

利用python爬取全国水雨情信息
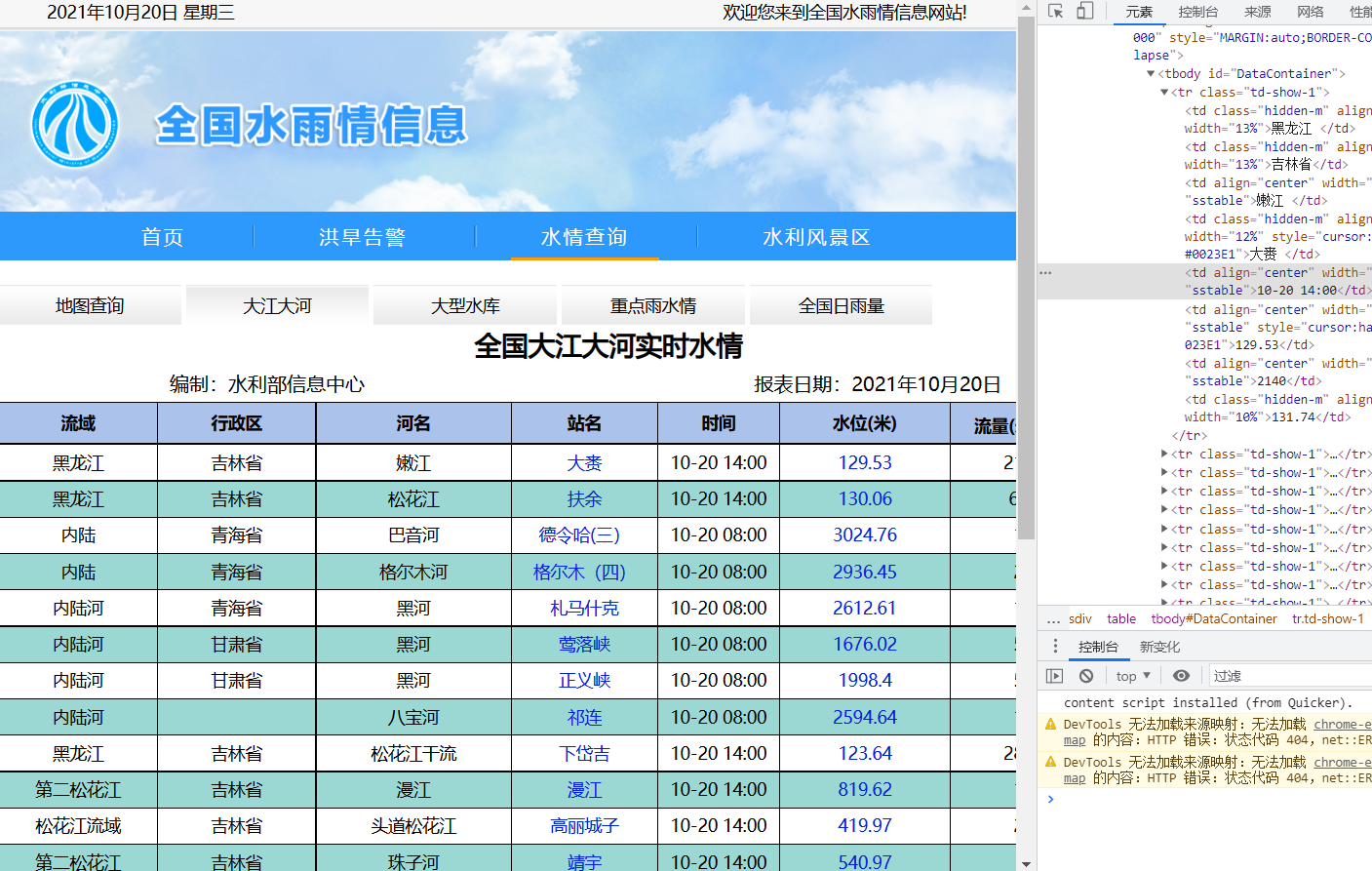
分析
我们没有找到接口,所以打算利用selenium来爬取。
代码
import datetime
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options #建议使用谷歌浏览器
import time
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome()
# 存储中英文对应的变量的中文名
word_dict = {"poiBsnm": "流域",
"poiAddv": "行政区",
"rvnm": "河名",
"stnm": "站名",
"tm": "时间",
"zl": "水位(米)",
"ql": "流量(立方米/秒)",
"wrz": "警戒水位(米)"}
# 空df接收结果
rain_total = pd.DataFrame([])
url = 'http://xxfb.mwr.cn/sq_dxsk.html'
driver.get(url)
time.sleep(5)
infos = driver.find_elements_by_xpath("/html/body//tbody[@id='DataContainer']/tr")
# pd.set_option('display.max_columns', None)#所有列
# pd.set_option('display.max_rows', None)#所有行
# 列表提取
for info in infos:
poiBsnm = info.find_element_by_xpath("./td[1]").text
poiAddv = info.find_element_by_xpath("./td[2]").text
rvnm = info.find_element_by_xpath("./td[3]").text
stnm = info.find_element_by_xpath("./td[4]").text
tm = info.find_element_by_xpath("./td[5]").text
zl = info.find_element_by_xpath("./td[6]").text
ql = info.find_element_by_xpath("./td[7]").text
wrz = info.find_element_by_xpath("./td[8]").text
# 组成pandas对象
rain_data = [[poiBsnm,poiAddv,rvnm,stnm,tm,zl,ql,wrz]]
rain_df = pd.DataFrame(data=rain_data,columns=list(word_dict.values()))
rain_total = pd.concat([rain_total,rain_df])
print(rain_total)
# 关闭浏览器
driver.close()
# 保存数据
data_str = datetime.datetime.now().strftime('%Y_%m_%d')
rain_total.to_csv("%s_全国水雨情信息.csv" % (data_str),index=None, encoding="GB18030")
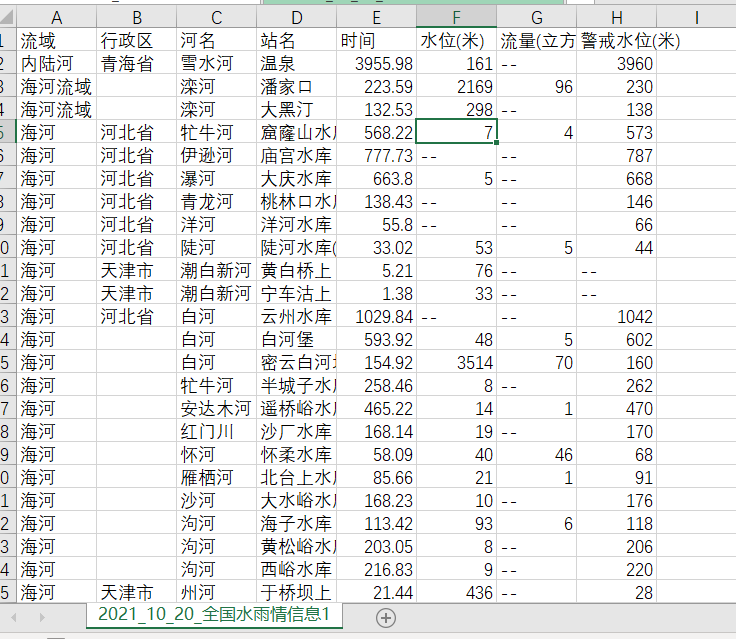
结果
反思
时间爬取出现了一点问题,我也很不理解,其次,循环哪里应该可以简洁代码,写的不是很好,第三,没有形成模块化的代码。还有就是谢谢崔工的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号