

关于 CU、PE 和 work-group、work-item 的理解
学习OpenCL,按最初的理解,对一个 GPU,其CU数是固定的,每个CU的PE数也是固定的,编程时,work-group数对应CU数,work-item数与PE数一致就ok啦。
我的显卡是 MX450(够差),参数:
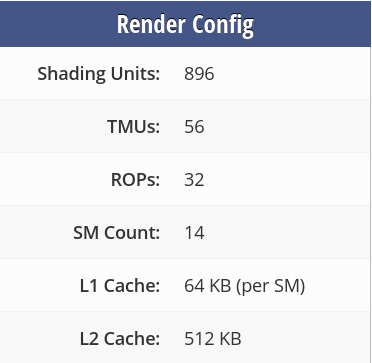
直观理解,CU=14,PE=896/14=64, 那么 work-group=14, work-item=64。
但是:
Max compute units 14
Max work item sizes 1024x1024x64
Max work group size 1024
Preferred work group size multiple (device) 32
上面是程序调用 clGetDeviceInfo(), CL_DEVICE_MAX_WORK_GROUP_SIZE 得到的结果是 1024,CL_DEVICE_PREFERRED_WORK_GROUP_SIZE_MULTIPLE 得到的结果是 32,都和前面的理解对不上。
再调用 clGetKernelWorkGroupInfo(), CL_KERNEL_WORK_GROUP_SIZE 得到的结果是 256,CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE 得到的结果是 32。
这两个函数的各个参数都没法得到 PE=64,在网上查了好长时间都没搞清楚。
那么,怎么设置 PE?
查到 https://community.khronos.org/t/cl-device-max-work-group-size-vs-cl-kernel-work-group-size/3234 的说法:
CL_KERNEL_WORK_GROUP_SIZE给出了可以分配给1个工作组的工作项的“最终”数量。这一点只有在我们创建内核之后才能发现。任何高于这个值的值都会导致错误。
不同的内核将有不同的最大工作组大小。这主要取决于运行内核所需的通用寄存器的数量,而这又取决于内核中__private(函数作用域)变量的数量。
如果你想增加调用clEncodeNDRangeKernel()成功的可能性,那么,你应该为所有参数调用clSetKernelArg(),然后检查CL_KERNEL_MEM_SIZE是否小于或等于 CL_DEVICE_MEM_SIZE。
怎么设计work-group、work-item数?
我理解 work-group 是 CU 的倍数,work-item 是 PE 的倍数,GPU 会自行安排,按照并行-串行-并行的方式运行。
例如,CU=2,PE=4,work-group=4、work-item=8,
运行顺序为:
group0、1 的 item0~3,并行
group0、1 的 item4~7,并行
group2、3 的 item0~3,并行
group2、3 的 item4~7,并行
不过,我还没完全确认自己的理解是否正确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号