RKNN Toolkit2工具详解与工程应用
一、RKNN Toolkit2介绍
在之前的博客中,有对rknn-toolkit2工具进行简要介绍,rknn-toolkit2只能运行在X86的Linux平台上,它主要用来进行模型转换,将常用深度学习模型,例如TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch等模型转换为 RKNN模型,只有转换成RKNN模型才能够使用 RKSOC 的 NPU 实现推理速。
rknn-toolkit2具体代码在瑞芯微AI github仓库中https://github.com/airockchip/rknn-toolkit2,可以通过clone的方式或者直接下载zip压缩包文件
项目下载完成之后,可以看见在这个工程中的rknn-toolkit2目录,就是我们需要的rknn-toolkit2工具。其中包含了doc、docker、examples、packages等子目录

| 文件夹名称 | 作用 |
|---|---|
| doc | 对rknn-toolkit2工具说明文档 |
| docker | 存放docker的dockerfile文件 |
| example | 存放了rknn-toolkit2的示例工程文件 |
| packages | 存放了rknn-toolkit2的python安装whl文件以及环境依赖文件 |
二、环境搭建
rknn-toolkit2的环境搭建,主要分为两个部分,第一就是python环境的搭建包括python的安装还有对应依赖模块的板状,第二就是rkknn-toolkit2 whl文件的安装
2.1 python环境的搭建
python环境有三种方法实现,包括直接在本地的python环境中安装、使用anaconda虚拟环境安装、以及直接使用瑞芯微官方提供的docker环境,在本篇博文中主要使用anaconda环境安装,其余两种方法读者自行尝试。
第一步,到anaconda官方下载相应的安装包https://www.anaconda.com/download/success,博主这里选择的是miniconda,miniconda相比于anaconda的唯一不同就是,每次初始化环境安装的依赖包会相对少一些,这个环境不会那么臃肿,后续自己需要什么库,自己进行安装即可
下载完成之后,会得到一个Miniconda3-latest-Linux-x86_64.shshell文件,注意这个shell文件没有可执行权限,先通过chmod命令加入可执行权限,直接运行即可
全部执行yes之后,新打开一个终端,可以看见提示符最前面出现(base)的字样,这说明我们已经在conda的base环境中了,如果不想每次打开终端都默认进入conda环境,可以在conda的base环境中执行conda config --set auto_activate_base false,这样每次打开终端就不会在conda环境中。使用conda activate [环境名]来激活某一个环境,具体conda的命令操作请读者自行查看其他文章学习,本文只会罗列安装对应环境时必要的命令
安装完conda之后,我们就需要创建一个rknn-toolkit2专属的python环境,使用如下命令
conda create -n rknn python=3.8
这个命令表示创建一个名字为rknn的python版本为3.8的conda虚拟环境,创建完成之后使用如下命令,来激活环境
conda activate rknn
激活完成后,会从base环境切换到rknn环境中来

当我们处在rknn环境中之后,就可以安装瑞芯微官方提供的依赖包文件了,切换到 rknn-toolkit2/rknn-toolkit2/packages目录下
可以看见对应的以来文件,因为博主安装的python环境为3.8,所以我需要选择以cp38为名的requirements文件,使用如下命令安装依赖项
pip install -r requirements_cp38-2.3.2.txt -i https://repo.huaweicloud.com/repositor
y/pypi/simple/
依赖安装完成之后可以使用如下命令查看安装好了的包
conda list
2.2 rknn-toolkit2 whl文件安装
环境依赖安装完成之后,接下来安装rknn-toolkit2对应的python模块,安装这个的目的能够在python代码中导入rknn相关的api内容例如from rknn.api import RKNN
执行如下命令安装rknn-toolkit2 whl文件
pip install rknn_toolkit2-2.0.0b0+9bab5682-cp38-cp38-linux_x86_64.whl -i https://repo.huaweicloud.com/repository/pypi/simple/

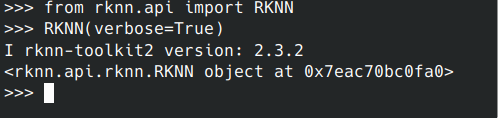
安装成功之后,先输入python3进入python命令行,在命令行中执行如下python命令,查看能够打印rknn_toolkit2版本证明是否安装成功
python3
from rknn.api import RKNN
RKNN(verbose=True)
如果能够打印出版本好,证明安装成功
至此,rknn-toolkit2的依赖环境就安装完成了,后续会在这个环境中进行模型构建等操作
2.3 官方例程测试
先进行瑞芯微官方历程测试,打开rknn-toolkit2-master/rknn-toolkit2/examples/pytorch/resnet18路径,这里选择使用resnet18作为测试模型,可以使用pycharm打开这个路径,也可以直接在命令行中激活rknn的conda环境直接使用python3运行test.py程序,博主使用pycharm运行python程序
注意,该程序需要路径下有resnet18.pt模型文件,如果路径下没有,程序中会自动从torchvision模型库中导出,需要自行安装torchvision,程序运行完成之后,可以看出模型已经正确将图片识别成space shuttle

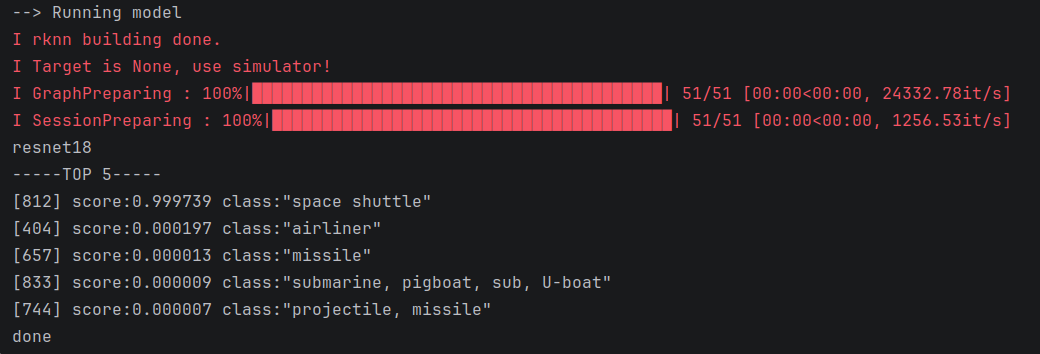
说明我们的环境,以及rknn整个流程与功能就没有问题了,后面将对rknn-toolkit2的各类接口进行详细阐述
三、RKNN Toolkit2模型构建以及接口API详解
3.1 模型构建流程
这一部分,主要是用来将常用的深度学习模型,转换成rk能够处理的rknn模型,具体整个模型构建流程分为两大部分,模型构建与模型评估
其中模型构建流程为:1、配置RKNN模型参数,2、导入常见深度学习模型,3、构建RKNN模型,4、导出RKNN模型
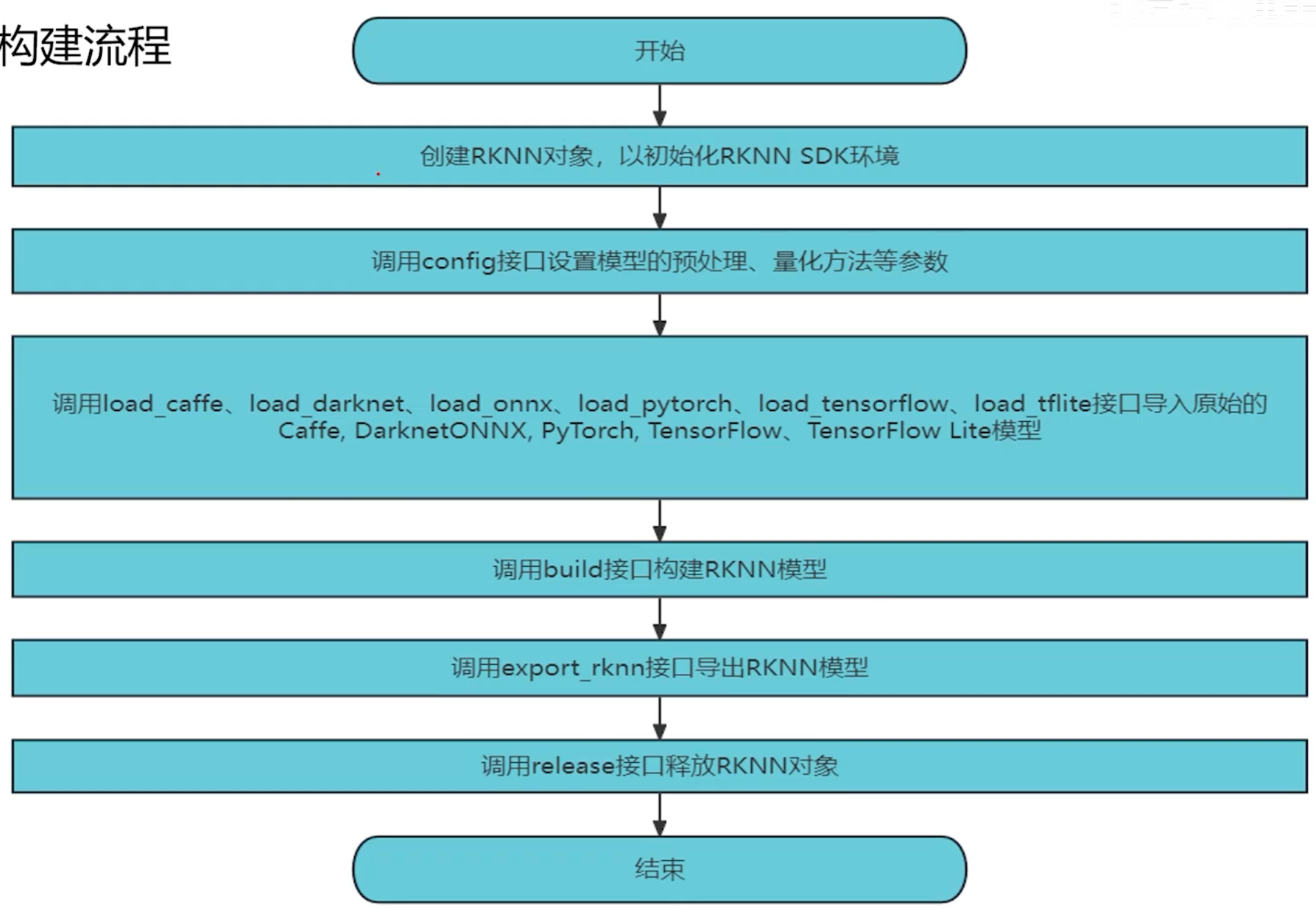
模型评估分为四个内容:1、推理测试,2、精度分析,3、性能评估,4、内存评估
3.2 rknn-toolkit2常用API接口
更加详细的API接口可以查看瑞芯微的rknn-toolkit2的API文档,具体路径在rknn-toolkit2-master/doc/03_Rockchip_RKNPU_API_Reference_RKNN_Toolkit2_V2.3.2_CN.pdf
1、RKNN实例初始化以及对象释放:
在使用rknn-toolkit2的所有API接口的时候,都需要先创建一个RKNN对象,通过这个对象对模型进行一系列操作,不使用这个对象之后需要进行释放
# 创建RKNN对象,verbose参数表示进行日志信息输出,默认输出到命令行中,如果指定了verbase_file,将输出到指定文件当中
rknn=RKNN(verbose=True, verbase_file='./log')
rknn.release()
2、模型预处理与量化配置:
在构建RKNN模型之前,需要先对模型进行通道均值、量化图片RGB2BGR转换、量化类型等的配置,这些操作可以通过config接口进行配置。
rknn.config(
# mean_values表示预处理时要减去的均值化参数
mean_values=[123.675, 116.28, 103.53],
# std_values表示预处理时要除以的标准化参数
std_values=[58.395, 58.395, 58.395],
# 量化类型,目前支持的量化类型有w8a8、w4a16、w8a16、w4a8、w16a16i和w16a16i_dfp。默认值为w8a8。
# w8a8:权重为8bit非对称量化精度,激活值为8bit非对称量化精度。(RK2118不支持)
# w4a16:权重为4bit非对称量化精度,激活值为16bit浮点精度。(仅RK3576/RV1126B支持)
# w8a16:权重为8bit非对称量化精度,激活值为16bit浮点精度。(仅RK3562支持)
# w4a8:权重为4bit非对称量化精度,激活值为8bit非对称量化精度。(暂不支持)
# w16a16i:权重为16bit非对称量化精度,激活值为16bit非对称量化精度。(仅RV1103/RV1106支持)
# w16a16i_dfp:权重为16bit动态定点量化精度,激活值为16bit动态定点量化精度。(仅RV1103/RV1106支持)
quantized_dtype=w8a8,
# quantized_algorithm:计算每一层的量化参数时采用的量化算法,目前支持的量化算法有normal,mmse,kl_divergence及gdq。默认值为normal。
# normal量化算法的特点是速度较快,推荐量化数据集量一般为20-100张左右,更多的数据集量下精度未必会有进一步提升。
# mmse量化算法由于采用暴力迭代的方式,速度较慢,但通常会比normal具有更高的精度,推荐量化数据集量一般为20-50张左右,用户也可以根据量化时间长短对量化数据集量进行适当增减。
# kl_divergence量化算法所用时间会比normal多一些,但比mmse会少很多,在某些场景下(feature分布不均匀时)可以得到较好的改善效果,推荐量化数据集量一般为20-100张左右。
# gdq量化算法只在w4a16和w8a16下有效,能有效的提高w4a16和w8a16的权重量化精度,推荐量化数据集量为200张以上。
quantized_algorithm=normal,
# quantized_method:目前支持layer,channel或者group{SIZE}。默认值为channel。
# layer:每层的weight只有一套量化参数;
# channel:每层的weight的每个输出通道都有一套量化参数,通常情况下channel会比layer精度更高。
# group{SIZE}:在channel的基础上,每个输出通道的weight在输入通道上又按{SIZE}细分为多个小组,每个小组有各自的一套量化参数,通常情况下group{SIZE}会比channel精度更高。{SIZE}是32到256之间的32的倍数值,如group32或group128。目前group{SIZE}只在quantized_dtype为w4a16下有效。
quantized_method=channel,
# 表示在加载量化图像时是否需要先做RGB2BGR的操作。默认值为false,该参数不会嵌入到rknn模型中,也就是如果模型的输入需要BGR,需要用户自行将RGB先转化为BGR在传入模型
quantized_img_RGB2BGR=Flase,
# 指定RKNN模型是基于哪个目标芯片平台生成的。
target_platform='rk3576',
# 用于指定非量化情况下的浮点的数据类型,目前支持的数据类型有float16。
float_dtype="float16",
# 模型优化等级。默认值为3。
optimization_level=3,
# 自定义字符串信息,后续可以在c API中获取到模型的自定义字符串信息
custom_string=None,
# 去除conv等权重以生成一个RKNN的从模型,该从模型可以与带完整权重的RKNN模型共享权重以减少内存消耗。默认值为False。
remove_weight=False,
# 压缩模型权重,可以减小RKNN模型的大小。默认值为False。
compress_weight=False,
# 是否仅生成单核模型,可以减小RKNN模型的大小和内存消耗。默认值为False。目前仅对RK3588 / RK3576生效。默认值为False。如果为True可以减小模型体积
single_core_mode=False,
# 对模型进行无损剪枝。对于权重稀疏的模型,可以减小转换后RKNN模型的大小和计算量。默认值为False。
model_pruning=False,
)
这里只展示出部分参数,具体参数请读者参考官方提供的API手册
3、常用深度学习模型加载:
完成了rknn的配置之后,我们就需要开始加载常用深度学习框架下的具体模型了,支持Caffe、TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch等模型的加载转换,这些模型在加载时需调用对应的接口,以下为这些接口的详细说明。
# caffe模型加载接口
ret = rknn.load_caffe(model='./mobilenet_v2.prototxt', blobs='./mobilenet_v2.caffemodel')
# tensorflow模型加载接口
ret = rknn.load_tensorflow(
tf_pb='./ssd_mobilenet_v1_coco_2017_11_17.pb',
inputs=['Preprocessor/sub'],
outputs=['concat', 'concat_1'],
input_size_list=[[300, 300, 3]])
# tensorflow lite模型加载接口
ret = rknn.load_tflite(model='./mobilenet_v1.tflite')
# onnx模型加载接口
ret = rknn.load_onnx(model='./arcface.onnx')
# darknet模型加载接口
ret = rknn.load_darknet(model='./yolov3-tiny.cfg',weight='./yolov3.weights')
# pytorch模型加载接口
ret = rknn.load_pytorch(model='./resnet18.pt',input_size_list=[[1,3,224,224]])
这里只是简单列出各类模型的加载接口函数,具体参数信息请查看官方API手册
4、构建RKNN模型:
ret = rknn.build(
# 是否对模型进行量化。默认值为True。
do_quantization=True,
# 用于量化校正的数据集。目前支持文本文件格式,用户可以把用于校正的图片(jpg或png格式)或npy文件路径放到一个.txt文件中。文本文件里每一行一条路径信息。
dataset='./dataset.txt',
# 模型的输入Batch参数调整。默认值为None,表示不进行调整。如果大于1,则可以在一次推理中同时推理多帧输入图像或输入数据,如MobileNet模型的原始input维度为[1, 224, 224, 3],output维度为[1, 1001],当rknn_batch_size设为4时,input的维度变为[4, 224, 224, 3],output维度变为[4, 1001]。
# 1. rknn_batch_size只有在NPU多核的平台上可以提高性能(提升核心利用率),因此rknn_batch_size的值建议与核心数匹配。
# 2. rknn_batch_size修改后,模型的input/output的shape都会被修改,使用inference推理模型时需要设置相应的input的大小,后处理时,也需要对返回的outputs进行处理。
rknn_batch_size=None,
# 是否开启自动混合量化调整精度或溢出。默认值为False,表示不进行调整。当模型经行量化时,开启自动混合量化会将低于指定阈值的余弦距离/欧式距离的op转为fp16计算(目前仅在w8a8量化下支持);当模型未进行量化时,开启自动混合量化会将超出fp16数值范围的op转为int16计算。
auto_hybrid=False,
)
5、导出RKNN模型:
通过rknn-toolkit2工具做好前期工作之后,构建的RKNN模型通过该接口可以导出存储为RKNN模型文件,用于模型部署。
ret = rknn.export_rknn(export_path='./mobilenet_v1.rknn')
至此整个rknn模型的构建流程与相关的api函数就讲解完成了,后续继续对RKNN模型的评估流程进行详解
四、RKNN Toolkit2模型推理
4.1 两种模型加载与推理运行方式
这一部分,主要是针对转换出来的模型进行推理测试、精度分析、性能评估和内存评估等测试,模型达到一定水平之后,再进行后期部署操作。
进行模型评估与推理有两种方式,第一种为连板推理,第二种为模拟器运行
如果直接通过load_rknn调用rknn模型加载的方式只能用于连板推理,如下为加载rknn模型的接口,加载完RKNN模型后,不需要再进行模型配置、模型加载和构建RKNN模型的步骤。并且加载后的模型仅限于连接NPU硬件进行推理或获取性能数据等,不能用于模拟器或精度分析等。因为这个rknn模型已经更具具体的硬件平台进行了调整和优化
ret = rknn.load_rknn(path='./mobilenet_v1.rknn')
模拟器运行主要是用在,rknn模型从常用深度学习框架转换成rknn模型的流程之后,在rknn模型build函数调用之后,可直接进行模拟器运行,可进行精度分析等流程
两种方式的不同流程如下图所示
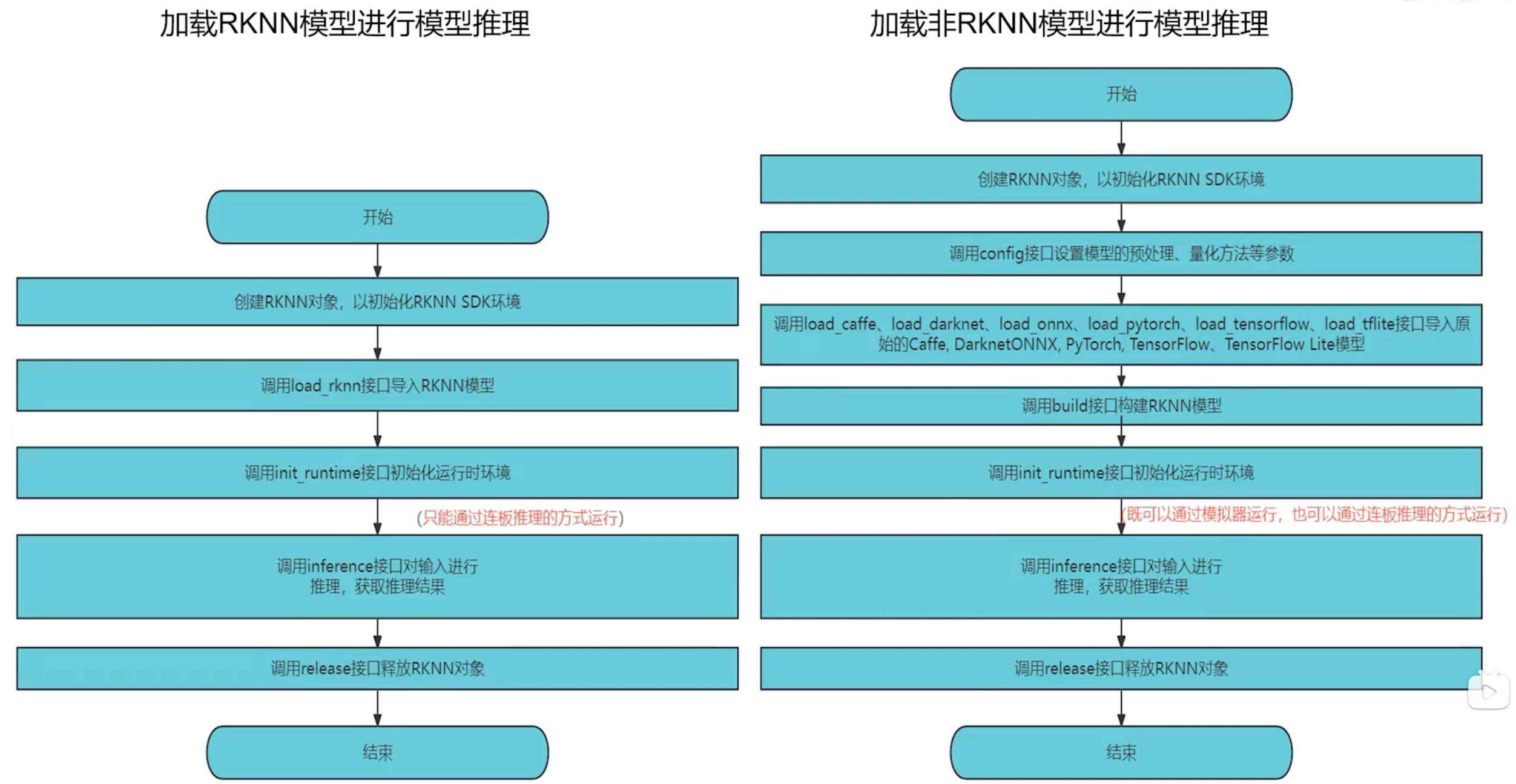
总结:一句话来说,如果直接使用load_rknn函数加载的rknn模型,在使用init_runtime时,target只能指定特定板卡,进行连板推理,target不能指定为None使用模拟器,如果使用常规深度学习模型转换的rknn模型,在build接口之后就可以使用init_runtime接口函数,既可以指定为连板推理模式,也可以使用模拟器模式推理。
4.2 推理流程
1、初始化运行环境
在模型推理或性能评估之前,必须先初始化运行时环境,明确模型的运行平台(具体的目标硬件平台或软件模拟器)。
ret = rknn.init_runtime(
# 目标硬件平台,支持“rv1103”、“rv1103b”、“rv1106”、“rv1106b”、“rv1126b”、“rk3562”、“rk3566”、“rk3568”、“rk3576”和“rk3588”。默认值为None,即在PC使用工具时,模型在模拟器上运行。 注:target设为None时,需要先调用build或hybrid_quantization接口才可让模型在模拟器上运行。
target=None,
# 设备编号,如果PC连接多台设备时,需要指定该参数,设备编号可以通过“list_devices”接口查看。默认值为None。
device_id=None,
# 进行性能评估时是否开启debug模式。在debug模式下,可以获取到每一层的运行时间,否则只能获取模型运行的总时间。默认值为False。
perf_debug=False,
# 是否进入内存评估模式。进入内存评估模式后,可以调用eval_memory接口获取模型运行时的内存使用情况。默认值为False。
eval_mem=False,
# core_mask:设置运行时的NPU核心。支持的平台为RK3588 / RK3576,支持的配置如下:
# RKNN.NPU_CORE_AUTO:表示自动调度模型,自动运行在当前空闲的NPU核上。
# RKNN.NPU_CORE_0:表示运行在NPU0核心上。
# RKNN.NPU_CORE_1:表示运行在NPU1核心上。
# RKNN.NPU_CORE_2:表示运行在NPU2核心上。
# RKNN.NPU_CORE_0_1:表示同时运行在NPU0、NPU1核心上。
# RKNN.NPU_CORE_0_1_2:表示同时运行在NPU0、NPU1、NPU2核心上。
# RKNN.NPU_CORE_ALL:表示根据平台自动配置NPU核心数量。
# 默认值为RKNN.NPU_CORE_AUTO。
# 注:RK3576只有2个核心,因此不能设置NPU_CORE_2和NPU_CORE_0_1_2。
core_mask=RKNN.NPU_CORE_AUTO,
# 设置当OP超出NPU规格时fallback的优先级,当前支持“cpu”或“gpu”,“gpu”只有在存在GPU硬件的平台上有效。默认值是“cpu”。
fallback_prior_device="cpu"
)
到此,模型需要的运行环境就设置好了,接下来进行推理测试步骤
2、推理测试
对当前模型进行推理,并返回推理结果。如果初始化运行环境时有设置target为Rockchip NPU设备,得到的是模型在硬件平台上的推理结果。如果没有设置target,得到的则是模型在模拟器上的推理结果。
outputs = rknn.inference(
# 待推理的输入列表,格式为ndarray。
inputs=[img],
# 输入数据的layout列表,“nchw”或“nhwc”,只对4维的输入有效。默认值为None,表示所有输入的layout都为NHWC。
data_format=None,
# 输入的透传列表。默认值为None,表示所有输入都不透传。非透传模式下,在将输入传给NPU驱动之前,工具会对输入进行减均值、除方差等操作;而透传模式下,不会做这些操作,而是直接将输入传给NPU。该参数的值是一个列表,比如要透传input0,不透传input1,则该参数的值为[1, 0]。
inputs_pass_through=None,
)
show_outputs(outputs)
3、两种推理方式
使用模拟器进行推理,直接使用X86端环境即可,如果使用连板推理,需要先配置好相应的环境主要有以下几点需要注意:
1、更新rknn_server程序到开发板上,大部分厂家开发板的默认镜像系统中可能已经包含有rknn_server,可以在/usr/bin下查看,但是可能和最新的rknn_toolkit2SDK的版本不匹配,可通过如下命令查看版本号
strings /usr/bin/rknn_server | grep -i "rknn_server version"
将最新的rknn_toolkit2SDK中的rknn_server更新到开发板中,通过ADB工具上传最新文件进行覆盖
adb push runtime/Linux/rknn_server/aarch64/usr/bin/* /usr/bin
2、更新librknnrt.so库到开发板上,和rknn_server同理,可能厂商所包含的动态库比较旧,通过如下命令进行版本查看
strings /usr/lib/librknnrt.so | grep -i "librknnrt version"
同样进行最新的动态库更新
adb push runtime/Linux/librknn_api/aarch64/librknnrt.so /usr/lib64
3、最后在连板调试时,开发板上需要先运行rknn_server程序,保证开发板与PC的ADB连接正常,运行PC中的推理代码,即可使用板卡上的NPU进行推理
调用restart_rknn.sh或者start_rnn.sh开启rknn_server,或者直接后台运行rknn_server,当然也可以直接运行PC端的连板调试,好像会自动调用开发板的bash开启rknn_server,测试得到的现象

PC端成功进行连板推理,得到正确结果
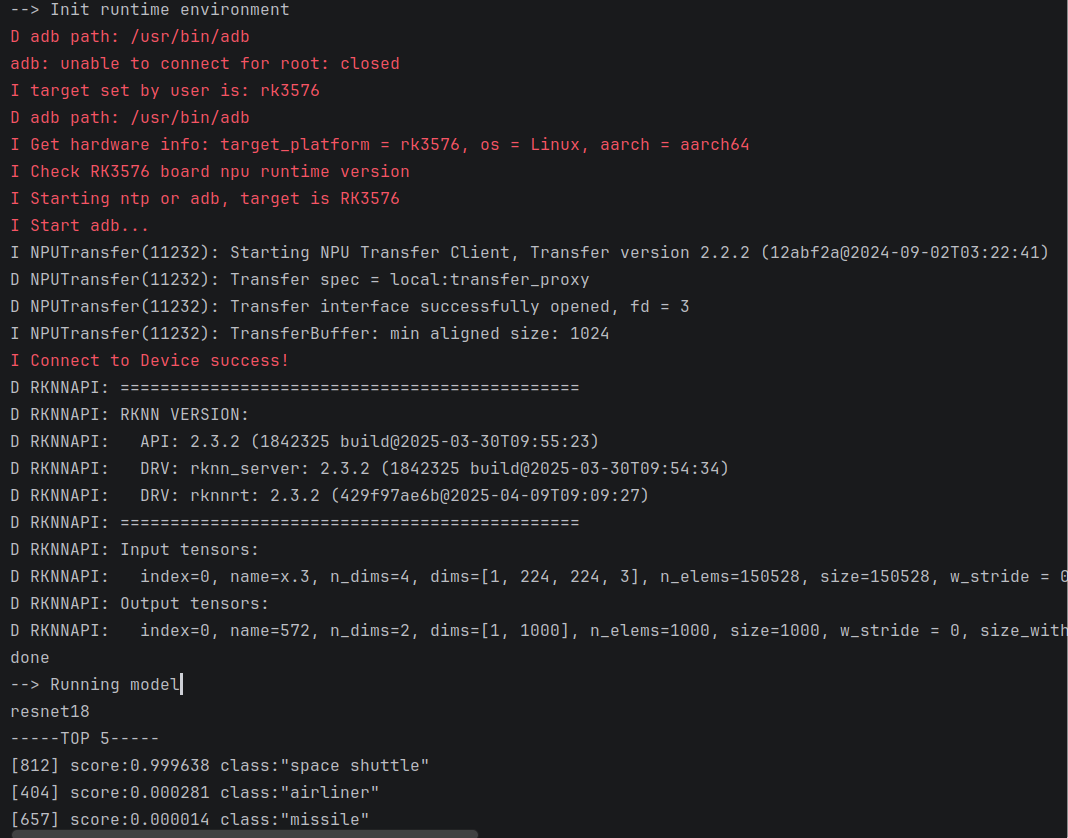
两种方式的py程序对比
1、已经有rknn模型了,直接通过加载rknn模型的方式,这种方式只能连板推理
import numpy as np
import cv2
from rknn.api import RKNN
import os
def show_outputs(output):
index = sorted(range(len(output)), key=lambda k : output[k], reverse=True)
fp = open('./labels.txt', 'r')
labels = fp.readlines()
top5_str = 'resnet18\n-----TOP 5-----\n'
for i in range(5):
value = output[index[i]]
if value > 0:
topi = '[{:>3d}] score:{:.6f} class:"{}"\n'.format(index[i], value, labels[index[i]].strip().split(':')[-1])
else:
topi = '[ -1]: 0.0\n'
top5_str += topi
print(top5_str.strip())
def show_perfs(perfs):
perfs = 'perfs: {}\n'.format(perfs)
print(perfs)
def softmax(x):
return np.exp(x)/sum(np.exp(x))
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# 此处直接加载rknn模型
rknn.load_rknn(path='./resnet_18.rknn')
# Set inputs
img = cv2.imread('./space_shuttle_224.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.expand_dims(img, 0)
# Init runtime environment
print('--> Init runtime environment')
# 将对应的平台设置为目标板卡平台
ret = rknn.init_runtime(target="rk3576")
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img], data_format=['nhwc'])
np.save('./pytorch_resnet18_0.npy', outputs[0])
show_outputs(softmax(np.array(outputs[0][0])))
print('done')
rknn.release()
2、既可以进行模拟推理,也能进行过连板推理的方式
import numpy as np
import cv2
from rknn.api import RKNN
import os
def export_pytorch_model():
import torch
import torchvision.models as models
net = models.resnet18(pretrained=True)
net.eval()
trace_model = torch.jit.trace(net, torch.Tensor(1, 3, 224, 224))
trace_model.save('./resnet18.pt')
def show_outputs(output):
index = sorted(range(len(output)), key=lambda k : output[k], reverse=True)
fp = open('./labels.txt', 'r')
labels = fp.readlines()
top5_str = 'resnet18\n-----TOP 5-----\n'
for i in range(5):
value = output[index[i]]
if value > 0:
topi = '[{:>3d}] score:{:.6f} class:"{}"\n'.format(index[i], value, labels[index[i]].strip().split(':')[-1])
else:
topi = '[ -1]: 0.0\n'
top5_str += topi
print(top5_str.strip())
def show_perfs(perfs):
perfs = 'perfs: {}\n'.format(perfs)
print(perfs)
def softmax(x):
return np.exp(x)/sum(np.exp(x))
if __name__ == '__main__':
model = './resnet18.pt'
if not os.path.exists(model):
export_pytorch_model()
input_size_list = [[1, 3, 224, 224]]
# Create RKNN object
rknn = RKNN(verbose=True)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[123.675, 116.28, 103.53], std_values=[58.395, 58.395, 58.395], target_platform='rk3576')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# 这里只是导出rknn模型
print('--> Export rknn model')
ret = rknn.export_rknn('./resnet_18.rknn')
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread('./space_shuttle_224.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.expand_dims(img, 0)
# Init runtime environment
print('--> Init runtime environment')
# 这里既可以指定相应平台,可以是指定为None使用模拟器
ret = rknn.init_runtime(target="rk3576")
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img], data_format=['nhwc'])
np.save('./pytorch_resnet18_0.npy', outputs[0])
show_outputs(softmax(np.array(outputs[0][0])))
print('done')
rknn.release()
至此,两种模型推理的方式就讲解完成了,接下来讲解rknn-toolkit2对于相应模型进行评估操作
五、RKNN Toolkit2模型量化精度分析
因为我们对原模型进行了量化操作,将原模型32位的浮点数转换为了8位的定点数,虽然减小了模型的体积,加快了推理速度,但是模型的精度可能会受到影响,可能会遇到模拟器推理结果与连板推理结果,与原模型推理结果精度相差较大的情况
rknn-toolkit2提供了精度分析接口,可以查看原始模型与模拟器模型与对应板卡上的模型的每一层的精度的损失情况,因为需要计算原始浮点模型与量化模型的精度差异,所以必须经过模型转换步骤,不能直接加载rknn模型
来进行精度分析
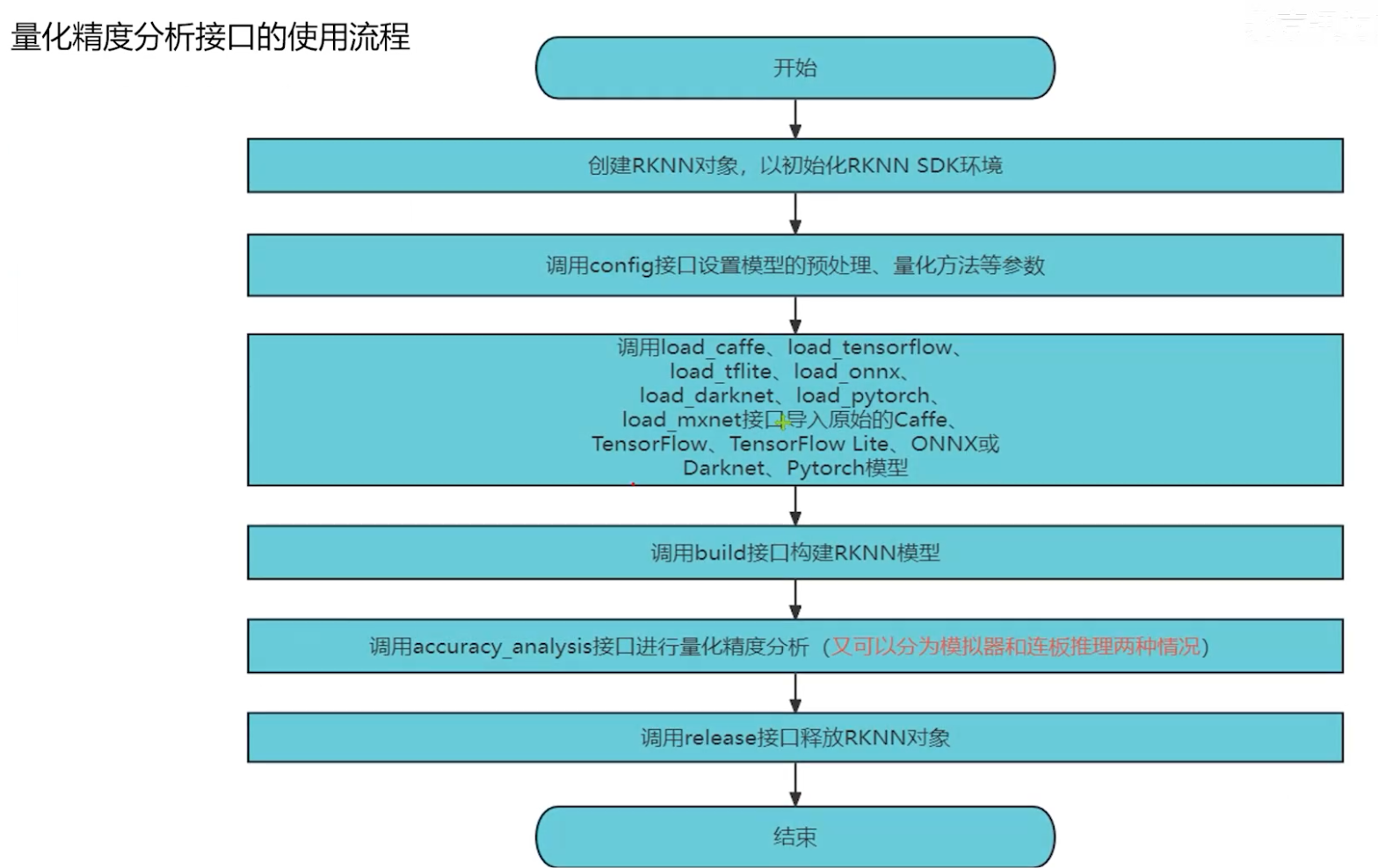
使用rknn.accuracy_analysis()接口进行精度分析,查看每层算子的精度,具体调用方式与参数如下
# 量化精度分析结果
rknn.accuracy_analysis(
# 输入文件路径表(格式包括jpg、png、bmp和npy)
inputs=["space_shuttle_224.jpg"],
# 分析结果保存路径
output_dir="snapshot",
# 目标硬件平台,默认为None,即使用仿真器进行精度分析,如果指定了target之后的结果会既有对应硬件平台的进度又有仿真器进度,还有原始模型的精度,指定target也需要连板分析
target='rk3576',
# 设备ID
device_id=None
)# 量化精度分析结果
实例程序,精度分析主要是在建立了rknn模型之后进行调用
import numpy as np
import cv2
from rknn.api import RKNN
import os
def export_pytorch_model():
import torch
import torchvision.models as models
net = models.resnet18(pretrained=True)
net.eval()
trace_model = torch.jit.trace(net, torch.Tensor(1, 3, 224, 224))
trace_model.save('./resnet18.pt')
def show_perfs(perfs):
perfs = 'perfs: {}\n'.format(perfs)
print(perfs)
def softmax(x):
return np.exp(x)/sum(np.exp(x))
if __name__ == '__main__':
model = './resnet18.pt'
if not os.path.exists(model):
export_pytorch_model()
input_size_list = [[1, 3, 224, 224]]
# Create RKNN object
rknn = RKNN(verbose=True)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[123.675, 116.28, 103.53], std_values=[58.395, 58.395, 58.395], target_platform='rk3576')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn('./resnet_18.rknn')
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# 量化精度分析结果
rknn.accuracy_analysis(
inputs=["space_shuttle_224.jpg"],
output_dir="snapshot",
target='rk3576',
device_id=None
)
rknn.release()
精度结果输出信息如下图所示
D adb path: /usr/bin/adb
adb: unable to connect for root: closed
I target set by user is: rk3576
D adb path: /usr/bin/adb
I Get hardware info: target_platform = rk3576, os = Linux, aarch = aarch64
I Check RK3576 board npu runtime version
I Starting ntp or adb, target is RK3576
I Start adb...
I Connect to Device success!
I NPUTransfer(16109): Starting NPU Transfer Client, Transfer version 2.2.2 (12abf2a@2024-09-02T03:22:41)
D NPUTransfer(16109): Transfer spec = local:transfer_proxy
D NPUTransfer(16109): Transfer interface successfully opened, fd = 3
I NPUTransfer(16109): TransferBuffer: min aligned size: 1024
D RKNNAPI: ==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 2.3.2 (1842325 build@2025-03-30T09:55:23)
D RKNNAPI: DRV: rknn_server: 2.3.2 (1842325 build@2025-03-30T09:54:34)
D RKNNAPI: DRV: rknnrt: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
D RKNNAPI: ==============================================
D RKNNAPI: Input tensors:
D RKNNAPI: index=0, name=x.3, n_dims=4, dims=[1, 224, 224, 3], n_elems=150528, size=150528, w_stride = 0, size_with_stride = 0, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-13, scale=0.018478
D RKNNAPI: Output tensors:
D RKNNAPI: index=0, name=572, n_dims=2, dims=[1, 1000], n_elems=1000, size=1000, w_stride = 0, size_with_stride = 0, fmt=UNDEFINED, type=INT8, qnt_type=AFFINE, zp=-70, scale=0.118524
D NPUTransfer(16109): Transfer client closed, fd = 3
D adb path: /usr/bin/adb
adb: unable to connect for root: closed
/userdata/dumps/: 26 files pulled, 0 skipped. 3.9 MB/s (10904336 bytes in 2.651s)
I Save Tensors to txt: 100%|████████████████████████████████████████| 25/25 [00:00<00:00, 91.47it/s]
I GraphPreparing : 100%|█████████████████████████████████████████| 51/51 [00:00<00:00, 21168.68it/s]
I AccuracyAnalysing : 100%|█████████████████████████████████████████| 51/51 [00:01<00:00, 32.35it/s]
I The error analysis results save to: snapshot/error_analysis.txt
W accuracy_analysis: The mapping of layer_name & file_name save to: snapshot/map_name_to_file.txt
# simulator_error: calculate the output error of each layer of the simulator (compared to the 'golden' value).
# entire: output error of each layer between 'golden' and 'simulator', these errors will accumulate layer by layer.
# single: single-layer output error between 'golden' and 'simulator', can better reflect the single-layer accuracy of the simulator.
# runtime_error: calculate the output error of each layer of the runtime.
# entire: output error of each layer between 'golden' and 'runtime', these errors will accumulate layer by layer.
# single_sim: single-layer output error between 'simulator' and 'runtime', can better reflect the single-layer accuracy of runtime.
layer_name simulator_error runtime_error
entire single entire single_sim
cos euc cos euc cos euc cos euc
-------------------------------------------------------------------------------------------------------------
[Input] x.3 1.00000 | 0.0 1.00000 | 0.0
[exDataConvert] x.3_int8 0.99999 | 2.1522 0.99999 | 2.1522
[Conv] input.11
[Relu] 82 0.99991 | 4.4227 0.99991 | 4.4227 0.99991 | 4.4495 0.99992 | 4.1873
[MaxPool] input.13 0.99995 | 2.2783 0.99998 | 1.3114 0.99995 | 2.2868 1.00000 | 0.0
[Conv] input.19
[Relu] 120 0.99966 | 2.2190 0.99979 | 1.7615 0.99968 | 2.1559 1.00000 | 0.0828
[Conv] out.3 0.99964 | 4.7999 0.99996 | 1.5311
[Add] input.25
[Relu] 142 0.99978 | 5.3705 0.99996 | 2.1654 0.99980 | 5.2328 1.00000 | 0.2159
[Conv] input.29
[Relu] 169 0.99918 | 3.1885 0.99982 | 1.4863 0.99925 | 3.0504 1.00000 | 0.0899
[Conv] out.5 0.99871 | 9.8806 0.99993 | 2.2329
[Add] input.33
[Relu] 191 0.99938 | 10.869 0.99996 | 2.8118 0.99945 | 10.318 1.00000 | 0.2707
[Conv] input.37
[Relu] 222 0.99859 | 3.2987 0.99991 | 0.8421 0.99876 | 3.0946 1.00000 | 0.0610
[Conv] out.7 0.99881 | 5.5206 0.99993 | 1.3496 0.99877 | 5.6291 0.99981 | 2.1976
[Conv] identity.2 0.99856 | 3.9809 0.99972 | 1.7560
[Add] input.43
[Relu] 267 0.99886 | 4.8305 0.99992 | 1.2945 0.99889 | 4.7696 0.99988 | 1.5886
[Conv] input.47
[Relu] 294 0.99819 | 2.5897 0.99987 | 0.6956 0.99832 | 2.4959 1.00000 | 0.0460
[Conv] out.9 0.99897 | 5.5916 0.99997 | 0.9661
[Add] input.51
[Relu] 316 0.99862 | 5.5386 0.99992 | 1.3672 0.99865 | 5.4652 1.00000 | 0.1058
[Conv] input.55
[Relu] 347 0.99865 | 2.1945 0.99990 | 0.5933 0.99874 | 2.1201 1.00000 | 0.0367
[Conv] out.11 0.99894 | 3.6506 0.99994 | 0.8461 0.99880 | 3.8846 0.99978 | 1.6488
[Conv] identity.4 0.99907 | 1.2875 0.99981 | 0.5793
[Add] input.61
[Relu] 392 0.99888 | 2.6139 0.99993 | 0.6481 0.99877 | 2.7273 0.99991 | 0.7419
[Conv] input.65
[Relu] 419 0.99847 | 1.2854 0.99989 | 0.3502 0.99862 | 1.2227 1.00000 | 0.0283
[Conv] out.13 0.99925 | 3.1385 0.99997 | 0.6257
[Add] input.69
[Relu] 441 0.99873 | 2.7363 0.99992 | 0.7065 0.99864 | 2.8425 1.00000 | 0.0720
[Conv] input.8
[Relu] 472 0.99826 | 0.9164 0.99992 | 0.2002 0.99833 | 0.9003 1.00000 | 0.0195
[Conv] out.2 0.99904 | 3.5051 0.99996 | 0.6881 0.99896 | 3.6996 0.99993 | 0.9050
[Conv] identity.1 0.99888 | 2.6061 0.99985 | 0.9391
[Add] input.12
[Relu] 517 0.99827 | 2.0228 0.99990 | 0.4849 0.99833 | 1.9857 0.99985 | 0.5965
[Conv] input.7
[Relu] 544 0.99805 | 1.0052 0.99992 | 0.2093 0.99812 | 0.9895 1.00000 | 0.0212
[Conv] out.1 0.99818 | 20.164 0.99996 | 2.7965
[Add] input.3
[Relu] 566 0.99851 | 16.448 0.99998 | 2.0470 0.99865 | 15.583 1.00000 | 0.2384
[Conv] x.1 0.99933 | 1.1513 0.99999 | 0.1388 0.99943 | 1.0599 1.00000 | 0.0
[Conv] 572_mm 0.99913 | 4.0149 0.99991 | 1.2341 0.99932 | 3.4780 1.00000 | 0.1185
[Reshape] 572_int8 0.99913 | 4.0149 0.99993 | 1.0861
[exDataConvert] 572 0.99913 | 4.0149 0.99993 | 1.0861 0.99932 | 3.4780 1.00000 | 0.0
这里目前只介绍,rknn-toolkit2工具基础使用,具体模型的精度介绍以及分析,以及如何使用混合量化来优化模型进度,请看具体博文,自此,模型的精度分析工具就介绍完毕了
六、RKNN Toolkit2模型性能分析
对于模型的性能评估都是在具体使用场景中,所以必须使用连板推理的方式来进行评估
6.1 模型性能评估
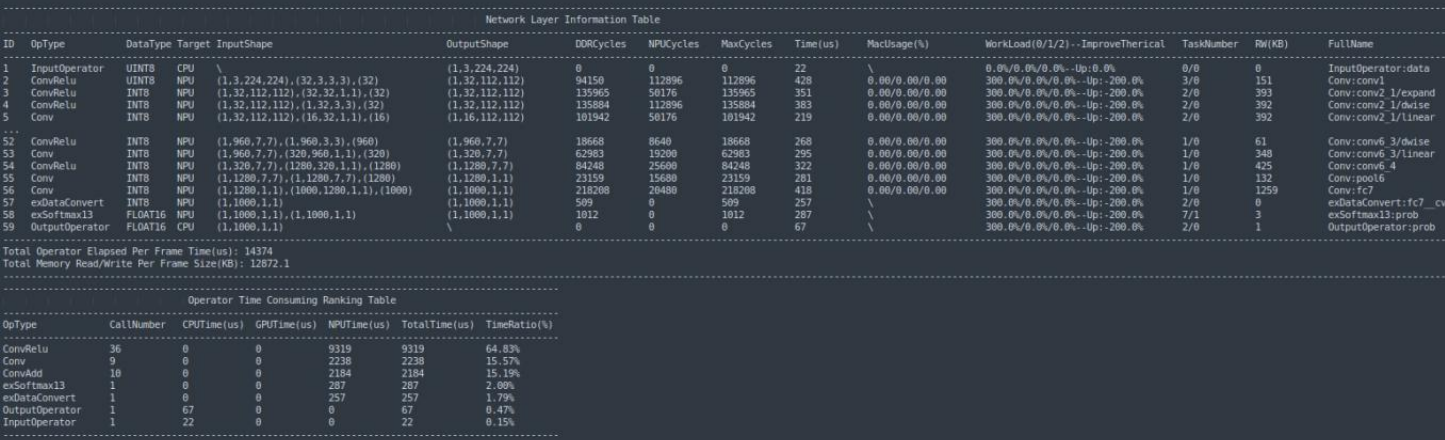
评估模型性能。模型必须运行在与PC连接的嵌入式平台上。如果调用“init_runtime”的接口来初始化运行环境时设置perf_debug为False,则获得的是模型在硬件上运行的总时间;如果设置perf_debug为True,除了返回总时间外,还将返回每一层的耗时情况。
perf_detail = rknn.eval_perf(
# 是否打印性能信息,默认值为True
is_print=True,
# 是否固定硬件设备的频率,默认值为true
fix_freq=True,
)
对应实例代码如下
from tarfile import data_filter
import numpy as np
import cv2
from rknn.api import RKNN
import os
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
rknn.load_rknn(path='./resnet_18.rknn')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(
target="rk3576",
perf_debug=None,
eval_mem=None,
)
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
print('--> Eval model')
rknn.eval_perf()
rknn.release()
最后的打印情况如下:
6.2 模型内存使用情况
使用内存评估时,记得打开init_runtime函数的eval_mem参数,将其设置为True,这一部分可以看见输出各部分的内存消耗情况。
在init_runtime()函数后调用eval_memory()接口函数就可以查看模型的内存使用情况
ret = rknn.init_runtime(target=platform, eval_mem=True)
memory_detail = rknn.eval_memory(
# 是否以规范格式打印内存使用情况,默认值为True。
is_print=True,
)
示例代码如下:
from tarfile import data_filter
import numpy as np
import cv2
from rknn.api import RKNN
import os
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
rknn.load_rknn(path='./resnet_18.rknn')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(
target="rk3576",
perf_debug=True,
eval_mem=True,
)
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
print('--> Eval model')
rknn.eval_memory()
rknn.release()
最后的打印情况如下:
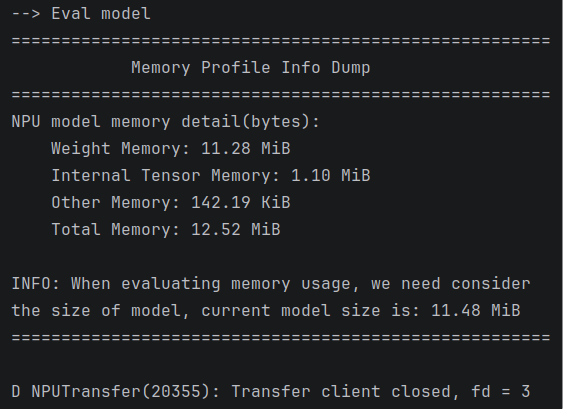
至此,模型的两大评估内容就讲解完成了
遇到的问题
1、在使用连板推理方式时,博主使用rk3576板卡,烧录的buildroot文件系统,一直连板推理不成功,所有工具包括adb,rknn-toolkit2,以及对应运行所需要的环境都是最新并且没问题的,还是无法连板推理,目前最大的嫌疑就是buildroot根文件系统某些功能被裁剪,无法进行连板推理,原因没找到,重新烧录debian系统镜像之后,成功运行连板推理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号