
首先观察、分析网站
网址:https://touch.qunar.com

接下按F12进入浏览器开发者模式,并且点击 自由行 选项进入到自由行频道,如下图:
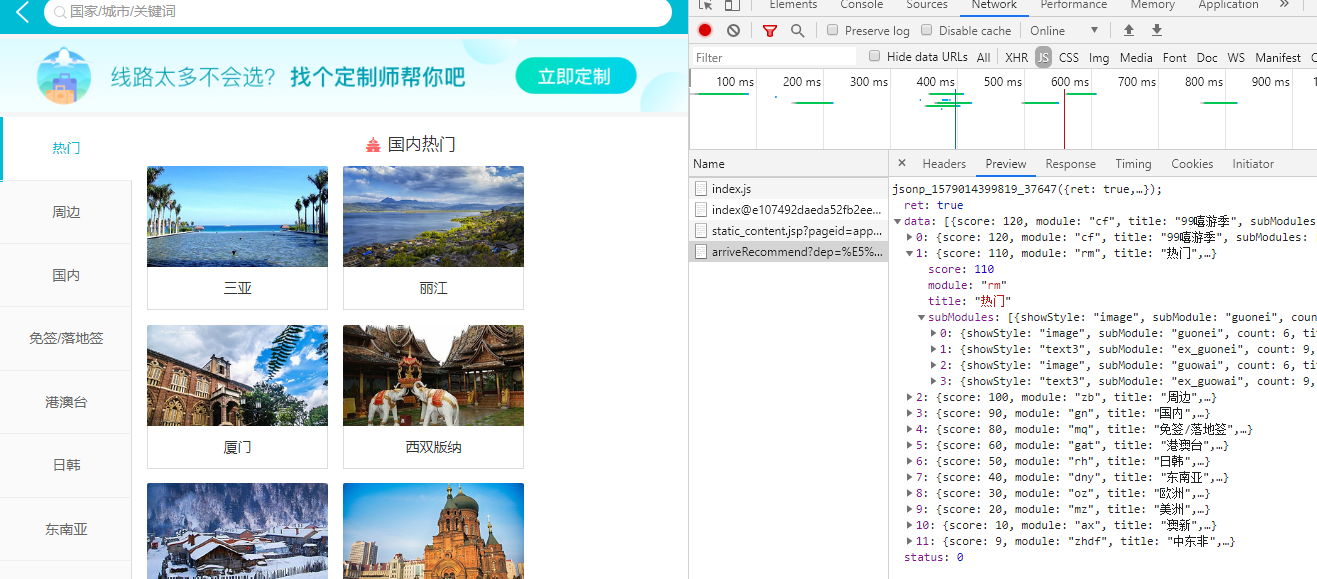



任意点击一张图片,再从开发者模式的header那里查看

可以看到上面的URL是UTF8编码的,解码后就可以看到中文部分了。
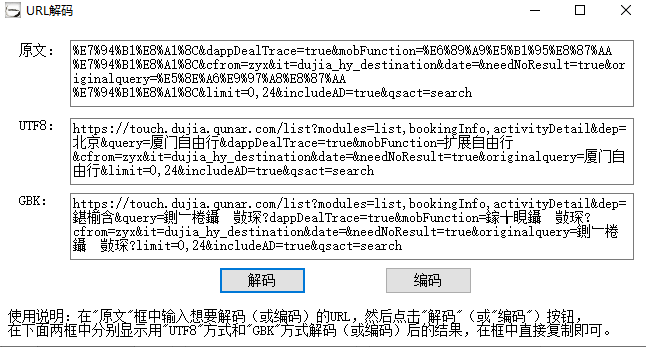
由于这里的目标是获取整个自由行的产品列表,因此还需要获取出发站点的列表,从不同的城市出发,会有不用的产品。
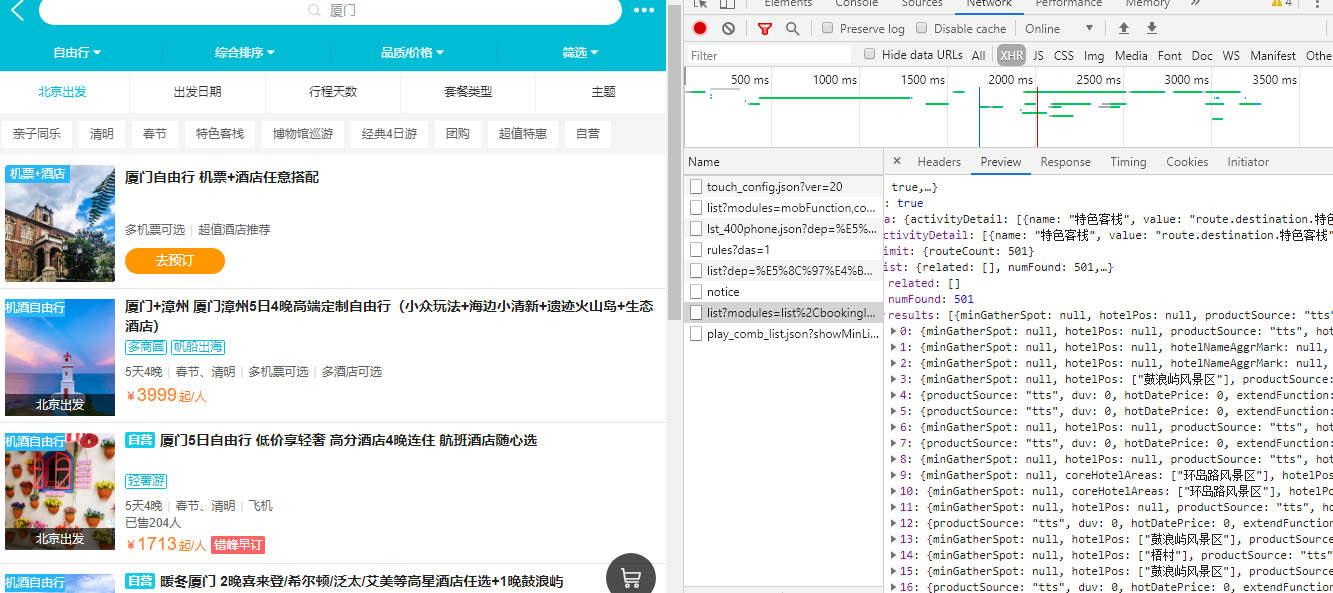
返回自由行的首页,单击搜索框左侧的出发站点,如下图:
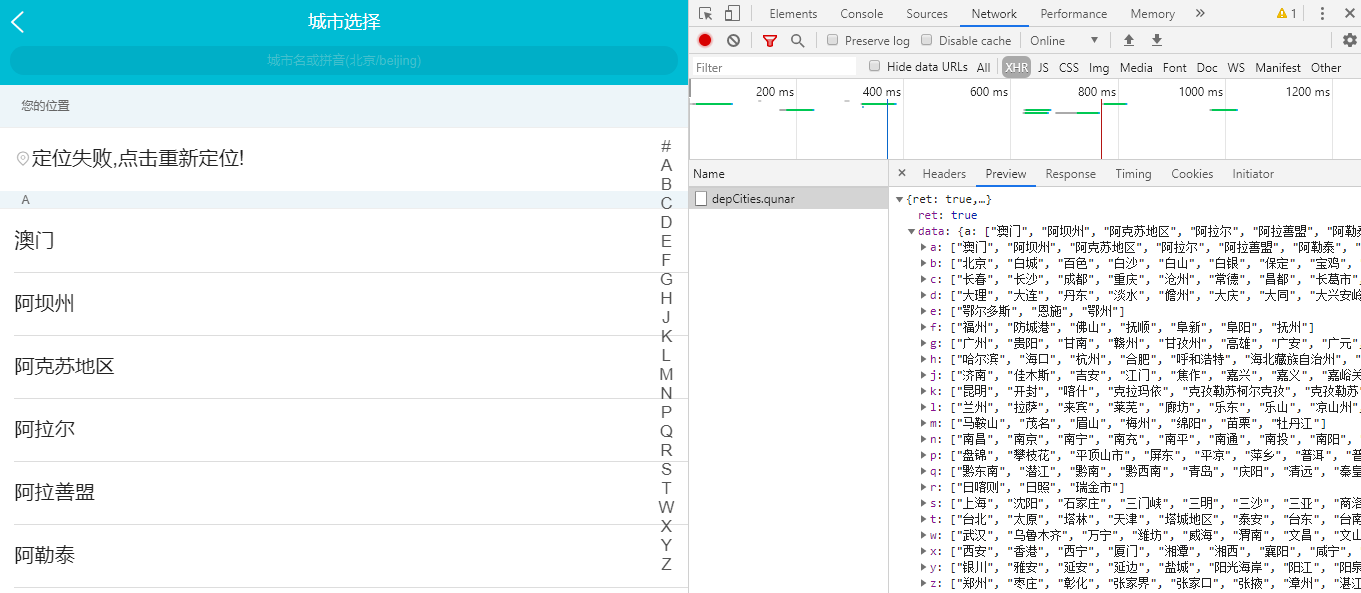
切换到Headers界面:
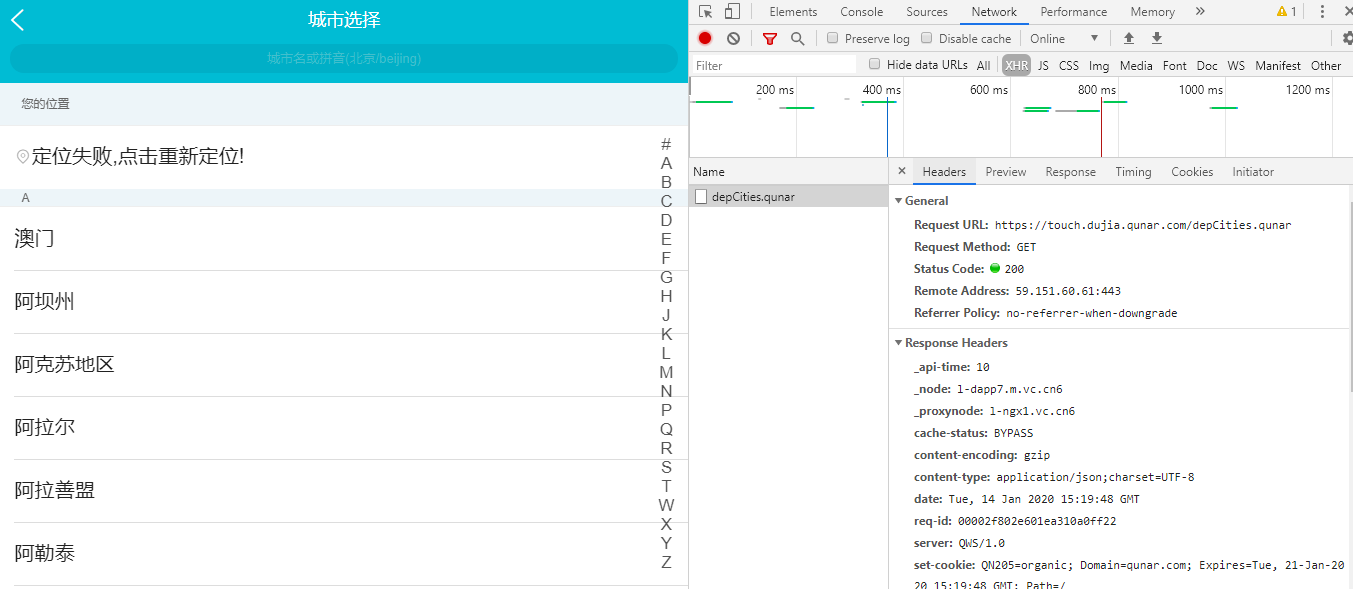
可以看到此时目标的URL是:https://touch.dujia.qunar.com/depCities.qunar
开始分析该网站的爬虫工作流程分析步骤:
1 获取出发地站点列表
2 获取旅游景点列表
3 获取景点产品列表
4 存储数据

#首先获取出发站点,代码如下: import requests url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: print(dep)

。。。。。。。。。

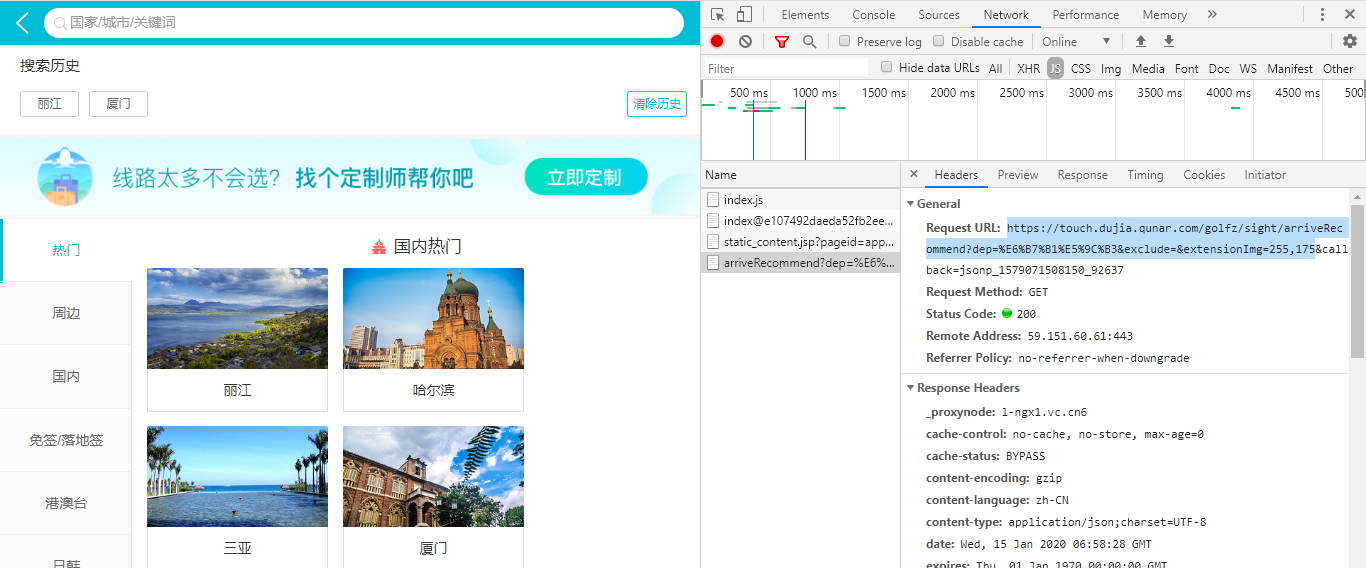
在获取数据的时候需要将最后一个callback参数删掉。因此目标URL如下:
https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep=%E6%B7%B1%E5%9C%B3&exclude=&extensionImg=255,175
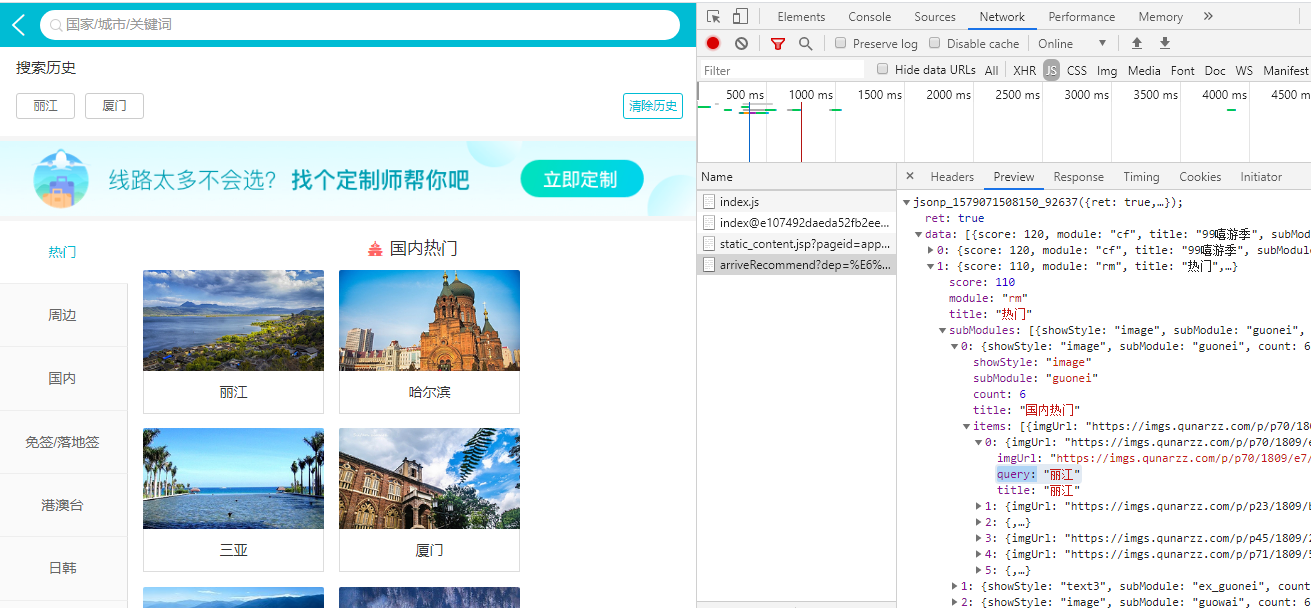
#然后根据出发地站点获取目的地,代码如下: import time import urllib import requests url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: print(dep) url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep)) time.sleep(3) strhtml = requests.get(url) arrive_dict = strhtml.json() for arr_item in arrive_dict['data']: for arr_item_1 in arr_item['subModules']: for query in arr_item_1['items']: print(query['query'])

.................

到达的 目的地有很多,上面这段代码也要运行很长时间,运行截图也是一部分的,篇幅有限还有很多地点没有展示,但很容易看到许多的目的地是重复的,
原因也很简单一个目的地多数都是对应这多个出发点的,按出发点分别来找目的地的话最后打印寻找到的目的地肯定有许多也就是重复的了,所以接下来
就是要对目的地进行去重,代码修改后,如下:
#然后根据出发地站点获取目的地,代码如下: import time import urllib import requests url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: #这里声明一个列表a用来保存当前这个出发点对应的所有目的地 a = [] print(dep) url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep)) time.sleep(3) strhtml = requests.get(url) arrive_dict = strhtml.json() for arr_item in arrive_dict['data']: for arr_item_1 in arr_item['subModules']: for query in arr_item_1['items']: #如果当前这个目的地不在a中的话,那就添加进去,否则不添加,这样就可以达到目的地去重的目的了 if(query['query'] not in a): a.append(query['query']) #打印当前出发点所有对应的不重复的目的地点 print(a)

这样每个出发点对应的目的点打印出来也好看清晰了许多。
完成了出发点和目的地的构建之后,接下来就要获取产品列表了。代码如下:
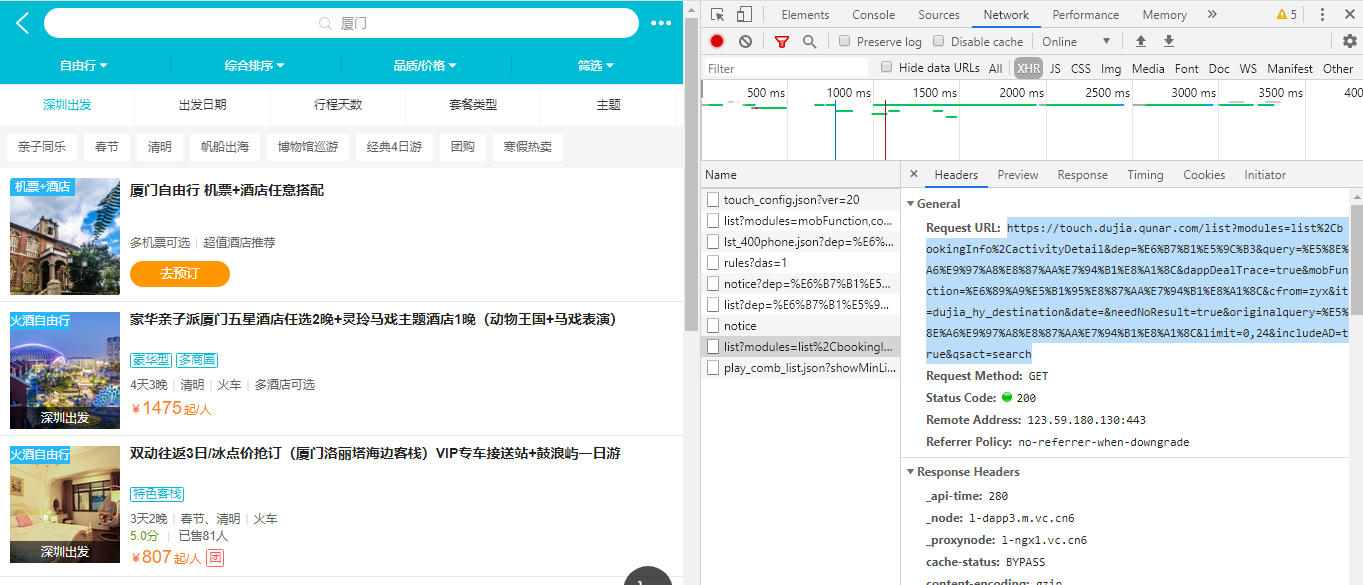
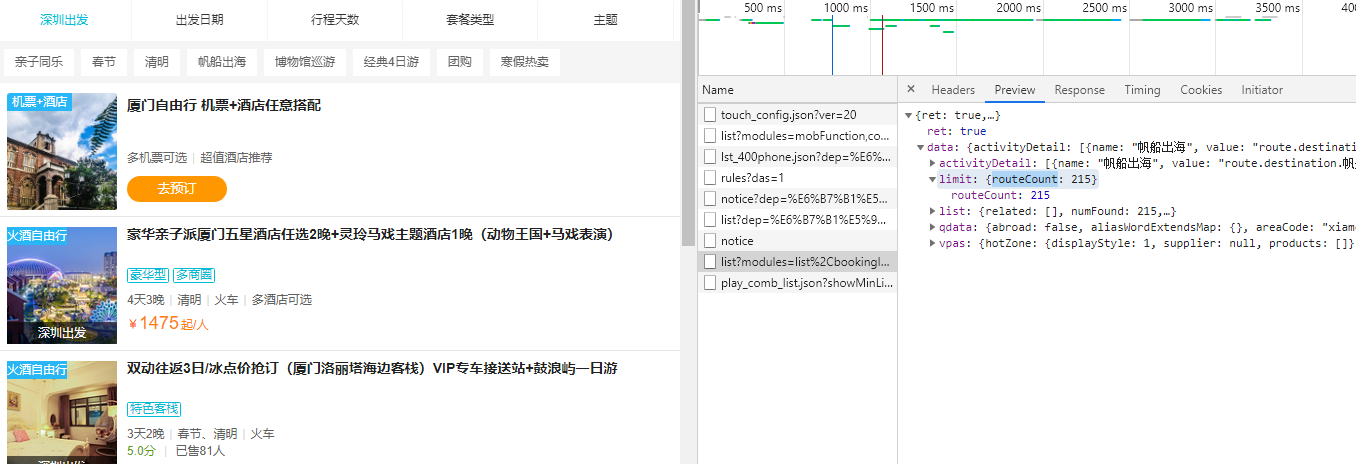
#获取产品列表 import time import urllib import pymongo import requests #使用MongoDB创建数据库、表 client = pymongo.MongoClient('localhost',27017) book_qunar = client['qunar'] sheet_qunar_zyx = book_qunar['qunar_zyx'] #获取产品 url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: #这里声明一个列表a用来保存当前这个出发点对应的所有目的地 a = [] url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep)) time.sleep(3) strhtml = requests.get(url) arrive_dict = strhtml.json() for arr_item in arrive_dict['data']: for arr_item_1 in arr_item['subModules']: for query in arr_item_1['items']: #如果当前这个目的地不在a中的话,那就添加进去,否则不添加,这样就可以达到目的地去重的目的了 if(query['query'] not in a): a.append(query['query']) #逐个地取出当前出发点对应的目的地item for item in a: url = 'https://touch.dujia.qunar.com/list?modules=list%2CbookingInfo%2CactivityDetail&dep={}&query={}&dappDealTrace=true&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=dujia_hy_destination&date=&needNoResult=true&originalquery={}&limit=0,24&includeAD=true&qsact=search'.format(urllib.request.quote(dep),urllib.request.quote(item),urllib.request.quote(item)) time.sleep(3) strhtml = requests.get(url) #获取当前目的地的产品数量 routeCount = int(strhtml.json()['data']['limit']['routeCount']) for limit in range(0,routeCount,24): url = 'https://touch.dujia.qunar.com/list?modules=list%2CbookingInfo%2CactivityDetail&dep={}&query={}&dappDealTrace=true&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=dujia_hy_destination&date=&needNoResult=true&originalquery={}&limit={},24&includeAD=true&qsact=search'.format(urllib.request.quote(dep),urllib.request.quote(item),urllib.request.quote(item),limit) time.sleep(3) strhtml = requests.get(url) #用一个字典保存当前这个产品的信息 result = { 'date':time.strftime('%Y-%m-%d',time.localtime(time.time())), 'dep':dep, 'arrive':item, 'limit':limit, 'result':strhtml.json() } #向数据库中插入这条产品信息记录 sheet_qunar_zyx.insert_one(result) print('成功!')
爬取的数据量是非常大的 代码需要运行非常长的时间,运行代码打开pycharm就可以观察到保存的数据了(前提是pycharm已经安装好了mongo的插件了以及本地安装配置好mongodb了)


