

python正则表达式
参考:https://www.runoob.com/python/python-reg-expressions.html 整理所得。
一、 march, search, findall, sub的区别
import re s = 'xx,Hello World Wide web, helloPython' # 生成一个正则表达式 reg = re.compile(r'(hello\w*)',re.IGNORECASE) # 从头开始匹配,并返回第一个匹配的结果。如果一开始就不匹配停止匹配,返回None。 print(reg.match(s)) # 从0开始第3位(包含)开始匹配,并返回第一个匹配的结果。如果一开始就不匹配就返回None。 print(reg.match(s,3)) # 从头开始匹配返回第一个匹配的结果,如果一开始就不匹配就继续匹配。 print(reg.search(s)) # 从0开始第4位(包含)开始匹配,第30位截止(不包含),返回第一个匹配的结果,如果一开始就不匹配就继续匹配。 print(reg.search(s,4,32)) # 返回所有结果 print(reg.findall(s)) # 替换所有的hello为hi~ print(reg.sub('hi~',s))
二、(),[],{} 的区别,参考:https://www.cnblogs.com/richiewlq/p/7307581.html
(abc)
[abc]
(a|b|c)
(\s*)
[\s*]
(abc){1,2}
三、贪婪和非贪婪匹配
import re # 贪婪模式 print(re.findall(r'(a.*b)','aacbccacxxxbbb')) # 非贪婪模式 print(re.findall(r'(a.*?b)','aacbccacxxxbbb')) print(re.findall(r'(a.*?)','aacbccacxxxbbb'))
['aacbccacxxxbbb']
['aacb', 'acxxxb']
['a', 'a', 'a']
四、分组匹配高级用法
import rea = 'interface = "/xxx/xx/a.json" and env="prod" and app = "app1" and app = "fff" and app in ("a","b") '
# Groupdict的用法: s = '1102231990xxxxxxxx' res = re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_year>\d{4})',s) print(res.groupdict())
{'province': '110', 'city': '223', 'born_year': '1990'}
# Scanner的用法:
# a = "app in ('xxx')"
KEY = r'(?P<KEY>[\(\)\'\"a-zA-Z./,]+)'
EQ = r'(?P<EQ>\s*=\s*)'
AND = r'(?P<AND>\s*and\s*)'
IN = r'(?P<IN>\s*in\s*)'
# master_pat = re.compile('|'.join([EQ,AND,KEY,IN]))
print('|'.join([KEY,EQ,IN,AND]))
master_pat = re.compile('|'.join([KEY,EQ,IN,AND]))
scanner = master_pat.scanner(a)
for m in iter(scanner.match,None):
print(m.lastgroup)
print(m.group().strip())
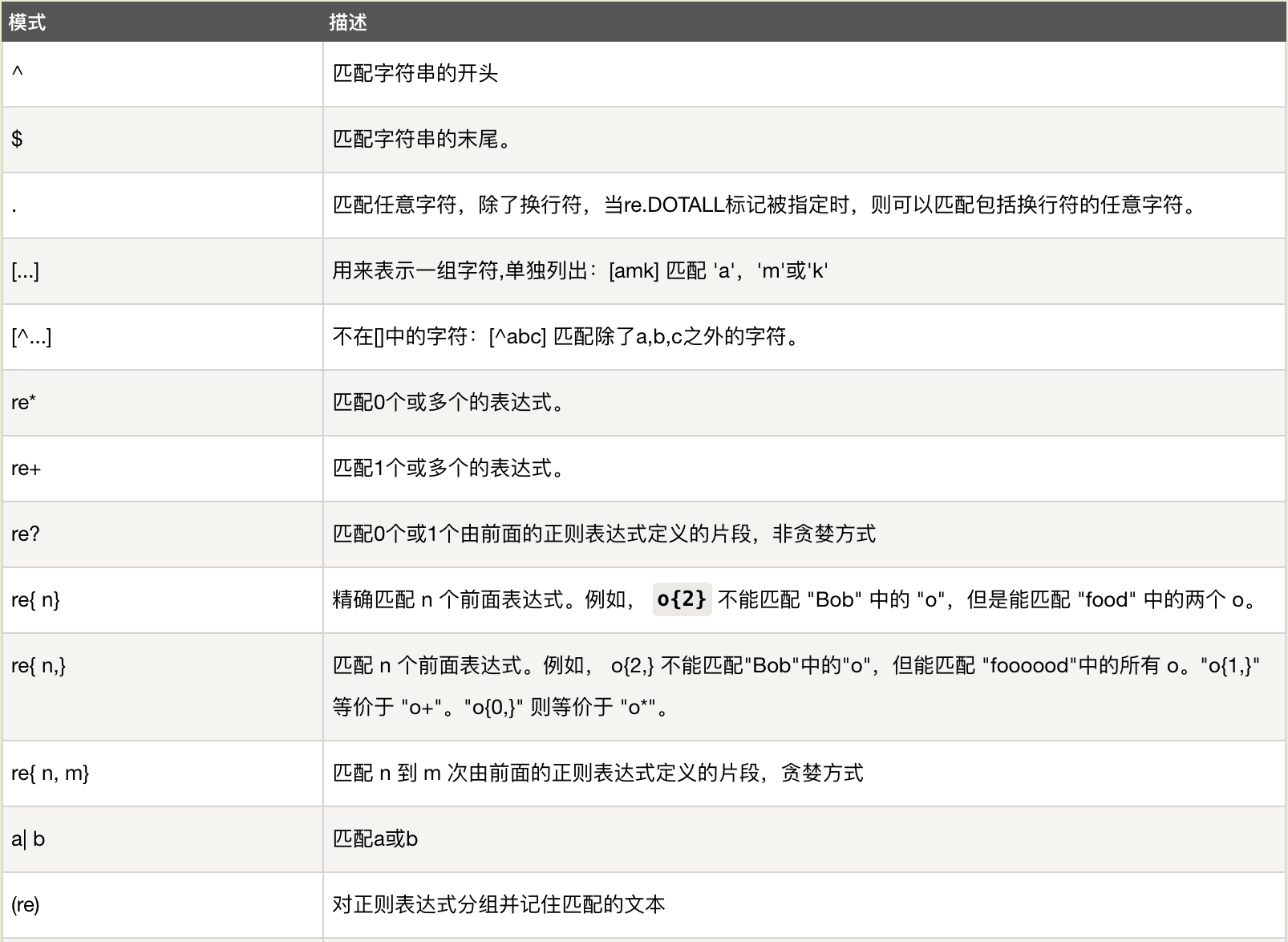
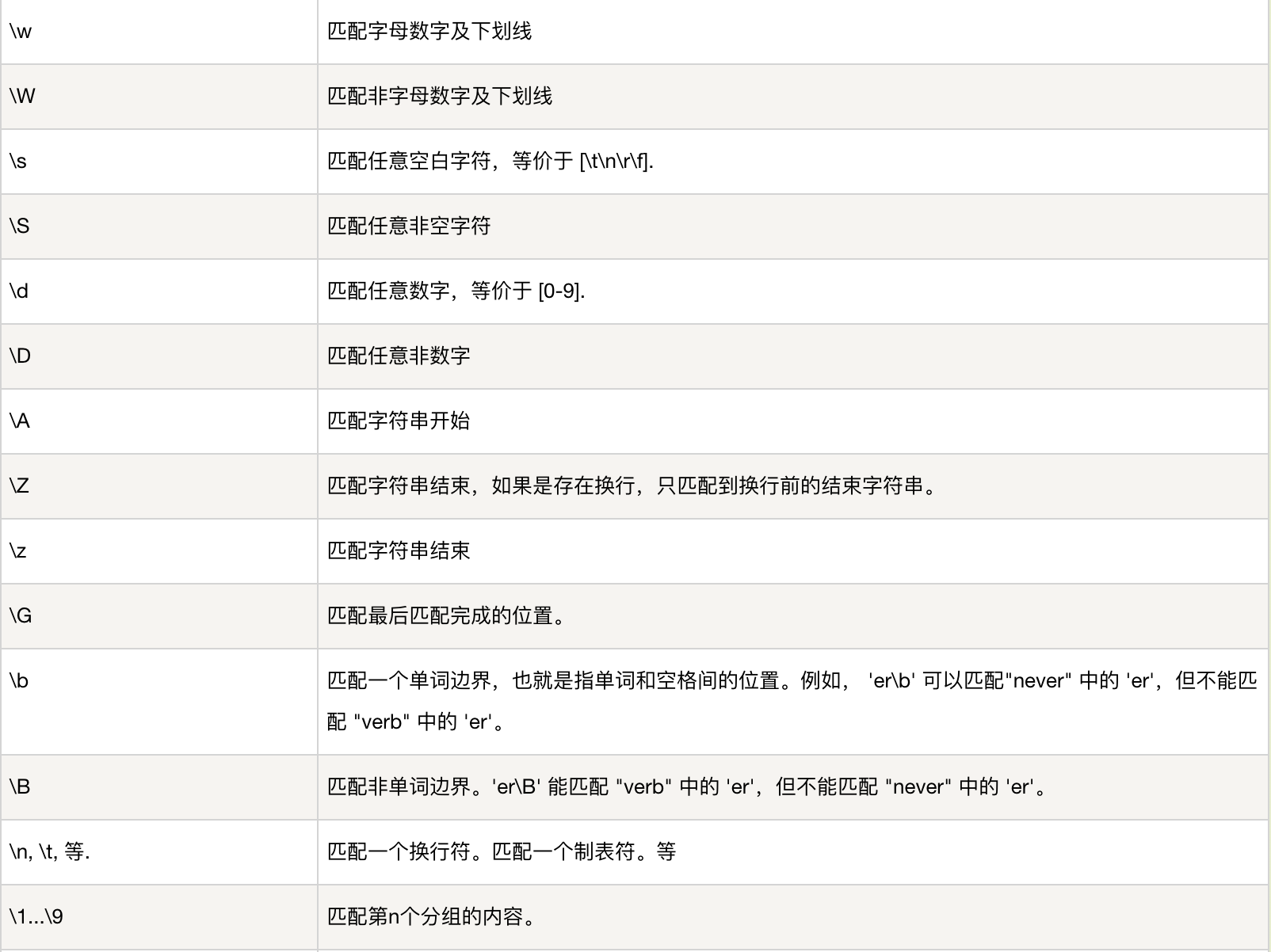
五、常用的正则规则(参考:https://www.runoob.com/python/python-reg-expressions.html)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号