
聚簇索引和二级索引
千里之行,始于足下。
—— 老子
索引可以分成聚簇索引和非聚簇索引(二级索引),它们的区别就在于叶子节点存放的是什么数据:
- 聚簇索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚簇索引的叶子节点;
- 二级索引的叶子节点存放的都是主键值,而不是实际数据。
因为表的数据都是存放在聚簇索引的叶子节点里,所以InnoDB存储引擎一定会为表创建一个聚簇索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个。
InnoDB在创建聚簇索引时,会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键;
- 如果没有主键,就选择第一个不包含NULL值的唯一列作为聚簇索引的索引键;
- 在上面两个都没有的情况下,InnoDB将自动生成一个隐式自增ID列作为聚簇索引的索引键;
一张表只能有一个聚簇索引,那为了实现非主键字段的快速搜索,就引出了二级索引(二级索引/辅助索引),它也是利用了B+树的数据结构,但是二级索引的叶子节点存放的都是主键值,不是实际数据。
二级索引的B+树如下图,数据部分为主键值:
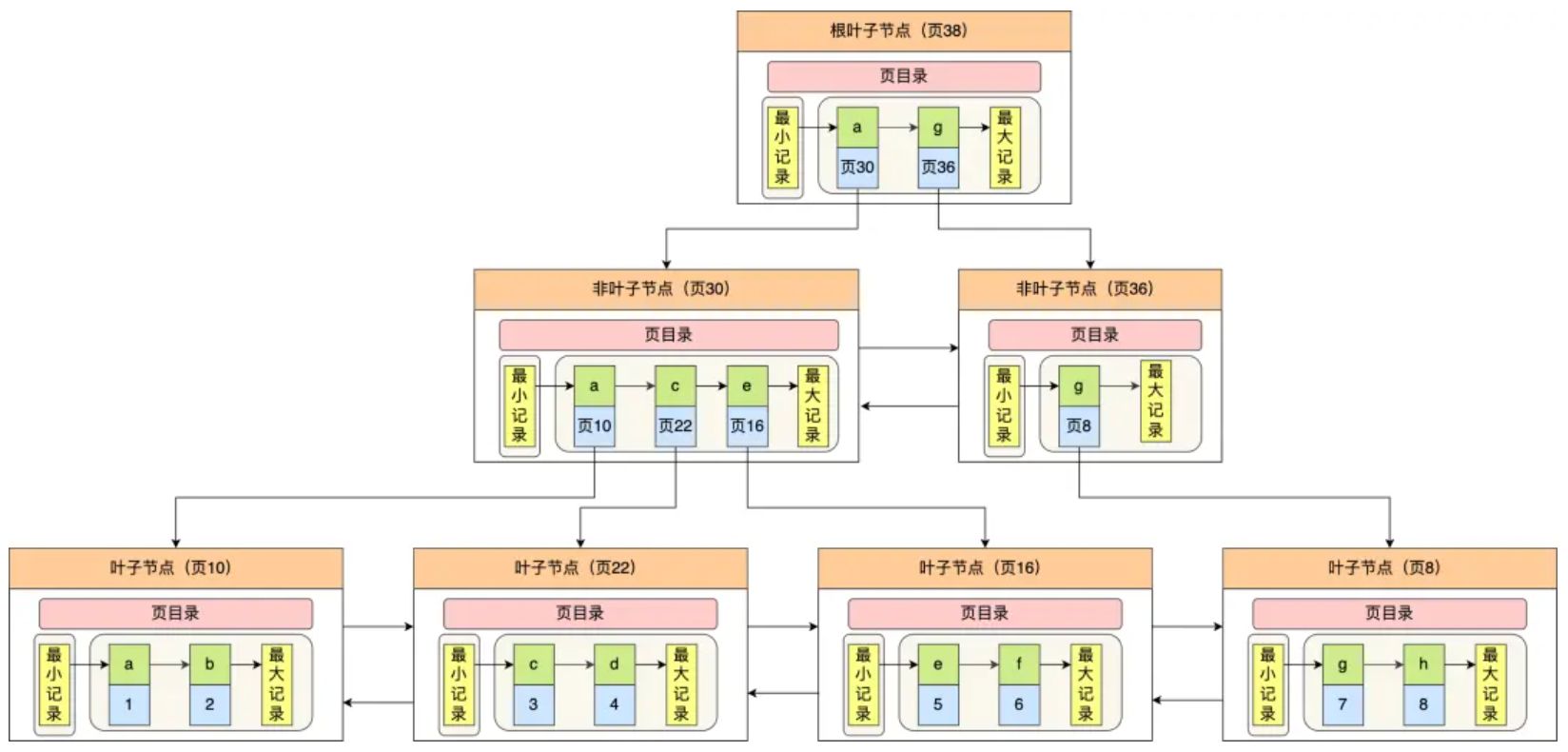
因此,如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程就叫作 回表 ,也就是说要查两个B+树才能查到数据。不过,当查询饿数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程就叫作 索引覆盖,也就是只需要查一个B+树就能找到数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号