spark运行模式
一、Local模式:在本地部署单个Spark服务
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
二、Standalone模式:Spark自带的任务调度模式。(国内常用)
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助其他的框架。是相对于Yarn和Mesos来说的。
Spark有standalone-client和standalone-cluster两种模式,主要区别在于:Driver程序的运行节点。
1.客户端模式
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077,hadoop103:7077 \ --executor-memory 2G \ --total-executor-cores 2 \ --deploy-mode client \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 10
--deploy-mode client,表示Driver程序运行在本地客户端

过程:本地递交任务后,会在本地机器上生成Driver,Driver会像spark集群的master注册,master会根据集群的资源使用情况在相应的机器上生成worker,worker会再把客户端的请求封装成Executor,Executor执行完毕后会向Driver反向注册,将执行结果告知Driver,Driver便可以查看到对应信息。但过多的反向注册,容易导致客户端资源紧张。
2.集群模式
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077,hadoop103:7077 \ --executor-memory 2G \ --total-executor-cores 2 \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 10
--deploy-mode cluster,表示Driver程序运行在集群
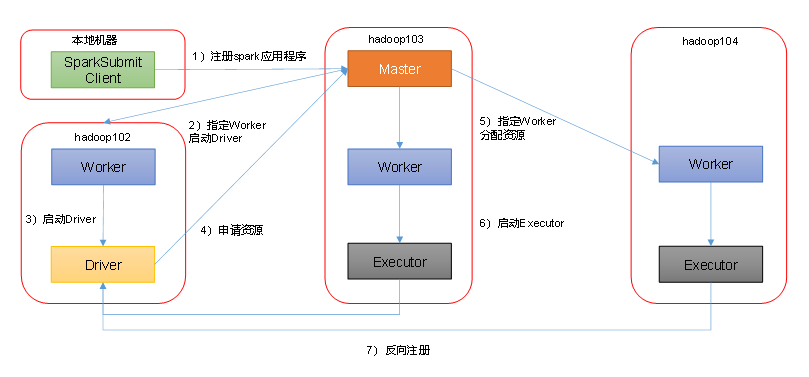
过程:客户端提交请求后,Driver由master根据集群情况选择节点生成,其余过程与client模式相同。该模式优点是分散了Driver,解决了反向注册时,因注册请求过多,造成Driver端资源紧张。
三、YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用)
本地sparksubmit提交任务后,会在本地Driver初始化sc,并将ExecutorLauncher指令发送给RM,RM会选择一台NM
启动EL(ExecutorLauncher),ExecutorLauncher就是AM(ApplicationMaster),AM会向RM申请资源,资源申请后AM会
启动一个Executor,Executor执行后会把结果返回给Driver。
1.脚本启动执行sparksubmit里面的main方法 2.反射回去client类里面的main方法并执行 3.发送指令给RM 4.RM选择一台NM启动AM 5.AM启动Driver线程执行用户任务 6.Driver向RM申请资源 7.AM封装并发送bin/java CoarseGrainedExecutorBackend指令给集群NM,并启动EB(ExecutorBackend) 8.启动EB,并在EB内部创建Executor对象 9.Executor向Driver反向注册 10.Driver分配任务
# yarn模式提交命令 spark-submit \ --class com.naxions.spark.WordCount \ # 定义的object类的名称 --master yarn \ wc.jar \ # 开发好的jar包 /input \ # 输入路径 /output # 输出路径
四、Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
国内一般不用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号