Muduo库之CurrentThread、Types
CurrentThread
在 CurrentThread 命名空间中实现了有关线程 id 的管理和优化。其主要用于获取当前线程的 id,并将线程 id 保存为 C 语言风格的字符串:
extern __thread int t_cachedTid; // 线程id
extern __thread char t_tidString[32]; // 线程id的字符串形式
extern __thread int t_tidStringLength; // tidString的长度
extern __thread const char* t_threadName; // 线程名称
在如上代码中,我们可以看到,变量均使用 __thread 进行修饰,它是 GCC 内置的线程局部存储设施。由该关键字进行修饰的变量在每一个线程中都具有一份独立实体,各个线程的值互不干扰。它通常用来修饰那些带有全局性且值可能变,但是又不值得用全局变量保护的变量。
简单来说,就是用该修饰符修饰的变量在每个线程中都存在,但是各个线程之间又互不干扰。
这里使用 __thread 修饰符缓存了线程id、字符串用于日志中,避免可能每次输出 log 时都需要通过系统调用获取一次线程id,然后再转化为字符串的操作,从而提高了效率。
inline int tid() {
if (__builtin_expect(t_cachedTid == 0, 0)) { // t_cachedTid==0 大概率为假
cacheTid();
}
return t_cachedTid;
}
函数 tid() 的目的就是为了获取线程id,如果是第一次获取,则将其缓存到 t_cachedTid 变量中,后续获取则直接返回该缓存值。其中的 __builtin_except 关键字是 GCC 引入的,作用是向编译器提供分支预测信息,从而帮助编译器进行代码优化。即该关键字所表示的条件会满足的可能性较大,比不使用该关键字直接进行真假判断的效率要高。其格式为:
__builtin_except(EXP, N) // 表明 EXP == N 的概率很大
其中的 分支预测 是说高级编程语言在编译成汇编指令后,由于 CPU 进行流水线式的执行,汇编过程中将多个条件判断分支按需进行优化,最近的条件语句执行效率更高,其他的需要进行 jmp 跳转。由于此处的 t_cachedTid 变量只在初始化时为0,在第一次获取线程id后该变量便不再为0,因此使用分支预测来表明 t_cachedTid 大概率不为0,以提高效率。
代码中的 cacheTid() 则定义于 Thread.cc 文件中:
pid_t gettid() {
return static_cast<pid_t>(::syscall(SYS_gettid));
}
void CurrentThread::cacheTid() {
if (t_cachedTid == 0) {
t_cachedTid = detail::gettid();
t_tidStringLength = snprintf(t_tidString, sizeof(t_tidString), "%5d ", t_cachedTid);
}
}
其内部通过系统调用 SYS_gettid 来获取线程的tid,然后通过 snprintf() 将其格式化为 C 风格的字符串存储到 t_tidString 变量值以供使用。
在 Linux 下每个进程都有一个进程id,类型为 pid_t,通过函数 getpid() 获取。而 POSIX 线程也有线程id,类型为 pthread_t,通过函数 pthread_self() 获取,该id由线程库维护。
但是不同进程之间相互独立,因此在不同的线程中,可能存在线程id相同的情况,这就难以在不同进程的两个线程之间进行通信。为此,可以通过系统调用 syscall(SYS_gettid) 来获取真实的线程id唯一标识。
除此之外,不使用 pthread_t 的原因还有:
- 不同的平台之间其实现不同,难以跨平台;
- 难以比较大小,不能作为关联容器的 Key;
- 无法定义无效值来表示一个不存在的线程;
- 线程销毁后,很可能再次创建相同 id 的线程;
而使用 pid_t 的优点如下:
- 所占字节大小要小于 pthread_t;
- 任何时候全局唯一,且短时间内反复创建多个线程不会出现相同id;
- 0为非法值,init 进程的 id 是 1;
- 在主线程中,
getpid()和gettid()返回值相同,则可用于确认当前线程是否为主线程。
而在 isMainThread() 函数的实现中,便是使用了上述方法,其实现在 Thread.cc 文件中:
bool CurrentThread::isMainThread() {
return tid() == ::getpid();
}
Types
在 Types.h 中定义了一个内存清零的函数 memZero(),其内部调用的是 memset() 函数:
inline void memZero(void* p, size_t n) {
memset(p, 0, n);
}
除此之外,还包括两个转换函数:implicit_cast<T> 和 down_cast<T>。
其中,implicit_cast<T> 是 static_cast<T> 和 const_cast<T> 的安全版本,用于在类型层次结构中向上转换,即将指向子类的指针转换为指向父类的指针,或者将指向对象的非常量指针转换为常量指针。而 static_cast<T> 则是同时支持向上转型和向下转型。
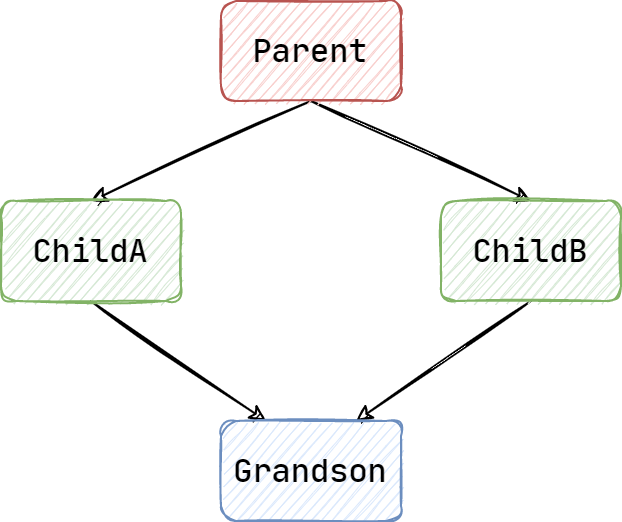
考虑如下继承关系:
class Parent {};
class ChildA : public Parent {};
class ChildB : public Parent {};
class Grandson : public ChildA, ChildB {};
然后:
void func(ChildA& obj);
void func(ChildB& obj);
void test(Grandson& arg) {
func(arg);
}
int main() {
Grandson son;
test(son);
return 0;
}
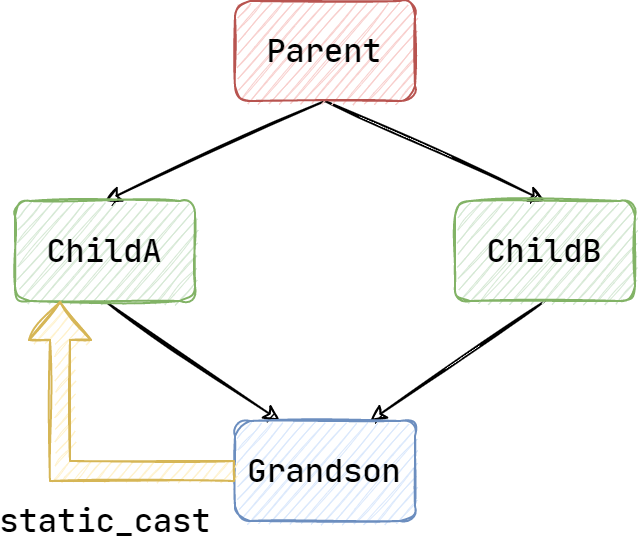
由于函数 func() 的重载解析出现歧义,所以编译不会通过,这时候我们使用 static_cast 指定要使用的重载函数:
void test(Grandson& arg) {
func(static_cast<ChildA&>(arg));
}
这个时候编译通过,参数 arg 被 static_cast 向上转型为 ChildA 类型。
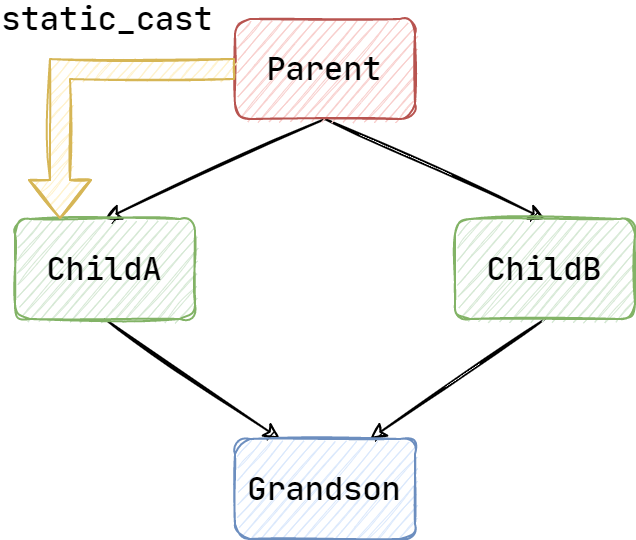
在过了一段时间之后,我将代码修改为如下样式:
void test(Parent& arg) {
func(static_cast<ChildA&>(arg));
}
int main() {
Parent pa;
test(pa);
return 0;
}
此时的代码编译可以通过,参数 arg 被 static_cast 向下转型为 ChildA 类型。
但是代码运行时就会出现问题(在函数中访问了对象并不存在的子类成员变量),为此为了摒弃 static_cast 这种强大的向上向下转型均可的机制,特地设计出 implicit_cast 以应对那些只需向上转型的场合。
同理,down_cast 则只适用于向下转型的时机。而且在代码中,如果是 Debug 模式下,则使用 dynamic_cast 来仔细检查向下转型是否合法,如果是非 Debug 模式,则使用高效的 static_cast。其中的:
if (false) {
implicit_cast<From*, To>(0);
}
仅仅只是在编译期进行类型检查,判断 To 是否是 Form* 的子类型,是否满足向下转型条件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号