Linux 平台 Nvidia GPU 的 OpenCL 开发环境搭建
对一个项目设计方案进行优化计算,因为严重非线性、多峰等问题,常规优化算法效果极差。
采用遗传算法来计算,效果不错,搜索到最优点的概率比较高。只是计算速度很慢,一个计算点大概要2个多小时,方案一次要算大约2千点,这哪算得过来啊?
考虑到遗传算法多个体的特点,天然适合并行计算,就找熟人申请了个服务器,40核的,确实速度有很大提高,一个计算点只要10分钟,两周时间可以算一次方案,可以接受吧。
最近,项目要求进行方案对比分析,要计算多个方案,这就麻烦了。
想到用 GPU,其计算核心多达数千个,应该更能加速计算。
我的电脑装的是 Nvidia MX450 显卡,比较低端,核心数 896,先用着进行编程调试,调通了再找高级机器。
考虑到通用性,没用 CUDA,而是用 OpenCL,记录下开发环境的搭建步骤:
一、操作系统是 Linux Mint,已经安装 Nvidia 的驱动。
Nvidia GPU 的 OpenCL 支持在 CUDA 包内,需先安装 CUDA 包。
运行 nvidia-smi,显示
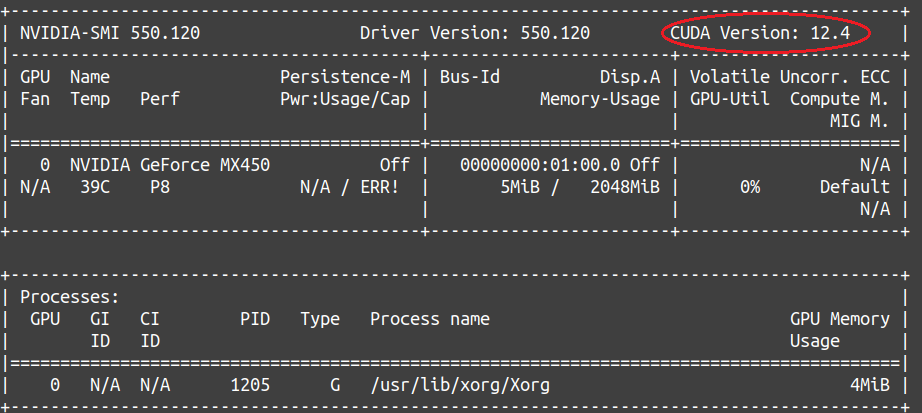
可以看出,这个显卡支持 CUDA 12.4
二、在 https://developer.nvidia.com/cuda-toolkit-archive 下载 CUDA Toolkit 12.4.1;
三、直接安装 CUDA Toolkit 12.4.1 显示空间不足
机器上 /分区还有 10g 空间,怎会不足?
查了下,发现是 CUDA Toolkit 12.4.1 安装过程解压占用了 /tmp,导致剩余空间不足。
解决办法,在 /home 分区新建 /home/tmp,运行
sudo sh cuda_12.4.1_550.54.15_linux.run --tmpdir=/home/tmp/
安装成功。
四、安装 OpenCL
sudo apt-get install ocl-icd-opencl-dev clinfo
有帖子说还要安装 ocl-icd-libopencl1 opencl-headers nvidia-opencl-dev,在机器上发现 CUDA Toolkit 已安装了 ocl-icd-libopencl1 和 OpenCL的include、lib64,无需再安装这几个包,后续也验证了。
五、在~/.bash.rc增加
export LD_LABRARY_PATH=$LD_LABRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=/usr/local/cuda
六、可以进行 OpenCL 程序的编程了,在 CMakeLists.txt 中增加
target_link_libraries(${PROJECT_NAME} OpenCL)
add_compile_definitions(CL_TARGET_OPENCL_VERSION=300)
用QtCreator新建了个 C 语言项目,跑了个向量相加的例子,成功。
后续要进行遗传算法程序向 GPU 的移植。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号