理解java中的volatile关键字
你好,这篇文章总结一下java中的volatile关键字。
从CPU讲起
大家都知道,存储设备容量越大越贵,速度越快越贵。
而计算机可以简单的看作为三步
- 输入
- 处理
- 输出
早期计算机使用的是穿孔纸袋作为输入,可以想象,输入的速度有多么的低~
随着计算机的发展,处理速度和输入速度都取得了飞跃性的发展。而处理速度更是远超输入速度。
为了弥补CPU与内存之间速度的鸿沟,有了DRAM(也就是我们说的内存),SRAM(L1CACHE,L2CACHE使用的叫做SRAM,构造复杂,价格比DRAM高得多)
从CPU到DRAM,中间还有:
TLB(快表,0周期)
L1CACHE(L1缓存,一些地方给出的数据是仅有1CPU周期的延迟)
L2CACHE(L2缓存,有更多延迟)
L3CACHE(L3缓存,更多更多的延迟)
当CPU想请求某个字的时候,将首先从L1缓存中去读,如果读不到,将从L2中读。再读不到,继续去L3读。
如果直接读到了缓存,这就是缓存命中(cache hit)。如果没读到,就是缓存不命中(cache miss).
缓存不命中(cache miss)有三种情形。
- 冷不命中(cold miss),
- 冲突不命中(conflict miss)
- 容量不命中(capacity miss)
后续的文章可能会详细介绍
以上是读相关的,写相关的更容易理解一些。
写分为 write-through 和 write-back
write-throuth理解为写穿,指的是将写的结果一路穿透到最下层的存储器。(理解为同步刷盘)
write-back理解为写即回,写了之后将写的内容标记一下,只有当需要更新的时候,再将这些内容写到下一层的缓存。(理解为异步刷盘)
MESI一致性协议
大家都知道,并发问题的根本原因都是出现了竞态(race condition)。
为了消除竞态,业界有很多种办法。
最好的方式当然就是从一开始就不出现并发问题,比如严格控制线程之间的调度顺序(hash的一些运用),单线程操作(redis),特殊的数据结构(disruptor)
更次一点的,比如java中的string,是不可变(immutable)的,这样也从根本消除了竞态。
最差的解决方案便是加锁了。
我主业是java,碰到有问题的变量一个synchronized就套上去,很快啊。
再比如数据库,比如mysql,各种奇奇怪怪的锁,什么intention lock啊,insert intention lock啊,balabala的。复杂又不友好。
高层应用有这么多的方法解决竞态,那么cpu呢?cpu现在都是多核的了,cpu怎么解决并发写?
进入正题。
MESI协议(Modified-Exclusive-Shared-Invalid) 是一种缓存一致性协议,用于保证缓存一致。
CPU的结构
在开始之前,先简单描述一下CPU的逻辑结构
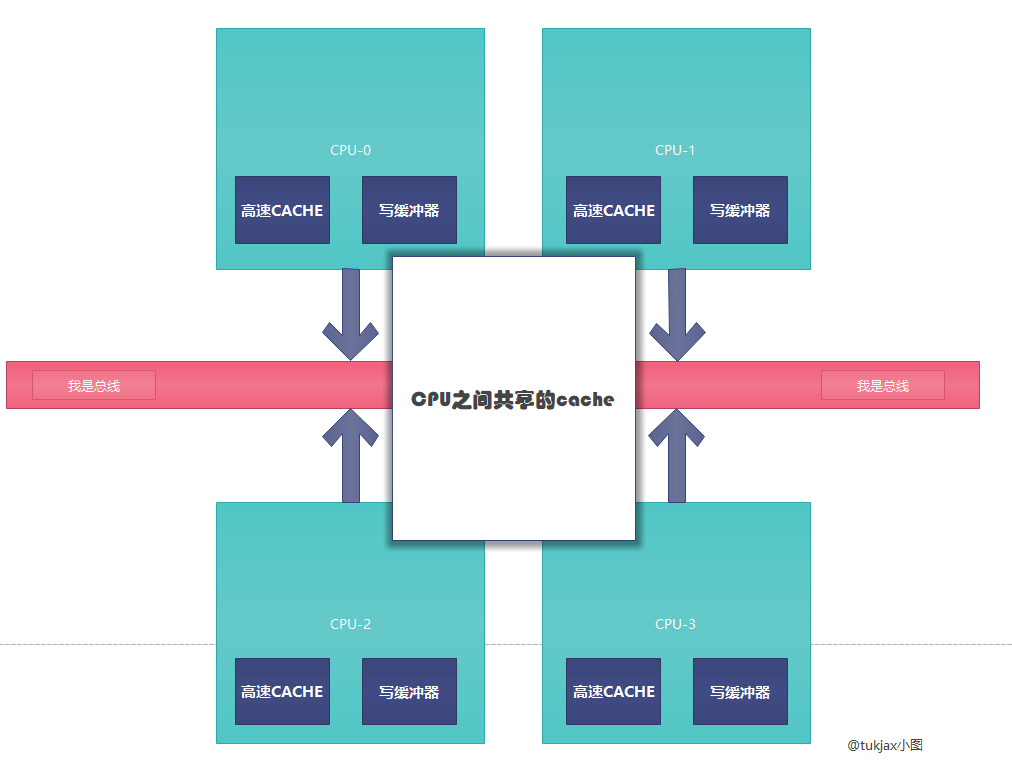
如图,每个CPU都有自己的缓存--高速CACHE,只有自身可以进行读写
CPU与CPU之间有共享缓存
CPU与CPU之间靠总线交互信息
写缓冲器 在后文介绍
MESI的目的
像一开始说的那样,CPU真的是太快太快了,能跟得上CPU速度的存储介质太贵太贵了。
为了省钱,越快的缓存越小,越靠近CPU。
CPU运算出来的结果先存到靠近CPU的高速CACHE中,高速缓存满了,再下放到更低一层地存储介质里,如此往复。
每个CPU都有自己的高速缓存,在大家都只是读数据的情况下,这当然没有啥并发问题---就像java中的string一样,都只是读罢了,完全没有竞态。
那如果CPU-0想写数据呢? 假设CPU-0要将某段内存地址A的值从0变成3,而CPU-1中的高速缓存仍然存储A的值为0,这两个CPU的值不就不一样了?
这岂不是读脏数据?
为了解决这种问题,我们有了MESI协议。
什么是MESI
MESI没有啥很高大上的含义,是几个单词的缩写
Modified---Exclusive---Shared---Invalid
M---E---S---I
yo
每条数据,在这条数据上,会有一个位置来存储这个数据当前的状态。
这个状态 只有四种
从一个CPU的视角出发.
Modified: 这条数据已经被我改变过了,我可以随意操作
Exclusive: 这条数据是我独享的,我可以随意操作
Shared: 这条数据可能被其它CPU也读到了,我要小心谨慎一点
Invalid : 这条数据失效啦!不再是我的了
想象消费者生产者模式,理解一下
每个CPU,自己又是消费者,又是生产者。
自己消费的内容有四种,如下图,包括Read,Invalidate,Read Invalidate,Writeback。
自己能生产的消息只有两种,Read Response, Invalidate Acknowledge。

看到这你也许已经晕了,没关系,这张图不重要,可以回头再看。结合下面这张图,来实际的运用一次。
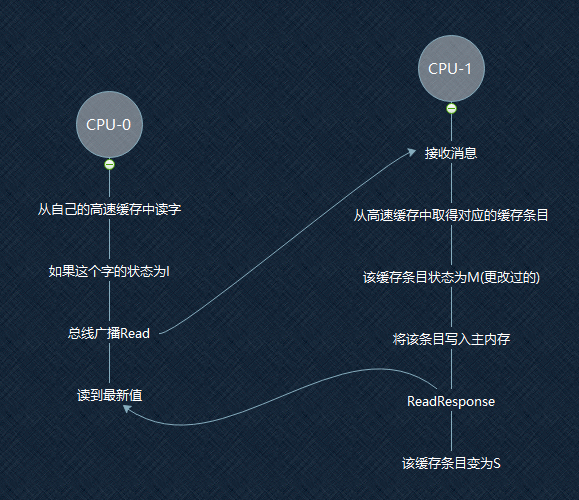
请看图,CPU-0要读一个数据,发现,欸,这条数据在我的高速缓存里,但状态是I,意思这条数据不再是我的了。那我得去别的地方读。
于是CPU-0进行一个总线的广播,CPU-1接到了这条消息,于是CPU-1从自己的高速CACHE里拿这个地址的数据(这里注意,是从自己的高速缓存里而不是写缓冲器里!对后面的理解重排序很重要!)。
CPU-1发现,欸,这条数据是M状态,意思是被我修改过,也许其它CPU还不知道这条数据被我修改过呢?我得赶紧把这条被我修改过的数据高速其它CPU,于是CPU-1把这条数据写到共享CACHE里,再通过总线响应Read Response给CPU-0这条数据的当前值。然后这条数据的状态变成了S(CPU-0现在也知道了这条数据)
于是CPU-0总能读到一条数据的最新值。
这就是MESI协议在读上的运用啦
再来看看写
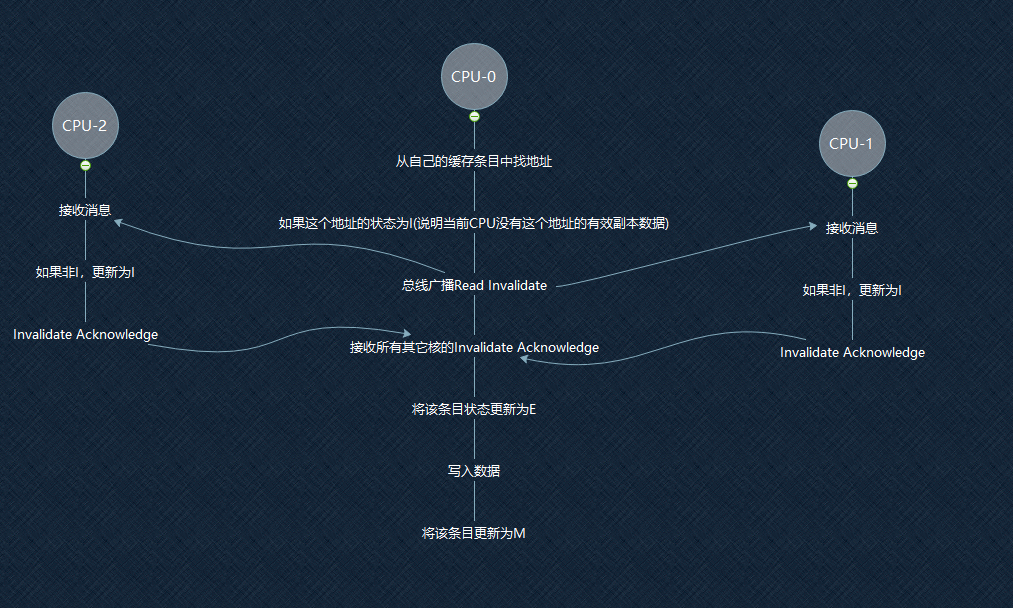
来,一步步走。
还是从CPU-0开始。
CPU-0再次没有从自己独占的高速缓存中找到这条地址(或者发现这条地址是I)
于是在总线广播Read Invalidate,要求接到这条消息的CPU,立马把这条地址的数据给我,并且你们的这条数据要置为I(要失效)
CPU-0的意思很明确啦,我就是要让其它CPU的这条数据都失效掉,我要独占这条数据~!
其它CPU接收到Invalidate Acknowledge消息后,也很听话的失效掉了自己的这条记录,然后返回Invalidate Acknowledge给CPU-0
发出投名状 "我们都很听话的失效掉了自己的这条记录啦"
CPU-0收到所有CPU的返回后,异常满意。
于是将这条数据的状态变成E(独占成功)
变成了自己的独占数据后,自然可以为所欲为的写数据了~
到了这里,有的读者可能发出了智慧的声音,“有没有可能多个CPU想同时独占某条数据呢?"
有可能。当然了,也是有解决方案的,总线仲裁(bus arbitration)。就不细讲了。
写缓冲器
其实这里还有一个问题
CPU-0广播出Read Invalidate后,一定要等待其它CPU返回Invalidate Acknowledge,才能去写这条数据吗?
并不是
CPU-0会直接将要写入的相关数据存入写缓冲器,并发送Read Invalidate消息。不进行等待,直接执行其它命令,不傻等,以此提高自身效率。
等其它CPU的回复都到达后,CPU-0才会将这个写缓冲器中的写操作真正写入到自己的高速缓存行中。
存储转发
因为引入了写缓冲器,那么CPU对某个数据的改变结果有可能还在自己的写缓冲器中,这个数据的内存地址对应的缓存行是老值,
所以执行读操作的时候,会现在自己的写缓冲器读一下,如果里面存在对应条目,直接作为读结果返回。否则才去自己的高速缓存里读。
这种直接从写缓冲器读取数据的技术,叫做存储转发
内存重排序
写缓冲器和存储转发都有可能导致内存重排序
以一个例子解释一下
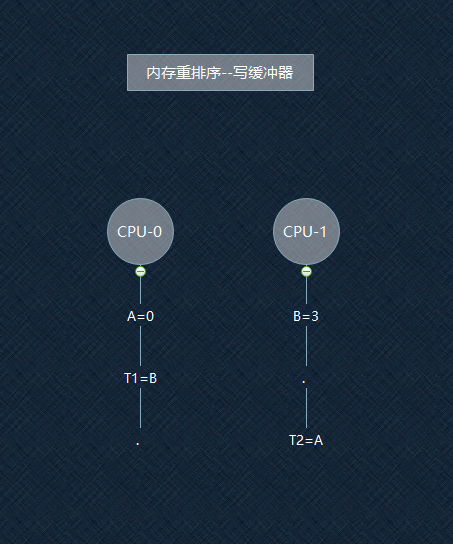
如图,假设A和B一开始都为0,T1和T2是两个变量。此执行顺序按时间从上至下。
按期望来说,最后结果应该是T1=3, T2=1
在T1时刻,CPU-0让A从0变为1,CPU-1将B从0变为3,但CPU-1的操作仅仅只是放入写缓冲器中
所以在T2时刻,CPU-0读到的B的值,可能还是0!
这就导致最后结果变成了, T1=0,T2=1
那么对CPU-0来讲,就好像B=3的操作是T2=A之后才进行的
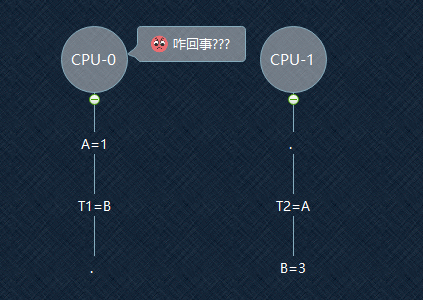
在CPU-0的视角中,CPU-1的写操作(B=3)被延迟到读操作(读A的值,T2=A)后的行为,叫做StoreLoad重排序(Stores Reordered After Loads)
同样,写存储器还会引起StoreStore重排序,再举一个例子
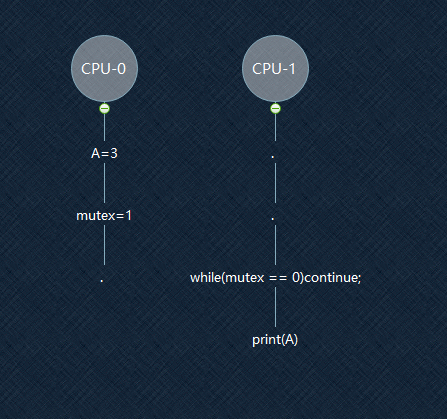
假设:A的值初始为0,mutex的值初始为0。一开始执行的时候,CPU-0的高速CACHE有mutex的副本,但没有A的副本。
所以执行A=3会进入写缓冲器中,而执行mutex=1会通过MESI协议同步给CPU-1
到了T3时刻,对于CPU-1来讲,mutex=1了,可以继续往下执行
T4时刻,对于CPU-1来讲,变量A仍然是0,因为对A的改变还在CPU-0的写缓冲器中
在CPU-1的视角中,CPU-0的写操作(A=3)被延迟到写操作(mutex=1)后的行为,叫做StoreStore重排序
解决重排序的方法--内存屏障
StoreLoad屏障--解决StoreLoad重排序
对于一个指令序列:
Store1; Store2; Store3; StoreLoadBarrier; Load1; Load2; Load3;
StoreLoadBarrier将禁止该屏障前后的重排序
也就是说,Load1,Load2,Load3,一定在Store1,Store2,Store3之后发生
但是Store1,Store2,Store3有可能发生重排序,也即是实际执行的指令序列有可能是这样的:
Store3; Store1; Store2; StoreLoadBarrier; Load1; Load2; Load3;
Load1,Load2,Load3之间也有可能发生重排序
实现方式为,将写缓冲器的条目刷进高速CACHE。所以之后的读,一定能读到最新值。
StoreStore屏障--解决StoreStore重排序
Store1; Store2; Store3; StoreStoreBarrier Store4; Store5; Store6;
Store1,Store2,Store3的任何操作,对于Store4,Store5,Store6都是可见的。同样,屏障前后的操作也有可能发生重排序
实现方式为,将写缓冲器的现有条目进行标记,表示这些条目的写操作需要先于该屏障之后的写操作被提交。
处理器在执行写操作的时候,如果发现写缓冲器中存在被标记的条目,那么即使这个写操作对应的高速缓存状态为E或M,处理器也不将其直接写入高速缓存,而是写入写缓冲器。在写缓冲器里是按顺序刷进高速缓存的。
volatile关键字的原理
终于到了volatile了。
先看看JSR-133(Java Specification Requests)中JMM(Java Memory Model)对volatile的定义
A write to a volatile field happens before every subsequent read of that volatile.
对volatile修饰的field的写,发生在任何读之前。
怎么做到的呢?其实就是在写volatile和读volatile中间,插入一个上文中提到的StoreLoad屏障
写volatile----->StoreLoadBarrier----->读volatile
StoreLoadBarrier的实现原理上文也提了---清空写缓冲器
这样就导致,任何一个CPU写了volatile后,都会将最新值放入高速CACHE中。
其它任何CPU,想要读这个volatile,必定能拿到最新值(还记得上面加粗的从高速CACHE中取值嘛?)
好了,这篇文章到这就结束了。
有一些地方没描述,或者是选择性地描述了---比如无效化队列,loadload重排序,再比如jvm在不同平台的不同表现。
还有一些地方解释的不清不楚的。
不过作为简单的描述型,总结型的文章,这样也够了。
最近在研究JSR-133,下一篇文章可能是这个方向的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号