
渐进式web应用开发---service worker (二)
2019-07-08 00:32 龙恩0707 阅读(1804) 评论(1) 收藏 举报阅读目录
- 1. 创建第一个service worker 及环境搭建
- 2. 使用service worker 对请求拦截
- 3. 从web获取内容
- 4. 捕获离线请求
- 5. 创建html响应
- 6. 理解 CacheStorage缓存
- 7. 理解service worker生命周期
- 8. 理解 service worker 注册过程
- 9. 理解更新service worker
- 10. 理解缓存管理和清除缓存
- 11. 理解重用已缓存的响应
1. 创建第一个service worker 及环境搭建
在上一篇文章,我们已经讲解了 service worker 的基本原理,请看上一篇文章 . 从这篇文章开始我们来学习下 service worker的基本知识。
在讲解之前,我们先来搭建一个简单的项目,和之前一样,首先我们来看下我们整个项目目录结构,如下所示:
|----- 项目 | |--- public | | |--- js # 存放所有的js | | | |--- main.js # js入口文件 | | |--- style # 存放所有的css | | | |--- main.styl # css 入口文件 | | |--- index.html # index.html 页面 | | |--- images | |--- package.json | |--- webpack.config.js | |--- node_modules
如上目录结构就是我们项目的最简单的目录结构。我们先来看下我们各个目录的文件代码。
index.html 代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>service worker 实列</title> </head> <body> <div id="app">22222</div> </body> </html>
其他的文件代码目前可以忽略不计,基本上没有什么代码。因此我们在项目的根目录下 运行 npm run dev 后,就会启动我们的页面。如下运行的页面。如下所示:

如上就是我们的页面简单的整个项目的目录架构了,现在我们来创建我们的第一个 service worker了。
一:创建我们的第一个service worker
首先从当前页面注册一个新的service worker, 因此在我们的 public/js/main.js 添加如下代码:
// 加载css样式 require('../styles/main.styl'); console.log(navigator); if ("serviceWorker" in navigator) { navigator.serviceWorker.register('/sw.js') .then(function(registration){ console.log("Service Worker registered with scope: ", registration.scope); }).catch(function(err) { console.log("Service Worker registered failed:", err); }); }
如上代码,首先在我们的chrome下打印 console.log(navigator); 看到如下信息:
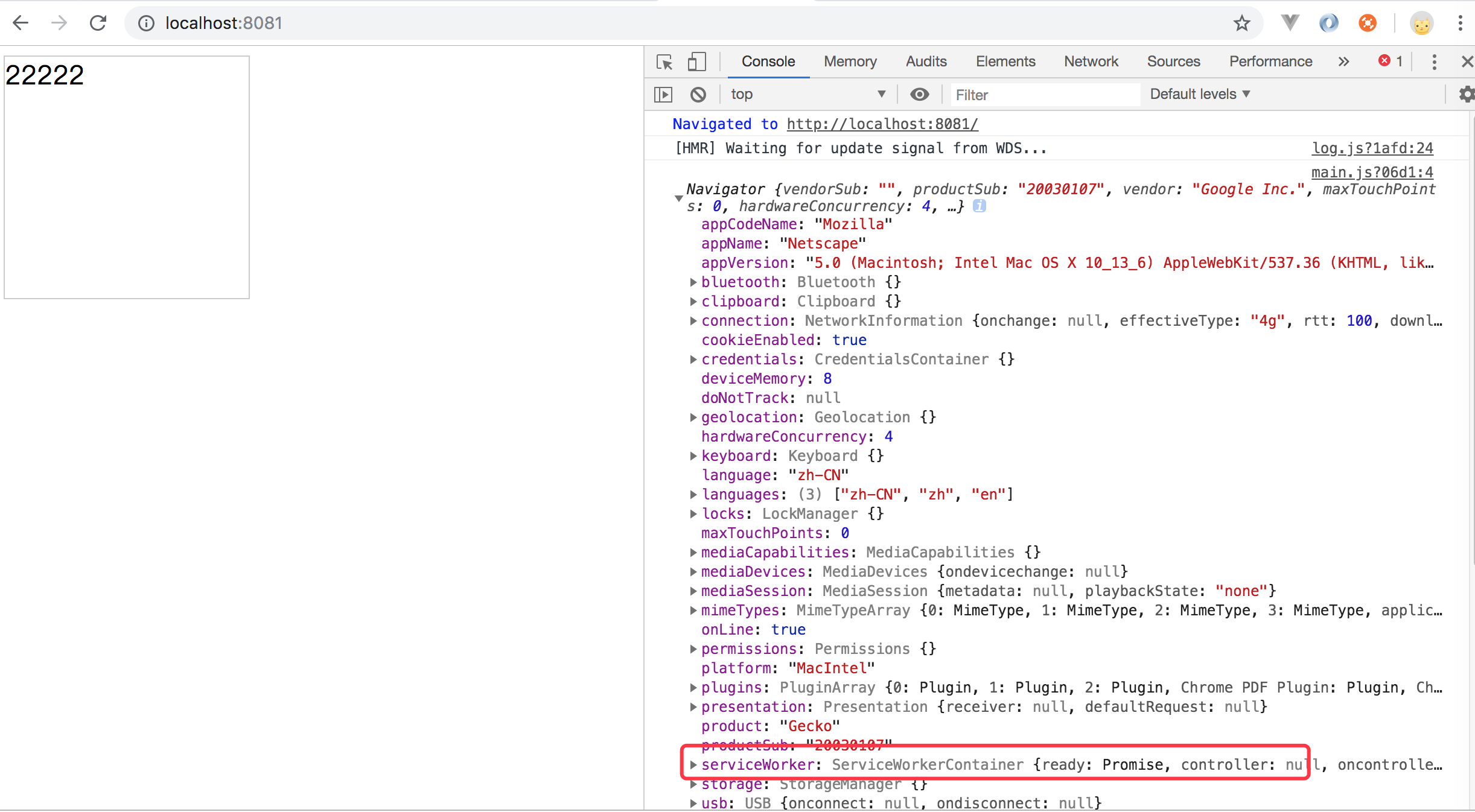
切记:要想支持service worker 的话,在本地必须以 http://localhost:8081/ 或 http://127.0.0.1:8081 来访问页面,在线上必须以https来访问页面,否则的话,浏览器是不支持的,因为http访问会涉及到service worker安全性问题。 比如我在本地启动的是以 http://0.0.0.0:8081/ 这样来访问页面的话,浏览器是不支持 service worker的。如下所示: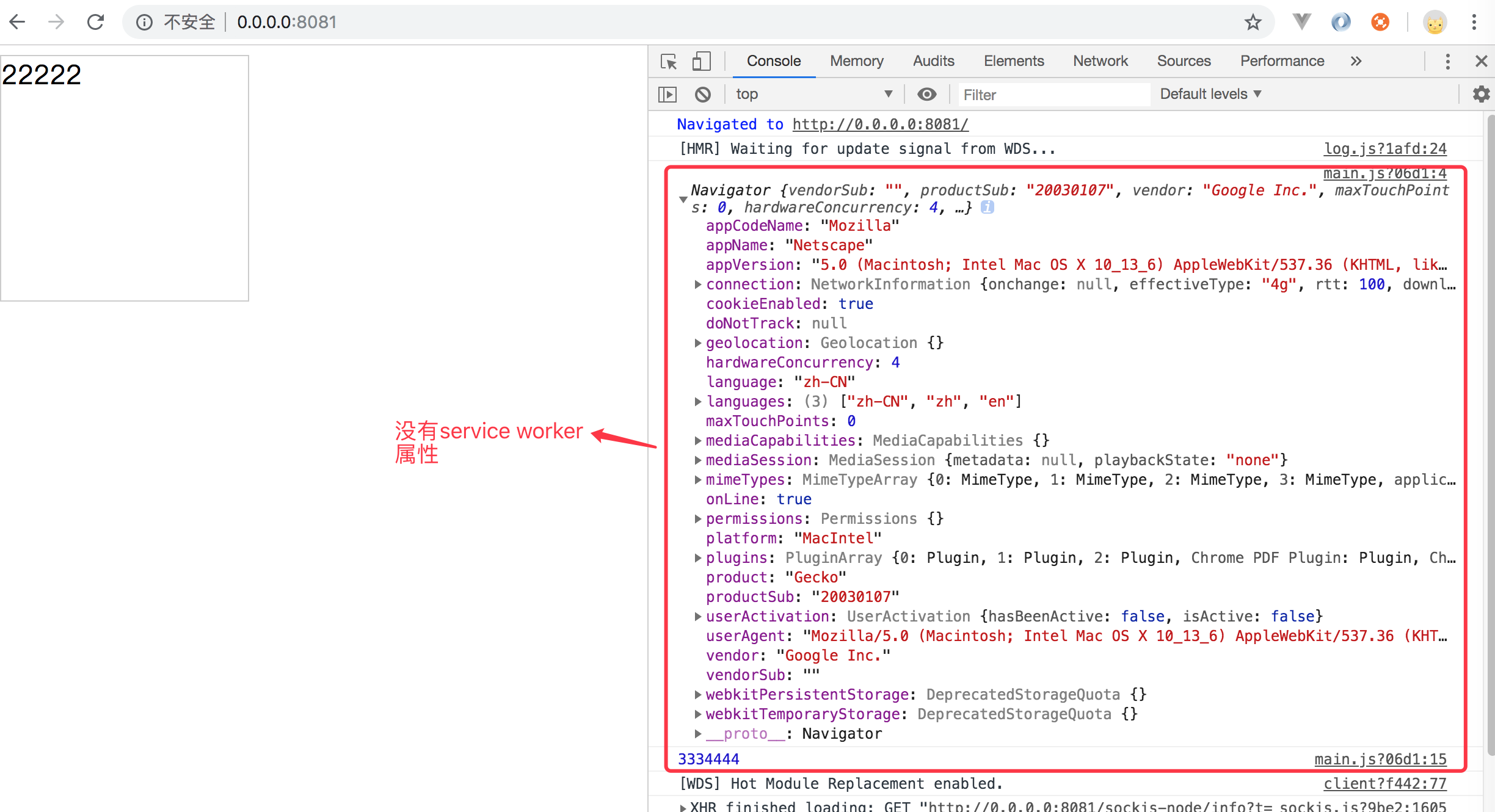
如上代码,使用了if语句判断了浏览器是否支持 service worker, 如果支持的话,我们会使用 navigator.serviceWorker.register 方法注册了我们的 service worker,该方法接收2个参数,第一个参数是我们的脚本的URL,第二个参数是作用域(晚点会讲到)。
如上register方法会返回一个promise对象,如果promise成功,说明注册service worker 成功,就会执行我们的then函数代码,否则的话就会执行我们的catch内部代码。
如上代码我们的 navigator.serviceWorker.register('/sw.js'), 注册了一个 sw.js,因此我们需要在我们的 项目的根目录下新建一个 sw.js 。目前它没有该目录文件,然后我们继续刷新页面,可以看到它进入了catch语句代码;如下所示:

现在我们需要在 我们的项目根目录下新建 sw.js.
注意:我们的sw.js文件路径放到了项目的根目录下,这就意味着 serviceworker 和网站是同源的,因此在 项目的根目录下的所有请求都可以代理的。如果我们把 sw.js 放入到我们的 public 目录下的话,那么就意味这我们只能代理public下的网络请求了。但是我们可以在注册service worker的时候传入一个scope选项,用来覆盖默认的service worker的作用域。比如如下:
navigator.serviceWorker.register('/sw.js');
navigator.serviceWorker.register('/sw.js', {scope: '/'});
如上两条命令是完全相同的作用域了。
下面我们的两条命令将注册两个不同的作用域,因为他们是放在两个不同的目录下。如下代码:
navigator.serviceWorker.register('/sw.js', {scope: '/xxx'});
navigator.serviceWorker.register('/sw22.js', {scope: '/yyy'});
现在在我们的项目根目录下有sw.js 这个文件,因此这个时候我们再刷新下我们的页面,就可以看到打印出消息出来了 Service Worker registered with scope: http://localhost:8081/ ,说明注册成功了。如下所示:
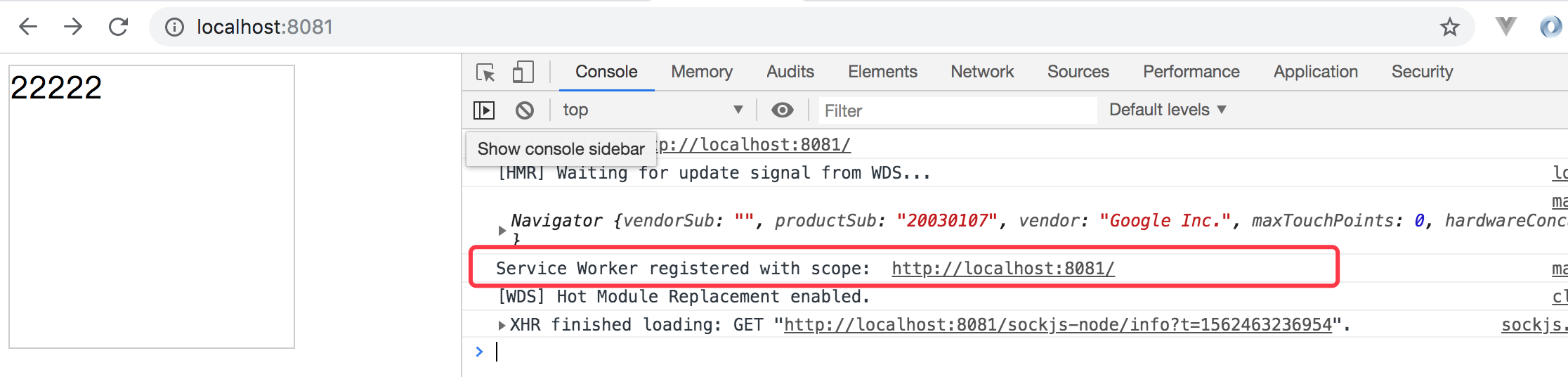
下面我们继续在我们的 项目的根目录 sw.js 添加代码如下:
console.log(self); self.addEventListener("fetch", function(e) { console.log("Fetch request for: ", e.request.url); });
如上代码,我们首先可以打印下self是什么,在service worker中,self它是指向service worker本身的。我们首先在控制台中看看self到底是什么,我们可以先打印出来看看,如下所示: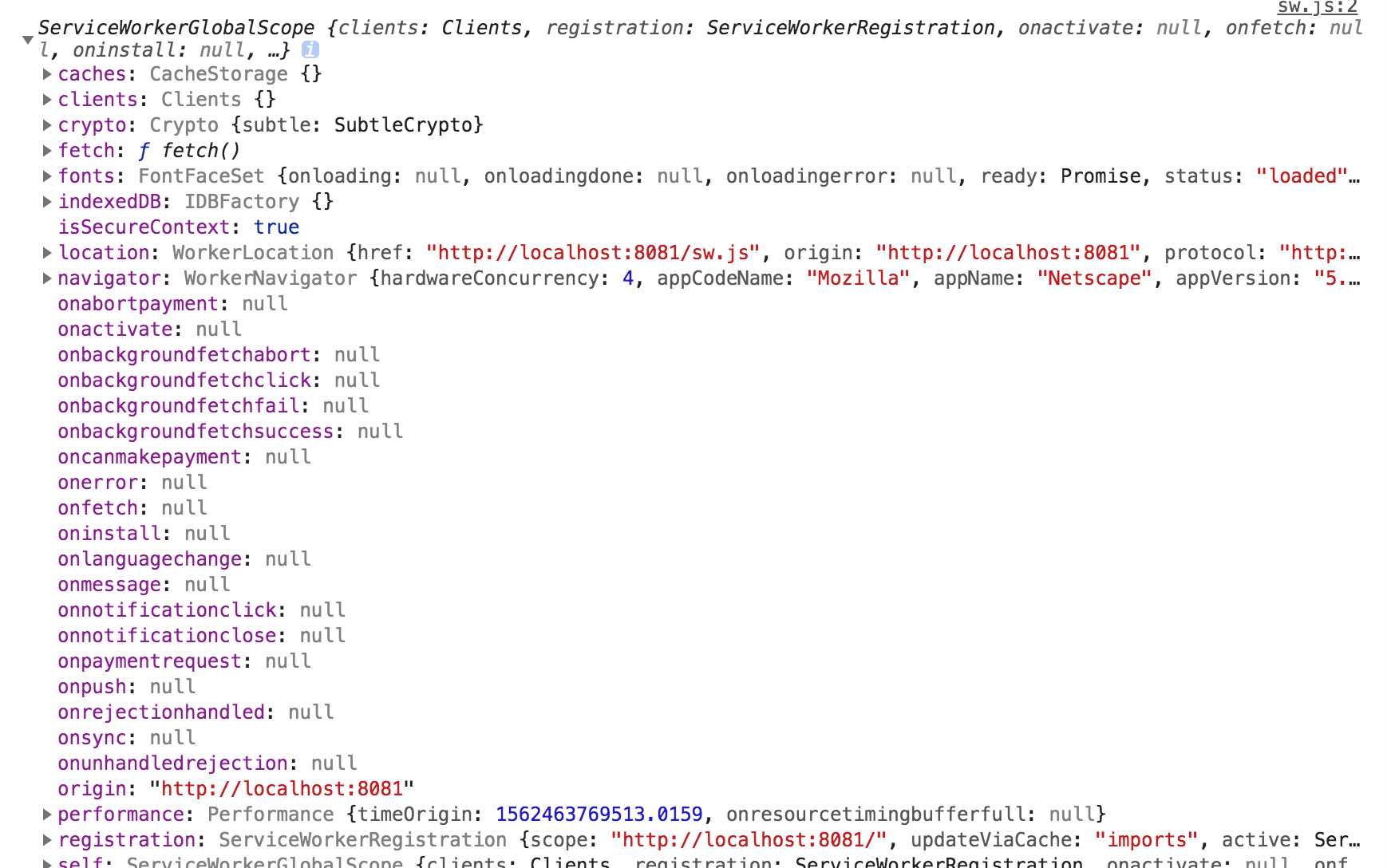
如上代码,我们的service worker添加了一个事件监听器,这个监听器会监听所有经过service worker的fetch事件,并允许我们的回调函数,我们修改sw.js后,我们并没有看到控制台打印我们的消息,因此我们先来简单的学习下我们的service worker的生命周期。
当我们修改sw.js 代码后,这些修改并没有在刷新浏览器之后立即生效,这是因为原先的service worker依然处于激活状态,但是我们新注册的 service worker 仍然处于等待状态,如果这个时候我们把原先第一个service worker停止掉就可以了,为什么有这么多service worker,那是因为我刷新下页面,浏览器会重新执行我们的main.js 代码中注册 sw.js 代码,因此会有很多service worker,现在我们要怎么做呢?我们打开我们的chrome控制台,切换到 Application 选项,然后禁用掉我们的第一个正处于激活状态下的service worker 即可,如下图所示: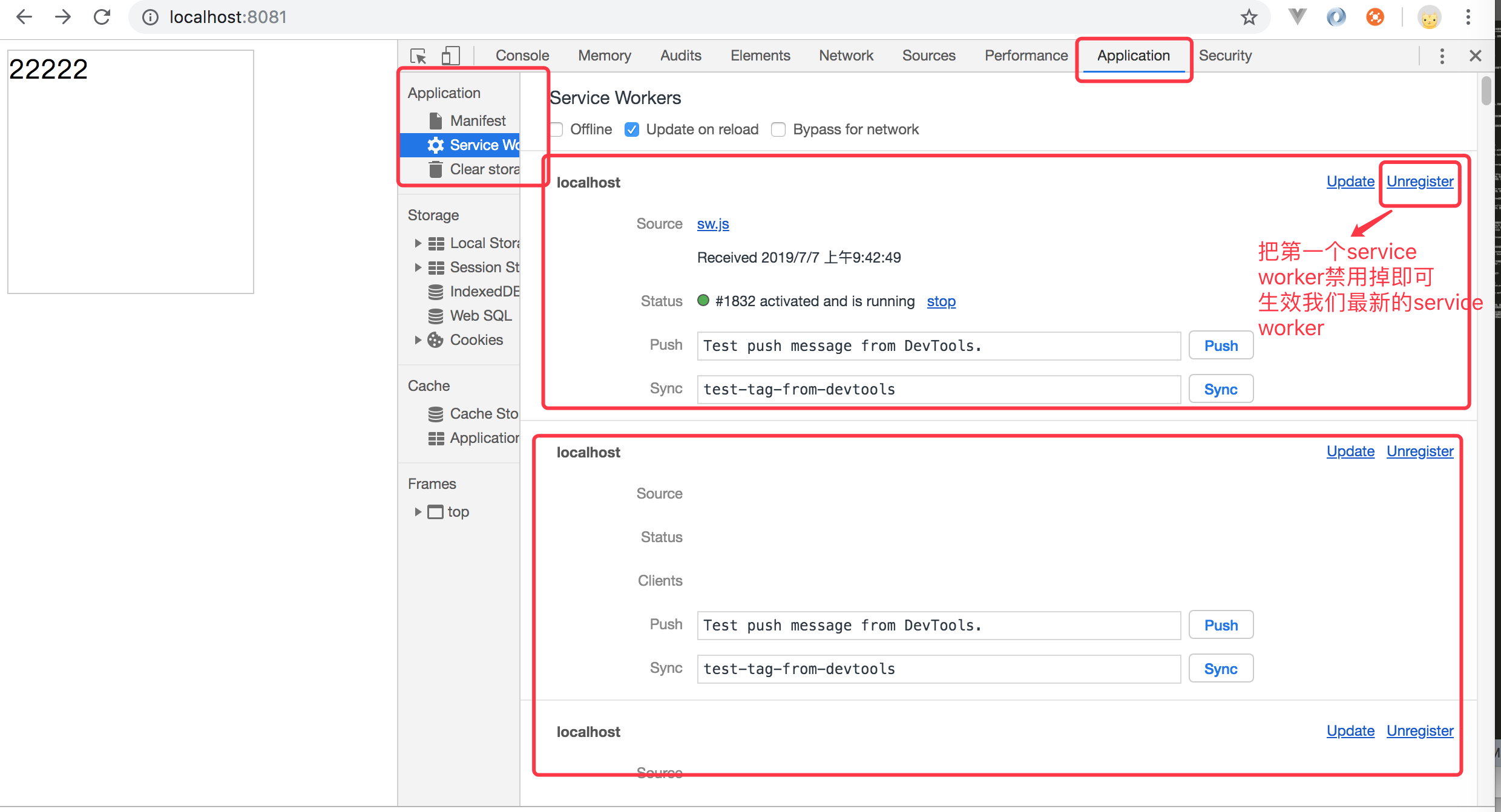
禁用完成后,我们再刷新下页面即可看到我们console.log(self);会打印出来了,说明已经生效了。
但是我们现在是否注意到,我们的监听fetch事件,第一次刷新的时候没有打印出 console.log("Fetch request for: ", e.request.url); 这个信息,这是因为service worker第一次是注册,注册完成后,我们才可以监听该事件,因此当我们第二次以后刷新的时候,我们就可以使用fetch事件监听到我们页面上所有的请求了,我们可以继续第二次刷新后,在控制台我们可以看到如下信息,如下图所示: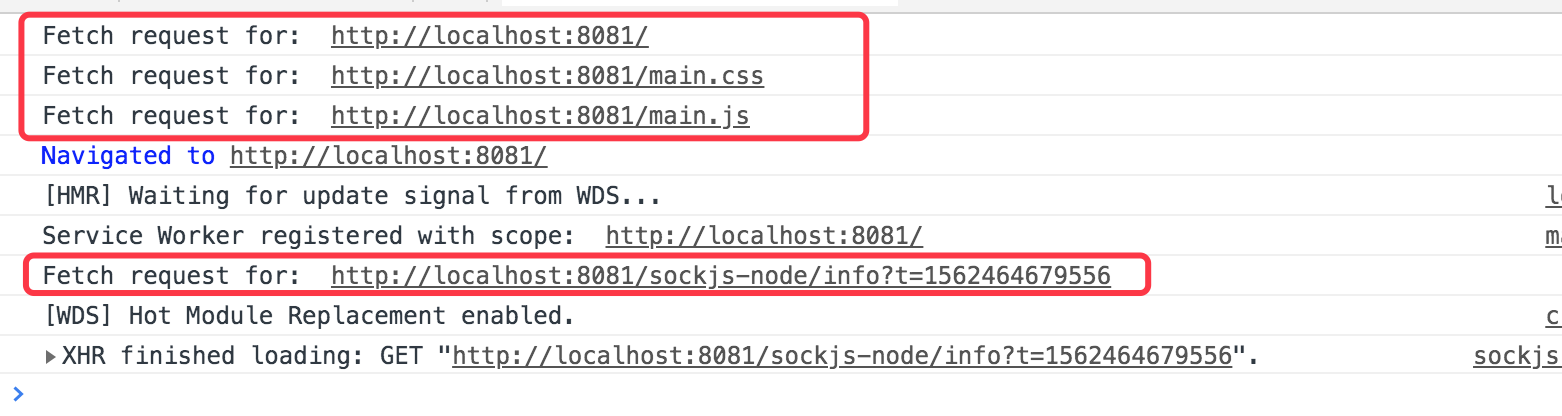
下面为了使我们更能理解我们的整个目录架构,我们再来看下我们整个目录结构变成如下样子:
|----- 项目 | |--- public | | |--- js # 存放所有的js | | | |--- main.js # js入口文件 | | |--- style # 存放所有的css | | | |--- main.styl # css 入口文件 | | |--- index.html # index.html 页面 | | |--- images | |--- package.json | |--- webpack.config.js | |--- node_modules | |--- sw.js
2. 使用service worker 对请求拦截
我们第二次以后刷新的时候,我们可以监听到我们页面上所有的请求,那是不是也意味着我们可以对这些请求进行拦截,并且修改代码,然后返回呢?当然可以的,因此我们把sw.js 代码改成如下这个样子:代码如下所示:
self.addEventListener("fetch", function(e) {
if (e.request.url.includes("main.css")) {
e.respondWith(
new Response(
"#app {color:red;}",
{headers: { "Content-Type": "text/css" }}
)
)
}
});
如上代码,我们监听fetch事件,并检查每个请求的URL是否包含我们的 main.css 字符串,如果包含的话,service worker 会动态的创建一个Response对象,在响应中包含了自定义的css,并使用这个对象作为我们的响应,而不会向远程服务器请求这个文件。效果如下所示:
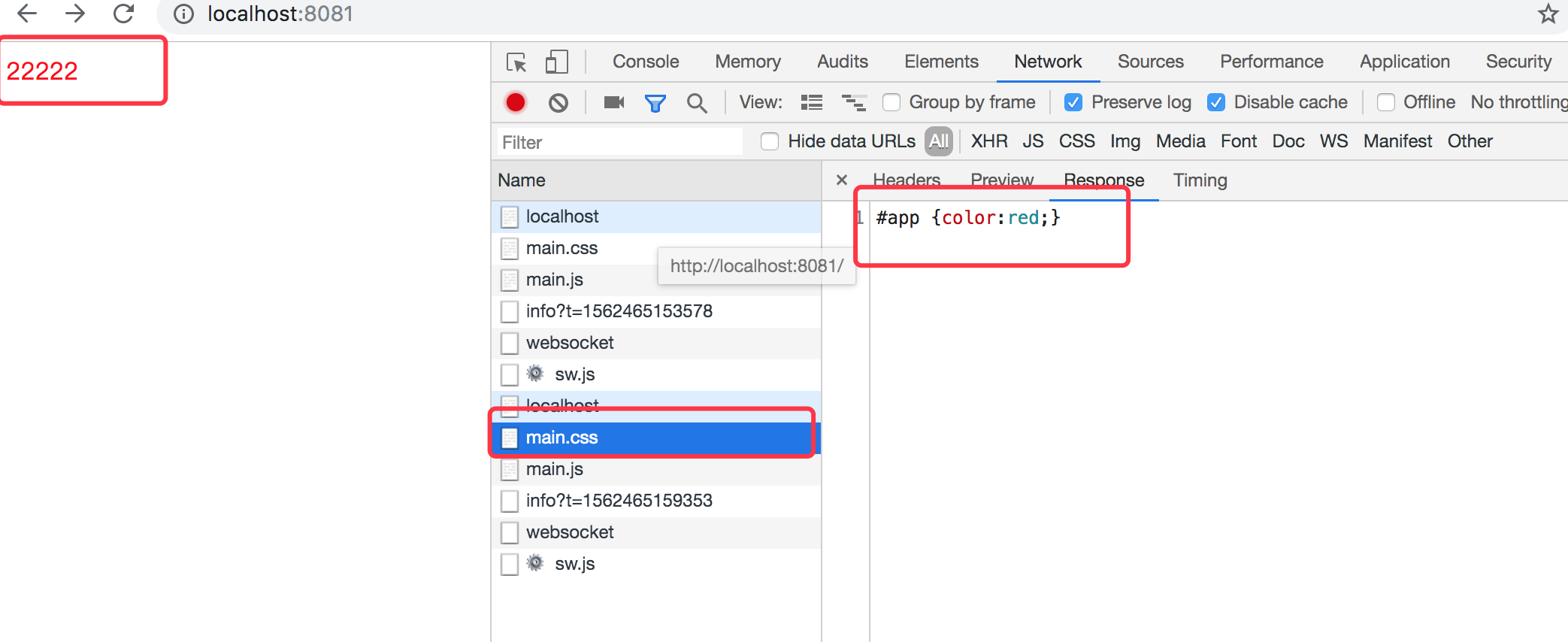
3. 从web获取内容
在第二点中,我们拦截main.css ,我们通过指定内容和头部,从零开始创建了一个新的响应对象,并使用它作为响应内容。但是service worker 更广泛的用途是响应来源于网络请求。我们也可以监听图片。
我们在我们的index.html页面中添加一张图片的代码;如下所示:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>service worker 实列</title> </head> <body> <div id="app">22222</div> <img src="/public/images/xxx.jpg" /> </body> </html>
然后我们在页面上浏览下,效果如下:

现在我们通过service worker来监听该图片的请求,然后替换成另外一张图片,sw.js 代码如下所示:
self.addEventListener("fetch", function(e) {
if (e.request.url.includes("/public/images/xxx.jpg")) {
e.respondWith(
fetch("/public/images/yyy.png")
);
}
});
然后我们继续刷新下页面,把之前的service worker禁用掉,继续刷新页面,我们就可以看到如下效果:
和我们之前一样,我们监听fetch事件,这次我们查找的字符串是 "/public/images/xxx.jpg",当检测到有这样的请求的时候,我们会使用fetch命令创建一个新的请求,并把第二张图片作为响应返回,fetch它会返回一个promise对象。
注意:fetch方法的第一个参数是必须传递的,可以是request对象,也可以是包含一个相对路径或绝对路径的URL的字符串。比如如下:
// url 请求 fetch("/public/images/xxx.jpg"); // 通过request对象中的url请求 fetch(e.request.url); // 通过传递request对象请求,在这个request对象中,除了url,可能还包含额外的头部信息,表单数据等。 fetch(e.request);
fetch它还有第二个参数,可以包含是一个对象,对象里面是请求的选项。比如如下:
fetch("/public/images/xxx.jpg", {
method: 'POST',
credentials: "include"
});
如上代码,对一个图片发起了一个post请求,并在头部中包含了cookie信息。fetch会返回一个promise对象。
4. 捕获离线请求
我们现在有了上面的service worker的基础知识后,我们来使用service worker检测用户何时处于离线状态,如果检测到用户是处于离线状态,我们会返回一个友好的错误提示,用来代替默认的错误提示。因此我们需要把我们的sw.js 代码改成如下所示:
self.addEventListener("fetch", function(event) {
event.respondWith(
fetch(event.request).catch(function() {
return new Response(
"欢迎来到我们的service worker应用"
)
})
);
});
如上代码我们监听并捕获了所有的fetch事件,然后使用另一个完全相同的fetch操作进行相应,我们的fetch它是返回的是一个promise对象,因此它有catch失败时候来捕获异常的,因此当我们刷新页面后,然后再切换到离线状态时候,我们可以看到页面变成如下提示了,如下图所示:
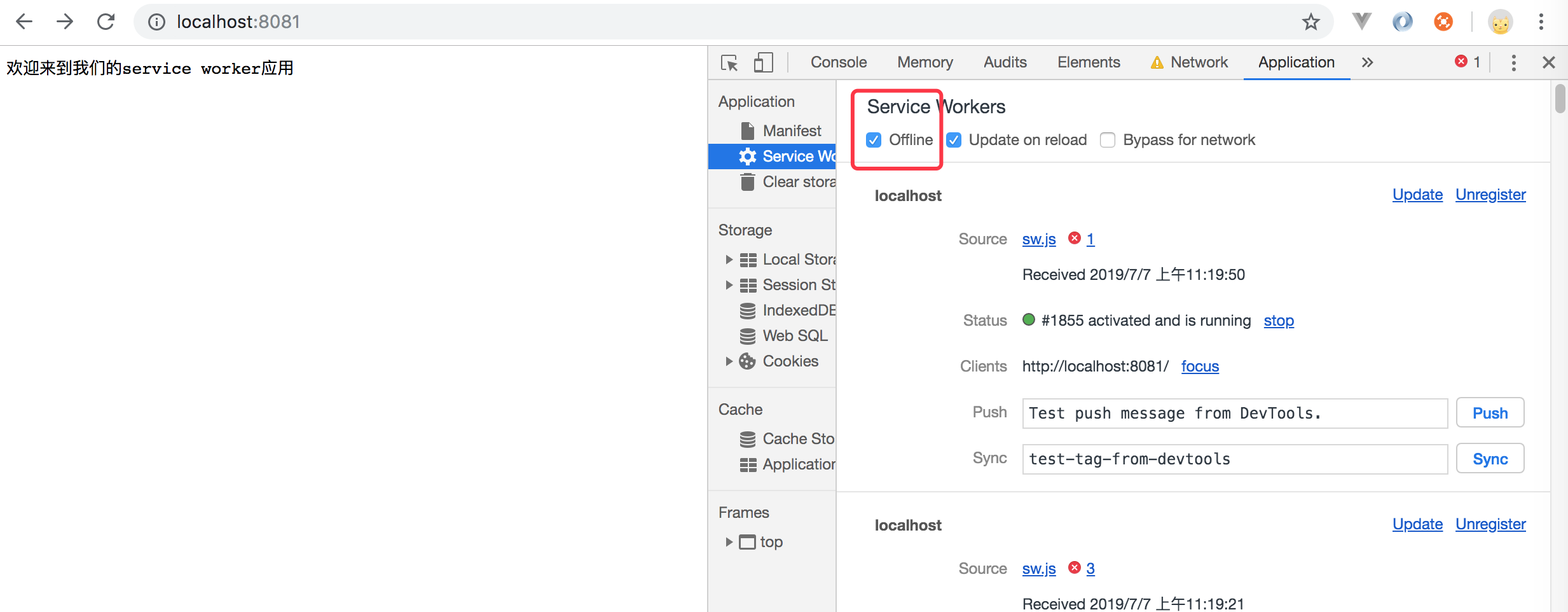
5. 创建html响应
如上响应都是对字符串进行响应的,但是我们也可以拼接html返回进行响应,比如我们可以把sw.js 代码改成如下:
var responseContent = `<html> <body> <head> <meta charset="UTF-8"> <title>service+worker异常</title> <style>body{color:red;font-size:18px;}</style> </head> <h2>service worker异常的处理</h2> </body> ` self.addEventListener("fetch", function(event) { console.log(event.request); event.respondWith( fetch(event.request).catch(function() { return new Response( responseContent, {headers: {"Content-Type": "text/html"}} ) }) ); });
然后我们继续刷新页面,结束掉第一个service worker应用,可以看到如下所示:
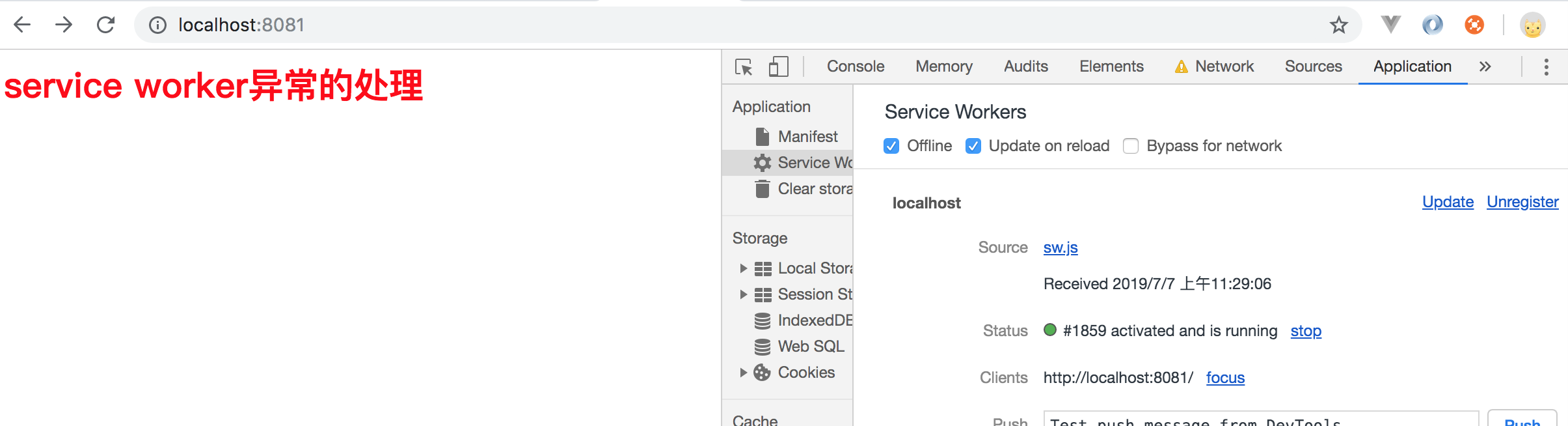
如上代码,我们先定义了给离线用户的html内容,并将其赋值给 responseContent变量中,然后我们添加一个事件监听器,监听所有的fetch事件,我们的回调函数就会被调用,它接收一个 event事件对象作为参数,随后我们调用了该事件对象的 respondWith 方法来响应这个事件,避免其触发默认行为。
respondWith方法接收一个参数,它可以是一个响应对象,也可以是一段通过promise得出响应对象的代码。
如上我们调用fetch,并传入原始请求对象,不仅仅是URL,它还包括头部信息、cookie、和请求方法等,如上我们的打印的 console.log(event.request); 如下所示:

fetch方法它返回的是一个promise对象,如果用户和服务器在线正常的话,那么他们就返回页面中正常的页面,那么这个时候promise对象会返回完成状态。如下我们把利息勾选框去掉,再刷新下页面,可以看到如下信息:
如上页面正常返回了,它就不会进入promise中catch异常的情况下,但是如果离线状态或者异常的情况下,那么就会进入catch异常代码。
因此catch函数就会被调用到。
6. 理解 CacheStorage缓存
在前面的学习当中,当用户离线的时候,我们可以向他们的页面显示自定义的html内容,而不是浏览器的默认错误提示,但是这样也不是最好的处理方式,我们现在想要做的是,如果用户在线的时候,我们以正常的index.html内容显示给用户,包括html内容,图片和css样式等,当用户离线的时候,我们的目标还是想显示index.html中的内容,图片和css样式等这样的显示给用户,也就是说,不管是在线也好,离线也好,我们都喜欢这样显示内容给用户访问。因此如果我们想要实现这么一个功能的话,我们需要在用户在线访问的时候,使用缓存去拿到文件,然后当用户离线的时候,我们就显示缓存中的文件和内容即可实现这样的功能。
什么是CacheStorage?
CacheStorage 是一种全新的缓存层,它拥有完全的控制权。既然CacheStorage可以缓存,那么我们现在要想的问题是,我们什么时候进行缓存呢?到目前为止,我们先来看下 service worker的简单的生命周期如下:
安装中 ----> 激活中 -----> 已激活
我们之前是使用 service worker 监听了fetch事件,那么该事件只能够被激活状态的service worker所捕获,但是我们目前不能在该事件中来缓存我们的文件。我们需要监听一个更早的事件来缓存我们的service worker页面所依赖的文件。
因此我们需要使用 service worker中的install事件,在每个service worker中,该事件只会发生一次。即首次在注册之后以及激活之前,该事件会发生。在service worker接管页面并开始监听fetch事件之前,我们通过该事件进行监听,因此就可以很好的缓存我们所有离线可用的文件。
如果安装有问题的话,我们可以在install事件中取消安装service worker,如果在缓存时出现问题的话,我们可以终止安装,因为当用户刷新页面后,浏览器会在用户下次访问页面时再次尝试安装service worker。通过这种方式,我们可以有效的为service worker创建安装依赖,也就是说在service worker安装并激活之前,我们必须下载并缓存这些文件。
因此我们现在把 sw.js 全部代码改成如下代码:
// 监听install的事件 self.addEventListener("install", function(e) { e.waitUntil( caches.open("cacheName").then(function(cache) { return cache.add("/public/index.html"); }) ) });
如上代码,我们为install事件添加了事件监听器,在新的service worker注册之后,该事件会立即在其安装阶段被调用。
如上我们的service worker 依赖于 "/public/index.html", 我们需要验证它是否成功缓存,然后我们才能认为它安装成功,并激活新的 service worker,因为需要异步获取文件并缓存起来,所以我们需要延迟install事件,直到异步事件完成,因此我们这边使用了waitUntil,waitUntil会延长事件存在的时间,直到promise成功,我们才会调用then方法后面的函数。
在waitUntil函数中,我们调用了 caches.open并传入了缓存的名称为 "cacheName". caches.open 打开并返回一个现有的缓存,如果没有找到该缓存,我们就创建该缓存并返回他。最后我们执行then里面的回调函数,我们使用了 cache.add("/public/index.html").这个方法将请求文件放入缓存中,缓存的键名是 "/public/index.html"。
2. 从CacheStorage中取回请求
上面我们使用 cache.add 将页面的离线版本存储到 CacheStorage当中,现在我们需要做的事情是从缓存中取回并返回给用户。
因此我们需要在sw.js 中添加fetch事件代码,添加如下代码:
// 监听fetch事件 self.addEventListener("fetch", function(e) { e.respondWith( fetch(e.request).catch(function() { return caches.match("/public/index.html"); }) ) });
如上代码和我们之前的fetch事件代码很相似,我们这边使用 caches.match 从CacheStorage中返回内容。
注意:match方法可以在caches对象上调用,这样会在所有缓存中寻找,也可以在某个特定的cache对象上调用。如下所示:
// 在所有缓存中寻找匹配的请求 caches.match('/public/index.html'); // 在特定的缓存中寻找匹配的请求 cache.open("cacheName").then(function(cache) { return cache.match("/public/index.html"); });
match方法会返回一个promise对象,并且向resolve方法传入在缓存中找到的第一个response对象,当找不到任何内容的时候,它的值是undefined。也就是说,即使match找不到对应的响应的时候,match方法也不会被拒绝。如下所示:
caches.match("/public/index.html").then(function(response) {
if (response) {
return response;
}
});
3. 在demo中使用缓存
在如上我们已经把sw.js 代码改成如下了:
// 监听install的事件 self.addEventListener("install", function(e) { e.waitUntil( caches.open("cacheName").then(function(cache) { return cache.add("/public/index.html"); }) ) }); // 监听fetch事件 self.addEventListener("fetch", function(e) { e.respondWith( fetch(e.request).catch(function() { return caches.match("/public/index.html"); }) ) });
当我们第一次访问页面的时候,我们会监听install事件,对我们的 "/public/index.html" 进行缓存,然后当我们切换到离线状态的时候,我们再次刷新可以看到我们的页面只是缓存了 index.html页面,但是页面中的css和图片并没有缓存,如下所示:
现在我们要做的事情是,我们需要对我们所有页面的上的css,图片,js等资源文件进行缓存,因此我们的sw.js 代码需要改成如下所示:
var CACHE_NAME = "cacheName"; var CACHE_URLS = [ "/public/index.html", "/main.css", "/public/images/xxx.jpg" ]; self.addEventListener("install", function(e) { e.waitUntil( caches.open(CACHE_NAME).then(function(cache) { return cache.addAll(CACHE_URLS); }) ) }); // 监听fetch事件 self.addEventListener("fetch", function(e) { e.respondWith( fetch(e.request).catch(function() { return caches.match(e.request).then(function(response) { if (response) { return response; } else if (e.request.headers.get("accept").includes("text/html")) { return caches.match("/public/index.html"); } }) }) ) });
如上代码,我们设置了两个变量,第一个变量 CACHE_NAME 是缓存的名称,第二个变量是一个数组,它包含了一份需要存储的URL列表。
然后我们使用了 cache.addAll()方法,它接收的参数是一个数组,它的作用是把数组里面的每一项存入缓存当中去,当然如果任何一个缓存失败的话,那么它返回的promise会被拒绝。
我们监听了install事件后对所有的资源文件进行了缓存后,当用户处于离线状态的时候,我们使用fetch的事件来监听所有的请求。当请求失败的时候,我们会调用catch里面的函数来匹配所有的请求,它也是返回一个promise对象,当匹配成功后,找到对应的项的时候,直接从缓存里面读取,如果没有找到的话,就直接返回 "/public/index.html" 的内容作为代替。为了安全起见,我们在返回"/public/index.html" 之前,我们还进行了一项检查,该检查确保请求是包含 text/html的accept的头部,因此我们就不会返回html内容给其他的请求类型。比如图片,样式请求等。
我们之前创建一个html响应的时候,必须将其 Content-Type的值定义为 text/html,方便浏览器可以正确的响应识别它是html类型的,那么为什么我们这边没有定义呢,而直接返回了呢?那是因为我们的 cache.addAll()请求并缓存的是一个完整的response对象,该对象不仅包含了响应体,还包含了服务器返回的任何响应头。
注意:使用 caches.match(e.request) 来查找缓存中的条目会存在一个陷阱。
比如用户可能不会总是以相同的url来访问我们的页面,比如它会从其他的网站中跳转到我们的页面上来,比如后面带了一些参数,比如:"/public/index.html?id=xxx" 这样的,也就是说url后面带了一些查询字符串等这些字段,如果我们还是和之前一样进行匹配,是匹配不到的,因此我们需要在match方法中添加一个对象选项;如下所示:
caches.match(e.request, {ignoreSearch: true});
这样的,通过 ignoreSearch 这个参数,通知match方法来忽略查询字符串。
现在我们先请求下我们的页面,然后我们勾选离线复选框,再来查看下我们的页面效果如下所示:
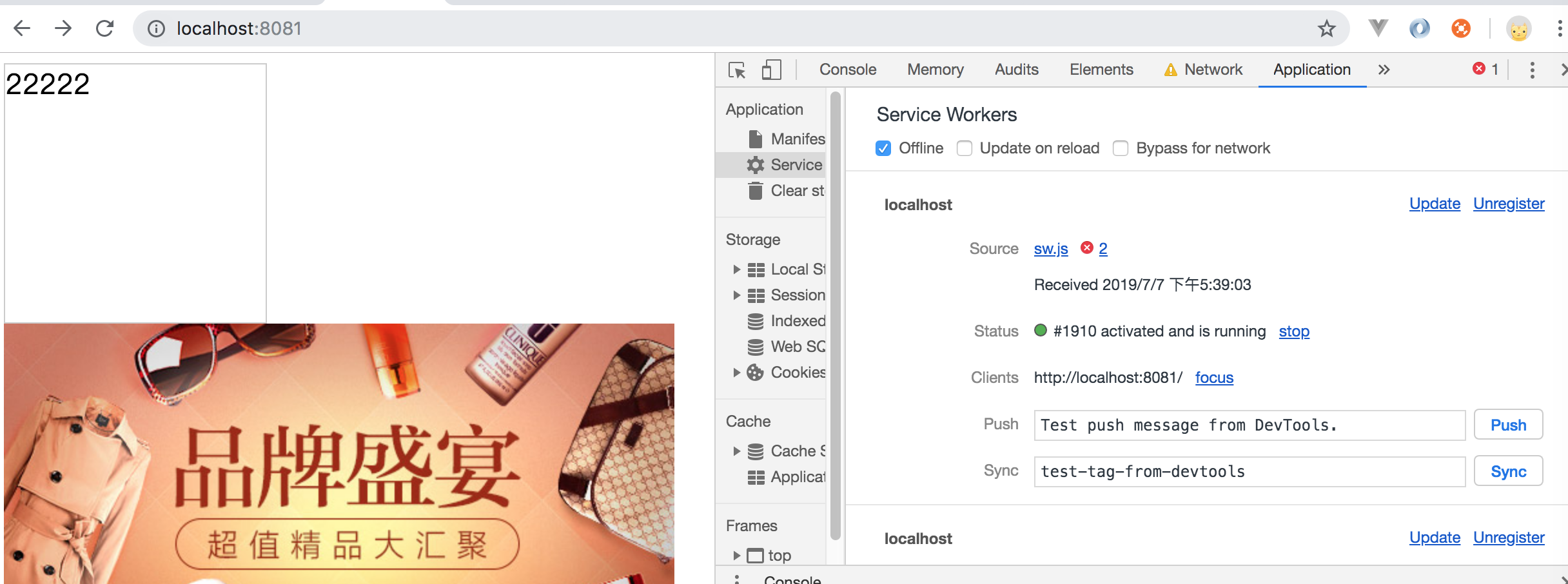
如上可以看到,我们在离线的状态下,页面显示也是正常的。
7. 理解service worker生命周期
service worker 的生命周期如下图所示:
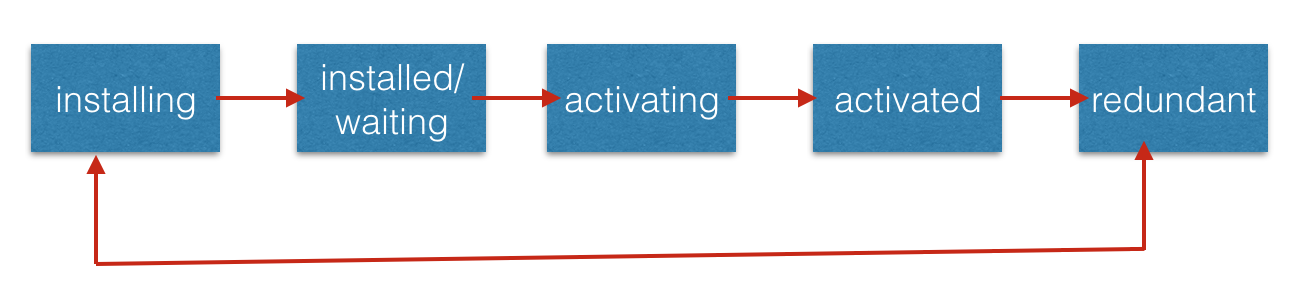
installing(正在安装)
当我们使用 navigator.serviceWorker.register 注册一个新的 service worker的时候,javascript代码就会被下载、解析、并进入安装状态。如果安装成功的话,service worker 就会进入 installed(已安装)的状态。但是如果在安装过程中出现错误,脚本将被永久进入 redundant(废弃中)。
installed/waiting(已安装/等待中)
一旦service worker 安装成功了,就会进入 installed状态,一般情况中,会马上进入 activating(激活中)状态。除非另一个正在激活的 service worker 依然在被控制中。在这种情况下它会维持在 waiting(等待中)状态。
activating(激活中)
在service worker激活并接管应用之前,会触发 activate 事件。
activated(已激活)
一旦 service worker 被激活了,它就准备好接管页面并监听功能性事件(比如fetch事件)。
redundant(废弃)
如果service worker在注册或安装过程中失败了,或者被新的版本代替,就会被置为 redundant 状态,处于这种 service worker将不再对应用产生任何影响。
注意:service worker的状态和浏览器的任何一个窗口或标签页都没有关系的,也就是说 如果service worker是activated(已激活)状态的话,它就会保持这个状态。
8. 理解 service worker 注册过程
当我们第一次访问我们的网站的时候(我们也可以通过删除service worker后刷新页面的方式进行模拟),页面就会加载我们的main.js 代码,如下所示:
if ("serviceWorker" in navigator) { navigator.serviceWorker.register('/sw.js', {scope: '/'}).then(function(registration) { console.log("Service Worker registered with scope: ", registration.scope); }).catch(function(err) { console.log("Service Worker registered failed:", err); }); }
那么我们的应用就会注册service worker,那么service worker的文件将会被下载,然后就开始安装,install事件就会被触发,并且在service worker整个生命周期中只会触发一次,然后触发了我们的函数,将调用的时机记录在控制台中。service worker随后就会进入 installed状态。然后立即就会变成 activating 状态。这个时候,我们的另一个函数就会被触发,因此 activate事件就会把状态记录到控制台中。最后,service worker 进入 activated(已激活)状态。现在service worker被激活状态了。
但是当我们的service worker 正在安装的时候,我们的页面已经开始加载并且渲染了。也就是说 service worker 变成了 active状态了。因此就不能控制页面了,只有我们再刷新页面的时候,我们的已经被激活的service worker才能控制页面。因此我们就可以监听和操控fetch事件了。
9. 理解更新service worker
我们首先来修改下 sw.js 代码,改成如下:
self.addEventListener("fetch", function(e) {
if (e.request.url.includes("main.css")) {
e.respondWith(
new Response(
"#app {color:red;}",
{headers: { "Content-Type": "text/css" }}
)
)
}
});
然后我们再刷新页面,发现页面中的颜色并没有改变,为什么呢?但是我们service worker明明控制了页面,但是页面为什么没有生效?
我们可以打开chrome开发者工具中 Application -> Service Worker 来理解这段代码的含义:如下图所示:
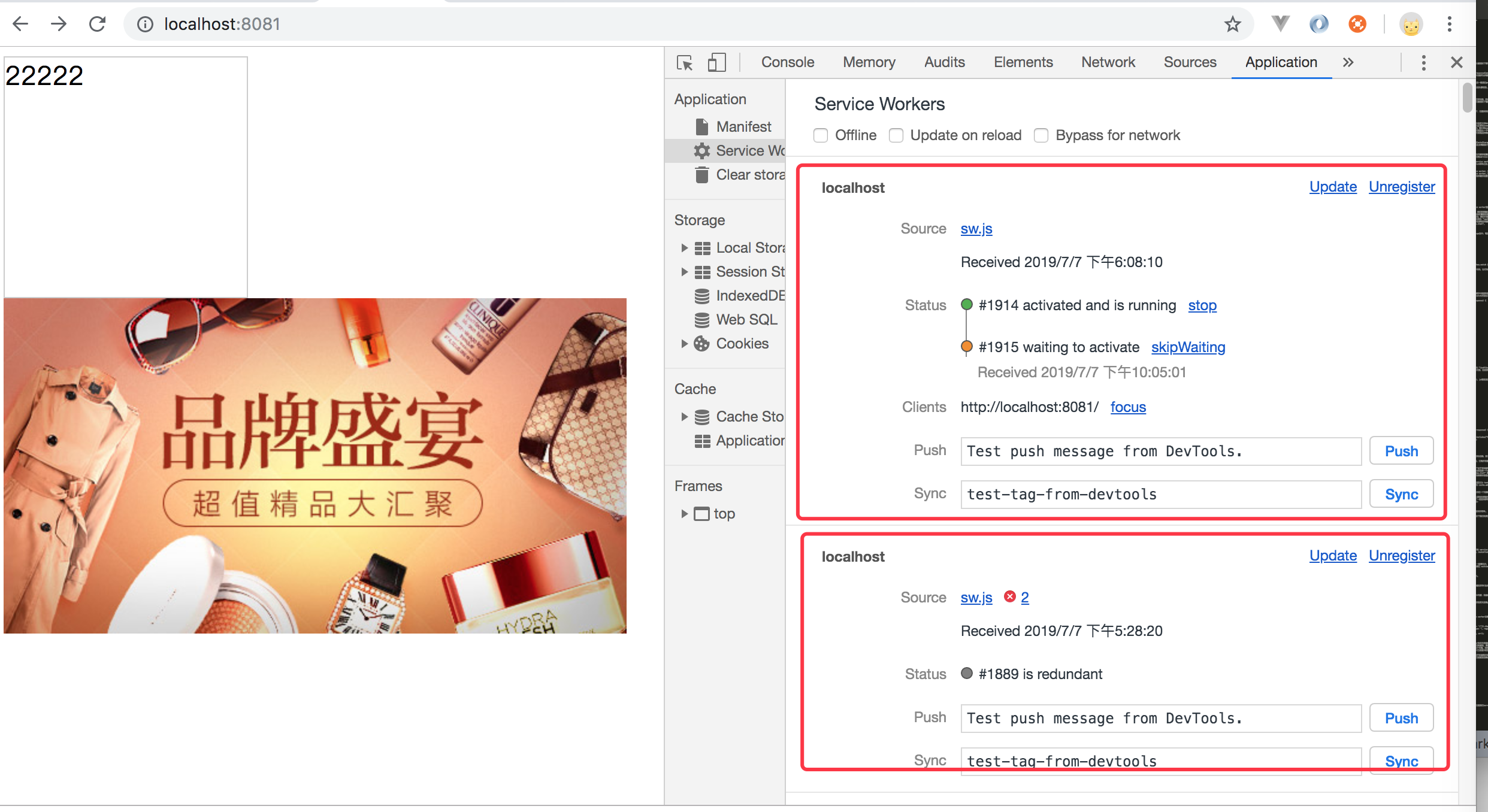
如上图所示,页面注册了多个service worker,但是只有一个在控制页面,旧的service worker是激活的,而新的service worker仍处于等待状态。
每当页面加载一个激活的service worker,就会检查 service worker 脚本的更新。如果文件在当前的service worker注册之后发生了修改,新的文件就会被注册和安装。安装完成后,它并不会替换原先的service worker,而是会保持 waiting 状态。它将会一直保持等待状态,直到原先的service worker作用域中的每个标签和窗口关闭。或者导航到一个不再控制范围内的页面。但是我们可以关闭原先的service worker, 那么原先的service worker 就会变成废弃状态。然后我们新的service worker就会被激活。因此我们可以如下图所示: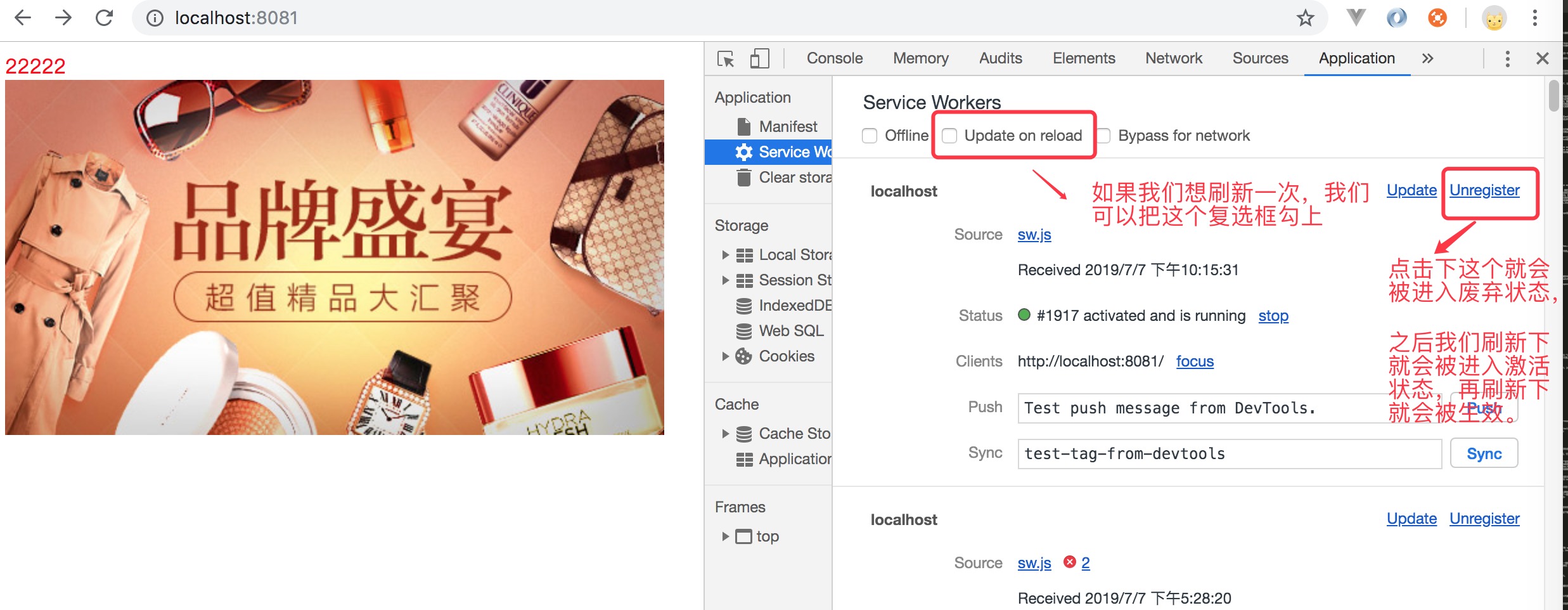
但是如果我们想修改完成后,不结束原来的service worker的话,想改动代码,刷新一下就生效的话,我们需要把 Update on reload这个复选框勾上即可生效,比如如下所示:
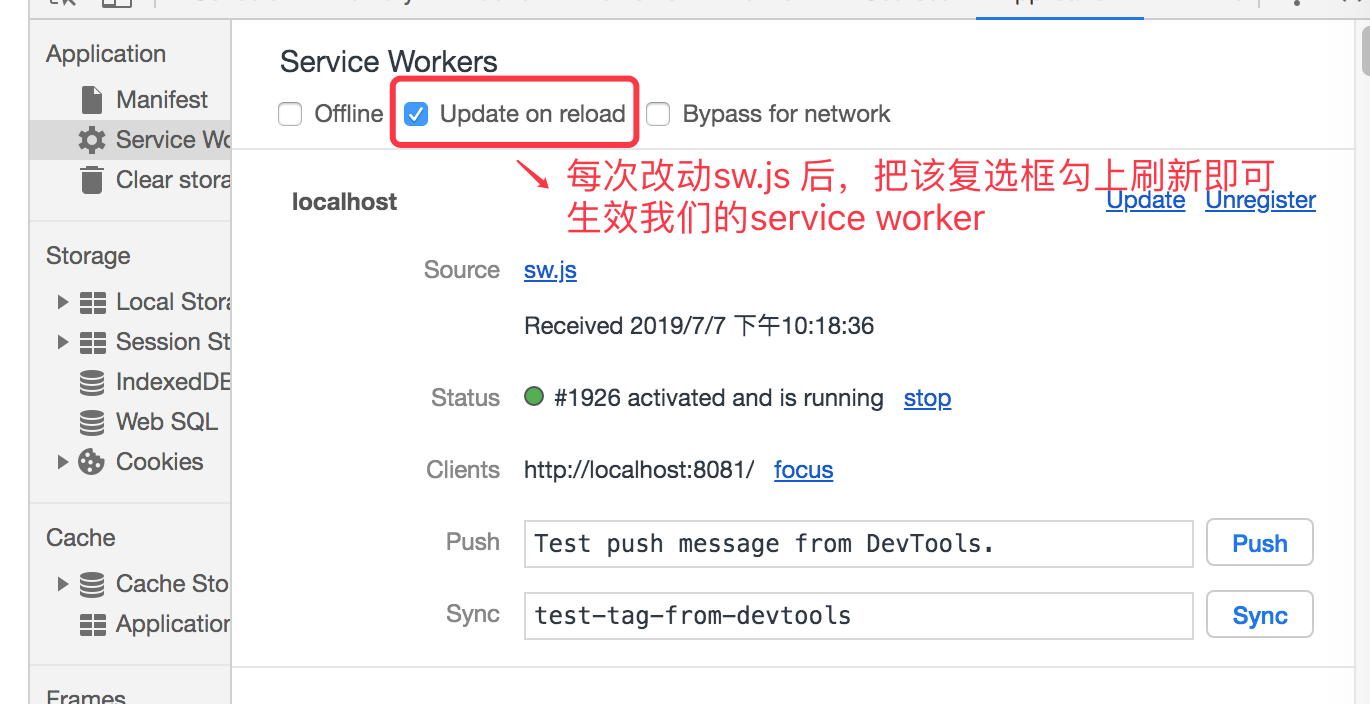
注意:
那么为什么安装完成新的service worker 不能实时生效呢?比如说安装新的service worker不能控制新的页面呢?原先的service worker 控制原先的页面呢?为什么浏览器不能跟踪多个service worker 呢?为什么所有的页面都必须由单一的service worker所控制呢?
我们可以设想下如下这么一个场景,如果我们发布了一个新版本的service worker,并且该service worker的install事件会从缓存中删除 update.json 该文件,并添加 update2.json文件作为代替,并且修改fetch事件,让其在请求用户数据的时候,返回新的文件,如果多个service worker控制了不同的页面,那么旧的service worker控制的页面可能会在缓存中搜索旧的 update.json 文件,但是该文件又被删除了,那么就会导致该应用奔溃。因此我们需要被确保打开所有的标签页或窗口由一个service worker控制的话,就可以避免类似的问题发生。
10. 理解缓存管理和清除缓存
为什么需要管理缓存呢?
我们首先把我们的sw.js 代码改成原先的如下代码:
var CACHE_NAME = "cacheName"; var CACHE_URLS = [ "/public/index.html", "/main.css", "/public/images/xxx.jpg" ]; self.addEventListener("install", function(e) { e.waitUntil( caches.open(CACHE_NAME).then(function(cache) { return cache.addAll(CACHE_URLS); }) ) }); // 监听fetch事件 self.addEventListener("fetch", function(e) { e.respondWith( fetch(e.request).catch(function() { return caches.match(e.request).then(function(response) { if (response) { return response; } else if (e.request.headers.get("accept").includes("text/html")) { return caches.match("/public/index.html"); } }) }) ) });
如上代码,我们的service worker会在安装阶段下载并缓存所需要的文件。如果希望它再次下载并缓存这些文件的话,我们就需要触发另一个安装事件。在sw.js中的,我们把 CACHE_NAME 名字改下即可。比如叫 var CACHE_NAME = "cacheName2"; 这样的。
通过如上给缓存名称添加版本号,并且每次修改文件时自增它,可以实现两个目的。
1)修改缓存名称后,浏览器就知道安装新的service worker来代替旧的service worker了,因此会触发install事件,因此会导致文件被下载并存储在缓存中。
2)它为每一个版本的service worker都创建了一份单独的缓存。即使我们更新了缓存,在用户关闭所有页面之前,旧的service worker依然是激活的。旧的service worker可能会用到缓存中的某些文件,而这些文件又是可以被新的service worker所修改的,通过让每个版本的service worker所拥有自己的缓存,就可以确保不会出现其他的异常情况。
如何清除缓存呢?
caches.delete(cacheName); 该方法接收一个缓存名字作为第一个参数,并删除对应的缓存。
caches.keys(); 该方法是获取所有缓存的名称,并且返回一个promsie对象,其完成的时候会返回一个包含缓存名称的数组。如下所示:
caches.keys().then(function(cacheNames){ cacheNames.forEach(function(cacheName){ caches.delete(cacheName); }); });
如何缓存管理呢?
在service worker生命周期中,我们需要实现如下目标:
1)每次安装 service worker,我们都需要创建一份新的缓存。
2)当新的service worker激活的时候,就可以安全删除过去的service worker 创建的所有缓存。
因此我们在现有的代码中,添加一个新的事件监听器,监听 activate 事件。
self.addEventListener("activate", function(e) {
e.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (CACHE_NAME !== cacheName && cacheName.startWith("cacheName")) {
return caches.delete(cacheName);
}
})
)
})
)
});
11. 理解重用已缓存的响应
如上我们的带版本号缓存已经实现了,为我们提供了一个非常灵活的方式来控制我们的缓存,并且保持最新的缓存。但是缓存内的实现是非常低下的。
比如每次我们创建一个新的缓存的时候,我们会使用 cache.add() 或 cache.addAll() 这样的方法来缓存应用需要的所有文件。但是,如果用户已经在本地拥有了 cacheName 这个缓存的话,那如果这个时候我们创建 cacheName2 这个缓存的话,我们发现我们创建的 cacheName2 需要缓存的文件 在 cacheName 已经有了,并且我们发现这些文件是永远不会被改变的。如果我们重新缓存这些文件的话,就浪费了宝贵的带宽和时间从网络再次下载他们。
为了解决如上的问题,我们需要如下做:
如果我们创建一个新的缓存,我们首先要遍历一份不可变的文件列表,然后从现有的缓存中寻找他们,并直接复制到新的缓存中。因此我们的sw.js 代码变成如下所示:
var CACHE_NAME = "cacheName"; var immutableRequests = [ "/main.css", "/public/images/xxx.jpg" ]; var mutableRequests = [ "/public/index.html" ]; self.addEventListener("install", function(e) { e.waitUntil( caches.open(CACHE_NAME).then(function(cache) { var newImmutableRequests = []; return Promise.all( immutableRequests.map(function(url) { return caches.match(url).then(function(response) { if (response) { return cache.put(url, response); } else { newImmutableRequests.push(url); return Promise.resolve(); } }); }) ).then(function(){ return cache.addAll(newImmutableRequests.concat(mutableRequests)); }) }) ) });
如上代码。
1)immutableRequests 数组中包含了我们知道永远不会改变的资源URL,这些资源可以安全地在缓存之间复制。
2)mutableRequests 中包含了每次创建新缓存时,我们都需要从网络中请求的url。
如上代码,我们的 install 事件会遍历所有的 immutableRequests,并且在所有现有的缓存中寻找他们。如果被找到的话,都会使用cache.put()复制到新的缓存中。如果没有找到该资源的话,会被放入到新的 newImmutableRequests 数组中。
一旦所有的请求被检查完毕,代码就会使用 cache.addAll()来缓存 mutableRequests 和 newImmutableRequests 中所有的URL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号