使用Pandas进行数据匹配
Pandas中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能。与Excel不同之处在于merge函数有4种匹配拼接模式,分别为inner,left,right和outer模式。 其中inner为默认的匹配模式。本篇文章我们将介绍merge函数的使用方法和4种拼接模式的区别。
下面是我们准备进行拼接的两个数据表,左边是贷款状态表loan_stats,右边为用户等级表member_grade。我们将分别用merge函数的4种匹配模式对这两个表进行拼接。

准备工作
开始使用merge函数进行数据拼接之前先导入所需的功能库,然后将分别读取两个数据表,并命名为loanstats表和member_grade表。
|
1
2
3
4
|
import numpy as npimport pandas as pdloanstats=pd.DataFrame(pd.read_excel('loanStats.xlsx'))member_grade=pd.DataFrame(pd.read_excel('member_grade.xlsx')) |
函数功能介绍
merge函数的使用方法很简单,以下是官方的函数功能介绍和使用说明。merge函数中第一个出现的数据表是拼接后的left部分,第二个出现的数据表是拼接后的right部分。第三个是数据匹配模 式,默认是inner模式。第四个参数on表示数据匹配所依据的字段名称,如果这个字段名称同时出现在两个数据表中,那么可以省略on参数的设置,merge默认会按照两个数据表中共有的字段名称进行匹配和拼接。如果两个数据表中的匹配字段名称不一致,则需要分别在left_on和right_on参数中指明两个表匹配字段的名称。如果两个数据表中没有匹配字段,需要使用索引列进行匹配和拼接,可以对left_index和right_index参数设置为True。merge还有一些排序和其他的参数,可在需要使用时进行设置。

Inner模式匹配
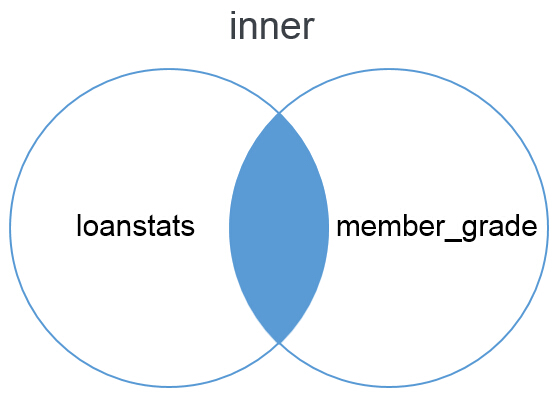
inner模式是merge的默认匹配模式,我们通过下面的文氏图来说明inner的匹配方法。Inner模式提供在loanstats和member_grade表中共有字段的匹配结果。也就是对两个的表交集部分进行匹配和拼接。单独只出现在一个表中的字段值不会参与匹配和拼接。
以下是使用merge函数进行拼接的代码,因为inner是默认的拼接模式,因此也可以省略how=’inner’部分。其中第一个出现的loanstats出现在拼接后的左侧,member_grade出现在拼接后的右侧。拼接后的数据表中只包含两个表的交集,因此不存在未匹配到的NaN情况。
|
1
|
loan_inner=pd.merge(loanstats,member_grade,how='inner') |
left模式匹配
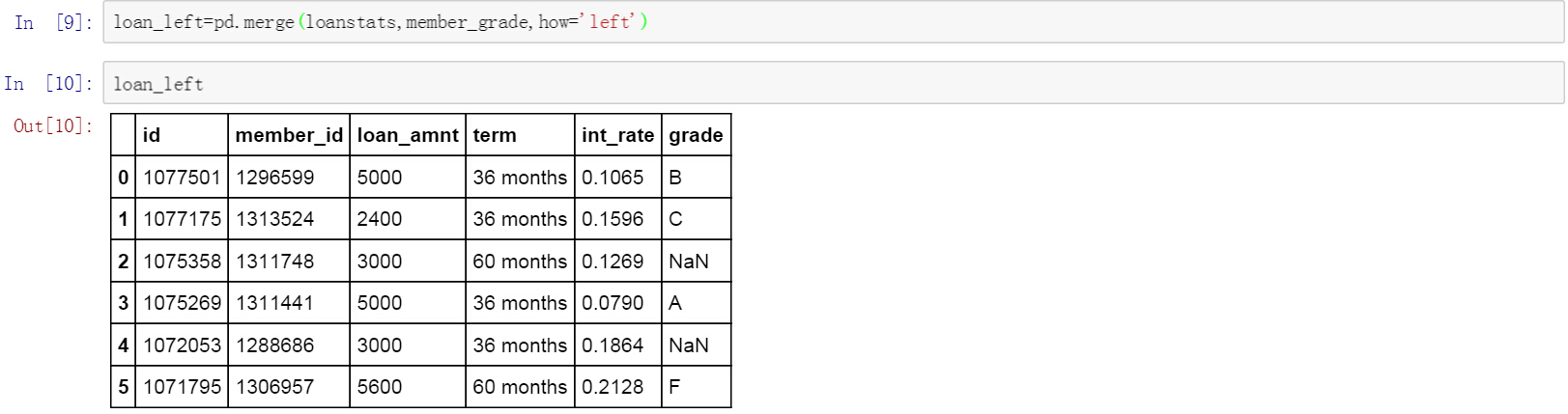
left模式是左匹配,以左边的数据表loanstats为基础匹配右边的数据表member_grade中的内容。匹配不到的内容以NaN值显示。在Excel中就好像将Vlookup公式写在了左边的表中。下面的文氏图说明了left模式的匹配方法。Left模式匹配的结果显示了所有左边数据表的内容,以及和右边数据表共有的内容。

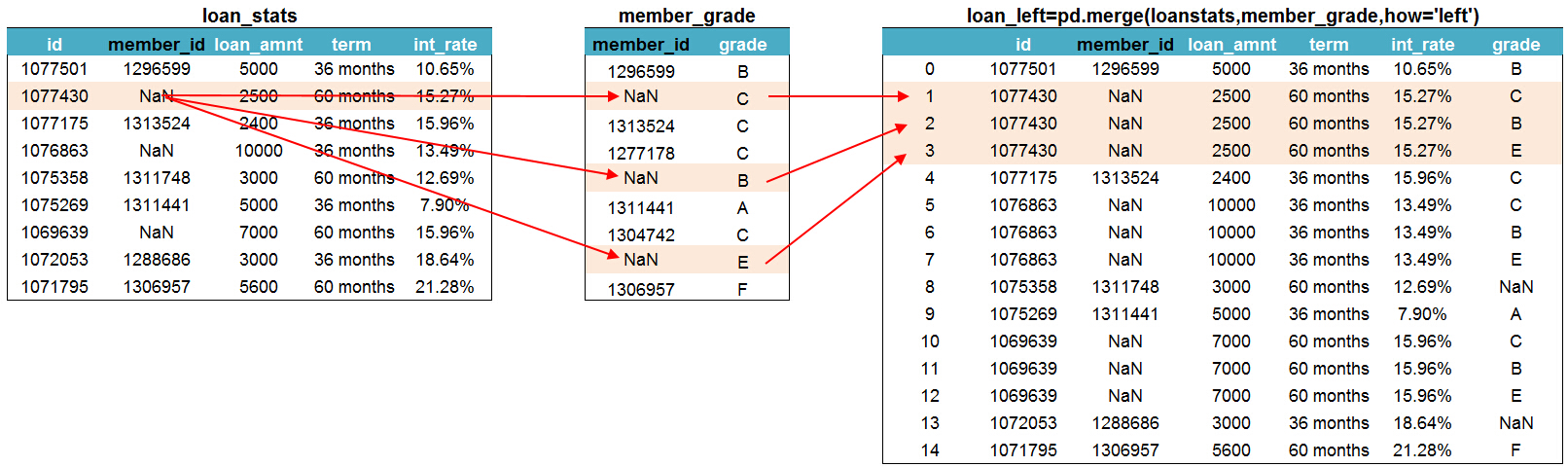
以下为使用left模式匹配并拼接后的结果,loanstats在merge函数中第一个出现,因此为左表,member_grade第二个出现,为右表。匹配模式为left模式。从结果中可以看出left匹配模式保留了一张完整的loanstats表,以此为基础对member_grade表中的内容进行匹配。loanstats表中有两个member_id值在member_grade中无法找到,因此grades字段显示为NaN值。
|
1
|
loan_left=pd.merge(loanstats,member_grade,how='left') |
right模式匹配
第三种模式是right匹配,right与left模式正好相反,right模式是右匹配,以右边的数据表member_grade为基础匹配左边的数据表loanstats。匹配不到的内容以NaN值显示。下面通过文氏图说明right模式的匹配方法。Right模式匹配的结果显示了所有右边数据表的内容,以及和左边数据表共有的内容。
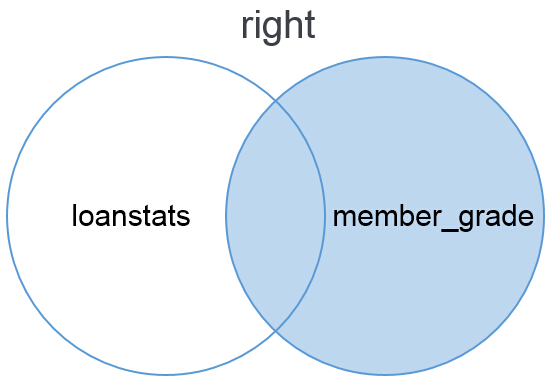
以下为使用right模式匹配拼接的结果,从结果表中可以看出right匹配模式保留了完整的member_grade表,以此为基础对loanstats表进行匹配,在member_grade数据表中有两个条目在loanstats数据表中无法找到,因此显示为了NaN值。
|
1
|
loan_right=pd.merge(loanstats,member_grade,how='right') |

outer模式匹配
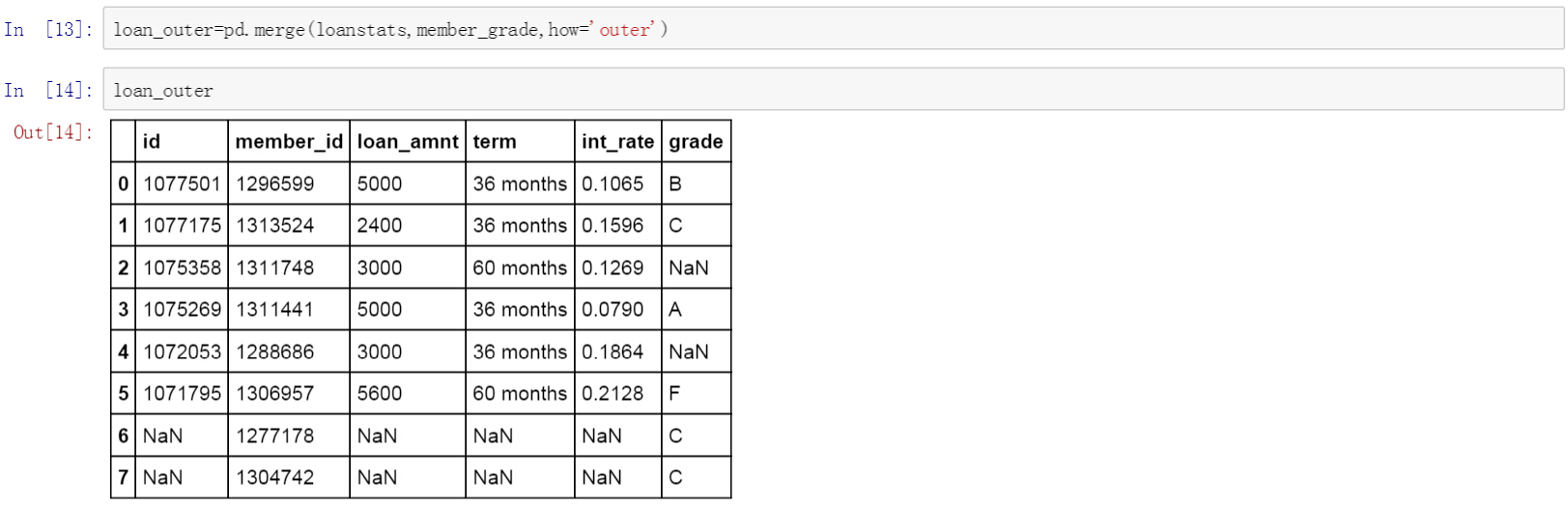
最后一种模式是outer匹配,outer模式是两个表的汇总,将loanstats和member_grade两个要匹配的两个表汇总在一起,生成一张汇总的唯一值数据表以及匹配结果。

下面是使用outer模式匹配拼接的结果,其中member_id列包含了loanstats和member_grade中的唯一值,grade列显示了对member_grade表匹配的结果,其他列则显示了对loanstats表匹配的结果 ,无法匹配的内容以NaN值显示。
|
1
|
loan_outer=pd.merge(loanstats,member_grade,how='outer') |
NaN值匹配问题
在进行数据匹配和拼接的过程中经常会遇到NaN值。这种情况下merge函数会如何处理呢?merge会将两个数据表中的NaN值进行交叉匹配拼接,换句话说就是将loanstats表member_id列中的NaN值
分别与member_grade表中member_id列中的每一个NaN值进行匹配,然后再拼接在一张表中。下面是包含NaN值的两张数据表进行拼接的结果,当我们使用left模式进行匹配时,loanstats作为基础
表,其中member_id列的NaN值分别与member_grade表中member_id列的每一个NaN值进行匹配。并将匹配结果显示在了结果表中。
|
1
|
loan_left=pd.merge(loanstats,member_grade,how='left') |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号