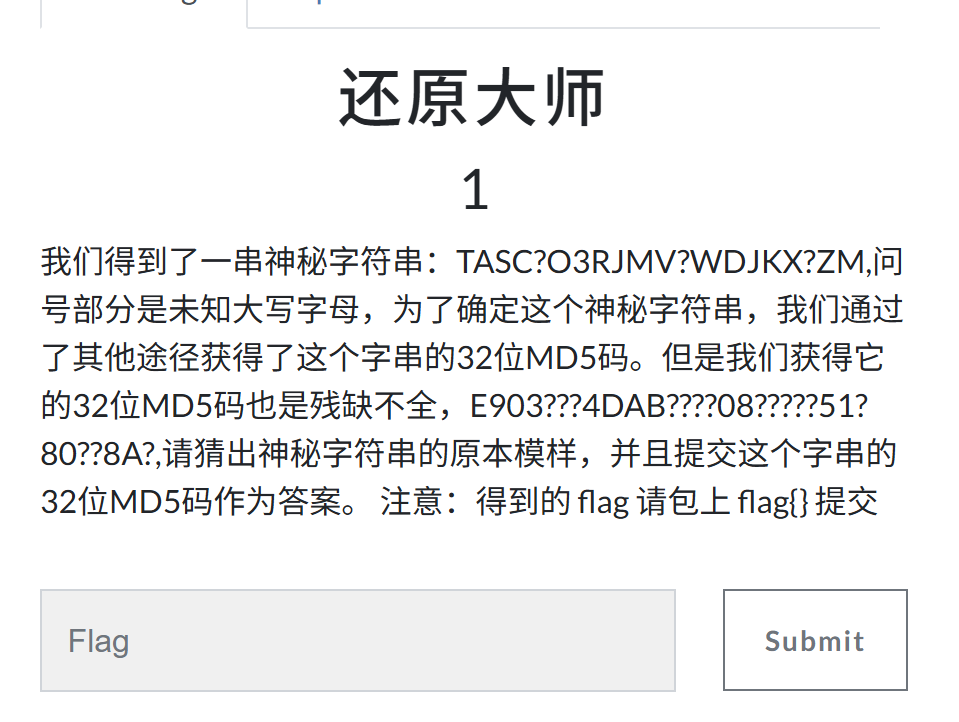
意思是:神秘字符串/md5值 都只有一部分
脚本:
import hashlib import string
def md5(str): m = hashlib.md5() m.update(str.encode("utf8")) return m.hexdigest()
for i in string.ascii_uppercase: for j in string.ascii_uppercase:
for k in string.ascii_uppercase:
c = 'TASC' + i + 'O3RJMV' + j + 'WDJKX' + k + 'ZM'
x = md5(c).upper()
if 'E903' in x and '4DAB' in x and '08' in x and '51' in x and '80' in x and '8A' in x:
print(c)
print(x)
break
BUUCTF 异性相吸
查看题目![在这里插入图片描述]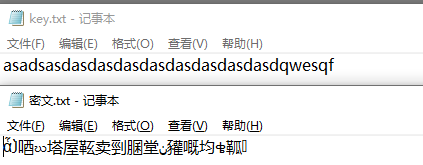
把这两个用010打开


进行异或
a = '0110000101110011011000010110010001110011011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011100010111011101100101011100110111000101100110'
b = '0000011100011111000000000000001100001000000001000001001001010101000000110001000001010100010110000100101101011100010110000100101001010110010100110100010001010010000000110100010000000010010110000100011000000110010101000100011100000101010101100100011101010111010001000001001001011101010010100001010000011011'
c = ''
for i in range(len(a)):
if(a[i] == b[i]):
c+='0'
else:
c+='1'
print(c)
运行得到0110011001101100011000010110011101111011011001010110000100110001011000100110001100110000001110010011100000111000001110010011100100110010001100100011011100110110011000100011011101100110001110010011010101100010001101010011010001100001001101110011010000110011001101010110010100111000001110010110010101111101
二转十六 十六转文
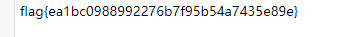
BUUCTF密码学的心声
1.打开可以看到一个曲谱![img]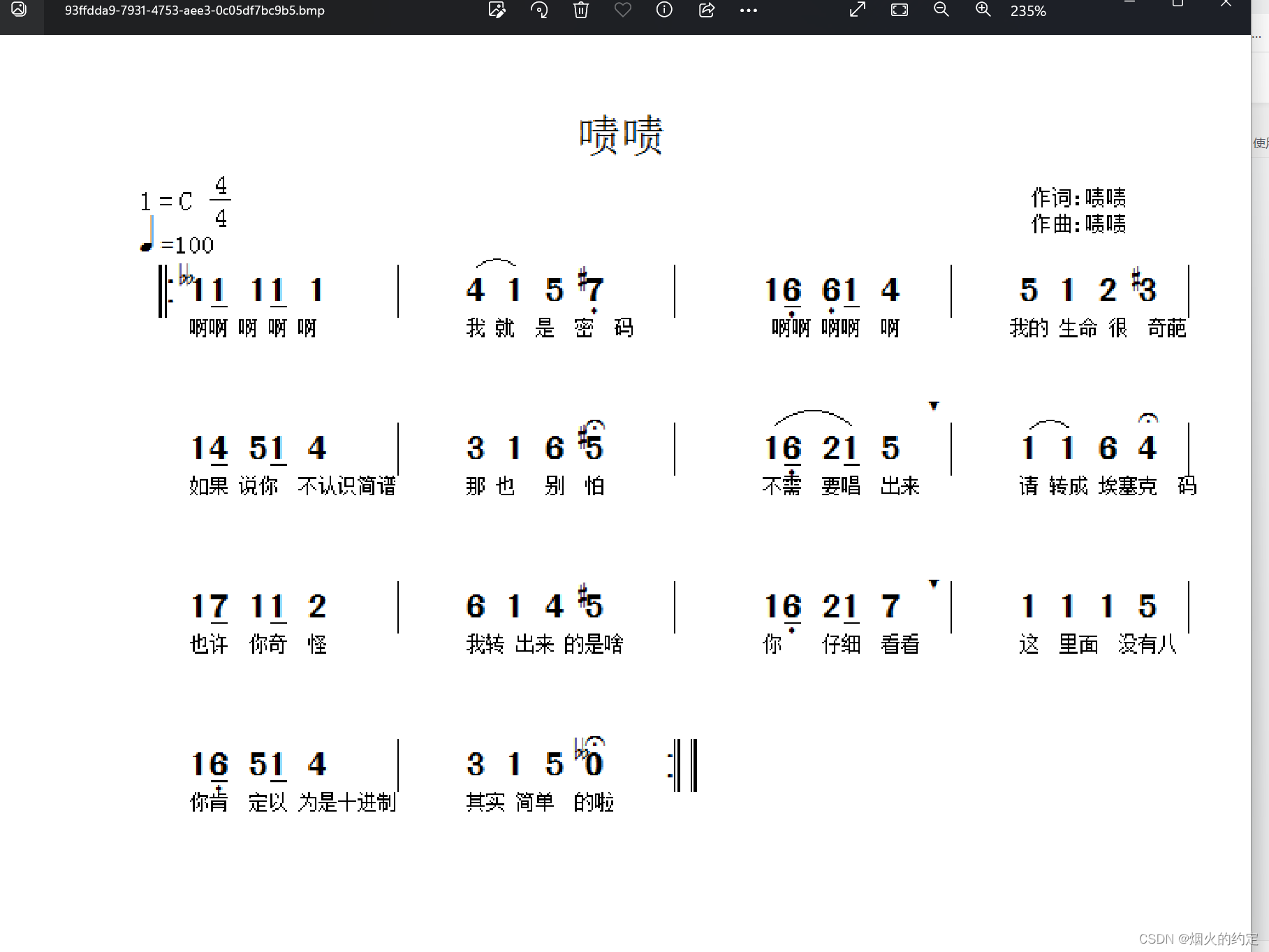
2.看到曲谱中的提示埃塞克码可以想到ascii码,没有八可以联想到八进制,而八进制又对应着三位的二进制,然后写个脚本就好了
l = [111,114,157,166,145,123,145,143,165,162,151,164,171,126,145,162,171,115,165,143,150]
res = ''
for i in l:
i = str(i)
res += chr(int(i,8))
print(res)
3.运行得到flag
flag{ILoveSecurityVeryMuch}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号