
OO第一单元总结
OO第一单元总结
一、第一次作业
1、类图
第一次作业的类图为下图白色部分:
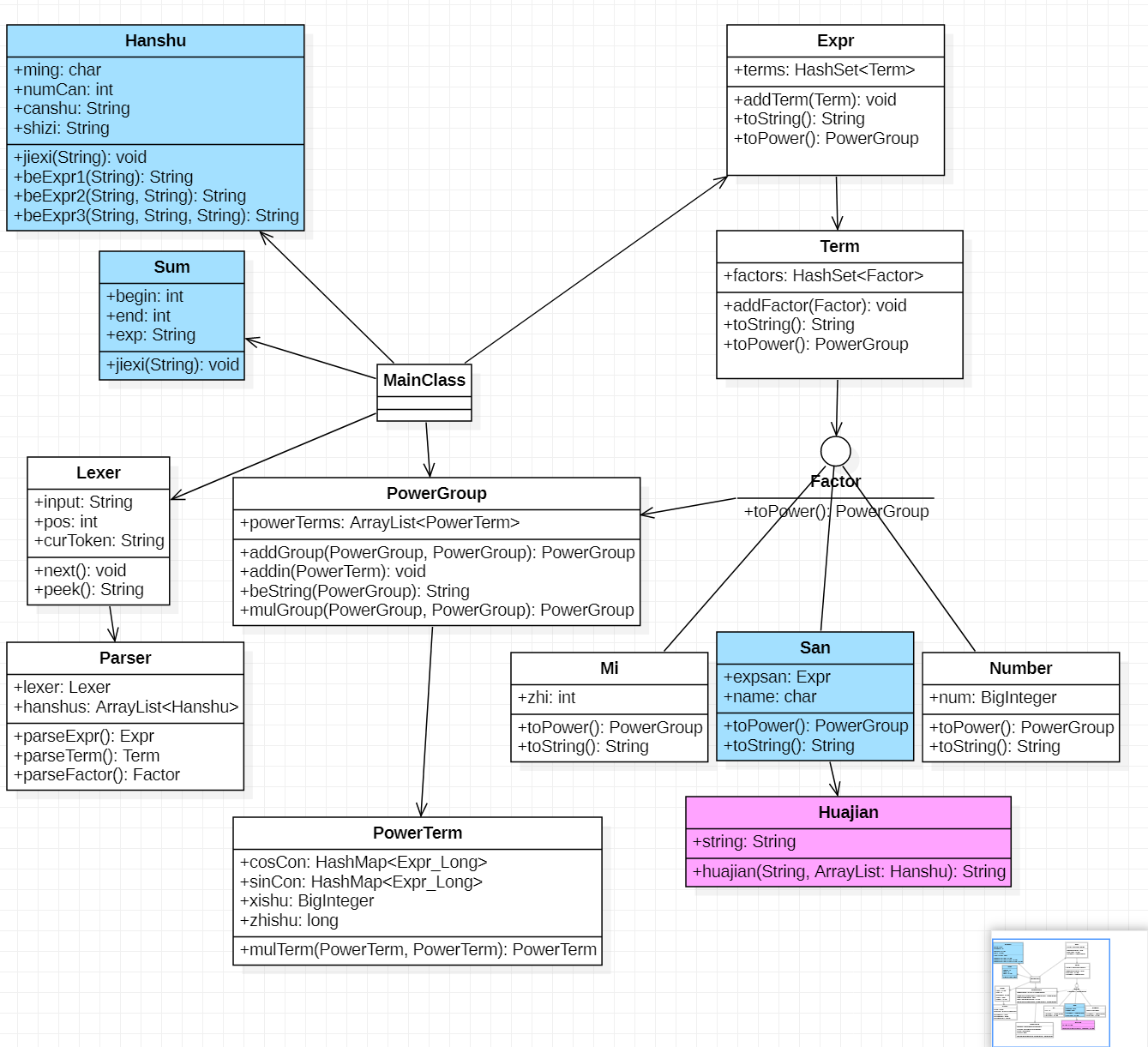
优点:采用了递归下降的方法对表达式进行解析,层次鲜明,代码相对简单。
缺点:对表达式的预处理采用字符串操作,容易出现意料之外的bug,且预处理部分选择了面向过程编程,导致main函数很长。
2、架构设计
为了便于解析,我将表达式看成了项的和,并没有差的概念,这就使得我需要对加减号进行处理,即把“-项”变为“+-项”。对此,我选择了对所有的正负号进行处理,通过正则表达式和一些字符串操作,使得预处理之后的表达式满足以下要求:1、所有项之间有且仅有一个“+”;2、所有的常数因子均为带单个符号的整数。
受到了第一次实验的启发,我选择了采用递归下降的方法来对表达式进行解析:表达式可看作是若干个项的和,而项可看作是若干个因子的乘积,如此鲜明的层次为递归下降提供了很好的环境。
之后,我选择了将因子进行形式上的统一:a*x**b ,在此基础上,项和表达式也可以进行形式上的统一,也就是类图中出现的PowerTerm类和PowerGroup类。有了形式的统一,表达式最后便是一个PowerGroup的实例,通过重写的toString方法即可输出。
3、度量分析
我使用了IDEA的MetricsReload插件做度量分析:
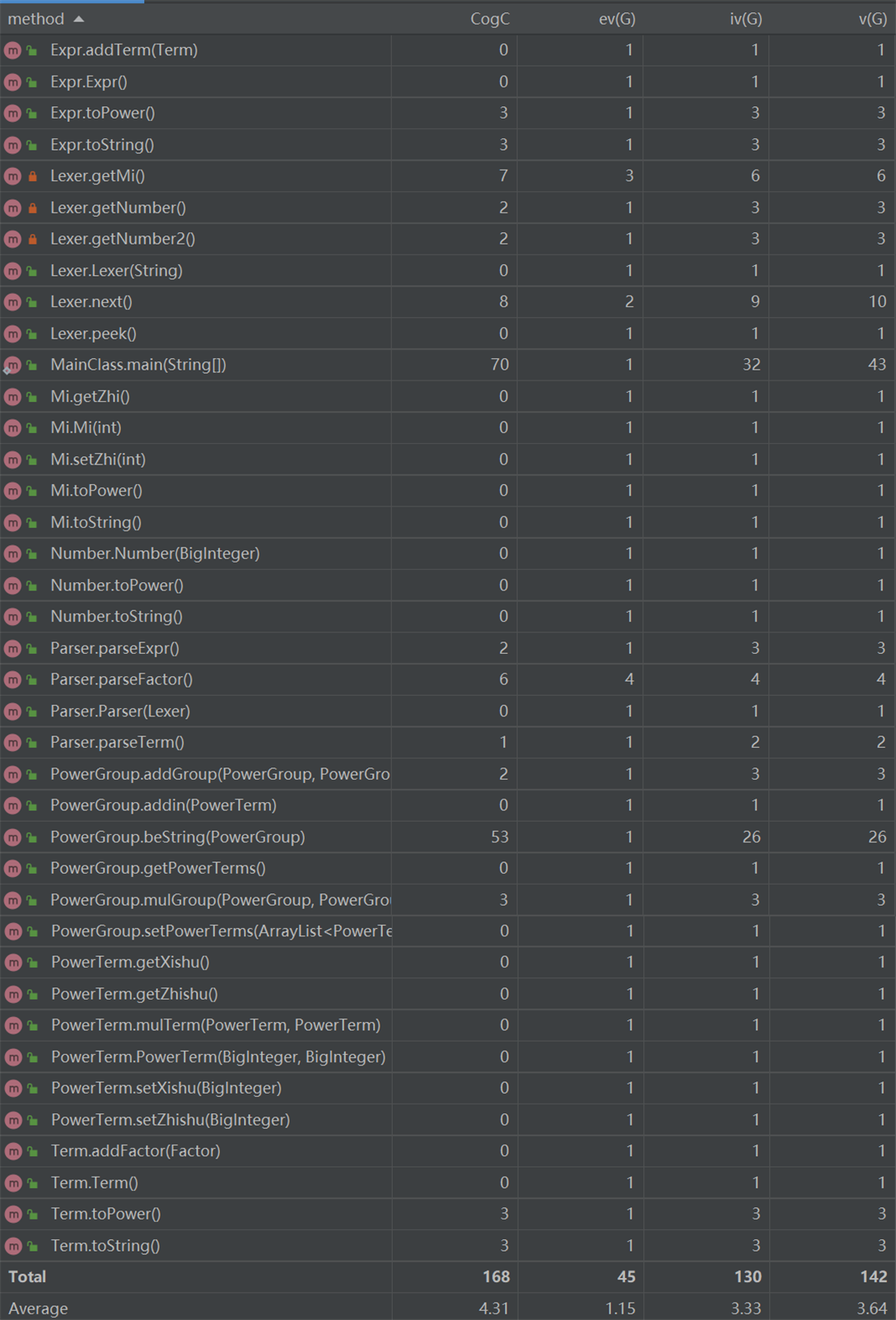
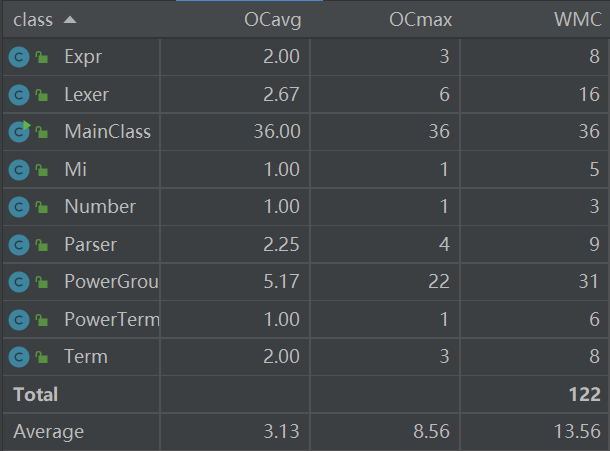
从中可看出,MainClass复杂度显著高于其他类,这源于我对表达式的预处理基本上是面向过程编程,且采用了大量的字符串操作,尤其是正负号处理那一块。
二、第二次作业
1、类图
第二次作业的类图为下图白色部分+蓝色部分:
优点:基本上就是在第一次作业的基础上进行了增量开发;同样采用了递归下降的方法对表达式进行解析,层次鲜明,代码相对简单。
缺点:关于自定义函数和求和函数的处理,我还是选择将它们放在预处理部分通过字符串操作处理掉了,有较大的隐藏风险。
2、架构设计(迭代过程)
在第二次作业的起步阶段,我就自认为第一次作业的架构是有着较高的可拓展性的,因此我的方向不是重写而是增量开发。
通过两次作业的对比,我认为第二次作业的难点在于在第一次作业的基础上增加了三角函数、求和函数、自定义函数,至于指数限制等等不足为惧。
对于求和函数和自定义函数,生性较为懒惰的我选择了字符串替换来处理(为第三次作业埋下了苦果),具体操作在此不作赘述。
对于三角函数,我在前期的很长一段时间都无法想到一个很(简)好(单)的方法对其进行处理:第一次作业所有的因子都可以转化为a*x**b的统一形式,且该形式的运算非常简便,但是本次作业的三角函数完全不符合这个形式,且三角函数的运算往往是无法合并的,很多情况下只能和原本的项通过乘号堆叠起来。最后,讨论区里林嘉宁同学的方法让我眼前一亮:既然三角函数容易堆叠起来,那就干脆直接用一个容器来储存一个项的三角函数部分,而项仍然可拥有一个统一形式:幂函数x容器,而这个改变,仅仅需要我们对PowerTerm和PowerGroup这两个类进行修改即可。
3、度量分析
我使用了IDEA的MetricsReload插件做度量分析:
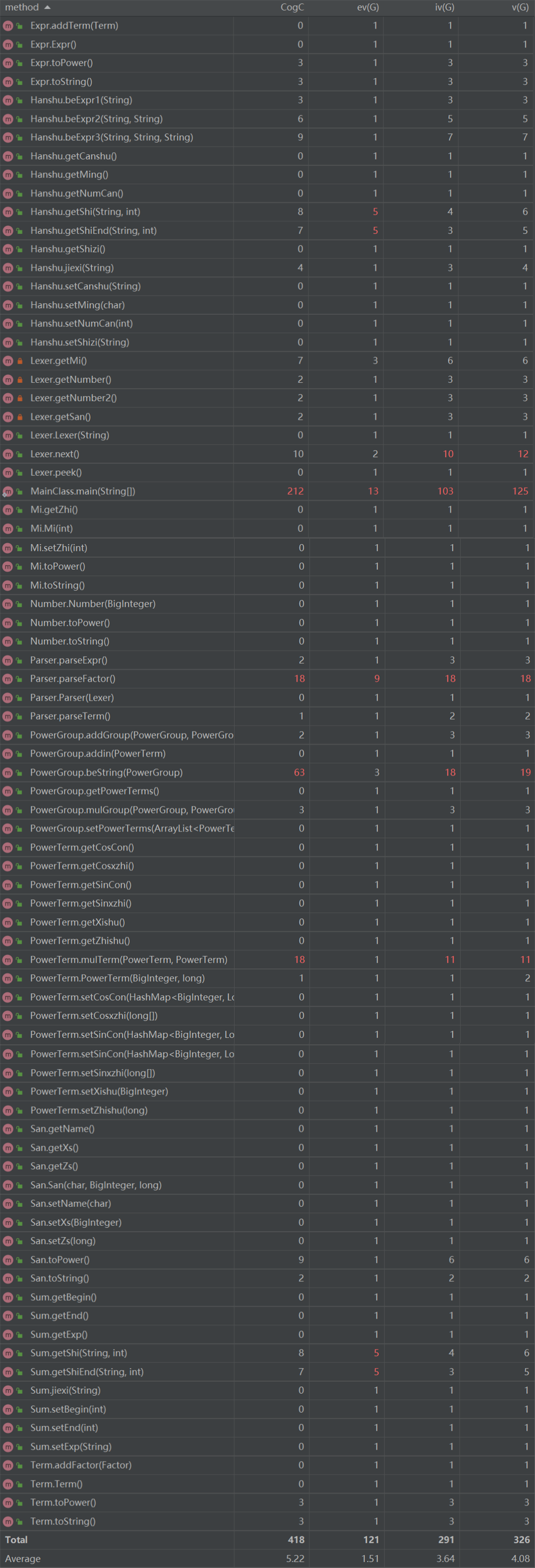
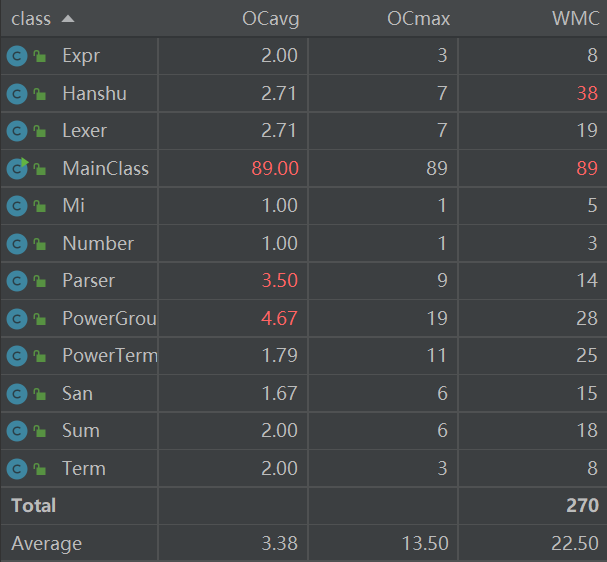
从中可看出,MainClass复杂度比第一次作业更加恐怖,这一变化主要源于我把对自定义函数和求和函数的操作也变成了主函数中的、面向过程的字符串操作。
三、第三次作业
1、类图
第三次作业的类图为下图所有部分:
优点:延续了前两次作业的架构;递归下降可以无视括号的多重嵌套,不受其影响。
缺点:对表达式的预处理仍然采用了字符串操作,包括嵌套的自定义函数也是这样处理。
2、架构设计(迭代过程)
由于采用的是递归下降的解析方法,括号嵌套不足为惧;我认为最大的麻烦是三角函数括号内不再像第二次作业一样限定了只能是幂函数因子或常数因子,而是可以是表达式,这就使得第二次作业采用的统一形式再次失效,除此之外,三角函数内部的表达式也可能需要我们进行去括号处理,不能直接暴力原样输出。
分析了问题所在,生性懒惰的我经过思考,决定依旧采用第二次作业中项的统一形式,不同的是,我将三角函数因子的统一形式在三角函数类,也就是San类中进行了修改,把三角函数简单地统一为name+expsan的形式,前者用于判断该三角函数的类型,后者则是括号内的表达式整体。
那么,新的问题来了,如何对三角函数中的表达式进行化简?生性懒惰的我选择了将主函数基本上都Ctrl+C、Ctrl+V到了一个新的方法类——Huajian中的huajian方法中,这样三角函数中的表达式化简就相当于递归调用了整个项目。
3、度量分析
我使用了IDEA的MetricsReload插件做度量分析:

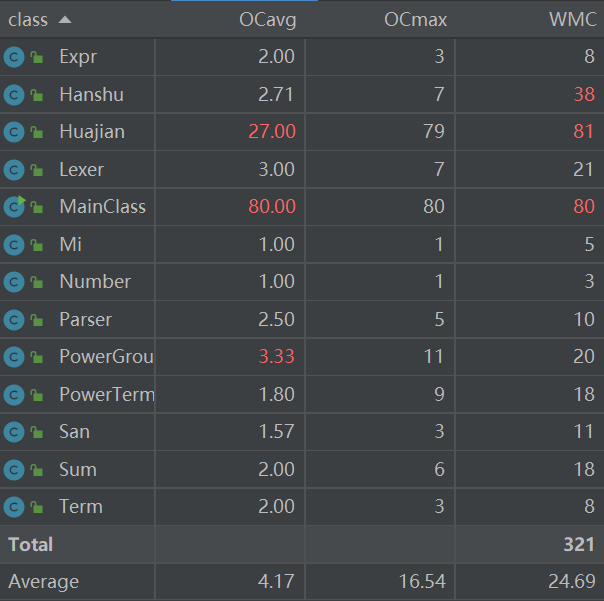
从中可看出,MainClass复杂度与第二次作业相差不大,但是平均值高了不少,这源于我创建的新类Huajian中的huajian方法包含了MainClass中的大量代码,且本方法的调用为递归调用,导致本次作业整体复杂度较高。
四、自身bug分析
综合三次作业来看,我出现的bug主要有以下几种:
1、代码复制粘贴后修改有遗漏,导致第二次作业三角函数在大多数情况一律输出为cos函数(尽管我不能理解这居然过了中测),这种无脑bug在此就不多分析了。
2、预处理中的正负号处理仍然有遗漏,嵌套在自定义函数中的自定义函数如果有逗号会出现问题。出现在MainClass类中的主方法。
3、sum函数的起始点与终点采用了int,无法应对大数据。出现在Sum类中的属性设计。
4、删除字符串最后一个字符时使用了删除length()-1位置字符的方法,如果字符串为空的话就会直接出错。出现在PowerGroup类中的beString方法。
对比分析出现了bug的方法和未出现bug的方法在代码行和圈复杂度上的差异,我发现出现bug的方法的圈复杂度往往更高。
当然,我的主函数采用的风格基本上是面向过程,圈复杂度高不可避免,而其中包含了大量操作,出现bug的概率自然也更高,因此上述结论仅供参考。
五、互测策略
在3次互测中,我都选择了同一种策略:先测试一些边缘数据(差不多是广撒网的想法),如果都没成功的话再逐一查看代码。
在查看代码的过程中,我并没有分析全部的代码,而是集中观察几个容易出bug的部分:1、指数、sum的起始点与终点的数据类型或范围;2、表达式预处理部分的字符串操作;3、拆完括号后的表达式的化简部分中的字符串操作。
经过这三周,我个人认为根据代码构造bug数据的效率并不比直接数据轰炸低。
(不过,对于选择了第二种输入方式的代码,生性懒惰的我选择了直接放弃,这也算是一个遗憾了hhh)
六、心得体会
这一单元中,我最大的体会就是:一个好的架构设计非常重要!!!
什么才算好?目前的我认为它至少要满足一点:可拓展性要强。在这三次作业中,我基本是沿用了第一次作业的架构,之后的两次作业仅仅是对其进行局部修改、增量开发,基本上没有出现重写的惨烈状况,因此,我可以算是好的架构的受益者了。
不过,我的漏洞也是极其明显的:我的预处理部分统统选择了字符串操作,而且是面向过程编程(可能是我爱C语言爱得深沉……)。这不仅导致第三次作业出现了一些bug,而且导致MainClass类极其冗长。
因此,在之后的课程学习中,我会继续选择一个可拓展性强的架构进行编程,尽量避免重写的悲剧发生;同时,我会尽可能地纠正我在JAVA里面向过程编程的恶习,让自己的代码风格好起来!
PS:一个大家可能都不知道的东西
我可以告诉大家一个代码风格的扣分点,一个文件的代码量不能超过600行,要不然会扣50分,至于我是怎么知道的,请琢磨上文中“MainClass类极其冗长”这句话……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号