oracle命令1
基础查询
查询当前用户
show user;

查询当前用户下的表
select * from tab;

清屏
host cls;
clear;
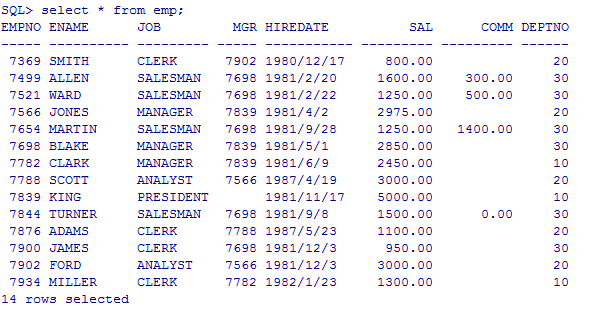
--查询所有的员工信息
select * from emp;
查询行宽
SQL> show linesize
linesize 80
SQL> --设置行宽
SQL> set linesize 120
SQL> --设置列宽
SQL> col ename for a8 (本意思是colum ename format a8 啊代表一个字符,8a代表8个字符)
SQL> col sal for 9999 (9代表一个数字,9999代表4个数字长度)
SQL> /
SQL优化的原则:
SQL> 1。尽量使用列名
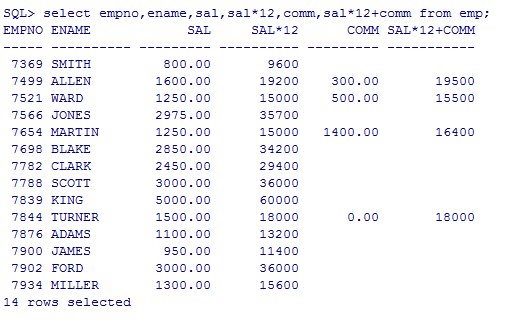
查询员工信息:员工号 姓名 月薪 年薪 奖金 年收入
select empno,ename,sal,sal*12,comm,sal*12+comm from emp;
SQL中的null
1、包含null的表达式都为null
2、null永远!=null
滤空
nvl(a,b) nvl2
如下
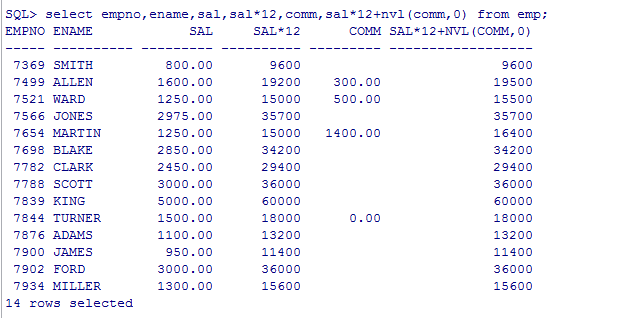
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
sal*12+nvl(comm,0) 如果comm为null那么初始值为0
针对上面第二点 null永远!=null
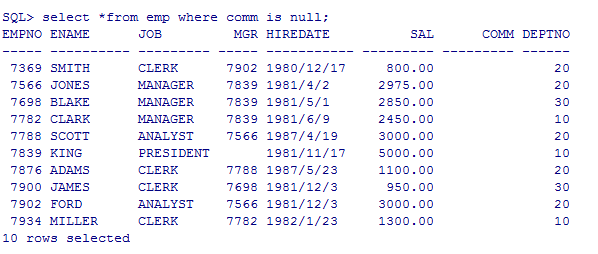
--查询奖金为null的员工
select * from emp where comm=null;则查不出来,需要用is关键字
select *from emp where comm is null;
ed可以进入编辑模式
中文乱码解决
查看编码
select userenv('language') from dual;


AMERICAN_AMERICA.ZHS16GBK
不然下面使用的别名中文就会变成???
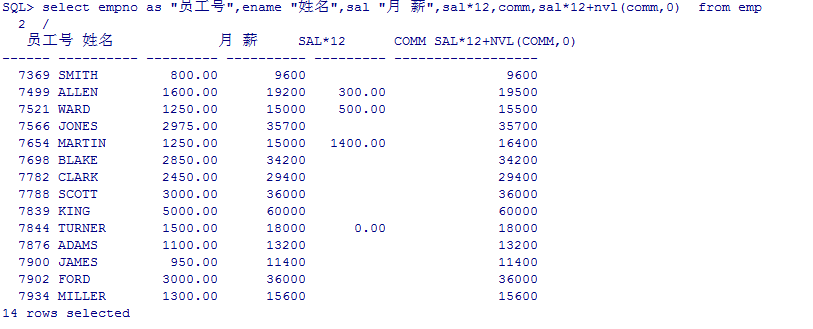
别名使用
select empno as "员工号",ename "姓名",sal "月 薪",sal*12,comm,sal*12+nvl(comm,0) from emp;
distinct 去掉重复记录
select distinct deptno from emp;

select distinct deptno,job from emp;
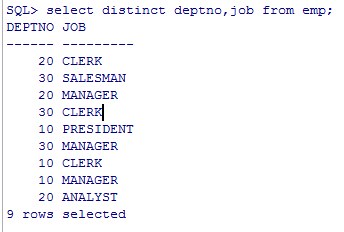
结论:distinct作用于后面所有的列
--连接符 ||
--concat函数
select concat('Hello',' World') from emp;
select concat('Hello',' World') from dual;
select 3+2 from dual;

--dual表:伪表
--伪列
select 'Hello'||' World' 字符串 from dual;

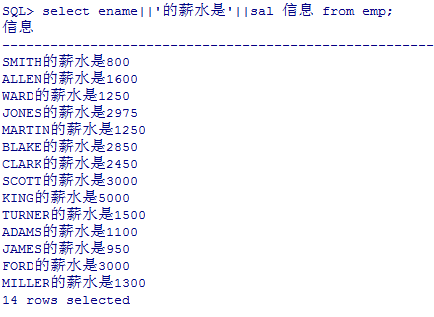
--查询员工信息:***的薪水是****
select ename||'的薪水是'||sal 信息 from emp;
过滤和排序
--查询10号部门的员工
select * from emp where deptno=10;

--字符串大小写敏感
--查询名叫KING的员工
select * from emp where ename='KING'

--日期格式敏感
查询日期格式
select * from v$nls_parameters;

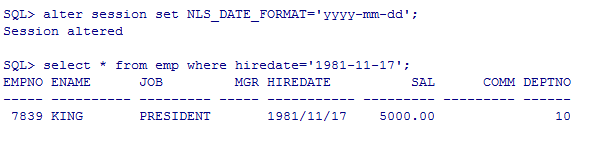
修改日期格式
alter session set NLS_DATE_FORMAT='yyyy-mm-dd';
--查询入职日期是17-11月-81的员工
select * from emp where hiredate='17-11月-81';
alter session set NLS_DATE_FORMAT='DD-MON-RR';改回
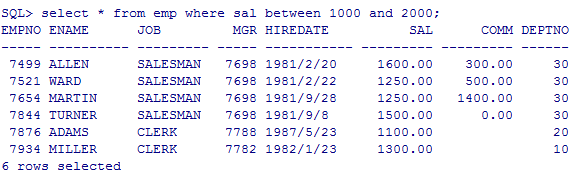
SQL> --between and
SQL> --查询薪水1000~2000之间的员工
--between and: 1.含有边界 2.小值在前 大值在后
select * from emp where sal between 1000 and 2000;
SQL> --in 在集合中
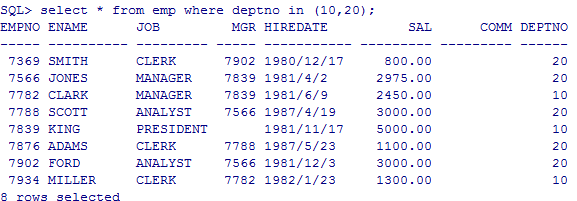
SQL> --查询10和20号部门的员工
select * from emp where deptno in (10,20);
SQL> --查询不是10和20号部门的员工
select * from emp where deptno not in (10,20);
之前对空值有2条这里加一条--null值 3、如果集合中含有null,不能使用not in;但可以使用in
--模糊查询
select * from emp where ename like 'S%';

select * from emp where ename like '____';

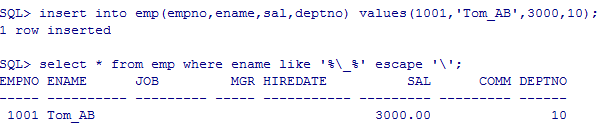
--转意字符
insert into emp(empno,ename,sal,deptno) values(1001,'Tom_AB',3000,10);
select * from emp where ename like '%\_%' escape '\';
--order by 后面 + 列、表达式、别名、序号
select empno,ename,sal,sal*12 from emp order by sal*12 desc;
select empno,ename,sal,sal*12 年薪 from emp order by 4 desc;
select empno,ename,sal,sal*12 年薪 from emp order by 年薪 desc;
--order by 作用于后面所有的列,先按照第一个列排序,再后面的列
--desc只作用于离他最近的列
select * from emp order by deptno desc,sal desc;

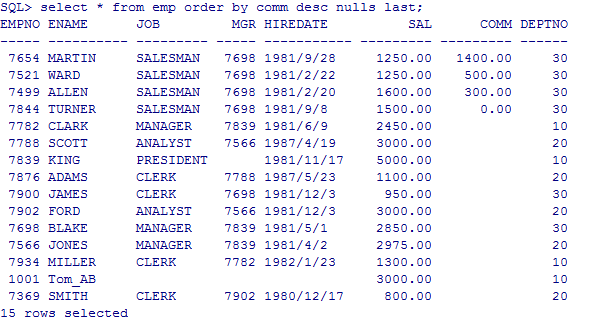
针对空值的 4. null的排序 null值最大 故查询需要放在最后
select * from emp order by comm desc nulls last;
单行函数
--字符函数
select lower('Hello World') 转小写,upper('Hello World') 转大写,initcap('hello world') 首字母大写 from dual;

--substr(a,b) 从a中,第b位开始取
select substr('Hello World',4) 子串 from dual;

--substr(a,b,c) 从a中,第b位开始取,取c位
select substr('Hello World',4,3) 子串 from dual;

--length 字符数 lengthb 字节数
select length('Hello World') 字符,lengthb('Hello World') 字节 from dual;
select length('北京') 字符,lengthb('北京') 字节 from dual;

--instr(a,b)--在a中,查找b
select instr('Hello World','ll') 位置 from dual;

--lpad 左填充 rpad 右填充
select lpad('abcd',10,'*') 左,rpad('abcd',10,'*') 右 from dual;

--trim 去掉前后指定的字符
select trim('H' from 'Hello WorldH') from dual;

--replace替换
select replace('Hello World','l','*') from dual;

--四舍五入
select round(45.926,2) 一,round(45.926,1) 二,round(45.926,0) 三,round(45.926,-1) 四,round(45.926,-2) 五 from dual;

--截断
select trunc(45.926,2) 一,trunc(45.926,1) 二,trunc(45.926,0) 三,trunc(45.926,-1) 四,trunc(45.926,-2) 五 from dual;

--当前时间
select sysdate from dual;
数字-字符串-日期转换
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;

select (sysdate-1) 昨天,sysdate 今天,(sysdate+1) 明天 from dual;

--计算员工的工龄:天 星期 月 年
select ename,hiredate,(sysdate-hiredate) 天,(sysdate-hiredate)/7 星期,(sysdate-hiredate)/30 月,(sysdate-hiredate)/365 年 from emp;
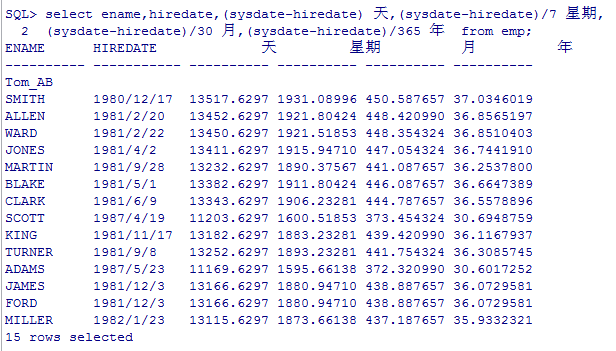
不允许日期 + 日期 没有意义
--months_between
select ename,hiredate,(sysdate-hiredate)/30 一,months_between(sysdate,hiredate) 二 from emp;

select add_months(sysdate,53) from dual;
--last_day
select last_day(sysdate) from dual;

--next_day
--下一个星期四
select next_day(sysdate,'星期四') from dual;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss"今天是"day') from dual;(日期转字符串)

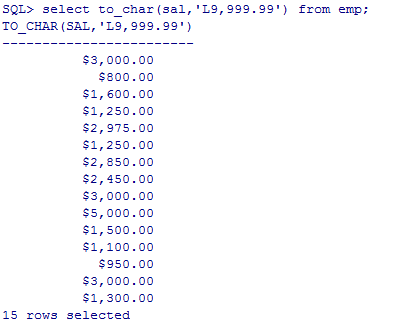
--查询员工的薪水:两位小数、千位符、本地货币代码(数字转字符串)
select to_char(sal,'L9,999.99') from emp;
--nvl2(a,b,c) 当a=null的时候,返回c;否则返回b
select sal*12+nvl2(comm,comm,0) from emp;

--nullif(a,b) 当a=b的时候,返回null;否则返回a
select nullif('abc','abc') 值 from dual;
select nullif('abc','abcd') 值 from dual;

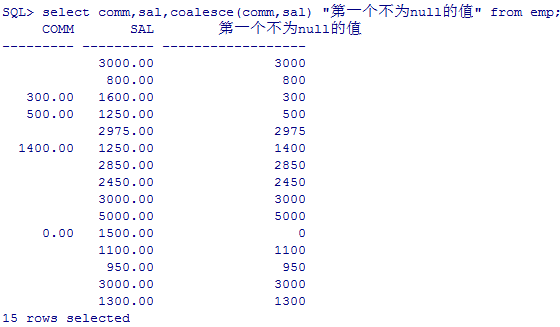
--coalesce 从左到右 找到第一个不为null的值
select comm,sal,coalesce(comm,sal) "第一个不为null的值" from emp;
--给员工涨工资,总裁1000 经理800 其他400
select ename,job,sal 涨前,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end 涨后
from emp;
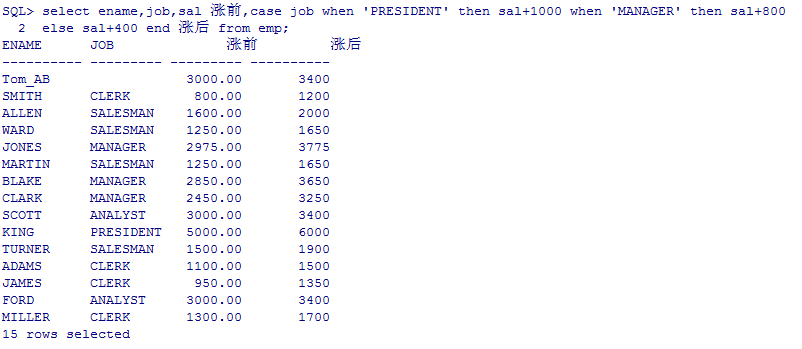
select ename,job,sal 涨前,decode(job,'PRESIDENT',sal+1000,'MANAGER',sal+800, sal+400) 涨后 from emp;

多行函数
--工资总额
select sum(sal) from emp;

--平均工资
select sum(sal)/count(*) 一,avg(sal) 二 from emp;

--null值 5. 组函数会自动滤空;
select count(*), count(comm) from emp;

select count(*), count(nvl(comm,0)) from emp;

--null值 5. 组函数会自动滤空;可以嵌套滤空函数来屏蔽他的滤空功能
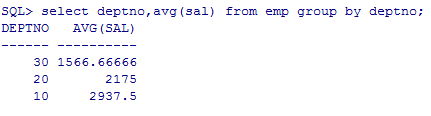
--每个部门的平均工资
select deptno,avg(sal) from emp group by deptno;
--多个列的分组
--多个列的分组: 先按照第一个列分组,如果相同,再第二个列分组,以此类推
select deptno,job,sum(sal) from emp group by deptno,job order by 1;

--where和having的区别:where不能使用多行函数
--查询10号部门的平均工资
select deptno,avg(sal) from emp group by deptno having deptno=10;
select deptno,avg(sal) from emp where deptno=10 group by deptno;

--SQL优化 3. 尽量使用where
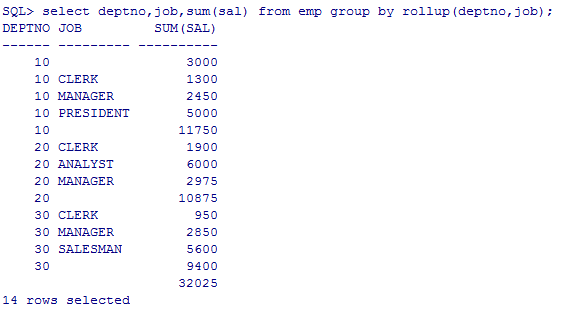
group by 的增强
select deptno,job,sum(sal) from emp group by rollup(deptno,job);
多表查询
--等值连接
--查询员工信息:员工号 姓名 月薪 部门名称
desc dept

select e.empno,e.ename,e.sal,d.dname from emp e,dept d where e.deptno=d.deptno;

--不等值连接
--查询员工信息:员工号 姓名 月薪 工资级别
select * from salgrade;

select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;

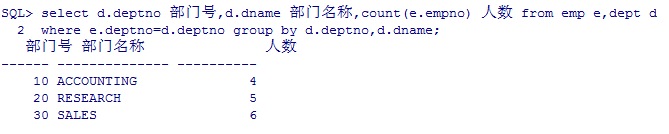
--外连接:
--按部门统计员工信息:部门号 部门名称 人数
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数 from emp e,dept d where e.deptno=d.deptno group by d.deptno,d.dname;
SQL> select * from dept;

SQL> select * from emp where deptno=40;
未选定行
希望把某些不成立的记录(40号部门),任然包含在最后的结果中 ---> 外连接
左外连接: 当where e.deptno=d.deptno不成立的时候,等号左边的表任然被包含在最后的结果中
写法:where e.deptno=d.deptno(+)
右外连接: 当where e.deptno=d.deptno不成立的时候,等号右边的表任然被包含在最后的结果中
写法:where e.deptno(+)=d.deptno
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数 from emp e,dept d where e.deptno(+)=d.deptno group by d.deptno,d.dname;

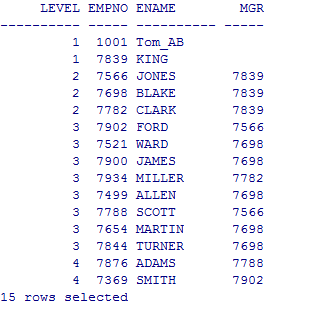
--层次查询
select level,empno,ename,mgr from emp connect by prior empno=mgr start with mgr is null order by 1;
子查询
--子查询所要解决的问题:不能一步求解
select * from emp where sal > (select sal from emp where ename='SCOTT');

可以在主查询的where select having from 后面使用子查询
不可以在group by使用子查询
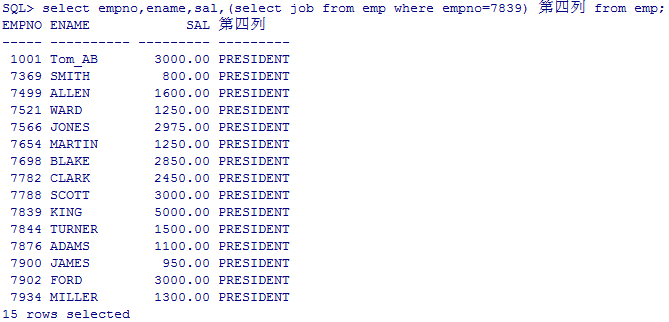
select empno,ename,sal,(select job from emp where empno=7839) 第四列 from emp;
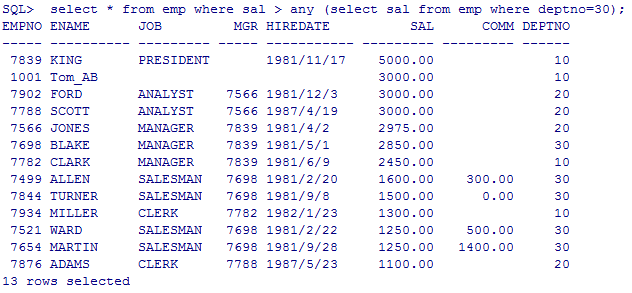
--any: 和集合中的任意一个值比较
--查询工资比30号部门任意一个员工高的员工信息
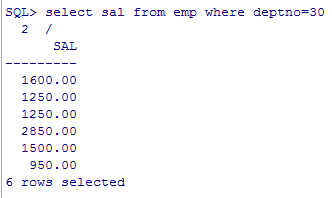
select * from emp where sal > any (select sal from emp where deptno=30);
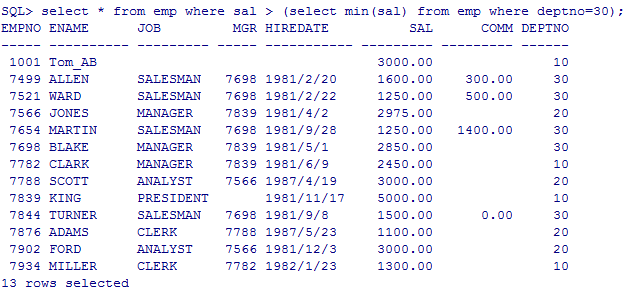
--min最小值
select * from emp where sal > (select min(sal) from emp where deptno=30);
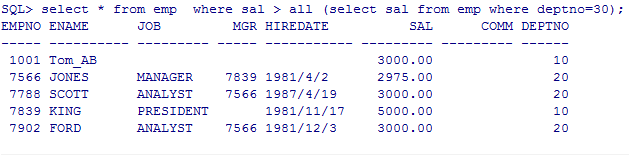
--all:和集合中的所有值比较
-查询工资比30号部门所有员工高的员工信息
select * from emp where sal > all (select sal from emp where deptno=30);
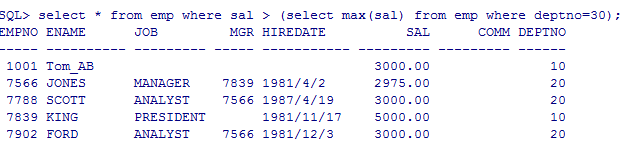
max最大值
select * from emp where sal > (select max(sal) from emp where deptno=30);
集合运算
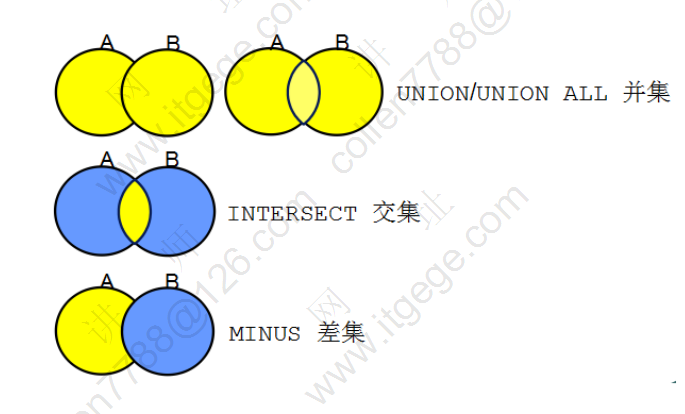



select * from emp where deptno=10 union select * from emp where deptno=20;

尽量不要使用集合运算
--oracle分页(Pageing Query)
select *
from (select rownum r,e1.*
from (select * from emp order by sal) e1
where rownum <=8
)
where r >=5;
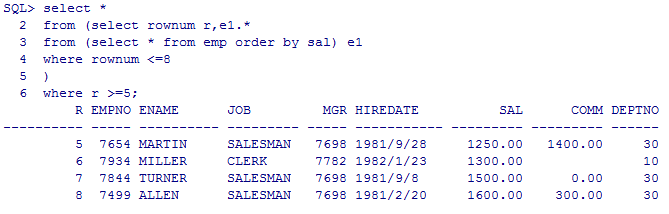
select * from (select e1.*,rownum r from (select * from emp order by sal) e1) where r>=5 and r<=8;

SQL的类型
1、DML(Data Manipulation Language 数据操作语言): select insert update delete
2、DDL(Data Definition Language 数据定义语言): create table,alter table,truncate table,drop table
create/drop view,sequnece,index,synonym(同义词)
3、DCL(Data Control Language 数据控制语言): grant(授权) revoke(撤销权限)

使用管理员给scott用户授权
grant connect,resource,create any view,create any synonym,create database link to scott;
--插入insert
insert into emp(empno,ename,sal,deptno) values(1002,'Tom',3000,10);
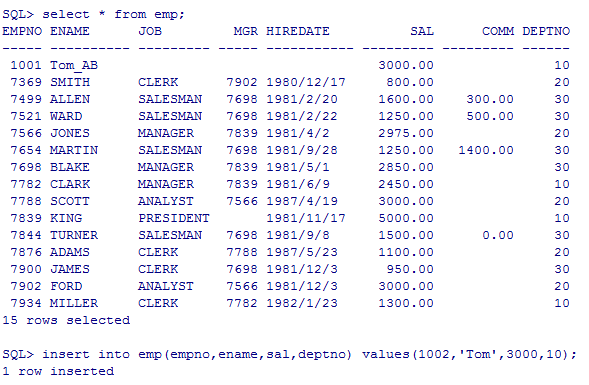
insert into emp(empno,ename,sal,deptno) values(&empno,&ename,&sal,&deptno);

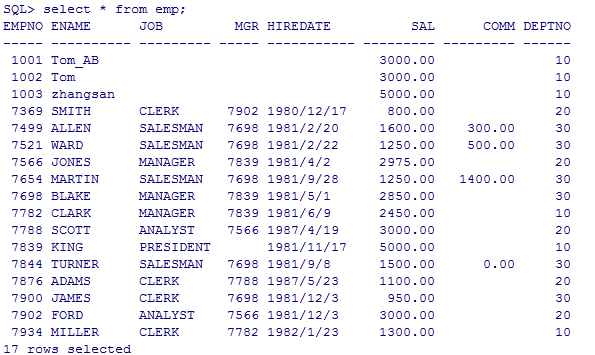
select empno,ename,sal,&t from emp;

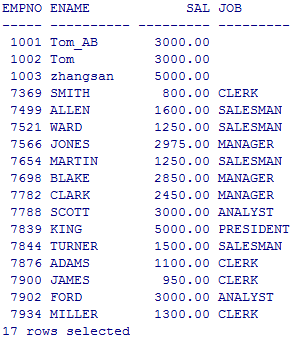
一次添加多行
create table emp10 as select * from emp where 1=2;
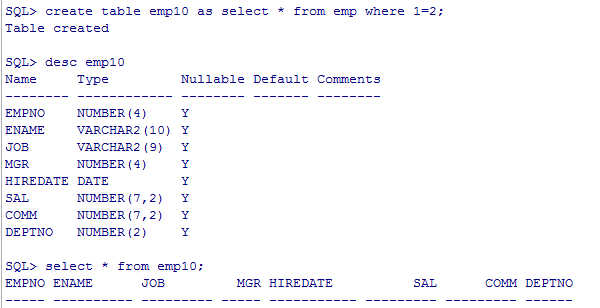
--一次性将emp中,所有10号部门的员工插入到emp10中
insert into emp10 select * from emp where deptno=10;
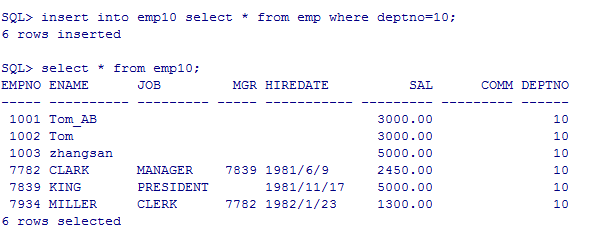


--flashback其实是一种恢复
--设置运行命令是是否显示语句SQL
SQL> set feedback off
--导入数据
SQL> @d:\testdelete.sql
SQL> select count(*) from testdelete;
显示sql执行时间
SQL> set timing on;
SQL> delete from testdelete;

SQL> set timing off;
清空表
SQL> drop table testdelete purge;
SQL> @d:\testdelete.sql
SQL> set timing on;
SQL> truncate table testdelete;
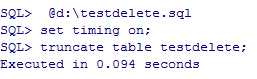
SQL> set timing off;
--原因:(非常非常非常)undo数据(还原数据)

SQL> create table testsavepoint (tid number,tname varchar2(20));
显示sql
SQL> set feedback on;
SQL> insert into testsavepoint values(1,'Tom');
已创建 1 行。
SQL> insert into testsavepoint values(2,'Mary');
已创建 1 行。
--创建保存点
SQL> savepoint a;
保存点已创建。
SQL> select * from testsavepoint;
SQL> insert into testsavepoint values(3,'Maee');
已创建 1 行。
SQL> select * from testsavepoint;
SQL> rollback to savepoint a;
SQL> select * from testsavepoint;
SQL> commit;
--事务处理集。(只读)
SQL> set transaction read only;
insert into testsavepoint values(3,'Maee');


您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号