
深入理解 path-to-regexp.js 及源码分析
2019-04-07 10:33 龙恩0707 阅读(10360) 评论(1) 收藏 举报阅读目录
一:path-to-regexp.js 源码分析如下:
我们在vue-router中,react-router或koa-router中,我们经常做路由匹配像这种格式的 /foo/:id 这样的,或者其他更复杂的路由匹配,都能支持,那么这些路由背后是怎么做的呢?其实它就是依赖于 path-to-regexp.js的。下面我们先来了解下 path-to-regexp.js的基本用法。
一:path-to-regexp.js 源码分析如下:
首先从源码中该js文件对外暴露了5个方法,源码如下:
module.exports = pathToRegexp module.exports.parse = parse module.exports.compile = compile module.exports.tokensToFunction = tokensToFunction module.exports.tokensToRegExp = tokensToRegExp
首先要说明下的是:分析源码的最好的方式是:做个demo,然后在页面上执行结果打上断点一步步调式。就能理解代码的基本含义了。
首先path-to-regexp.js源码如下初始化一些数据:
/** * Default configs. 默认的配置项在 '/' 下 */ var DEFAULT_DELIMITER = '/'; /** * The main path matching regexp utility. * * @type {RegExp} */ var PATH_REGEXP = new RegExp([ // Match escaped characters that would otherwise appear in future matches. // This allows the user to escape special characters that won't transform. '(\\\\.)', // Match Express-style parameters and un-named parameters with a prefix // and optional suffixes. Matches appear as: // // ":test(\\d+)?" => ["test", "\d+", undefined, "?"] // "(\\d+)" => [undefined, undefined, "\d+", undefined] '(?:\\:(\\w+)(?:\\(((?:\\\\.|[^\\\\()])+)\\))?|\\(((?:\\\\.|[^\\\\()])+)\\))([+*?])?' ].join('|'), 'g');
然后看源码中看到一个很复杂的正则。我们来分析下该正则的含义,因为下面会使用到该正则返回的 PATH_REGEXP 来匹配的。
1. new RegExp('\\\\.', 'g'); 的含义是:在 new RegExp对象后,会返回 /\\./g, 然后是匹配字符串 \\ , 点号(.) 是元字符匹配任意的字符。因此如下测试代码可以理解具体的作用了:
var reg12 = new RegExp('\\\\.', 'g'); console.log(reg12); // 输出 /\\./g console.log(reg12.test('.')); // false console.log(reg12.test('\.')); // false console.log(reg12.test('\a')); // false console.log(reg12.test('.a')); // false console.log(reg12.test('n.a')); // false console.log(reg12.test('\\a')); // true console.log(reg12.test('\\aaaa')); // false console.log(reg12.test('\\.')); // true
想要详细了解相关的知识点,请看这篇文章
2. (?:\\:(\\w+)(?:\\(((?:\\\\.|[^\\\\()])+)\\))?|\\(((?:\\\\.|[^\\\\()])+)\\))([+*?])?
如上复杂的正则表达式可以分解为如下:
(?:\\: (\\w+) (?:\\ ( ( (?:\\\\.|[^\\\\()])+ )\\ ) )? | \\ ( ( (?:\\\\.|[^\\\\()])+ )\\ ) )([+*?])?
如上正则表达式,我们把它分解成如上所示,俗话说,正则表达式不管它有多复杂,我们可以学会一步步分解出来。
1. (?:\\:)的含义:?:以这样的开头,我们可以理解为 非捕获性分组。非捕获性分组的含义可以理解:子表达式可以作为被整体修饰但是子表达式匹配的结果不会被存储;什么意思呢?比如如下demo:
// 非捕获性分组 var num2 = "11 22"; /#(?:\d+)/.test(num2); console.log(RegExp.$1); // 输出:"" var num2 = "11aa22"; console.log(/(?:\d+)/.test(num2)); // 返回 true
具体理解非捕获性分组我们可以看这篇文章.
因此 (?:\\:) 的含义是 匹配 \\: 这样的字符串。比如如下测试demo:
/(?:\\:)/g.test("\\:"); // 返回true
/(?:\\:)/g.test("\\:a"); // 返回true
因此我们可以总结 (?:\\:) 的具体含义是:使用非捕获性分组,只要能匹配到字符串中含有 \\: 就返回true.
2. (\\w+) 的含义:
\w; 查找任意一个字母或数字或下划线,等价于A_Za_z0_9,_ 那么 \\w+ 呢?请看如下demo
const t1 = new RegExp('\\w+', 'g'); console.log(t1); // 输出 /\w+/g console.log(t1.test('11')); // true
也就是说 \\w+ 在 RegExp中实列化后,变成了 /\w+/g, 、\w+ 的含义就是匹配任意一个或多个字母、数字、下划线。
3. (?:\\ 和 第一点是一样的。就是匹配 字符串中包含的 '\\' 这个的字符。
4. (?:\\\\.|[^\\\\()])+ 中的 ?:\\\\. , 上面介绍了 (?:)这是非捕获性分组,\\\\.的含义就是匹配字符串中 "\\" , 点号(.) 是元字符匹配任意的字符。然后元字符+ 就是匹配至少一个或多个。比如如下demo。
const t1 = new RegExp('(?:\\\\.)+', 'g'); console.log(t1); // 输出 /(?:\\.)+/g /(?:\\.)+/g.test("\\\\\aaaa"); // true /(?:\\.)+/g.test("\\\\\bbbb"); // true /(?:\\.)+/g.test("\\..."); // true
([^\\\\()])+ 的含义是:分组匹配 ([^\\()])+
const t1 = new RegExp('([^\\\\()])+', 'g'); console.log(t1); // 输出 /([^\\()])+/g;
如下图所示:
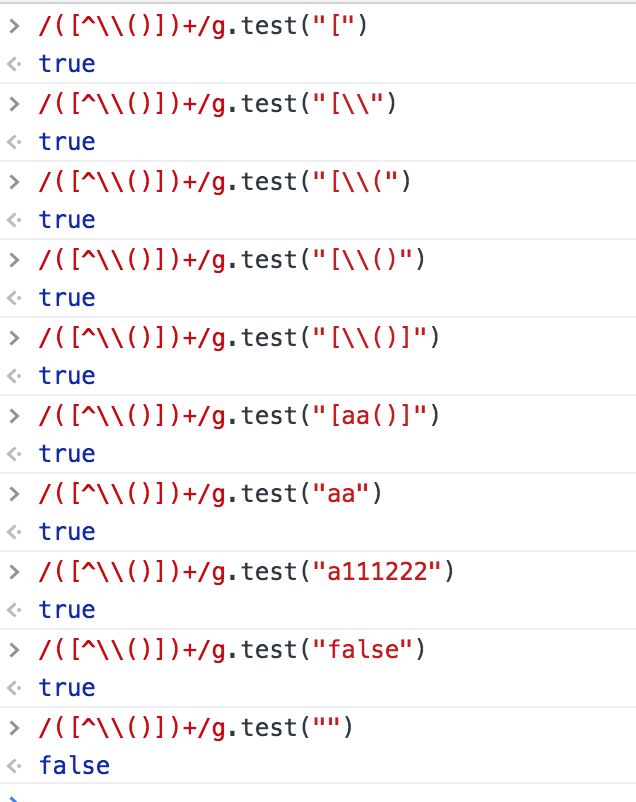
应该就是任意一个字符吧,如果是空字符串的话,返回false.
后面的正则表达式也是差不多的意思。
一: pathToRegExp
该方法的作用是将路径字符串转换为正则表达式。
如下基本代码:
/** * Normalize the given path string, returning a regular expression. * * An empty array can be passed in for the keys, which will hold the * placeholder key descriptions. For example, using `/user/:id`, `keys` will * contain `[{ name: 'id', delimiter: '/', optional: false, repeat: false }]`. * * @param {(string|RegExp|Array)} path * @param {Array=} keys * @param {Object=} options * @return {!RegExp} */ function pathToRegexp (path, keys, options) { if (path instanceof RegExp) { return regexpToRegexp(path, keys) } if (Array.isArray(path)) { return arrayToRegexp(/** @type {!Array} */ (path), keys, options) } return stringToRegexp(/** @type {string} */ (path), keys, options) }
该方法有三个参数:
@param path {string|RegExp|Array} 为url路径,它的类型为一个字符串、正则表达式或一个数组.
@param keys {Array} 默认为空数组 []
@param options {Object} 为一个对象。
@return 返回的是一个正则表达式
pathToRegexp代码的基本含义如下:
1. 判断该路径是否是正则表达式的实列,if (path instanceof RegExp) {}, 如果是的话,就直接返回正则表达式 return regexpToRegexp(path, keys);
2. 判断该路径是否是一个数组,如果是一个数组的话,if (Array.isArray(path)) {}, 那么就把数组转换为 正则表达式,如代码:return arrayToRegexp((path), keys, options);
3. 如果即不是正则表达式的实列,也不是一个数组的话,那就是字符串了,因此使用把字符串转换为正则表达式,如代码: return stringToRegexp((path), keys, options);
比如如下demo,传入的path是一个字符串路径,它返回的是一个正则表达式。
3.1 只有第一个参数字符串。
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id');
console.log(t1); // /^\/foo\/([^\/]+?)(?:\/)?$/i
// 普通的字符串
const t2 = pathToRegExp('aaa');
console.log(t2); // /^aaa(?:\/)?$/i
我们先打个断点看看,它代码是如何执行的:
如下图所示:
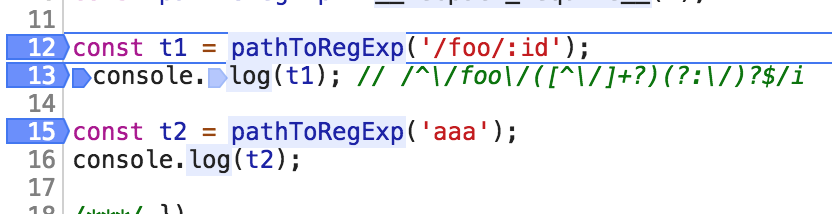
可以看到,断点会先进入 pathToRegExp 方法内部,代码如上,先判断第一个参数path是否是一个字符串,还是是一个正则表达式,或者是一个数组,由于我们传入的是一个字符串,因此会调用 return stringToRegexp((path), keys, options); 这个方法内部执行。如下 stringToRegexp 函数方法内部,如下所示:
我们可以看到,第一个参数path传入的是一个字符串 "/foo/:id", 然后第二个参数和第三个参数我们都没有传递,因此他们都为undefined。最后他们会调用 tokensToRegExp 这个函数,但是在调用该函数之前,会先调用 parse这个方法:parse(path, options);我们先进入 parse这个方法内部看看情况。
parse函数代码如下:
/** * Parse a string for the raw tokens. * * @param {string} str * @param {Object=} options * @return {!Array} */ function parse (str, options) { var tokens = [] var key = 0 var index = 0 var path = '' var defaultDelimiter = (options && options.delimiter) || DEFAULT_DELIMITER var whitelist = (options && options.whitelist) || undefined var pathEscaped = false var res while ((res = PATH_REGEXP.exec(str)) !== null) { var m = res[0] var escaped = res[1] var offset = res.index path += str.slice(index, offset) index = offset + m.length // Ignore already escaped sequences. if (escaped) { path += escaped[1] pathEscaped = true continue } var prev = '' var name = res[2] var capture = res[3] var group = res[4] var modifier = res[5] if (!pathEscaped && path.length) { var k = path.length - 1 var c = path[k] var matches = whitelist ? whitelist.indexOf(c) > -1 : true if (matches) { prev = c path = path.slice(0, k) } } // Push the current path onto the tokens. if (path) { tokens.push(path) path = '' pathEscaped = false } var repeat = modifier === '+' || modifier === '*' var optional = modifier === '?' || modifier === '*' var pattern = capture || group var delimiter = prev || defaultDelimiter tokens.push({ name: name || key++, prefix: prev, delimiter: delimiter, optional: optional, repeat: repeat, pattern: pattern ? escapeGroup(pattern) : '[^' + escapeString(delimiter === defaultDelimiter ? delimiter : (delimiter + defaultDelimiter)) + ']+?' }) } // Push any remaining characters. if (path || index < str.length) { tokens.push(path + str.substr(index)) } return tokens }
该方法同样我们传入了两个参数,第一个是 path这个路径,第二个是 options,该参数是一个对象,看这句代码:
var defaultDelimiter = (options && options.delimiter) || DEFAULT_DELIMITER;
由此可见,该options对象有一个参数 delimiter, 我们可以先理解为一个分隔符吧。默认为 DEFAULT_DELIMITER = '/' 这样的。
var whitelist = (options && options.whitelist) || undefined 这句代码的时候,我们也可以看到options对象也有一个 whitelist 该key。具体做什么用的,我们现在还未知,不过没有关系,我们一步步先走下去。
while ((res = PATH_REGEXP.exec(str)) !== null) {} 当代码执行到这句的时候,使用while循环,如果res = PATH_REGEXP.exec(str)) !== null, 当res不是null的时候,就执行下面的代码,我们先来看下使用正则中的exec方法执行完成后,一般会返回什么,如下基本的测试 exec代码:
var reg = new RegExp([ // Match escaped characters that would otherwise appear in future matches. // This allows the user to escape special characters that won't transform. '(\\\\.)', // Match Express-style parameters and un-named parameters with a prefix // and optional suffixes. Matches appear as: // // ":test(\\d+)?" => ["test", "\d+", undefined, "?"] // "(\\d+)" => [undefined, undefined, "\d+", undefined] '(?:\\:(\\w+)(?:\\(((?:\\\\.|[^\\\\()])+)\\))?|\\(((?:\\\\.|[^\\\\()])+)\\))([+*?])?' ].join('|'), 'g'); var str = "/foo/:id"; console.log(reg.exec(str));
如下图是 console.log(reg.exec(str)); 这句代码输出的数据;

exec() 该方法如果找到了匹配的文本的话,则会返回一个结果数组,否则的话,会返回一个null。
该数组的第0个元素的含义是:它是与正则相匹配的文本。
第1个元素是与RegExpObject的第1个子表达式相匹配的文本。如果没有的话,就返回undefined.
第2个元素是与RegExpObject的第2个子表达式相匹配的文本,如果没有的话,就返回undefined。
.... 依次类推。
除了这些返回之外,exec方法还反回了两个属性,
index: 该属性是声明的匹配文本的第一个字符的位置。
input: 该属性是存放的是被检索的字符串。
因此exec方法返回的是一个数组,具体的对应的含义就是上面的解释的哦。
我们使用断点可以看到如下代码的截取的数据,如下图所示:



如上就是 parse 函数返回的数据了,现在我们继续进入 tokensToRegExp 函数,看如何转为正则表达式了。
tokensToRegExp 函数第一个参数 tokens 如下值就是执行完 parse函数返回的值了。
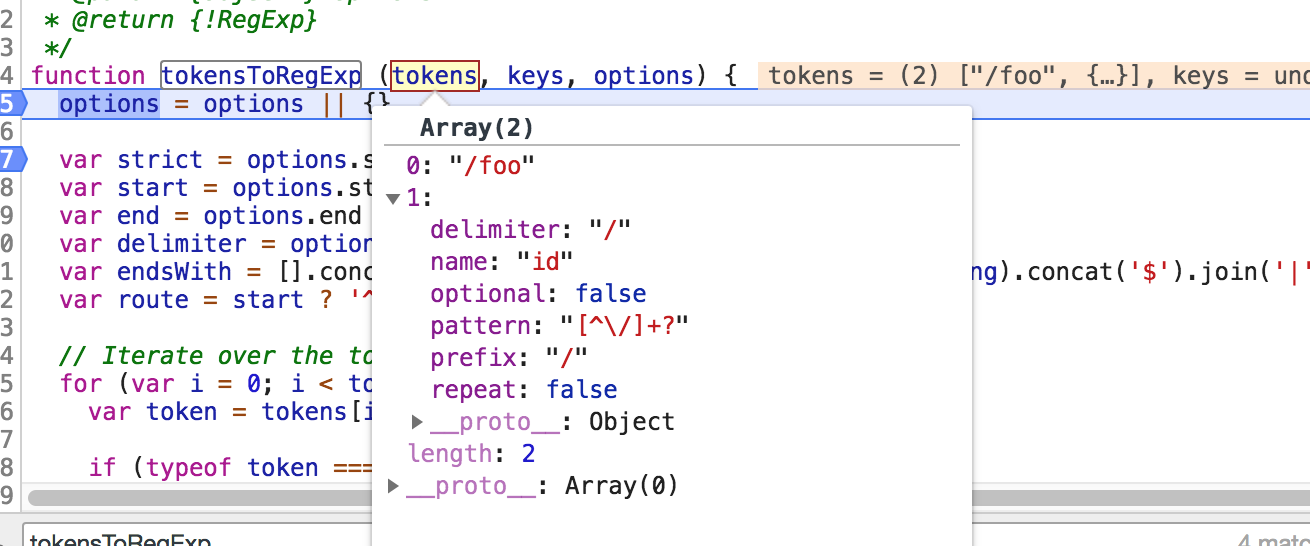
我们继续走可以看到如下所示:

注意:我们现在就能明白 第三个参数 options 传进来的是一个对象,它有哪些key呢?从上面我们分析可知:
有如下key配置项:
options = { delimiter: '', whitelist: '', strict: '', start: '', end: '', endsWith: '' }
如上是目前知道的配置项,该配置项具体是什么作用,我们目前还未知,我们可以继续走下代码看看;
我们接下来是遍历传进来的tokens了。tokens它是一个数组,具体的可以看如上所示。
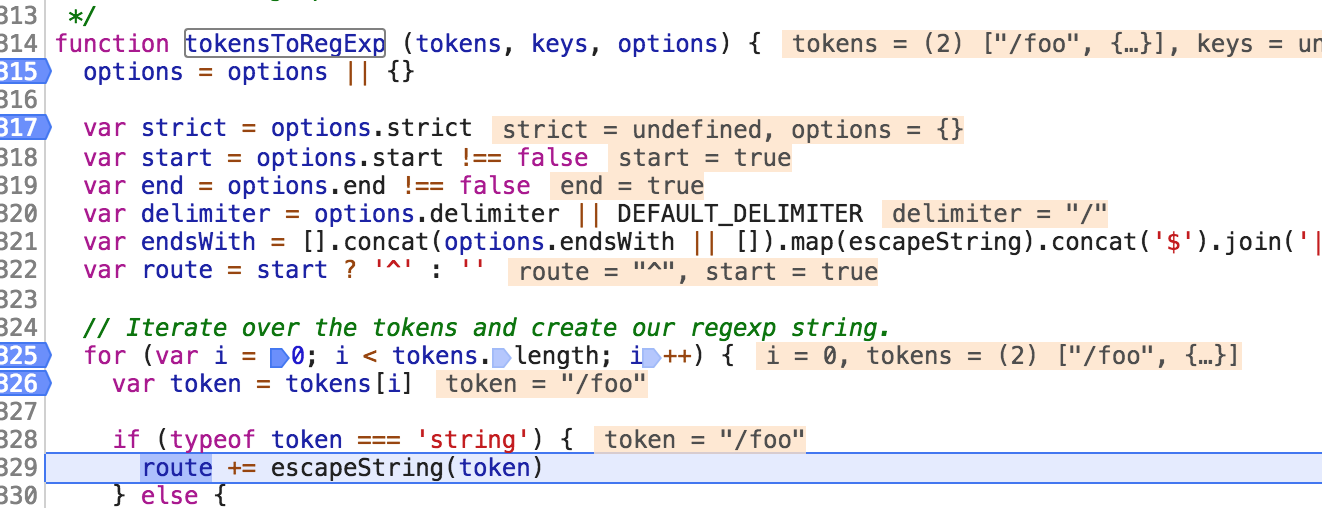
tokens 第一个参数为'/foo'; 因此进入 route += escapeString(token); 因此会调用 escapeString 函数,然后把值返回回来给 route; escapeString 函数代码如下:
/** * Escape a regular expression string. * * @param {string} str * @return {string} */ function escapeString (str) { return str.replace(/([.+*?=^!:${}()[\]|/\\])/g, '\\$1') }
因此最后返回给 route 的值为 "\/foo", 代码执行如下所示:

执行完成后,如上所示,我们会继续循环tokens, 因此会获取到第二个元素了,第二个元素是一个对象,该值为如下:
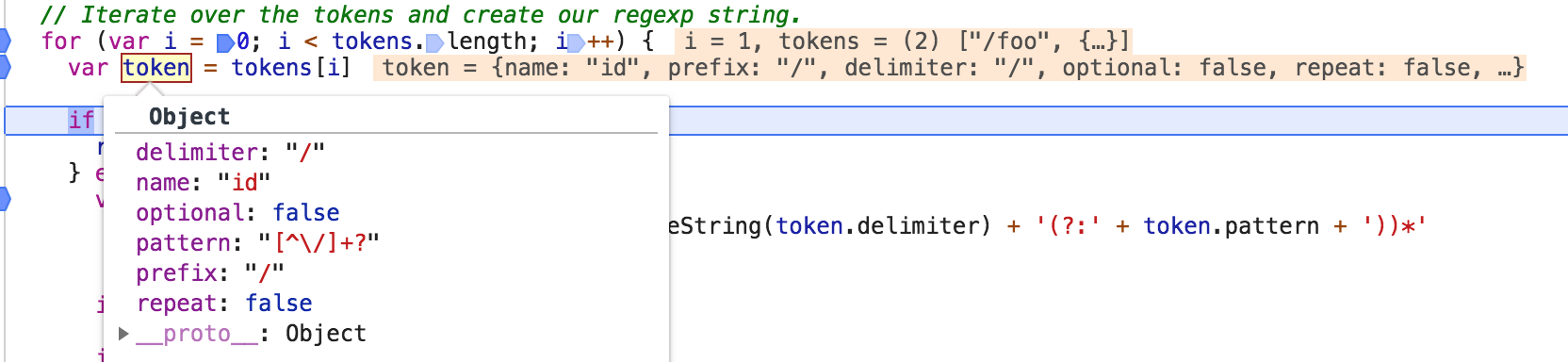
因此我们会进入 else语句代码内部了,首先判断:
var capture = token.repeat ? '(?:' + token.pattern + ')(?:' + escapeString(token.delimiter) + '(?:' + token.pattern + '))*' : token.pattern
判断 token的属性 repeat 是否为true,如果为true的话,就使用 ? 后面的表达式,否则的是 token.pattern的值
了。
如下图所示:
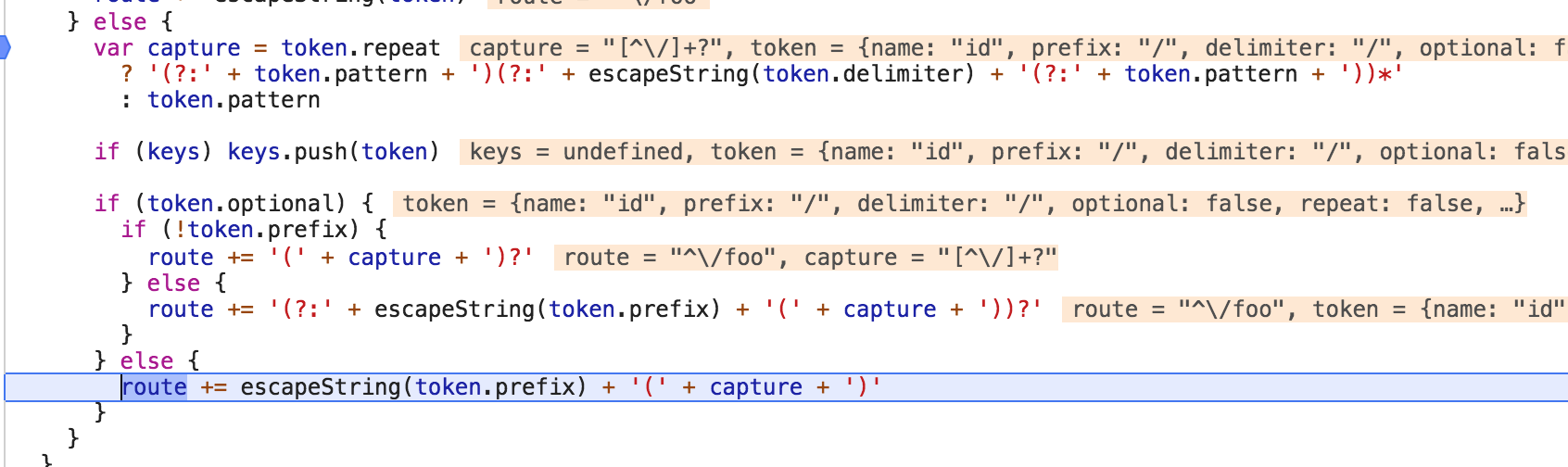
最后我们返回的 route就是如下的正则表达式了;

最后就是代码继续判断了,执行结果为如下:
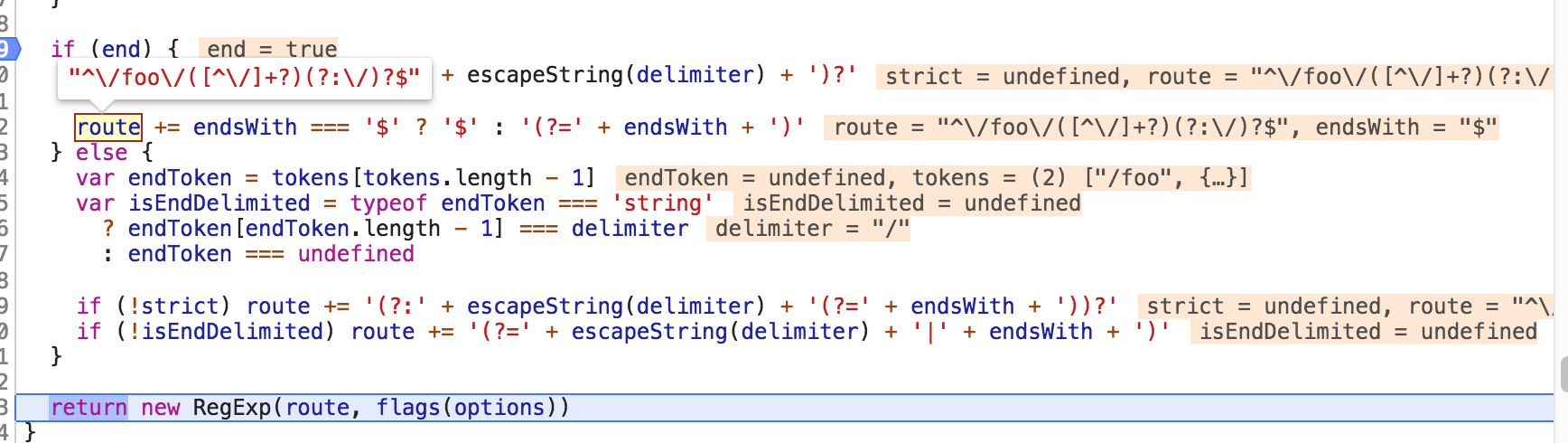
我们可以看到,执行结果后就是返回的我们的正则表达式了:
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id');
console.log(t1); // /^\/foo\/([^\/]+?)(?:\/)?$/i
和上面打印的是类似的。
总结:当我们使用 pathToRegexp 将字符串转换为正则表达式的时候,第一个参数为字符串,第二个参数和第三个参数为undefined的时候,首先会调用
function pathToRegexp (path, keys, options) { return stringToRegexp(/** @type {string} */ (path), keys, options); }
这个函数,然后接着调用 stringToRegexp 这个函数,会将字符串转化为正则表达式,该函数传入三个参数,第一个参数为字符串,第二个参数和第三个参数目前为undefined。现在我们来看下stringToRegexp函数代码如下:
/** * Create a path regexp from string input. * * @param {string} path * @param {Array=} keys * @param {Object=} options * @return {!RegExp} */ function stringToRegexp (path, keys, options) { return tokensToRegExp(parse(path, options), keys, options) }
接着会调用 tokensToRegExp 函数,将字符串转换为真正的正则,在调用该方法之前,会先调用 parse 方法,会将字符串使用exec方法匹配,如果匹配成功的话,就返回exec匹配成功后的一个数组,里面会包含很多字段。如下代码:
function parse (str, options) { var tokens = [] var key = 0 var index = 0 var path = '' var defaultDelimiter = (options && options.delimiter) || DEFAULT_DELIMITER var whitelist = (options && options.whitelist) || undefined var pathEscaped = false var res while ((res = PATH_REGEXP.exec(str)) !== null) { var m = res[0] var escaped = res[1] var offset = res.index path += str.slice(index, offset) index = offset + m.length // Ignore already escaped sequences. if (escaped) { path += escaped[1] pathEscaped = true continue } var prev = '' var name = res[2] var capture = res[3] var group = res[4] var modifier = res[5] if (!pathEscaped && path.length) { var k = path.length - 1 var c = path[k] var matches = whitelist ? whitelist.indexOf(c) > -1 : true if (matches) { prev = c path = path.slice(0, k) } } // Push the current path onto the tokens. if (path) { tokens.push(path) path = '' pathEscaped = false } var repeat = modifier === '+' || modifier === '*' var optional = modifier === '?' || modifier === '*' var pattern = capture || group var delimiter = prev || defaultDelimiter tokens.push({ name: name || key++, prefix: prev, delimiter: delimiter, optional: optional, repeat: repeat, pattern: pattern ? escapeGroup(pattern) : '[^' + escapeString(delimiter === defaultDelimiter ? delimiter : (delimiter + defaultDelimiter)) + ']+?' }) } // Push any remaining characters. if (path || index < str.length) { tokens.push(path + str.substr(index)) } return tokens }
如上代码,首先会 while ((res = PATH_REGEXP.exec(str)) !== null) {} 匹配'/foo/:id',将结果保存到res中,再判断res是否为null,如果没有匹配到的话,就返回null,如果匹配到了,就返回匹配后的结果。
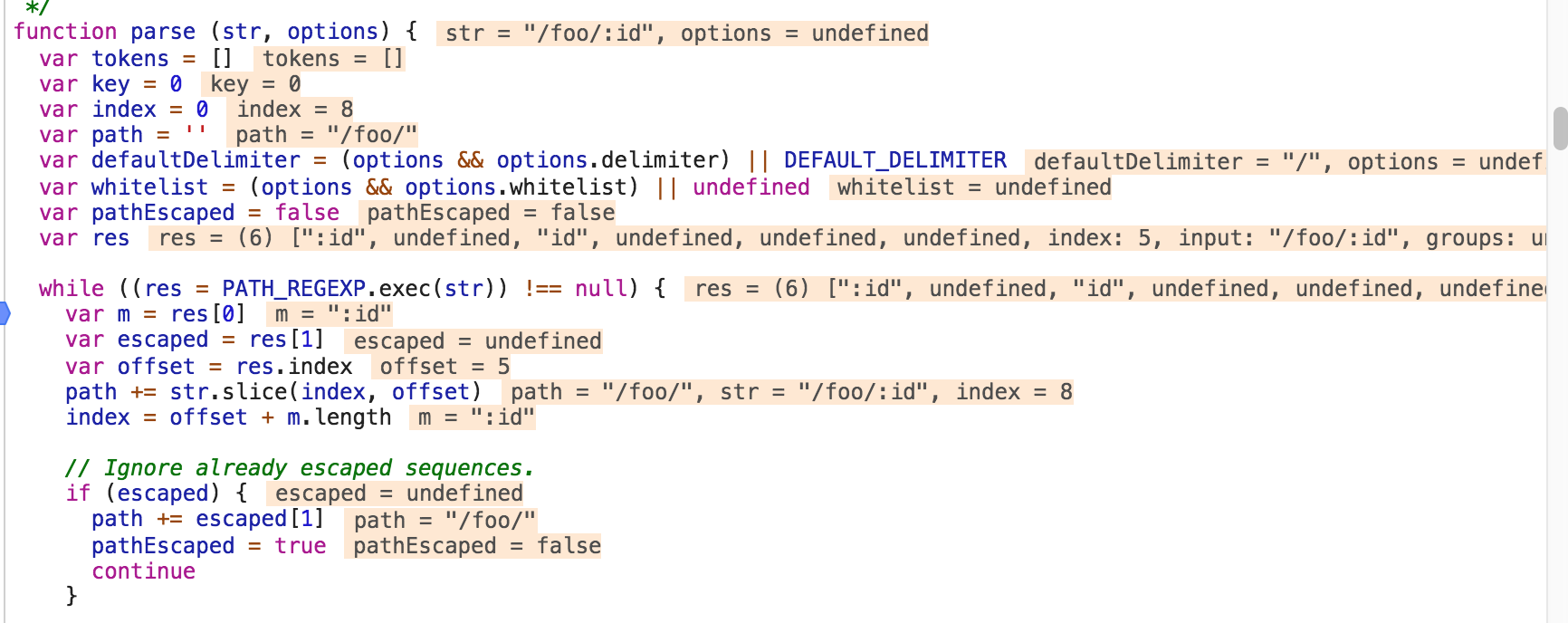
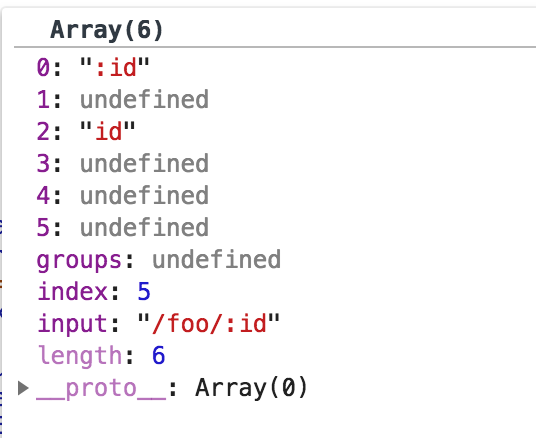
因此匹配到了 :id, 因此res匹配的结果如下:
[ ":id", undefined, "id", undefined, undefined, undefined, groups: undefined, index: 5, input: '/foo/:id' ]
如下图所示:
接着执行这段代码:
var m = res[0] var escaped = res[1] var offset = res.index path += str.slice(index, offset) index = offset + m.length // Ignore already escaped sequences. if (escaped) { path += escaped[1] pathEscaped = true continue } var prev = '' var name = res[2] var capture = res[3] var group = res[4] var modifier = res[5]
因此 m = ":id", escaped = undefined, offset = 5, path += str.slice(index, offset); 因此 path = '/foo/:id'.slice(0, 5); path = '/foo/'; 接着 index = offset + m.length = 5 + 3 = 8; 接着判断 有没有 escaped,上面可知为undefined,因此不会进入if语句内部,接着 prev = ''; name = res[2] = 'id'; capture = res[3] = undefined, group = undefined, modifier = res[5] = undefined;
再接着执行下面的代码:
if (!pathEscaped && path.length) { var k = path.length - 1 var c = path[k] var matches = whitelist ? whitelist.indexOf(c) > -1 : true if (matches) { prev = c path = path.slice(0, k) } } // Push the current path onto the tokens. if (path) { tokens.push(path) path = '' pathEscaped = false } var repeat = modifier === '+' || modifier === '*' var optional = modifier === '?' || modifier === '*' var pattern = capture || group var delimiter = prev || defaultDelimiter
首先 pathEscaped 为false, !pathEscaped 所以为true,path = '/foo/', 因此 也有 path.length 的长度了,所以会进入if语句内部,var k = path.length - 1 = 4; var c = path[4] = '/'; var matches = whitelist ? whitelist.indexOf(c) > -1 : true; whitelist 是第三个参数 options对象的key, 由于第三个参数传了undefined进来,因此whitelist就为undefined; 因此 matches = true; if (matches) {} 这个判断语句会进入,prev = 4; path = '/foo/'.slice(0, 4) = '/foo';
再接着执行代码:
if (path) { tokens.push(path) path = '' pathEscaped = false }
因此 tokens = ['/foo']; 然后置空 path = ''; pathEscaped 设置为false; 继续定义如下:
var repeat = modifier === '+' || modifier === '*' var optional = modifier === '?' || modifier === '*' var pattern = capture || group var delimiter = prev || defaultDelimiter
从上面的代码分析可知 modifier = res[5] = undefined; 因此 repeat = false; optional = false; pattern = capture || group; capture 和 group 上面也是为undefined, 因此 pattern = undefined; var delimiter = prev || defaultDelimiter = '/';
最后执行
tokens.push({ name: name || key++, prefix: prev, delimiter: delimiter, optional: optional, repeat: repeat, pattern: pattern ? escapeGroup(pattern) : '[^' + escapeString(delimiter === defaultDelimiter ? delimiter : (delimiter + defaultDelimiter)) + ']+?' })
因此 tokens 最后变成如下数据:
tokens = [ "/foo", { name: 'id', delimiter: '/', optional: false, pattern: "[^\/]+?" prefix: "/" repeat: false } ]
最后代码,再如下:
// Push any remaining characters. if (path || index < str.length) { tokens.push(path + str.substr(index)) } return tokens
tokens最终的值变成如下:
var p = path + str.substr(index); p = '' + str.substr(8) = '/foo/:id'.substr(8) + '' = '';
最终 tokens = [ "/foo", { name: 'id', delimiter: '/', optional: false, pattern: "[^\/]+?" prefix: "/" repeat: false } ]
执行完 path 函数后,我们返回了 tokens的值了,接着我们继续调用 tokensToRegExp(parse(path, options), keys, options) 这个函数,我们会进入该函数的内部了。
首先代码初始化如下:
options = options || {} var strict = options.strict var start = options.start !== false var end = options.end !== false var delimiter = options.delimiter || DEFAULT_DELIMITER var endsWith = [].concat(options.endsWith || []).map(escapeString).concat('$').join('|') var route = start ? '^' : ''
首先我们传进来的 options = undefined; 因此 strict = undefined; start = true; end = true;
delimiter = DEFAULT_DELIMITER = '/';
endsWith = [].concat([]).map(escapeString).concat('$').join('|'). escapeString 代码如下:
function escapeString (str) { return str.replace(/([.+*?=^!:${}()[\]|/\\])/g, '\\$1') }
最后 endsWith = '$';
接着就是代码for循环了,如下代码:
for (var i = 0; i < tokens.length; i++) { var token = tokens[i] if (typeof token === 'string') { route += escapeString(token) } else { var capture = token.repeat ? '(?:' + token.pattern + ')(?:' + escapeString(token.delimiter) + '(?:' + token.pattern + '))*' : token.pattern if (keys) keys.push(token) if (token.optional) { if (!token.prefix) { route += '(' + capture + ')?' } else { route += '(?:' + escapeString(token.prefix) + '(' + capture + '))?' } } else { route += escapeString(token.prefix) + '(' + capture + ')' } } }
我们从上面可知 tokens 值返回的是如下:
tokens = [ "/foo", { name: 'id', delimiter: '/', optional: false, pattern: "[^\/]+?" prefix: "/" repeat: false } ]
因此第一次循环,判断tokens[0] 是否是一个字符串,是字符串的话,就直接进入了第一个if语句代码内部,因此route = escapeString(tokens[0]); 就调用escapeString 函数内部代码了,因此最终调用的代码:
'/foo'.replace(/([.+*?=^!:${}()[\]|/\\])/g, '\\$1'); 最后 route = "\/foo";
接着第二次循环,该第二个参数是一个对象,就会else语句代码内部,就会执行下面这段代码:
var capture = token.repeat ? '(?:' + token.pattern + ')(?:' + escapeString(token.delimiter) + '(?:' + token.pattern + '))*' : token.pattern if (keys) keys.push(token)
token.repeat 它的值为false的,因此 capture = token.pattern = "[^\/]+?";
token.optional = false, 因此也就进入else语句代码内部了,执行代码:
route += escapeString(token.prefix) + '(' + capture + ')';
最后route = escapeString('/') = "\/foo" + "\/" + '(' + capture + ')'; = "\/foo" + "\/" + "[^\/]+?"
= "^\/foo\/([^\/]+?)"
最后代码如下:
if (end) { if (!strict) route += '(?:' + escapeString(delimiter) + ')?' route += endsWith === '$' ? '$' : '(?=' + endsWith + ')' } else { var endToken = tokens[tokens.length - 1] var isEndDelimited = typeof endToken === 'string' ? endToken[endToken.length - 1] === delimiter : endToken === undefined if (!strict) route += '(?:' + escapeString(delimiter) + '(?=' + endsWith + '))?' if (!isEndDelimited) route += '(?=' + escapeString(delimiter) + '|' + endsWith + ')' } return new RegExp(route, flags(options))
如上可知 end 为true,因此会进入if语句,strict 为undefined,因此 !strict 就为true了,所以 route = '(?:' + escapeString(delimiter) + ')?' = "^\/foo\/([^\/]+?)(?:\/)?";
再接着 route += endsWith === '$' ? '$' : '(?=' + endsWith + ')'; 由上面可知 endsWith 就是等于 $; 因此会在尾部再加上 $ 符号,最后 route的值变为 "^\/foo\/([^\/]+?)(?:\/)?$";
最后会调用 return new RegExp(route, flags(options)); flags代码如下:
function flags (options) { return options && options.sensitive ? '' : 'i' }
因为 options 传入的参数为 undefined, 因此 最终 返回的是 i 了; 因此转为正则的话 new RegExp = (route, 'i') = "^\/foo\/([^\/]+?)(?:\/)?$/i"; i 的含义是不区分大小写。
如上就是 pathToRegExp 对字符串转换为正则表达式的全部过程,可以看到设计的复杂性及设计该代码的人的厉害。
注意:其他的方法源码我就不一一分析了,大家有空自己可以看下,目前的基本的公用函数都已经分析到了,最主要的公用函数就是:parse, tokensToRegExp等,当然里面还有类似这个函数 tokensToFunction 有兴趣的也可以分析下,发现分析源码很耗时。
二:pathToRegexp 的方法使用
该方法的作用是把字符串转为正则表达式。
如下demo:
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id');
console.log(t1); // /^\/foo\/([^\/]+?)(?:\/)?$/i
console.log(t1.exec('/foo/barrrr'));
/*
[
0: "/foo/barrrr"
1: "barrrr"
groups: undefined
index: 0
input: "/foo/barrrr"
]
*/
console.log(t1.exec('/ccccc')); // null
const t2 = pathToRegExp('aaa');
console.log(t2); // /^aaa(?:\/)?$/i
如上代码中的字符串 '/foo/:id', 中的 '/' 为分隔符,它把多个匹配模式分割开,因此会分成 foo 和 :id, 因此我们正则匹配 foo的时候是完全匹配的,因此正则 是 /^\/foo$/ 这样的。但是 :id 是命名参数,它可以匹配任何请求路径字符串。
在命名参数上,我们也可以使用一些修饰符,比如?, + , * 等
2.1 在字符串后面加上 * 号
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id*');
console.log(t1.exec('/foo/a/b/c/d'));
// 输出如下:
/*
[
0: "/foo/a/b/c/d"
1: "a/b/c/d"
groups: undefined
index: 0
input: "/foo/a/b/c/d"
]
*/
console.log(t1.exec('/foo'));
/*
输出如下:
[
0: "/foo"
1: undefined
groups: undefined
index: 0
input: "/foo"
]
*/
*表示我这个命名参数:id可以接收0个或多个匹配模式
2.2 在字符串后面加上 + 号
如下代码:
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id+');
console.log(t1.exec('/foo/a/b/c/d'));
// 输出如下:
/*
[
0: "/foo/a/b/c/d"
1: "a/b/c/d"
groups: undefined
index: 0
input: "/foo/a/b/c/d"
]
*/
console.log(t1.exec('/foo')); // null
+ 表示命名参数至少要接收一个匹配模式,也就是说 '/foo/' 后至少有一个匹配模式,如果没有的话,就会匹配失败。
2.3 在字符串后面加上 ? 号
const pathToRegExp = require('path-to-regexp');
const t1 = pathToRegExp('/foo/:id?');
console.log(t1.exec('/foo/a/b/c/d')); // null
console.log(t1.exec('/foo/a'));
/*
输出为
[
0: "/foo/a"
1: "a"
groups: undefined
index: 0
input: "/foo/a"
]
*/
console.log(t1.exec('/foo')); // null
/*
输出为:
[
0: "/foo"
1: undefined
groups: undefined
index: 0
input: "/foo"
]
*/
? 表示命名参数可以接收0个或1个匹配模式,如果为多个匹配模式的话,就会返回null.
2.4 pathToRegexp 方法的第二个参数keys,默认我们可以传入一个数组,默认为 []; 我们来看下
const pathToRegExp = require('path-to-regexp');
const keys = [];
var t1 = pathToRegExp('/:foo/icon-(\\d+).png',keys)
const t11 = t1.exec('/home/icon-123.png');
const t12 = t1.exec('/about/icon-abc.png');
console.log(t11);
/*
打印输出为:
[
0: "/home/icon-123.png"
1: "home"
2: "123"
groups: undefined
index: 0
input: "/home/icon-123.png"
]
*/
console.log(t12); // 输出为null
console.log(keys);
/*
输出值为:
[
{
delimiter: "/"
name: "foo"
optional: false
pattern: "[^\/]+?"
prefix: "/"
repeat: false
},
{
delimiter: "-"
name: 0
optional: false
pattern: "\d+"
prefix: "-"
repeat: false
}
]
*/
注意如上:未命名参数的keys.name为0。
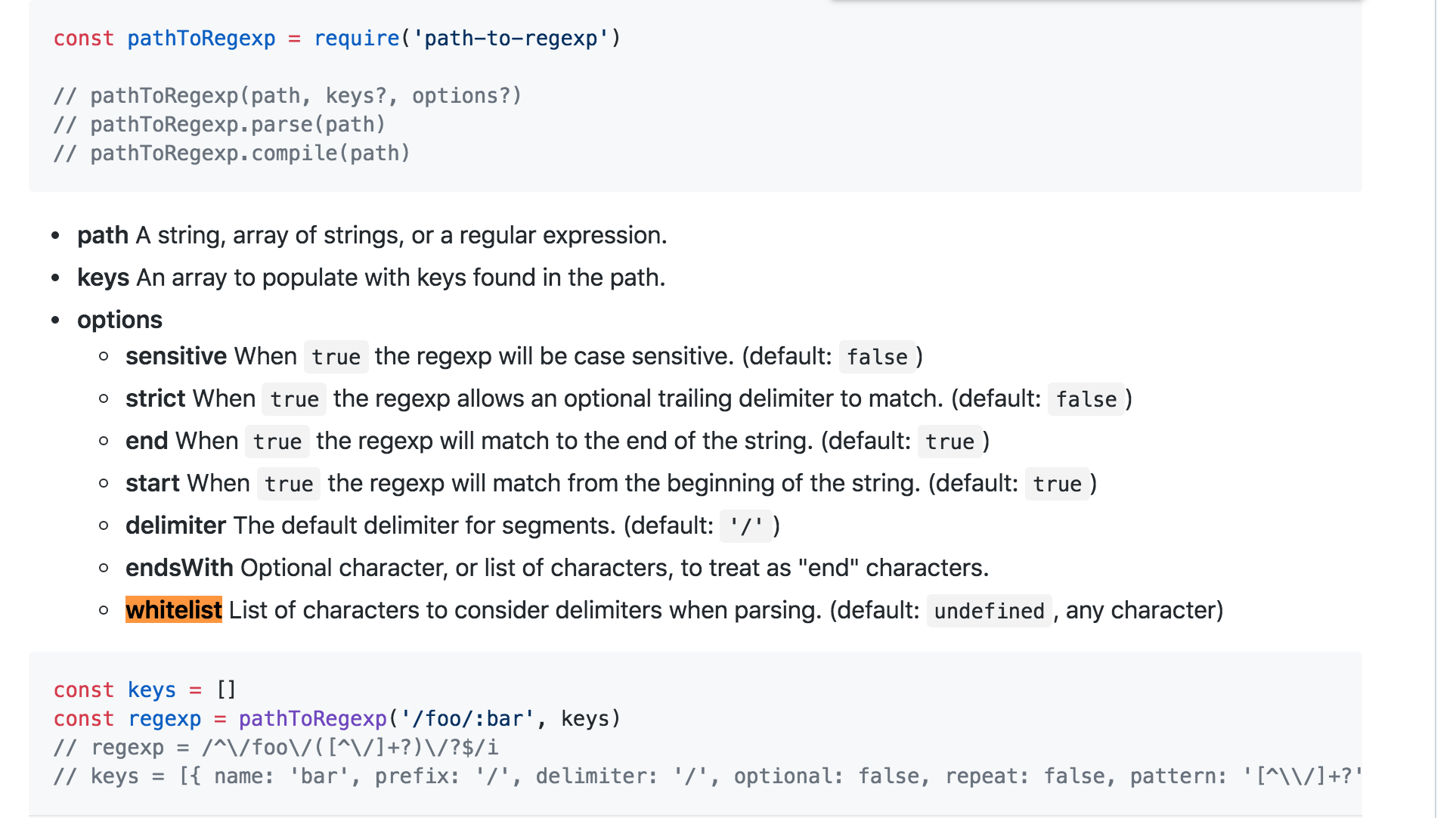
2.5 第三个参数options,为一个对象,包含如下对应的key值:
options = { delimiter: '', whitelist: '', strict: '', start: '', end: '', endsWith: '' }
我们可以看到官网对这些字段的含义解析如下:
更多请看github上的使用方式 (https://github.com/pillarjs/path-to-regexp)
注意:至于其他的 Parse方法使用及 Compile 方法的使用,tokensToRegExp 和 tokensToFunction 请看 github上的demo。
github上的源码及使用(https://github.com/pillarjs/path-to-regexp)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号