
javascript数据结构与算法--链表
2015-03-14 11:57 龙恩0707 阅读(2231) 评论(4) 收藏 举报链表与数组的区别?
1. 定义:
数组又叫做顺序表,顺序表是在内存中开辟一段连续的空间来存储数据,数组可以处理一组数据类型相同的数据,但不允许动态定义数组的大小,即在使用数组之前必须确定数组的大小。而在实际应用中,用户使用数组之前有时无法准确确定数组的大小,只能将数组定义成足够大小,这样数组中有些空间可能不被使用,从而造成内存空间的浪费。
链表是一种常见的数据组织形式,它采用动态分配内存的形式实现。链表是靠指针来连接多块不连续的的空间,在逻辑上形成一片连续的空间来存储数据。需要时可以用new分配内存空间,不需要时用delete将已分配的空间释放,不会造成内存空间的浪费。
2. 二者区分;
A 从逻辑结构来看
- 数组必须事先定义固定的长度,不能适应数据动态地增减情况。当数据增加时,可能超出数组原先定义的数组的长度;当数据减少时,浪费内存。
- 链表可以动态地进行存储分配;可以适应数据动态增减情况;
B 从内存存储来看
- 数组是从栈中分配空间,对于程序员方便快速,自由度小。
- 链表是从堆中分配空间,自由度大但是申请管理比较麻烦。
C 从访问顺序来看
数组中的数据是按顺序来存储的,而链表是随机存储的。
- 要访问数组的元素需要按照索引来访问,速度比较快,如果对他进行插入删除操作的话,就得移动很多元素,所以对数组进行插入操作效率低。
- 由于链表是随机存储的,链表在插入,删除操作上有很高的效率(相对数组),如果要访问链表中的某个元素的话,那就得从链表的头逐个遍历,直到找到所需要的元素为止,所以链表的随机访问的效率比数组要低。
注意: 以上的区分在其他的编程语言 “数组和链表”的区别或许确实是这样的,但是在javascript的数组中并不存在上面的问题,因为 javascript有push,pop,shift,unshift,split等方法,所以不需要再访问数组中其他的元素了。
Javascript中数组的主要问题是:它们被实现成了对象,与其他语言(比如c++和java)的数组相比,效率很低。如果发现使用数组很慢的话,可以使用链表来替代它。至于在javascript中,一般情况下还是使用数组比较方便,我个人建议使用数组,但是现在我们还是要介绍下链表的基本概念,至少我们有一个理念,什么是链表,这个我们应该要知道的。所以下面我们来慢慢来分析链表的基本原理了。
一:定义链表
链表是由一组节点组成的集合。每个节点都使用一个对象的引用指向它的后继。指向另一个节点的引用叫做链。如下图一:

数组元素靠他们位置的索引进行引用,而链表元素则是靠相互之间的关系进行引用。如上图一:我们说B跟在A的后面,而不是和数组一样说B是链表中的第二个元素。遍历链表,就是跟着链接,从链表的首元素一直遍历到尾元素(不包含链表的头节点,头节点一般用来作为链表的接入点)。而链表的尾元素指向null 如上图1.
二:单向链表插入新节点和删除一个节点的原理;
1. 单向链表插入新节点,如上图2所示;链表中插入一个节点效率很高。向链表中插入一个节点,需要修改它前面的节点(前驱),使其指向新加入的节点,而新加入的节点则指向原来前驱指向的节点。
2. 单向链表删除一个节点;如上图3所示;从链表中删除一个元素也很简单,将待删除元素的前驱节点指向待删除元素的后继节点,同时将待删除元素指向null,元素就删除成功了。
三:设计一个基于对象的链表。
1 先设计一个创建节点Node类;如下:
function Node(element) { this.element = element; this.next = null; }
Node类包含2个属性,element用来保存节点上的数据,next用来保存指向下一个节点的链接(指针)。
2. 再设计一个对链表进行操作的方法,包括插入删除节点,在列表中查找给定的值等。
function LinkTable () { this.head = new Node(“head”); }
上面的链表类只有一个属性,那就是使用一个Node对象来保存该链表的头节点。
一:插入新节点insert方法步骤如下;
- 需要明确知道新节点要在那个节点前面或者后面插入。
- 在一个已知节点后面插入元素时,先要找到后面的节点。
因此在创建新节点之前,先要创建查找节点的方法 find,如下:
function find(item){ var curNode = this.head; while(curNode.element != item) { curNode = curNode.next; } return curNode; }
如上代码的意思:首先创建一个新节点,并将链表的头节点赋给这个新创建的节点curNode,然后再链表上进行循环,如果当前节点的element属性和我们要找的信息不符合,就从当前的节点移动到下一个节点,如果查找成功,该方法返回包含该数据的节点,否则的话 返回null。
一旦找到 “后面”的节点了,就可以将新节点插入到链表中了。首先将新节点的next属性设置为 “后面”节点的next属性对应的值。然后设置 “后面”节点的next属性指向新节点。Insert方法定义如下:
function insert(newElement,item) { var newNode = new Node(newElement); var current = this.find(item); newNode.next = current.next; newNode.previous = current; current.next = newNode; }
二:定义一个显示链表中的元素。
function display (){ var curNode = this.head; while(!(curNode.next == null)) { console.log(curNode.next.element); curNode = curNode.next; } }
该方法先将列表的头节点赋给一个变量curNode,然后循环遍历列表,如果当前节点的next属性为null时,则循环结束。
下面是添加节点的所有JS代码;如下:
function Node(element) { this.element = element; this.next = null; } function LinkTable() { this.head = new Node("head"); } LinkTable.prototype = { find: function(item){ var curNode = this.head; while(curNode.element != item) { curNode = curNode.next; } return curNode; }, insert: function(newElement,item) { var newNode = new Node(newElement); var current = this.find(item); newNode.next = current.next; current.next = newNode; }, display: function(){ var curNode = this.head; while(!(curNode.next == null)) { console.log(curNode.next.element); curNode = curNode.next; } } }
我们可以先来测试如上面的代码;
如下初始化;
var test = new LinkTable();
test.insert("a","head");
test.insert("b","a");
test.insert("c","b");
test.display();
1 执行test.insert("a","head"); 意思是说把a节点插入到头节点 head的后面去,执行到上面的insert方法内中的代码 var current = this.find(item); item就是头节点head传进来的;那么变量current值是 截图如下:

继续走到下面 newNode.next = current.next; 给新节点newNode的next属性指向null,继续走,current.next = newNode; 设置后面的节点next属性指向新节点a;如下:
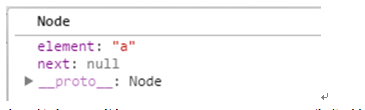
2. 同上面原理一样,test.insert("b","a"); 我们接着走 var current = this.find(item);
那么现在的变量current值是如下:
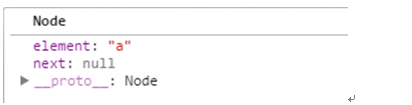
继续走 newNode.next = current.next; 给新节点newNode的next属性指向null,继续走,current.next = newNode; 设置后面的节点next属性指向新节点b;如下:

test.insert("c","b"); 在插入一个c 原理也和上面执行一样,所以不再一步一步讲了,所以最后执行 test.display();方法后,将会打印出a,b,c
三:从链表中删除一个节点;
原理是:从链表中删除节点时,需要先找到待删除节点前面的节点。找到这个节点后,修改它的next属性使其不再指向待删除的节点,而是指向待删除节点的下一个节点。如上面的图三所示:
现在我们可以定义一个方法 findPrevious()。该方法遍历链表中的元素,检查每一个节点的下一个节点中是否存储着待删除数据,如果找到的话,返回该节点,这样就可以修改它的next属性了。如下代码:
function findPrevious (item) { var curNode = this.head; while(!(curNode.next == null) && (curNode.next.element != item)) { curNode = curNode.next; } return curNode; }
现在我们可以编写singleRemove方法了,如下代码:
function singleRemove(item) { var prevNode = this.findPrevious(item); if(!(prevNode.next == null)) { prevNode.next = prevNode.next.next; } }
下面所有的JS代码如下:
function Node(element) { this.element = element; this.next = null; } function LinkTable() { this.head = new Node("head"); } LinkTable.prototype = { find: function(item){ var curNode = this.head; while(curNode.element != item) { curNode = curNode.next; } return curNode; }, insert: function(newElement,item) { var newNode = new Node(newElement); var current = this.find(item); newNode.next = current.next; current.next = newNode; }, display: function(){ var curNode = this.head; while(!(curNode.next == null)) { console.log(curNode.next.element); curNode = curNode.next; } }, findPrevious: function(item) { var curNode = this.head; while(!(curNode.next == null) && (curNode.next.element != item)) { curNode = curNode.next; } return curNode; }, singleRemove: function(item) { var prevNode = this.findPrevious(item); if(!(prevNode.next == null)) { prevNode.next = prevNode.next.next; } } }
下面我们再来测试下代码,如下测试;
var test = new LinkTable(); test.insert("a","head"); test.insert("b","a"); test.insert("c","b"); test.display(); test.singleRemove("a"); test.display();
当执行 test.singleRemove("a"); 删除链表a时,执行到singleRemove方法内的var prevNode = this.findPrevious(item); 先找到前面的节点head,如下:

然后在singleRemove方法内判断上一个节点head是否有下一个节点,如上所示,很明显有下一个节点,那么就把当前节点的下一个节点 指向 当前的下一个下一个节点,那么当前的下一个节点就被删除了,如下所示:

二:双向链表
双向链表图,如下图一所示:

前面我们介绍了是单向链表,在Node类里面定义了2个属性,一个是element是保存新节点的数据,还有一个是next属性,该属性指向后驱节点的链接,那么现在我们需要反过来,所以我们需要一个指向前驱节点的链接,我们现在把他叫做previous。Node类代码现在改成如下:
function Node(element) { this.element = element; this.next = null; this.previous = null; }
1. 那么双向链表中的insert()方法和单向链表的方法类似,但是需要设置新节点previous属性,使其指向该节点的前驱。代码如下:
function insert(newElement,item) { var newNode = new Node(newElement); var current = this.find(item); newNode.next = current.next; newNode.previous = current; current.next = newNode; }
2. 双向链表的doubleRemove() 删除节点方法比单向链表的效率更高,因为不需要再查找前驱节点了。那么双向链表的删除原理如下:
1. 首先需要在链表中找出存储待删除数据的节点,然后设置该节点前驱的next属性,使其指向待删除节点的后继。
2. 设置该节点后继的previous属性,使其指向待删除节点的前驱。
如上图2所示;首先在链表中找到删除节点C,然后设置该C节点前驱的B的next属性,那么B指向尾节点Null了;设置该C节点后继的(也就是尾部节点Null)的previous属性,使尾部Null节点指向待删除C节点的前驱,也就是指向B节点,即可把C节点删除掉。
代码可以如下:
function doubleRemove(item) { var curNode = this.find(item); if(!(curNode.next == null)) { curNode.previous.next = curNode.next; curNode.next.previous = curNode.previous; curNode.next = null; curNode.previous = null; } }
比如测试代码如下:
var test = new LinkTable(); test.insert("a","head"); test.insert("b","a"); test.insert("c","b"); test.display(); // 打印出a,b,c console.log("------------------"); test.doubleRemove("b"); // 删除b节点 test.display(); // 打印出a,c console.log("------------------");
进入doubleRemove方法,先找到待删除的节点,如下:

然后设置该节点前驱的next属性 ,使其指向待删除节点的后继,如上代码
curNode.previous.next = curNode.next;
该节点的后继的previous属性,使其指向待删除节点的前驱。如上代码
curNode.next.previous = curNode.previous;
再设置 curNode.next = null; 再查看curNode值如下图所示:
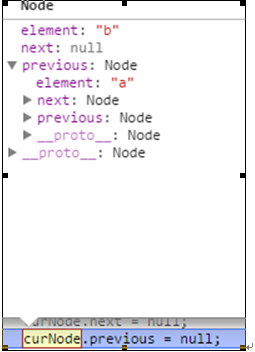
下一个节点为null,同理当设置完 curNode.previous = null 的时候,会打印出如下:

我们可以再看看如上图2 删除节点的图 就可以看到,C节点与它的前驱节点B,与它的尾节点都断开了。即都指向null。
注意:双向链表中删除节点貌似不能删除最后一个节点,比如上面的C节点,为什么呢?因为当执行到如下代码时,就不执行了,如下图所示;

上面的是删除节点的分析,现在我们再来分析下 双向链表中的 添加节点的方法insert(); 我们再来看下;
当执行到代码 test.insert("a","head"); 把a节点插入到头部节点后面去,我们来看看insert方法内的这一句代码;
newNode.previous = current; 如下所示;

当执行到如下这句代码时候;
current.next = newNode;
如下所示;

同理插入b节点,c节点也类似的原理。
双向链表反序操作;现在我们也可以对双向链表进行反序操作,现在需要给双向链表增加一个方法,用来查找最后的节点。如下代码;
function findLast(){ var curNode = this.head; while(!(curNode.next == null)) { curNode = curNode.next; } return curNode; }
如上findLast()方法就可以找到最后一个链表中最后一个元素了。现在我们可以写一个反序操作的方法了,如下:
function dispReverse(){ var curNode = this.head; curNode = this.findLast(); while(!(curNode.previous == null)) { console.log(curNode.element); curNode = curNode.previous; } }
如上代码先找到最后一个元素,比如C,然后判断当前节点的previous属性是否为空,截图如下;

可以看到当前节点的previous不为null,那么执行到console.log(curNode.element); 先打印出c,然后把当前的curNode.previous 指向与curNode了(也就是现在的curNode是b节点),如下所示;

同理可知;所以分别打印出c,b,a了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号