大数据篇:Zookeeper
大数据篇:Zookeeper

1 Zookeeper概念
-
Zookeeper是什么
是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
-
Zookeeper特点

-
哪些系统用到了Zookeeper
- HDFS
- YARN
- Storm
- HBase
- Flume
- Dubbo(阿里巴巴)
2 Zookeeper基本原理
2.1 Zookeeper架构
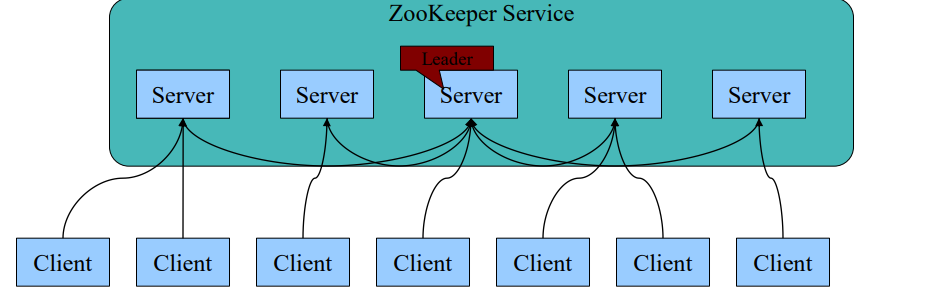
- 一个领导者(Leader)和多个跟随者(Follower)组成的集群,在启动时根据Paxos协议选举一个Leader。
- 集群中只要有半数以上的节点存活,Zookeeper集群就能正常服务。
- 全局一致性:每个Server保存一份相同的数据副本,Client无论链接到哪个Server,数据都是一致的。
- Leader根据Zab协议负责处理数据的更新等操作。
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行。
- 原子性:一次更新操作(可以是多个),当且仅当大多数Server在内存中成功修改数据,要么成功,要么失败。
- 实时性:在一定时间范围内,Client能读到最新数据。
2.2 Zookeeper角色
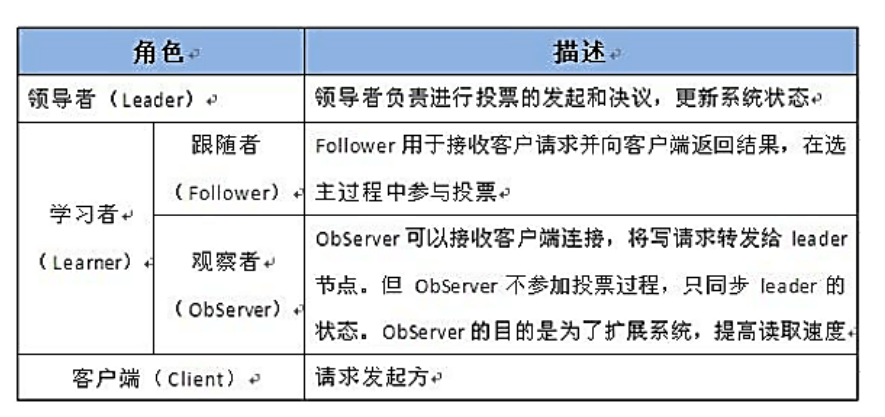
- Leader选举算法采用了Paxos协议;
- Paxos核心思想:当多数Server写成功,则任务数据写成功。
- 如果有3个Server,则需要2个写成功即可。
- 如果有5个Server,则需要3个写成功即可。
- Zookeeper Server数目一般为奇数
- 如果有3个Server,则最多允许1个Server挂掉。
- 如果有4个Server,则最多允许1个Server挂掉。
- 所以3台和4台效果一样,那么为什么选4台呢。
2.3 Zookeeper数据结构
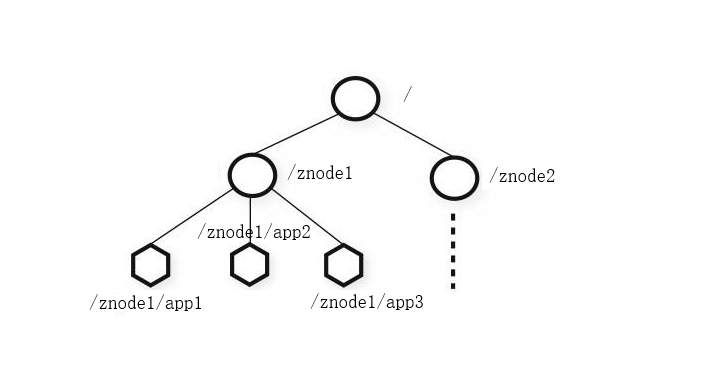
- Zookeeper数据模型结构与Unix文件系统很像,整体可以看做是树,每个节点为一个Znode,每一个Znode默认能存储1MB数据,每个Znode都可以通过其路径唯一标识。
- 和Unix不同的是,Znode可以存数据,又可有子节点。(不同于文件和文件夹的概念)
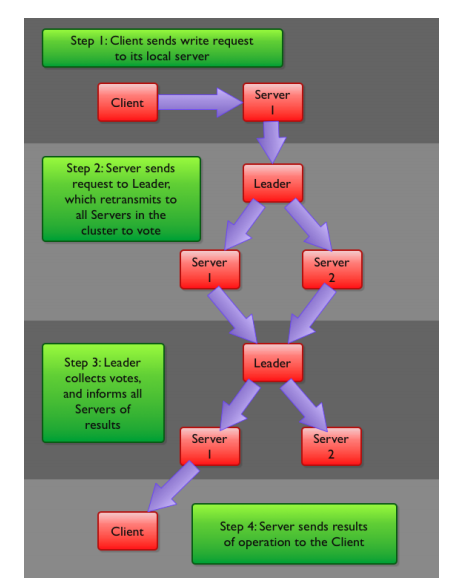
2.4 Zookeeper 数据写流程
3 Zookeeper应用场景
- 统一命名服务
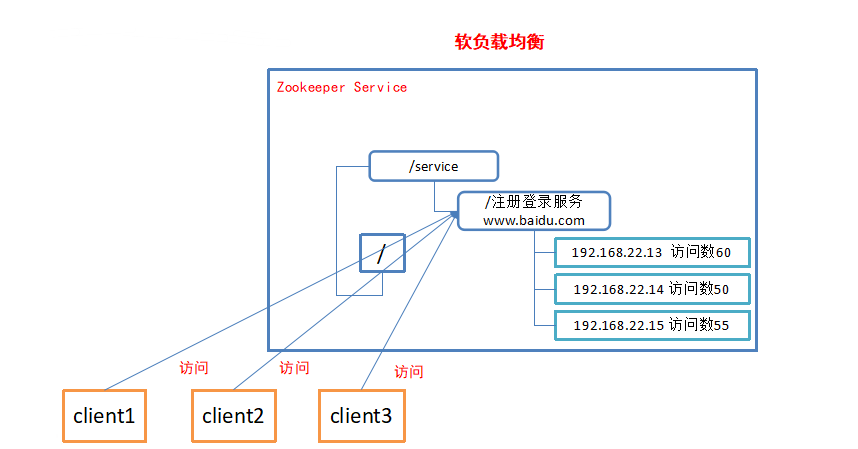
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
- 配置管理
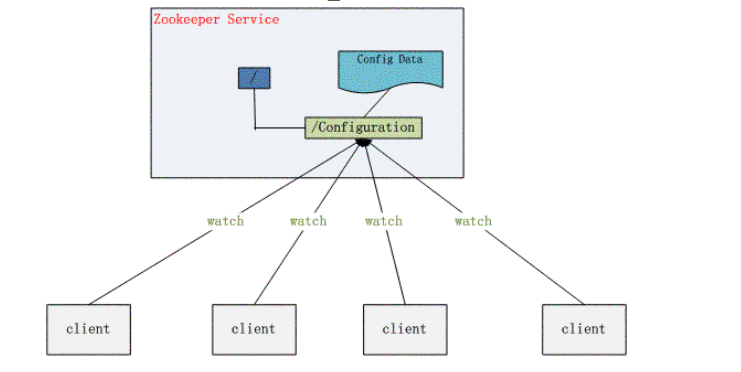
一个集群中,所有节点的配置信息是一致的,对配置文件修改后,希望能够快速同步到各个节点上。例如Hadoop。
- 集群管理
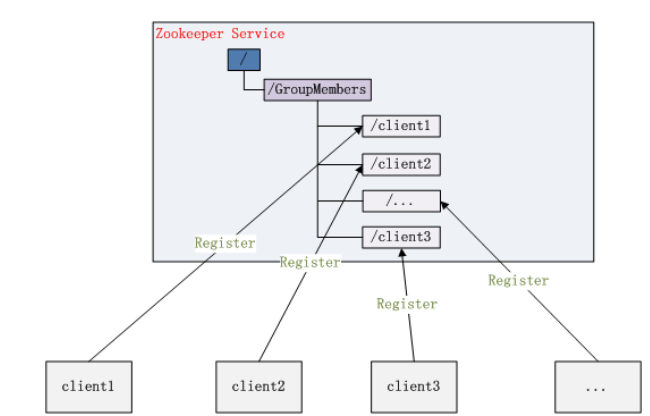
分布式环境中,实时掌握每个节点的状态是必要的。例如集群中的Master的监控和选举。
- 分布式通知/协调
分布式环境中,经常存在一个服务需要知道它所管理的子服务状态。例如NameNode需要知道DataNode状态。
- 分布式锁
多个客户端同时在Zookeeper上创建相同的znode,只有一个创建成功。
创建成功的客户端得到锁,其他客户端等待。
- 分布式队列
当一个列队的成员都聚齐时,这个列队才可用,否则一直等待所有成员到达,这种事同步列队。
列队按照FIFO方式进行入队和出队操作,例如实现生产者和消费者模型。
同步列队中一个Job由多个task组成,只有所有任务完成后,Job才运行完成。如:可以为Job创建一个/job的节点,在其下每完成一个task创建一个临时的znode,一旦临时节点数达到task总数,则Job运行完成。
4 zookeeper windows链接工具
下载地址:https://files.cnblogs.com/files/ttzzyy/ZooInspector.zip
- 下载解压
- 在此目录下java -jar zookeeper-dev-ZooInspector.jar或者点击start.bat文件启动。
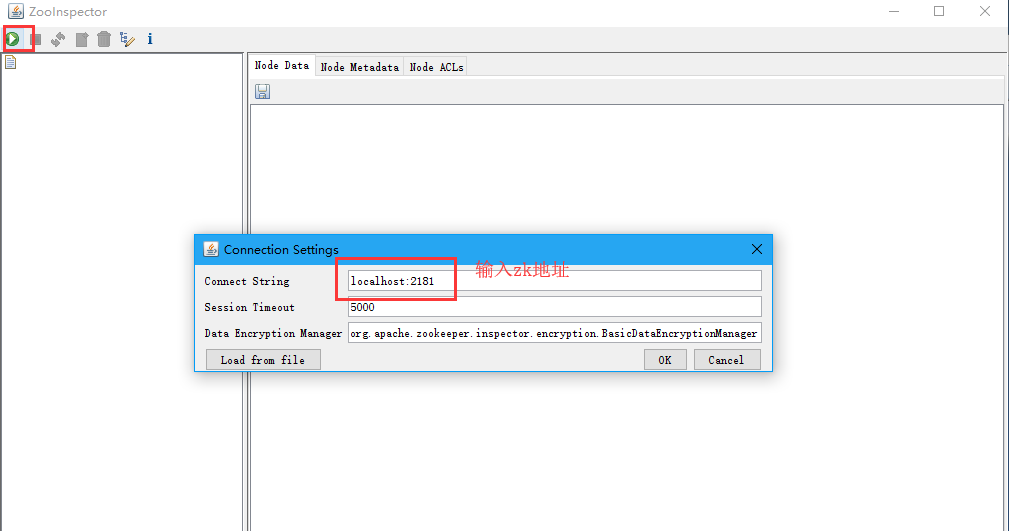
- 进行对zk的操作吧!
5 zookeeper命令行操作
- 运行 zkCli.sh 脚本进入命令行工具
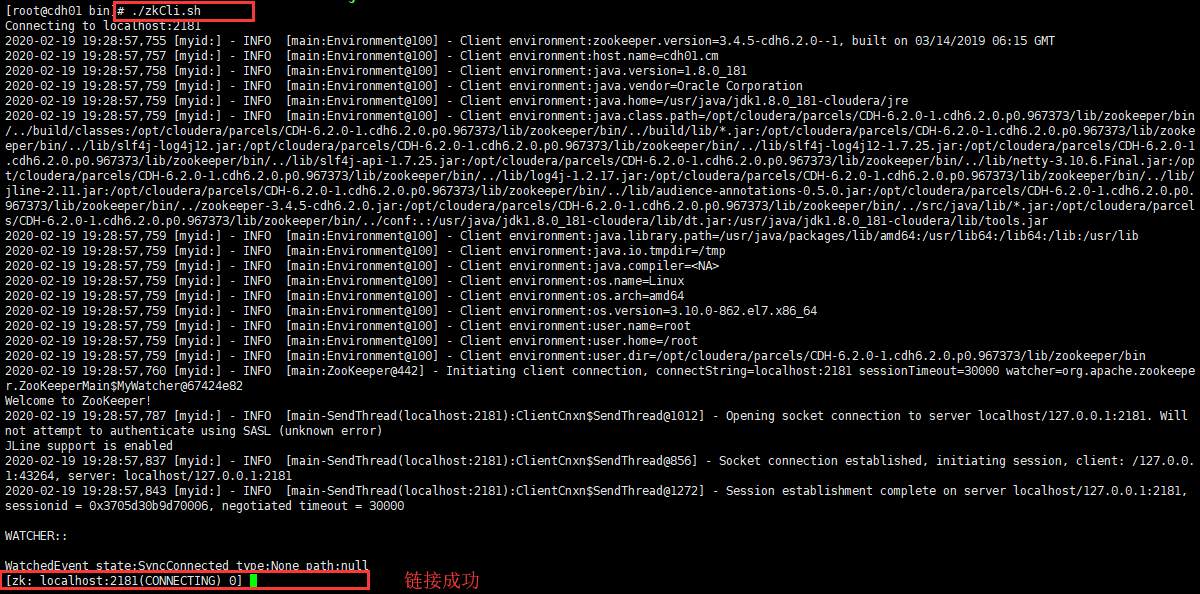
5.1 help 帮助命令

5.2 ls path [watch] 命令
- 查看znode中包含内容
- watch为观察的意思,观察此路径下的节点变化
5.2.1 普通查询

5.2.2 带监听的查询

- 另起一个客户端输入 create /test1 abcd

- 监听客户端变化

5.3 create [-s] [-e] path data acl 创建命令
- 创建命令
- -s 带序号的节点,把原节点的名字加一个全局增加的序号拼接在一起。
- -e 临时节点,未带此参数的节点全部为永久节点。
- -s -e 同时带上,创建有序的临时节点。
5.3.1 普通添加

5.3.2 带序号的节点添加

5.3.3 临时节点添加(当前会话退出就消失)

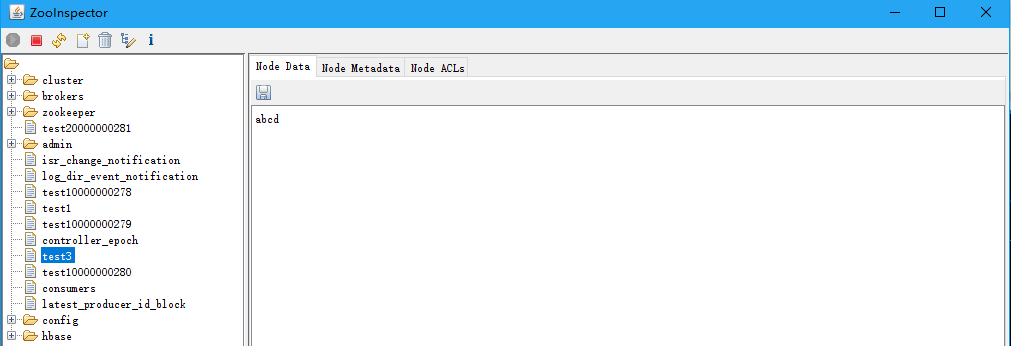
- 执行退出操作,再次查询消失

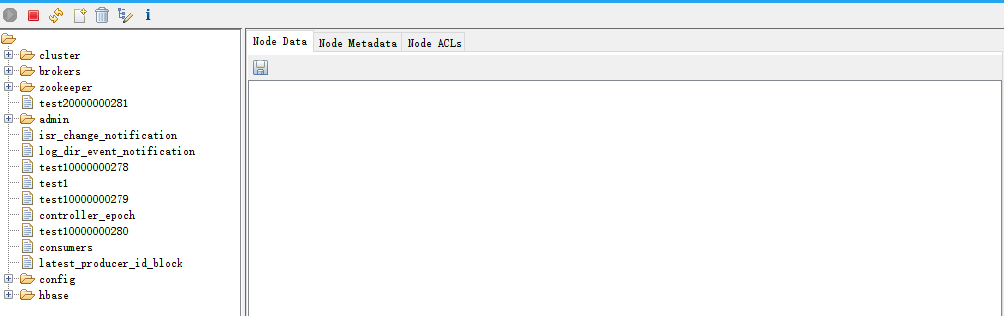
- 总结,zk共有4种节点
- PERSISTENT 无序永久节点
- PERSISTENT_SEQUENTIAL 有序永久节点
- EPHEMERAL 无序临时节点
- EPHEMERAL_SEQUENTIAL 有序临时节点
5.4 get path [watch] 获取命令
- 查看znode内容
- watch为观察的意思,观察此路径下的节点变化
5.4.1 普通获取

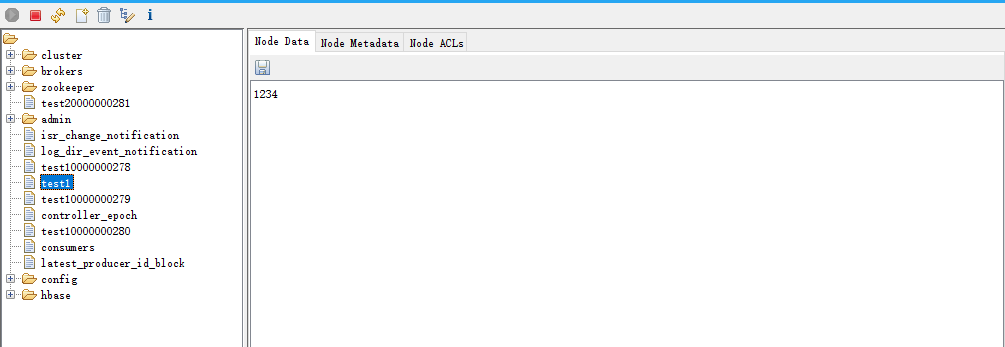
5.4.2 带监听的获取

- 另起一个客户端输入 set/test1 1234

- 监听客户端变化

5.5 stat path [watch] 查看节点状态

创建节点的事务zxid cZxid = 0xa00000117
- zk就是靠事务ID保证每批次操作的顺序执行。
- ZXID是一个64位的数字,低32代表一个单调递增的计数器,高32位代表Leader周期
- 高32位:a0000 ----Leader的周期编号+myid的组合
- 低32位:0117 ----事务的自增序列(单调递增的序列)只要客户端有请求,就+1
- 每次修改Zookeeper状态都会受到一个zxid形式的时间戳,也就是zk的事务ID,事务ID是zk中所有修改的总的次序。
- 每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1发生在zxid2之前。
创建时间 ctime = Wed Feb 19 19:42:34 CST 2020
最后更新的事务zxid mZxid = 0xa00000511
最后更新的时间 mtime = Wed Feb 19 20:48:02 CST 2020
最后更新的子节点zxid pZxid = 0xa00000524
子节点修改次数 cversion = 2
数据被修改的次数 dataVersion = 3
访问控制列表变化号 aclVersion = 0
如果是临时节点,这个是znode拥有者sessionID,如果是永久节点则为0 ephemeralOwner = 0x0
数据长度 dataLength = 4
子节点数量 numChildren = 0
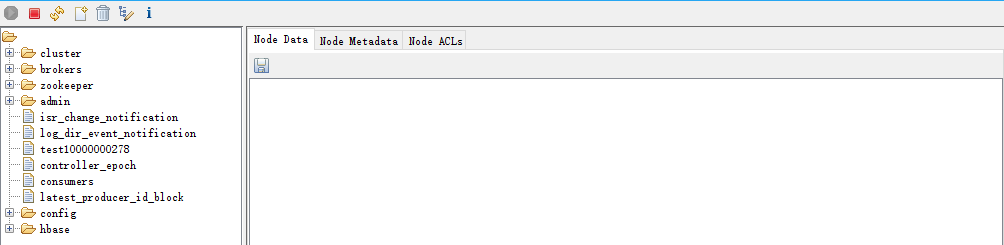
5.6 删除命令
-
delete path [version] 普通删除
-
rmr path 递归删除


6 zookeeper-java-api应用
- maven pom参考
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5-cdh6.2.0</version>
</dependency>
| 功能 | 描述 | |
|---|---|---|
| create | 在本地目录树中创建一个节点 | |
| delete | 删除一个节点 | |
| exists | 测试本地是否存在目标节点 | |
| get/set data | 从目标节点上读取 / 写数据 | |
| get/set ACL | 获取 / 设置目标节点访问控制列表信息 | |
| get children | 检索一个子节点上的列表 | |
| sync | 等待要被传送的数据 |
6.1 增删改查demo
import org.apache.zookeeper.*;
import java.io.IOException;
public class SimpleDemo {
// 会话超时时间
private static final int SESSION_TIMEOUT = 2000;
// 链接集群地址
private static final String CONNECT_ADDRESS = "192.168.37.10:2181,192.168.37.11:2181,192.168.37.12:2181";
// 创建 ZooKeeper 实例
ZooKeeper zk;
// 创建 Watcher 实例
Watcher wh = event -> System.out.println(event.toString());
// 初始化 ZooKeeper 实例
private void createZKInstance() throws IOException {
zk = new ZooKeeper(CONNECT_ADDRESS, SimpleDemo.SESSION_TIMEOUT, this.wh);
}
private void ZKOperations() throws IOException, InterruptedException, KeeperException {
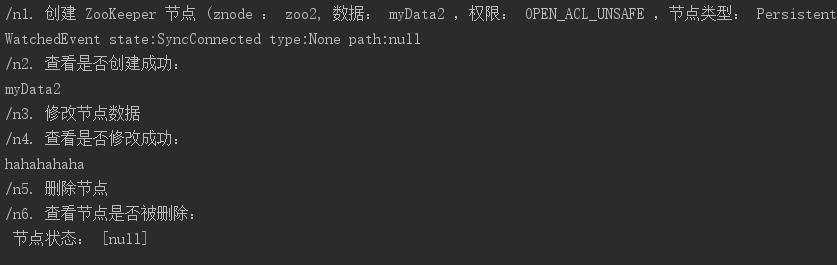
System.out.println("/n1. 创建 ZooKeeper 节点 (znode : zoo2, 数据: myData2 ,权限: OPEN_ACL_UNSAFE ,节点类型: Persistent");
zk.create("/zoo2", "myData2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("/n2. 查看是否创建成功: ");
System.out.println(new String(zk.getData("/zoo2", false, null)));
System.out.println("/n3. 修改节点数据 ");
zk.setData("/zoo2", "hahahahaha".getBytes(), -1);
System.out.println("/n4. 查看是否修改成功: ");
System.out.println(new String(zk.getData("/zoo2", false, null)));
System.out.println("/n5. 删除节点 ");
zk.delete("/zoo2", -1);
System.out.println("/n6. 查看节点是否被删除: ");
System.out.println(" 节点状态: [" + zk.exists("/zoo2", false) + "]");
}
private void ZKClose() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
SimpleDemo dm = new SimpleDemo();
dm.createZKInstance();
dm.ZKOperations();
dm.ZKClose();
}
}
- 效果:
6.2 服务器上下线动态感知程序demo
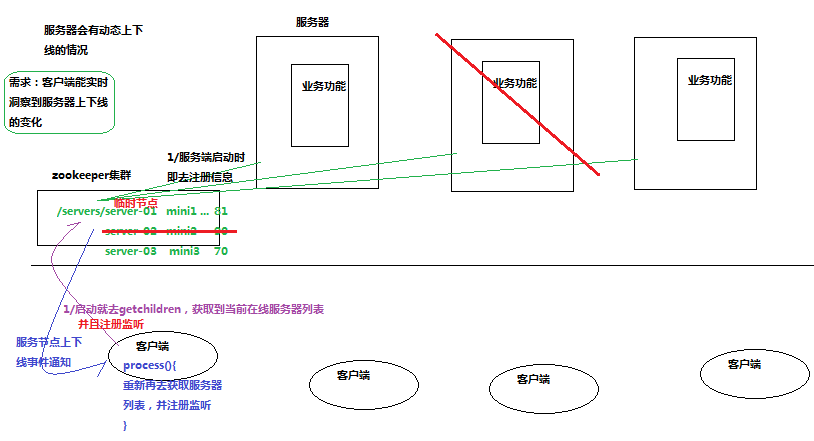
- AppServer.java
import org.apache.zookeeper.*;
public class AppServer {
private String groupNode = "sgroup";
private String subNode = "sub";
/**
* 连接zookeeper
*
* @param address server的地址
*/
public void connectZookeeper(String address) throws Exception {
ZooKeeper zk = new ZooKeeper(
"192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181",
5000, new Watcher() {
public void process(WatchedEvent event) {
// 不做处理
}
});
// 在"/sgroup"下创建子节点
// 子节点的类型设置为EPHEMERAL_SEQUENTIAL, 表明这是一个临时节点, 且在子节点的名称后面加上一串数字后缀
// 将server的地址数据关联到新创建的子节点上
String createdPath = zk.create("/" + groupNode + "/" + subNode, address.getBytes("utf-8"),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("create: " + createdPath);
}
/**
* server的工作逻辑写在这个方法中
* 此处不做任何处理, 只让server sleep
*/
public void handle() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 在参数中指定server的地址
if (args.length == 0) {
System.err.println("The first argument must be server address");
System.exit(1);
}
AppServer as = new AppServer();
as.connectZookeeper(args[0]);
as.handle();
}
}
- AppClient.java
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.ArrayList;
import java.util.List;
public class AppClient {
private String groupNode = "sgroup";
private ZooKeeper zk;
private Stat stat = new Stat();
private volatile List<String> serverList;
/**
* 连接zookeeper
*/
public void connectZookeeper() throws Exception {
zk = new ZooKeeper("192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181", 5000, new Watcher() {
public void process(WatchedEvent event) {
// 如果发生了"/sgroup"节点下的子节点变化事件, 更新server列表, 并重新注册监听
if (event.getType() == Event.EventType.NodeChildrenChanged
&& ("/" + groupNode).equals(event.getPath())) {
try {
updateServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
updateServerList();
}
/**
* 更新server列表
*/
private void updateServerList() throws Exception {
List<String> newServerList = new ArrayList<String>();
// 获取并监听groupNode的子节点变化
// watch参数为true, 表示监听子节点变化事件.
// 每次都需要重新注册监听, 因为一次注册, 只能监听一次事件, 如果还想继续保持监听, 必须重新注册
List<String> subList = zk.getChildren("/" + groupNode, true);
for (String subNode : subList) {
// 获取每个子节点下关联的server地址
byte[] data = zk.getData("/" + groupNode + "/" + subNode, false, stat);
newServerList.add(new String(data, "utf-8"));
}
// 替换server列表
serverList = newServerList;
System.out.println("server list updated: " + serverList);
}
/**
* client的工作逻辑写在这个方法中
* 此处不做任何处理, 只让client sleep
*/
public void handle() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
AppClient ac = new AppClient();
ac.connectZookeeper();
ac.handle();
}
}
-
开启client

-
加入节点名称参数开启server


-
client端变化

-
再次加入节点名称参数开启server

-
client端变化

-
关闭其中一个服务client端变化

-
关闭另一个服务client端变化
6.3 分布式共享锁demo

- DistributedClient.java
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedClient {
// 超时时间
private static final int SESSION_TIMEOUT = 5000;
// zookeeper server列表
private String hosts = "192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181";
private String groupNode = "locks";
private String subNode = "sub";
private ZooKeeper zk;
// 当前client创建的子节点
private String thisPath;
// 当前client等待的子节点
private String waitPath;
private CountDownLatch latch = new CountDownLatch(1);
/**
* 连接zookeeper
*/
public void connectZookeeper() throws Exception {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, new Watcher() {
public void process(WatchedEvent event) {
try {
// 连接建立时, 打开latch, 唤醒wait在该latch上的线程
if (event.getState() == Event.KeeperState.SyncConnected) {
latch.countDown();
}
// 发生了waitPath的删除事件
if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitPath)) {
doSomething();
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
// 等待连接建立
latch.await();
// 创建子节点
thisPath = zk.create("/" + groupNode + "/" + subNode, null, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// wait一小会, 让结果更清晰一些
Thread.sleep(10);
// 注意, 没有必要监听"/locks"的子节点的变化情况
List<String> childrenNodes = zk.getChildren("/" + groupNode, false);
// 列表中只有一个子节点, 那肯定就是thisPath, 说明client获得锁
if (childrenNodes.size() == 1) {
doSomething();
} else {
String thisNode = thisPath.substring(("/" + groupNode + "/").length());
// 排序
Collections.sort(childrenNodes);
int index = childrenNodes.indexOf(thisNode);
if (index == -1) {
// never happened
} else if (index == 0) {
// inddx == 0, 说明thisNode在列表中最小, 当前client获得锁
doSomething();
} else {
// 获得排名比thisPath前1位的节点
this.waitPath = "/" + groupNode + "/" + childrenNodes.get(index - 1);
// 在waitPath上注册监听器, 当waitPath被删除时, zookeeper会回调监听器的process方法
zk.getData(waitPath, true, new Stat());
}
}
}
private void doSomething() throws Exception {
try {
System.out.println("gain lock: " + thisPath);
Thread.sleep(2000);
// do something
} finally {
System.out.println("finished: " + thisPath);
// 将thisPath删除, 监听thisPath的client将获得通知
// 相当于释放锁
zk.delete(this.thisPath, -1);
}
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10; i++) {
new Thread() {
public void run() {
try {
DistributedClient dl = new DistributedClient();
dl.connectZookeeper();
} catch (Exception e) {
e.printStackTrace();
}
}
}.start();
}
Thread.sleep(Long.MAX_VALUE);
}
}
- 测试:

7 Paxos算法(帕索斯算法)
参考:
https://www.cnblogs.com/xuwc/p/9029882.html
- 维基的简介:Paxos算法是莱斯利·兰伯特(Leslie Lamport,就是 LaTeX 中的"La",此人现在在微软研究院)于1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。
- 在节点很多的情况下,如果要收敛,也就是确定一个一致的值,需要不停的循环,那么必然会造成速度慢。
7.1 生活中的例子
假如有一群驴友要决定中秋节去旅游,这群驴友分布在全国各地,假定一共25个 人,分别在不同的省,要决定到底去拉萨、昆明、三亚等等哪个地点(会合时间中秋节已经定了,此时需要决定旅游地)。最直接的方式当然就是建一个QQ群,大家都在里面投票,按照少数服从多数的原则。这种方式类似于“共享内存”实现的一致性,实现起来简单,但Paxos算法不是这种场景,因为Paxos算法认为这种方式有一个很大的问题,就是QQ服务器挂掉怎么办?Paxos的原则是容错性一定要很强。所以,Paxos的场景类似于这25个人相互之间只能发短信,需要解决的核心问题是,哪怕任意的一部分人(Paxos的目的其实是少于半数的人)“失联”了,其它人也能够在会合地点上达成一致。好了,怎么设计呢?
这25个人找了另外的5个人(当然这5个人可以从25个人中选,这里为了描述方便,就单拿出另外5个人),比如北京、上海、广州、深圳、成都的5个人,25个人都给他们发短信,告诉自己倾向的旅游地。这5个人相互之间可以并不通信, 只接受25个人发过来的短信。这25个人我们称为驴友,那5个人称为队长。
先来看驴友的逻辑。驴友可以给任意5个队长都发短信,发短信的过程分为两个步骤:
第一步(申请阶段):询问5个队长,试图与队长沟通旅游地。因为每个队长一直会收到不同驴友的短信,不能跟多个驴友一起沟通,在任何时刻只能跟一个驴友沟通,按照什么原则才能做到公平公正公开呢?这些短信都带有发送时间,队长采用的原则是同意与短信发送时间最新的驴友沟通,如果出现了更新的短信,则与短信更新的驴友沟通。总之,作为一个有话语权的人,只有时刻保持倾听最新的呼声,才能做出最明智的选择。在驴友发出短信后,等着队长。某些队长可能会说,你这条短信太老了,我不与你沟通;有些队长则可能返回说,你的短信是我收到的最新的,我同意跟你沟通。对于后面这些队长,还得返回自己决定的旅游地。关于队长是 怎么决定旅游地的,后面再说。
对于驴友来说,第一步必须至少有半数以上队长都同意沟通了,才能进入下一步。否则,你连沟通的资格都没有,一直在那儿狂发吧。你发的短信更新,你获得沟通权的可能性才更大。。。。。。
因为至少有半数以上队长(也就是3个队长以上)同意,你才能与队长们进行实质性的沟通,也就是进入第二步;而队长在任何时候只能跟1个驴友沟通,所以,在任何时候,不可能出现两个驴友都达到了这个状态。。。当然,你可以通过狂发短信把沟通权抢了。。。。
对于获得沟通权的那个驴友(称为A),那些队长会给他发送他们自己决定的旅游地(也可能都还没有决定)。可以看出,各个队长是自己决定旅游地的,队长之间无需沟通。
第二步(沟通阶段):这个幸运的驴友收到了队长们给他发的旅游地,可能有几种情况:
第一种情况:跟A沟通的队长们(不一定是全部5个队长,但是半数以上)全部都还没有决定到底去那儿旅游,此时驴友A心花怒放,给这些队长发第二条短信,告诉他们自己希望的旅游地(比如马尔代夫);
可能会收到两种结果:一是半数以上队长都同意了,于是表明A建议的马尔代夫被半数以上队长都 同意了,整个决定过程完毕了,其它驴友迟早会知道这个消息的,A先去收拾东西准备去马尔代夫;除此之外,表明失败。可能队长出故障了,比如某个队长在跟女 朋友打电话等等,也可能被其它驴友抢占沟通权了(因为队长喜新厌旧嘛,只有要更新的驴友给自己发短信,自己就与新人沟通,A的建议队长不同意)等等。不管 怎么说,苦逼的A还得重新从第一步开始,重新给队长们发短信申请。
第二种情况:至少有一个队长已经决定旅游地了,A可能会收到来自不同队长决定的多 个旅游地,这些旅游地是不同队长跟不同驴友在不同时间上做出的决定,那么,A会先看一下,是不是有的旅游地已经被半数以上队长同意了(比如3个队长都同意 去三亚,1个同意去昆明,另外一个没搭理A),如果出现了这种情况,那就别扯了,说明整个决定过程已经达成一致了,收拾收拾准备去三亚吧,结束了;如果都 没有达到半数以上(比如1个同意去昆明,1个同意去三亚,2个同意去拉萨,1个没搭理我),A作为一个高素质驴友,也不按照自己的意愿乱来了(Paxos 的关键所在,后者认同前者,否则整个决定过程永无止境),虽然自己原来可能想去马尔代夫等等。就给队长们发第二条短信的时候,告诉他们自己希望的旅游地, 就是自己收到的那堆旅游地中最新决定的那个。(比如,去昆明那个是北京那个队长前1分钟决定的,去三亚的决定是上海那个队长1个小时之前做出来的,于是顶 昆明)。驴友A的想法是,既然有队长已经做决定了,那我就干脆顶最新那个决定。
从上面的逻辑可以看出,一旦某个时刻有半数以上队长同意了某个地点比如昆明,紧跟着后面的驴友B继续发短信时,如果获得沟通权,因为半数以上队长都同意与B沟通了,说明B收到了来自半数以上队长发过来的消息,B必然会收到至少一个队长给他发的昆明这个结果(否则说明半数以上队长都没有同意昆明这个结果,这显然与前面的假设矛盾),B于是会顶这个最新地点,不会更改,因为后面的驴友都会顶昆明,因此同意昆明的队长越来越多,最终必然达成一致。
看完了驴友的逻辑,那么队长的逻辑是什么呢?
队长的逻辑比较简单。
在申请阶段,队长只会选择与最新发申请短信的驴友沟通,队长知道自己接收到最新短信的时间,对于更老的短信,队长不会搭理;队长同意沟通了的话,会把自己决定的旅游地(或者还没决定这一信息)发给驴友。
在沟通阶段,驴友C会把自己希望的旅游地发过来(同时会附加上自己申请短信的时 间,比如3分钟前),所以队长要检查一下,如果这个时间(3分钟前)确实是当前自己最新接收到申请短信的时间(说明这段时间没有驴友要跟自己沟通),那 么,队长就同意驴友C的这个旅游地了(比如昆明,哪怕自己1个小时前已经做过去三亚的决定,谁让C更新呢,于是更新为昆明);如果不是最新的,说明这3分 钟内又有其它驴友D跟自己申请了,因为自己是个喜新厌旧的家伙,同意与D沟通了,所以驴友C的决定自己不会同意,等着D一会儿要发过来的决定吧。
Paxos的基本思想大致就是上面的过程。可以看出,其实驴友的策略才是Paxos的关键。让我们来跟理论对应一下。
Paxos主要用于保证分布式存储中副本(或者状态)的一致性。副本要保持一致, 那么,所有副本的更新序列就要保持一致。因为数据的增删改查操作一般都存在多个客户端并发操作,到底哪个客户端先做,哪个客户端后做,这就是更新顺序。如 果不是分布式,那么可以利用加锁的方法,谁先申请到锁,谁就先操作。但是在分布式条件下,存在多个副本,如果依赖申请锁+副本同步更新完毕再释放锁,那么 需要有分配锁的这么一个节点(如果是多个锁分配节点,那么又出现分布式锁管理的需求,把锁给哪一个客户端又成为一个难点),这个节点又成为单点,岂不是可 靠性不行了,失去了分布式多副本的意义,同时性能也很差,另外,还会出现死锁等情况。
所以,说来说去,只有解决分布式条件下的一致性问题,似乎才能解决本质问题。
如上面的例子,Paxos解决这一问题利用的是选举,少数服从多数的思想,只要 2N+1个节点中,有N个以上同意了某个决定,则认为系统达到了一致,并且按照Paxos原则,最终理论上也达到了一致,不会再改变。这样的话,客户端不 必与所有服务器通信,选择与大部分通信即可;也无需服务器都全部处于工作状态,有一些服务器挂掉,只有保证半数以上存活着,整个过程也能持续下去,容错性 相当好。因此,以前看有的博客说在部署ZooKeeper这种服务的时候,需要奇数台机器,这种说法当然有一定来源背景,比如如果是5台,那么任意客户端 与任意其中3台达成一致就相当于投票结束,不过6台有何不可?只是此时需要与4台以上达成一致。
Paxos中的Acceptor就相当于上面的队长,Proposer就相当于上 面的驴友,epoch编号就相当于例子中申请短信的发送时间。关于Paxos的正式描述已经很多了,这里就不复述了,关于Paxos正确性的证明,因为比 较复杂,以后有时间再分析。另外,Paxos最消耗时间的地方就在于需要半数以上同意沟通了才能进入第二步,试想一下,一开始,所有驴友就给队长狂发短 信,每个队长收到的最新短信的是不同驴友,这样,就难以达到半数以上都同意与某个驴友沟通的状态,为了减小这个时间,Paxos还有Fast Paxos的改进等等,有空再分析。
倒是有一些问题可以思考一下:在Paxos之前,或者说除了Chubby,ZooKeeper这些系统,其它分布式系统同样面临这样的一致性问题,比如HDFS、分布式数据库、Amazon的Dynamo等等,解决思路又不同,有空再进行对比分析。
最后谈谈一致性这个名词。
关于Paxos说的一致性,个人理解是指冗余副本(或状态等,但都是因为存在冗余)的一致性。这与关系型数据库中ACID的一致性说的不是一个东西。在关系数据库里,可以连副本都没有,何谈副本的一致性?按照经典定义,ACID中的C指的是在一个事务中,事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。那么,什么又是一致性状态呢,这跟业务约束有关系,比如经典的转账事务,事务处理完毕后,不能出现一个账户钱被扣了,另一个账户的钱没有增加的情况,如果两者加起来的钱还是等于转账前的钱,那么就是一致性状态。
从很多博文来看,对这两种一致性往往混淆起来。另外,CAP原则里面所说的一致 性,个人认为是指副本一致性,与Paxos里面的一致性接近。都是处理“因为冗余数据的存在而需要保证多个副本保持一致”的问题,NoSQL放弃的强一致 性也是指副本一致性,最终一致性也是指副本达到完全相同存在一定延时。
当然,如果数据库本身是分布式的,且存在冗余副本,则除了解决事务在业务逻辑上的一致性问题外,同时需要解决副本一致性问题,此时可以利用Paxos协议。但解决了副本一致性问题,还不能完全解决业务逻辑一致性;如果是分布式数据库,但并不存在副本的情况,事务的一致性需要根据业务约束进行设计。
另外,谈到Paxos时,还会涉及到拜占庭将军问题,它指的是在存在消息丢失的不 可靠信道上试图通过消息传递的方式达到一致性是不可能的。Paxos本身就是利用消息传递方式解决一致性问题的,所以它的假定是信道必须可靠,这里的可 靠,主要指消息不会被篡改。消息丢失是允许的。
关于一致性、事务的ACID,CAP,NoSQL等等问题,以后再详细分析。本文的描述也许可能存在一些举例不太恰当的地方,如果错误,欢迎批评指正。
7.2 Paxos协议解释
-
Paxos算法的目的
-
Paxos算法的目的是为了解决分布式环境下一致性的问题。
-
多个节点并发操纵数据,如何保证在读写过程中数据的一致性,并且解决方案要能适应分布式环境下的不可靠性(系统如何就一个值达到统一)
-
-
Paxos的两个组件
- Proposer:提议发起者,处理客户端请求,将客户端的请求发送到集群中,以便决定这个值是否可以被批准。
- Acceptor:提议批准者,负责处理接收到的提议,他们的回复就是一次投票。会存储一些状态来决定是否接收一个值
-
Paxos有两个原则
- 安全原则---保证不能做错的事:
- 针对某个实例的表决只能有一个值被批准,不能出现一个被批准的值被另一个值覆盖的情况;(假设有一个值被多数Acceptor批准了,那么这个值就只能被学习)
- 每个节点只能学习到已经被批准的值,不能学习没有被批准的值。
- 存活原则---只要有多数服务器存活并且彼此间可以通信,最终都要做到的下列事情:
- 最终会批准某个被提议的值;
- 一个值被批准了,其他服务器最终会学习到这个值。
- 安全原则---保证不能做错的事:
7.3 Paxos流程图

1).获取一个proposal number, n;
2).提议者向所有节点广播prepare(n)请求;
3).接收者(Acceptors比较善变,如果还没最终认可一个值,它就会不断认同提案号最大的那个方案)比较n和minProposal,如果n>minProposal,表示有更新的提议minProposal=n;如果此时该接受者并没有认可一个最终值,那么认可这个提案,返回OK。如果此时已经有一个accptedValue, 将返回(acceptedProposal,acceptedValue);
4).提议者接收到过半数请求后,如果发现有acceptedValue返回,表示有认可的提议,保存最高acceptedProposal编号的acceptedValue到本地;
5).广播accept(n,value)到所有节点;
6).接收者比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否则,拒绝并且返回minProposal;
7).提议者接收到过半数请求后,如果发现有返回值>n,表示有更新的提议,跳转1(重新发起提议);否则value达成一致。
7.4 Paxos议案ID生成算法
在Google的Chubby论文中给出了这样一种方法:假设有n个proposer,每个编号为ir(0<=ir<n),proposal编号的任何值s都应该大于它已知的最大值,并且满足: s % n = ir => s = m * n + ir;
proposer已知的最大值来自两部分:proposer自己对编号自增后的值和接收到acceptor的拒绝后所得到的值。
例: 以3个proposer P1、P2、P3为例,开始m=0,编号分别为0,1,2。
1) P1提交的时候发现了P2已经提交,P2编号为1 >P1的0,因此P1重新计算编号:new P1 = 1 * 3 + 1 = 4;
2) P3以编号2提交,发现小于P1的4,因此P3重新编号:new P3 = 1 * 3+2 = 5。
7.5 Paxos原理
-
任意两个法定集合,必定存在一个公共的成员。该性质是Paxos有效的基本保障
-
活锁
- 当某一proposer提交的proposal被拒绝时,可能是因为acceptor 承诺返回了更大编号的proposal,因此proposer提高编号继续提交。 如果2个proposer都发现自己的编号过低转而提出更高编号的proposal,会导致死循环,这种情况也称为活锁。
- 比如说当此时的 proposer1提案是3, proposer2提案是4, 但acceptor承诺的编号是5,那么此时proposer1,proposer2 都将提高编号假设分别为6,7,并试图与accceptor连接,假设7被接受了,那么提案5和提案6就要重新编号提交,从而不断死循环。
-
异常情况——持久存储
- 在算法执行的过程中会产生很多的异常情况:proposer宕机,acceptor在接收proposal后宕机,proposer接收消息后宕机,acceptor在accept后宕机,learn宕机,存储失败,等等。
- 为保证paxos算法的正确性,proposer、aceptor、learn都实现持久存储,以做到server恢复后仍能正确参与paxos处理。
- propose存储已提交的最大proposal编号、决议编号(instance id)。
- acceptor存储已承诺(promise)的最大编号、已接受(accept)的最大编号和value、决议编号。
- learn存储已学习过的决议和编号
具体实例:(假设的3军问题)
1) 1支红军在山谷里扎营,在周围的山坡上驻扎着3支蓝军;
2) 红军比任意1支蓝军都要强大;如果1支蓝军单独作战,红军胜;如果2支或以上蓝军同时进攻,蓝军胜;
3) 三支蓝军需要同步他们的进攻时间;但他们惟一的通信媒介是派通信兵步行进入山谷,在那里他们可能被俘虏,从而将信息丢失;或者为了避免被俘虏,可能在山谷停留很长时间;
4) 每支军队有1个参谋负责提议进攻时间;每支军队也有1个将军批准参谋提出的进攻时间;很明显,1个参谋提出的进攻时间需要获得至少2个将军的批准才有意义;
5) 问题:是否存在一个协议,能够使得蓝军同步他们的进攻时间?
接下来以两个假设的场景来演绎BasicPaxos;参谋和将军需要遵循一些基本的规则
1) 参谋以两阶段提交(prepare/commit)的方式来发起提议,在prepare阶段需要给出一个编号;
2) 在prepare阶段产生冲突,将军以编号大小来裁决,编号大的参谋胜出;
3) 参谋在prepare阶段如果收到了将军返回的已接受进攻时间,在commit阶段必须使用这个返回的进攻时间;
7.5.1 先后提议的场景
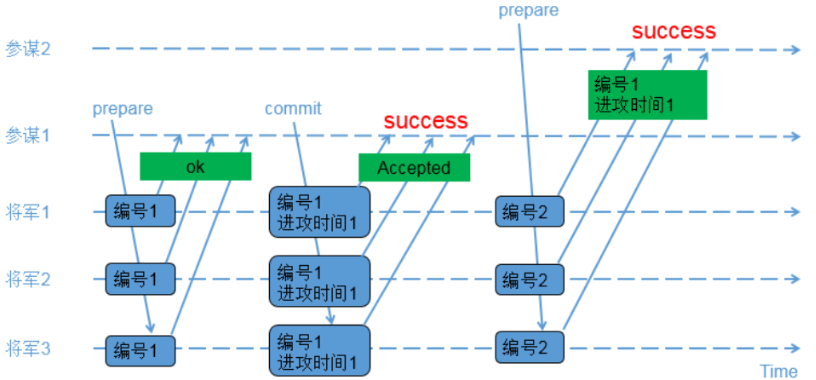
参与角色:
proposer(提议者):参谋1,参谋2
acceptor(决策者):将军1,将军2,将军3
1)参谋1发起提议,派通信兵带信给3个将军,内容为(编号1);
2)3个将军收到参谋1的提议,由于之前还没有保存任何编号,因此把(编号1)保存下来,避免遗忘;同时让通信兵带信回去,内容为(ok);
3)参谋1收到至少2个将军的回复,再次派通信兵带信给3个将军,内容为(编号1,进攻时间1);
4)3个将军收到参谋1的时间,把(编号1,进攻时间1)保存下来,避免遗忘;同时让通信兵带信回去,内容为(Accepted);
5)参谋1收到至少2个将军的(Accepted)内容,确认进攻时间已经被大家接收;
6)参谋2发起提议,派通信兵带信给3个将军,内容为(编号2);
7)3个将军收到参谋2的提议,由于(编号2)比(编号1)大,因此把(编号2)保存下来,避免遗忘;又由于之前已经接受参谋1的提议,因此让通信兵带信回去,内容为(编 号1,进攻时间1);
8)参谋2收到至少2个将军的回复,由于回复中带来了已接受的参谋1的提议内容,参谋2因此不再提出新的进攻时间,接受参谋1提出的时间;
7.5.2 交叉场景
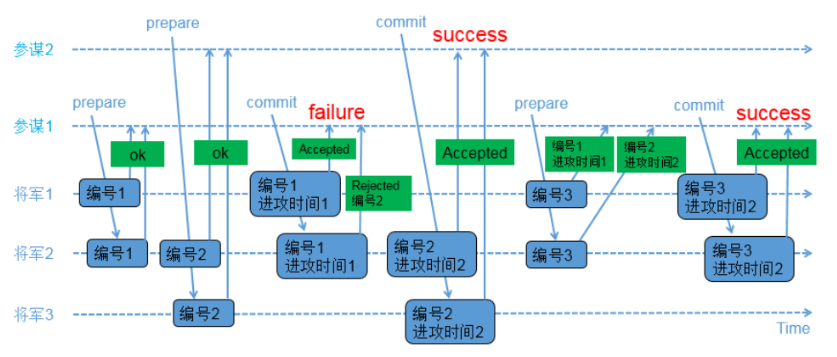
参与角色:
proposer(提议者):参谋1,参谋2
acceptor(决策者):将军1,将军2,将军3
1)参谋1发起提议,派通信兵带信给3个将军,内容为(编号1);
2)3个将军的情况如下
a)将军1和将军2收到参谋1的提议,将军1和将军2把(编号1)记录下来,如果有其他参谋提出更小的编号,将被拒绝;同时让通信兵带信回去,内容为(ok);
b)负责通知将军3的通信兵被抓,因此将军3没收到参谋1的提议;3)参谋2在同一时间也发起了提议,派通信兵带信给3个将军,内容为(编号2);
4)3个将军的情况如下
a)将军2和将军3收到参谋2的提议,将军2和将军3把(编号2)记录下来,如果有其他参谋提出更小的编号,将被拒绝;同时让通信兵带信回去,内容为(ok);
b)负责通知将军1的通信兵被抓,因此将军1没收到参谋2的提议;
5)参谋1收到至少2个将军的回复,再次派通信兵带信给有答复的2个将军,内容为(编号1,进攻时间1);
6)2个将军的情况如下
a)将军1收到了(编号1,进攻时间1),和自己保存的编号相同,因此把(编号1,进攻时间1)保存下来;同时让通信兵带信回去,内容为(Accepted);
b)将军2收到了(编号1,进攻时间1),由于(编号1)小于已经保存的(编号2),因此让通信兵带信回去,内容为(Rejected,编号2);
7)参谋2收到至少2个将军的回复,再次派通信兵带信给有答复的2个将军,内容为(编号2,进攻时间2);
8)将军2和将军3收到了(编号2,进攻时间2),和自己保存的编号相同,因此把(编号2,进攻时间2)保存下来,同时让通信兵带信回去,内容为(Accepted);
9)参谋2收到至少2个将军的(Accepted)内容,确认进攻时间已经被多数派接受;10)参谋1只收到了1个将军的(Accepted)内容,同时收到一个(Rejected,编号2);参谋1重新发起提议,派通信兵带信给3个将军,内容为(编号3);
11)3个将军的情况如下
a)将军1收到参谋1的提议,由于(编号3)大于之前保存的(编号1),因此把(编号3)保存下来;由于将军1已经接受参谋1前一次的提议,因此让通信兵带信回去,内容为(编号1,进攻时间1);
b)将军2收到参谋1的提议,由于(编号3)大于之前保存的(编号2),因此把(编号3)保存下来;由于将军2已经接受参谋2的提议,因此让通信兵带信回去,内容为(编号2,进攻时间2);
c)负责通知将军3的通信兵被抓,因此将军3没收到参谋1的提议;12)参谋1收到了至少2个将军的回复,比较两个回复的编号大小,选择大编号对应的进攻时间作为最新的提议;参谋1再次派通信兵带信给有答复的2个将军,内容为(编号3,进攻时间2);
13)将军1和将军2收到了(编号3,进攻时间2),和自己保存的编号相同,因此保存(编号3,进攻时间2),同时让通信兵带信回去,内容为(Accepted);
14)参谋1收到了至少2个将军的(accepted)内容,确认进攻时间已经被多数派接受。
7.6 paxos算法
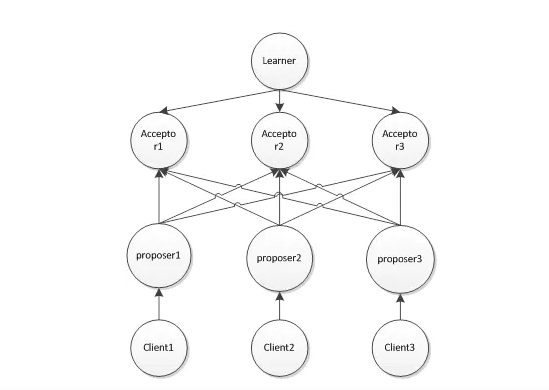
- 在paxos算法中,分为4种角色:
- Proposer :提议者
- Acceptor:决策者
- Client:产生议题者
- Learner:最终决策学习者
上面4种角色中,提议者和决策者是很重要的,其他的2个角色在整个算法中应该算做 打酱油的,Proposer就像Client的使者,由Proposer使者拿着Client的议题去向Acceptor提议,让Acceptor来决 策。这里上面出现了个新名词:最终决策。现在来系统的介绍一下paxos算法中所有的行为:
Proposer提出议题
Acceptor初步接受 或者 Acceptor初步不接受
如果上一步Acceptor初步接受则Proposer再次向Acceptor确认是否最终接受
Acceptor 最终接受 或者Acceptor 最终不接受
上面Learner最终学习的目标是Acceptor们最终接受了什么议题?注意,这里是向所有Acceptor学习,如果有多数派个Acceptor最终接受了某提议,那就得到了最终的结果,算法的目的就达到了。画一幅图来更加直观:
例子paxos的算法的流程(2阶段提交)
有2个Client(老板,老板之间是竞争关系)和3个Acceptor(政府官员):
现在需要对一项议题来进行paxos过程,议题是“A项目我要中标!”,这里的“我”指每个带着他的秘书Proposer的Client老板。
Proposer当然听老板的话了,赶紧带着议题和现金去找Acceptor政府官员。
作为政府官员,当然想谁给的钱多就把项目给谁。Proposer-1小姐带着现金同时找 到了Acceptor-1~Acceptor-3官员,1与2号官员分别收取了10比特币,找到第3号官员时,没想到遭到了3号官员的鄙视,3号官员告诉 她,Proposer-2给了11比特币。不过没关系,Proposer-1已经得到了1,2两个官员的认可,形成了多数派(如果没有形成多数 派,Proposer-1会去银行提款在来找官员们给每人20比特币,这个过程一直重复每次+10比特币,直到多数派的形成),满意的找老板复命去了,但 是此时Proposer-2保镖找到了1,2号官员,分别给了他们11比特币,1,2号官员的态度立刻转变,都说Proposer-2的老板懂事,这下子 Proposer-2放心了,搞定了3个官员,找老板复命去了,当然这个过程是第一阶段提交,只是官员们初步接受贿赂而已。故事中的比特币是编号,议题是 value。
这个过程保证了在某一时刻,某一个proposer的议题会形成一个多数派进行初步支持;华丽的,第一阶段结束
现在进入第二阶段提交,现在proposer-1小姐使用分身术(多线 程并发)分了3个自己分别去找3位官员,最先找到了1号官员签合同,遭到了1号官员的鄙视,1号官员告诉他proposer-2先生给了他11比特币,因 为上一条规则的性质proposer-1小姐知道proposer-2第一阶段在她之后又形成了多数派(至少有2位官员的赃款被更新了);此时她赶紧去提 款准备重新贿赂这3个官员(重新进入第一阶段),每人20比特币。刚给1号官员20比特币, 1号官员很高兴初步接受了议题,还没来得及见到2,3号官员的时候
这时proposer-2先生也使用分身术分别找3位官员(注意这里是 proposer-2的第二阶段),被第1号官员拒绝了告诉他收到了20比特币,第2,3号官员顺利签了合同,这时2,3号官员记录client-2老板 用了11比特币中标,因为形成了多数派,所以最终接受了Client2老板中标这个议题,对于proposer-2先生已经出色的完成了工作;
这时proposer-1小姐找到了2号官员,官员告诉她合同已经签了,将合同给 她看,proposer-1小姐是一个没有什么职业操守的聪明人,觉得跟Client1老板混没什么前途,所以将自己的议题修改为“Client2老板中 标”,并且给了2号官员20比特币,这样形成了一个多数派。顺利的再次进入第二阶段。由于此时没有人竞争了,顺利的找3位官员签合同,3位官员看到议题与 上次一次的合同是一致的,所以最终接受了,形成了多数派,proposer-1小姐跳槽到Client2老板的公司去了。
华丽的,第二阶段结束
Paxos过程结束了,这样,一致性得到了保证,算法运行到最后所有的 proposer都投“client2中标”所有的acceptor都接受这个议题,也就是说在最初的第二阶段,议题是先入为主的,谁先占了先机,后面的 proposer在第一阶段就会学习到这个议题而修改自己本身的议题,因为这样没职业操守,才能让一致性得到保证,这就是paxos算法的一个过程。原来 paxos算法里的角色都是这样的不靠谱,不过没关系,结果靠谱就可以了。该算法就是为了追求结果的一致性。
8 ZAB协议
ZooKeeper并没有直接采用Paxos算法,因为Paxos算法在节点很多的情况下,如果要收敛,也就是确定一个一致的值,需要不停的循环,那么必然会造成速度慢。所以zk参考Paxos提供了一种被称为ZAB(ZooKeeper Atomic Broadcast)的一致性协议。
ZAB协议主要用于构建一个高可用的分布式数据主备系统--AP
Paxos算法则是用于构建一个分布式的一致性状态机系统--CP
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时C和P两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了CP系统,但是CAP不可同时满足。
8.1 zookeeper中节点分四种状态
- looking:选举Leader的状态(集群刚启动时或崩溃恢复状态下,也就是需要选举的时候)
- following:跟随者(follower)的状态,服从Leader命令
- leading:当前节点是Leader,负责协调工作。
- observing:observer(观察者),不参与选举,只读节点。
8.2 zookeeper选举过程
- 举例场景:leader挂了,需要选举新的leader

- 阶段一:崩溃恢复
a.每个server都有一张选票<myid,zxid>,如(3,9),选票投自己。
b.每个server投完自己后,再分别投给其他还可用的服务器。如把Server3的(3,9)分别投给Server4和Server5,依次类推
c.比较投票,比较逻辑:优先比较Zxid,Zxid相同时才比较myid。比较Zxid时,大的做leader;比较myid时,小的做leader
d.改变服务器状态(崩溃恢复->数据同步,或者崩溃恢复->消息广播)
- 阶段二:消息广播
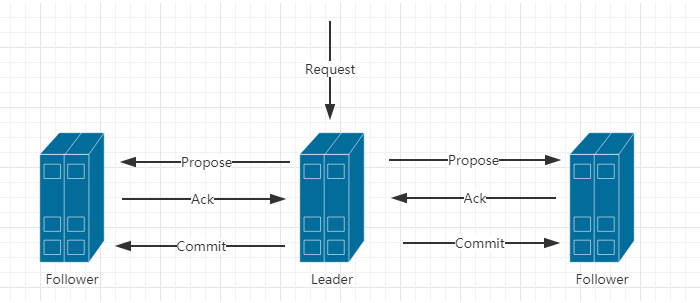
a.Leader接受请求后,将这个请求赋予全局的唯一64位自增Id(zxid)。
b.将zxid作为议案发给所有follower。
c.所有的follower接受到议案后,想将议案写入硬盘后,马上回复Leader一个ACK(OK)。
d.当Leader接受到合法数量(过半)Acks,Leader给所有follower发送commit命令。
e.follower执行commit命令。
注意:到了这个阶段,ZK集群才正式对外提供服务,并且Leader可以进行消息广播,如果有新节点加入,还需要进行同步。
- 阶段三:数据同步
a.取出Leader最大lastZxid(从本地log日志来)
b.找到对应zxid的数据,进行同步(数据同步过程保证所有follower一致)
c.只有满足quorum同步完成,准Leader才能成为真正的Leader
8.3 写数据流程

完

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号