第四次作业
第四次个人作业
(1).介绍
| 作业要求地址 | 地址 |
|---|---|
| GitHub项目地址 | 项目 |
| 结对伙伴博客 | zofun的博客 |
| 本人学号 | 201731062415 |
| 结对伙伴 | 唐财伟 |
(2).PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 700 | 720 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 40 | 30 |
| Design Review | 设计复审 (和同事审核设计文档) | 60 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 120 | 120 |
| Coding | 具体编码 | 300 | 480 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 120 |
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 1690 | 1955 |
(3).接口设计与实现
- 分析
本次作业的话,大致可以分为以下几个基础功能:
- 统计字符
- 统计单词总数
- 统计行数
- 统计文件中各单词的出现次数,最终只输出频率最高的10个
- 思路
我们希望利用一种模式,能够输入的文本和利用该文本进行的一系列操作解耦,让他们脱离开来,于是我们单纯的考虑到了职责链模式,该模式可以将请求的发起者和请求的处理者解耦,我们在仔细分析了该模式在本次作业中的可行性后,发现职责链模式确实可以来解决本次问题,于是我们便开始了代码的思考。 - 实现过程
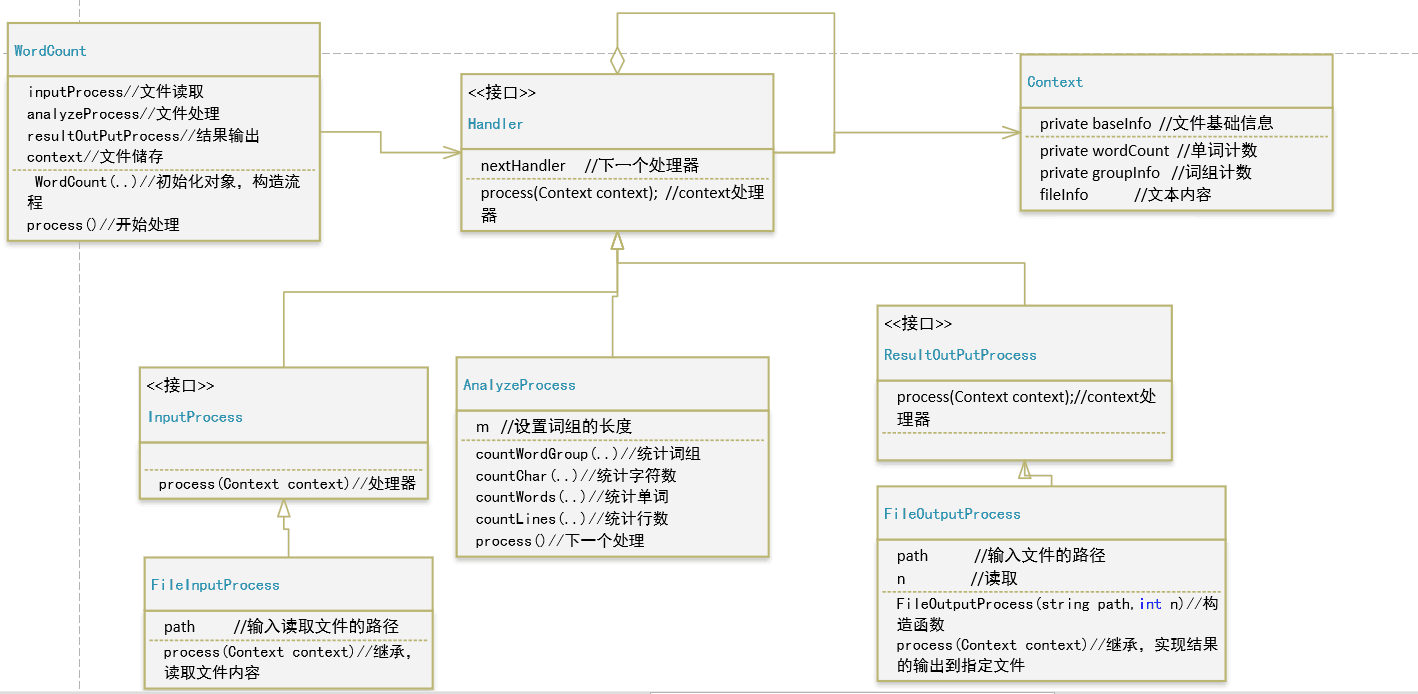
我们设计了总共8个类来实现所有的功能,具体如下:
- Handler类:作为抽象处理者,定义了抽象的处理方法process
- Program类:作为client(客户)类,向链中的对象提出请求
- Context,AnalyzeProcess,WordCount,ResultOutPutProcess,InputProcess类,作为具体的处理者。
- FileOutPutProcess,FileInputProcess:作为具体实现处理者的类,这两个类作为文件输入和输出。
大概的类图如下:
关键代码:
- 统计字符数:
public void countChar(Context context)
{
int count = 0;
foreach (char countchar in context.FileInfo)
{
if(countchar<128 && countchar >= 0)
{
count++;
}
}
context.BaseInfo.Add("characters", count);
}
- 统计每个单词出现次数
private void countWords(Context context)
{
string[] words = Regex.Split(context.FileInfo, @"\W+");
context.BaseInfo.Add("words", 0);
foreach (string word in words)
{
if (word.Length >= 4)
{
context.BaseInfo["words"]++;
}
if(word != "")
{
if (context.WordCount.ContainsKey(word))
{
context.WordCount[word]++;
}
else
{
context.WordCount[word] = 1;
}
}
}
}
- 统计行数
private void countLines(Context context)
{
mch = Regex.Matches(context.FileInfo, "\n");
context.BaseInfo.Add("lines", mch.Count+1);
}
- 统计词组
public void countWordGroup(Context context ,int m)
{
string[] words = Regex.Split(context.FileInfo, @"\W+");
for (int i = 0; i < words.Length - m; i++)
{
string wordGroup = null;
for (int j = i; j < i+m; j++)
{
wordGroup = wordGroup+words[j]+" ";
}
if (context.GroupCount.ContainsKey(wordGroup))
{
context.GroupCount[wordGroup]++;
}
else
{
context.GroupCount[wordGroup] = 1;
}
}
}
- 输出表达式(展示一部分)
sw.WriteLine("单词统计信息:");
//按字典序排序
context.WordCount = context.WordCount.OrderByDescending(o => o.Value).ThenBy(o => o.Key).ToDictionary(o => o.Key, o => o.Value);
int count = 0;
foreach (KeyValuePair<string, int> entry in context.WordCount)
{
sw.WriteLine("{0}:{1}", entry.Key.ToLower(), entry.Value);
count++;
if ((count == n) && n != -1)
{
break;
}
}
(4).代码复审过程
- 代码规范
我们采用了该代码规范 - 代码复审
我的某些功能实现的并不是很严谨,在我自己运行时没发现,在同伴的审查下,某些小缺陷一下就暴露出来了,得到了及时的更正,所以更多时候是我们共同审核我的部分(狗头)。。
(5).计算性能
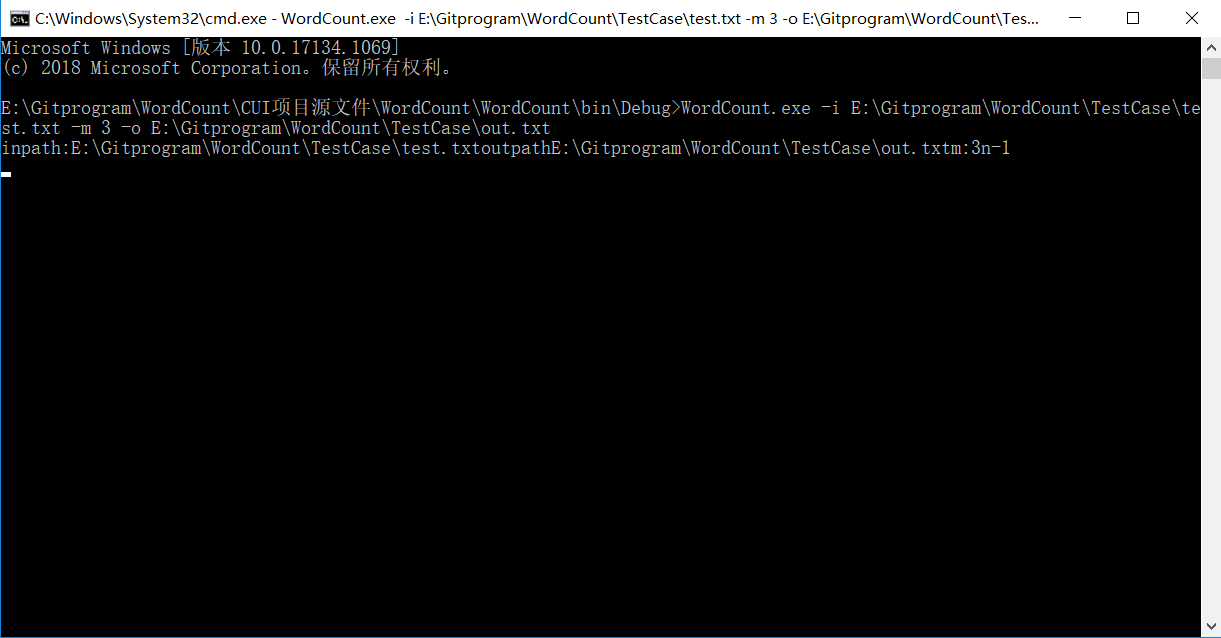
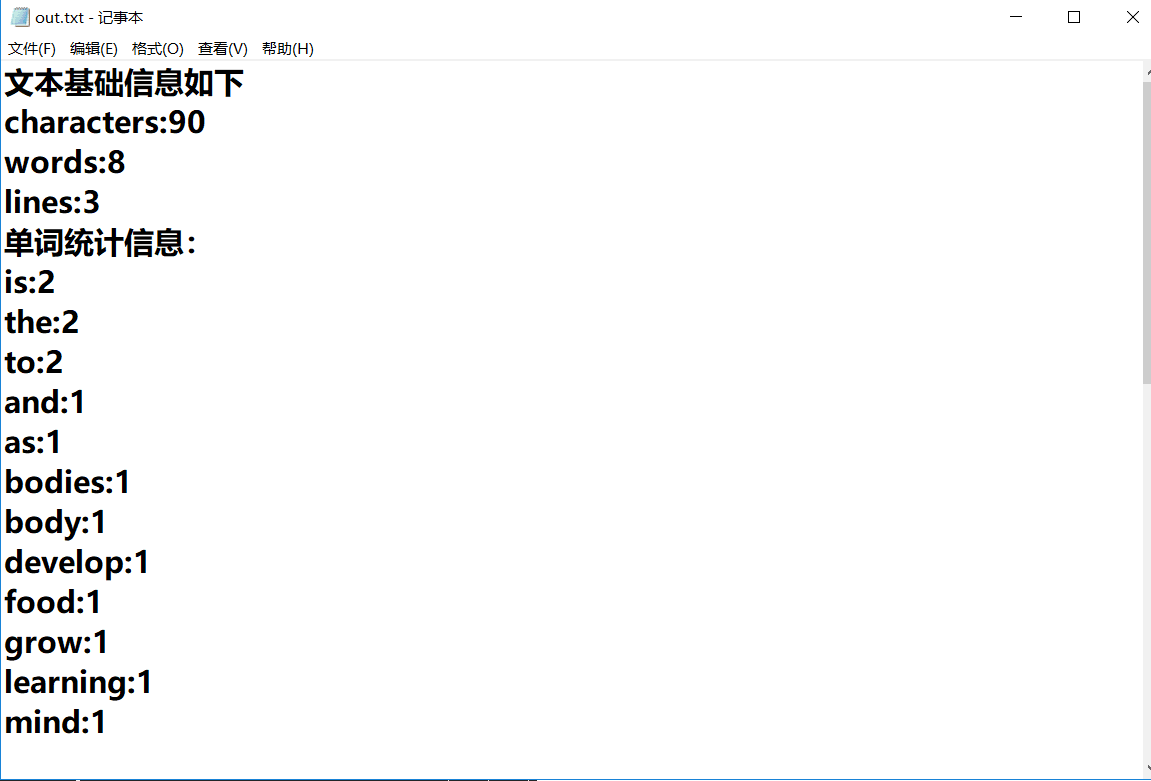
- 运行过程:
- 性能
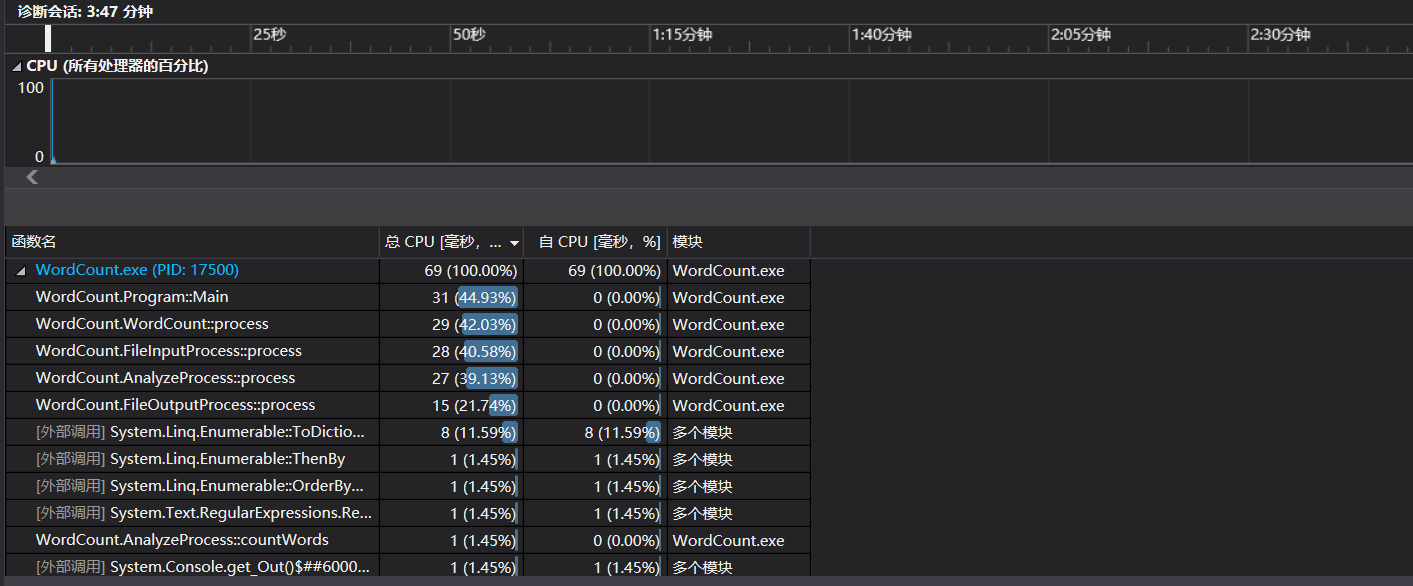
可以看到,大部分的资源都耗费在了WordCount上,但是程序总的耗费时间很短,因此修改的需求并不是很大。
(6).单元测试
- 统计字符模块的单元测试
- 编写单元测试代码

- 查看测试结果

- 统计单词模块的单元测试
- 编写测试代码

- 测试结果

- 统计词组模块的单元测试
- 编写测试代码

- 测试结果

(7).异常处理
- 读取文件时的异常处理代码
try
{
text = File.ReadAllText(path);
context.FileInfo = text;
//Console.WriteLine("文本内容如下" + context.FileInfo);
//完成文本内容的读取后,交由下一个处理
getNextHandler().process(context);
}
catch(Exception e)
{
Console.WriteLine("请输入正确的文件路径!");
}
- 输出文件异常处理代码:
try
{
sw.WriteLine("文本基础信息如下(其中words统计了小于等于4个字母的)");
foreach (KeyValuePair<string, int> entry in context.BaseInfo)
{
sw.WriteLine("{0}:{1}", entry.Key, entry.Value);
}
sw.WriteLine("单词统计信息:");
//按字典序排序
context.WordCount = context.WordCount.OrderByDescending(o => o.Value).ThenBy(o => o.Key).ToDictionary(o => o.Key, o => o.Value);
int count = 0;
foreach (KeyValuePair<string, int> entry in context.WordCount)
{
sw.WriteLine("{0}:{1}", entry.Key.ToLower(), entry.Value);
count++;
if ((count == n) && n != -1)
{
break;
}
}
sw.WriteLine("词组统计信息:");
context.WordCount = context.WordCount.OrderByDescending(o => o.Value).ThenBy(o => o.Key).ToDictionary(o => o.Key, o => o.Value);
foreach (KeyValuePair<string, int> entry in context.GroupCount)
{
sw.WriteLine("{0}:{1}", entry.Key.ToLower(), entry.Value);
}
}
catch (Exception e)
{
Console.WriteLine("输出文件错误!");
}
finally
{
sw.Flush();
sw.Close();
}
(8).结对过程
因为是室友,合作了那么多次,所以没有经过考虑,我们便结对了。
结对照片

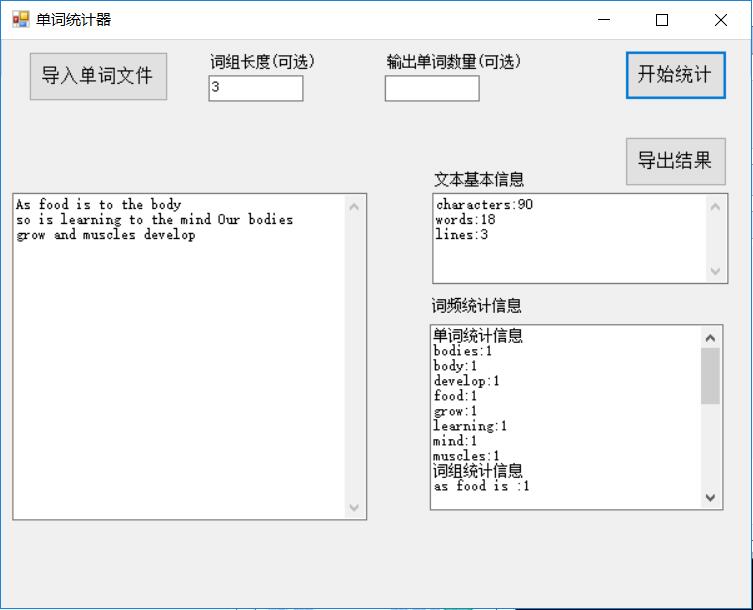
(9).附加功能
(10).总结
对于我来说,这次结对编程的效果绝对是1+1>2的,如果只是我一个人的话,我不会想到用什么模式来实现这样的问题,在我的考虑里,一个类可能就能解决掉所有的功能,但是这样的写法在以后肯定是会出现大问题的,我知道,所以这次的结对给我了一种新的考虑问题的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号