实时日志分析平台搭建笔记
基于 ELK 构架的日志收集平台,很多公司都搭建好了,但 ELK 只是做到了收集存储,缺少了分析功能。博主作为信息安全从业人员,需要对所有收集的日志进行安全分析,给出处理结果,这样才算完成一个闭环。正好目前所在的公司也准备启动日志分析工作,所以最近研究了日志分析平台。日志分析平台主要目的是收集生产和办公系统中产生的各种日志(目前主要是 access log 和系统日志,可能后期还会包含防火墙等设备的日志),实时的做出分析,找出风险,及时预警。结合 ELK 以及同行老司机们的经验,目前暂时的构架如下,目前只是在完成了测试环境的简单测试 demo,但还有很多未研究或者未解决的问题(例如如何将不同日志存入不同的 kafka topic 中),有待后续逐渐完善,写个博客作为笔记。
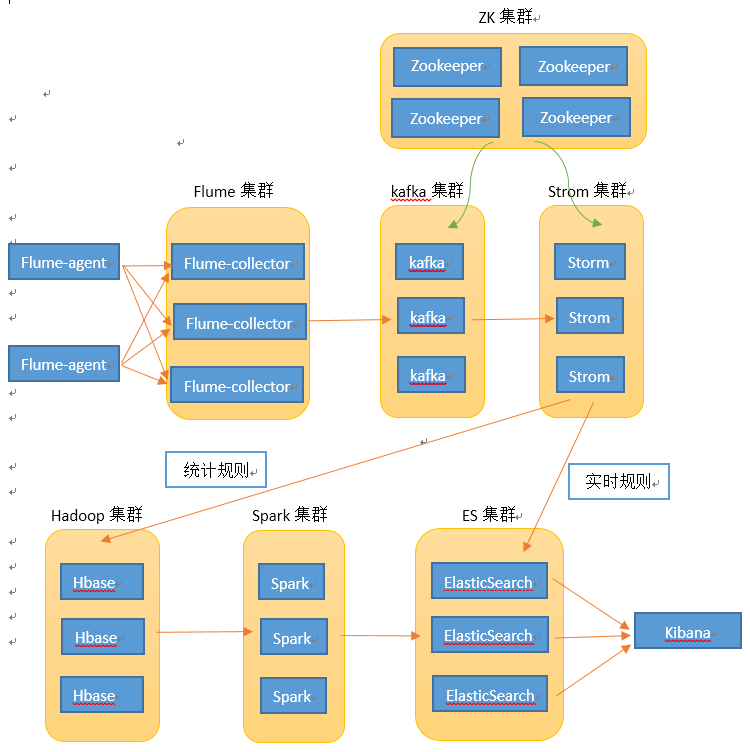
主要思路是收集日志采用 flume,日志可通过 syslog 等方式传输给 flume,在 flume 中汇总后,存入 kafka 中,然后 storm 去读取 kafka 的日志,在 storm 中运行一些实时检测的安全规则(例如 owasp top 10 的一些内容项),如果检测到一条日志存在风险,就直接扔到 es 里,另外不管日志是否有风险,都会扔到 Hbase 中。spark 上会运行一些基于统计的规则,spark 运行完成后,也会将有问题的日志写入 elasticsearch 中,最后暂且使用 kibana 进行展示。以上各组建都采用集群方式进行运行,可有效避免单机故障。
测试环境中目前采用 accesslog 进行测试,accesslog 日志格式如下:

200.110.75.247 - [03/Jul/2017:10:56:34 +0800] "POST /social/getDropsById.htm HTTP/1.1" "id=9" 500 1483 0.745 "http://192.168.32.33/social/showDrops.htm?id=3" "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
flume-agent 中采用的 conf 文件如下:
mysyslog.sources = s1 mysyslog.channels = c1 mysyslog.sinks = output36 output37 mysyslog.sinkgroups = g1 mysyslog.sources.s1.type = syslogudp mysyslog.sources.s1.port = 5140 mysyslog.sources.s1.host = 192.168.32.33 mysyslog.sources.s1.channels = c1 mysyslog.channels.c1.type = memory mysyslog.channels.c1.capacity = 500 mysyslog.channels.c1.transactionCapacity = 100 mysyslog.sinks.output36.type = avro mysyslog.sinks.output36.hostname = 192.168.32.36 mysyslog.sinks.output36.port = 12888 mysyslog.sinks.output37.type = avro mysyslog.sinks.output37.hostname = 192.168.32.37 mysyslog.sinks.output37.port = 12888 mysyslog.sinks.output36.channel = c1 mysyslog.sinks.output37.channel = c1 mysyslog.sinkgroups.g1.sinks = output36 output37 mysyslog.sinkgroups.g1.processor.type = load_balance mysyslog.sinkgroups.g1.processor.backoff = true mysyslog.sinkgroups.g1.processor.selector = random flume-collector 在测试环境中主要有两台机器,分别上 192.168.32.36 和 192.168.32.37,其中一台的 conf 文件如下: collector36.sources = avro-in collector36.channels = mem-channel collector36.sinks = kafka-out # For each one of the sources, the type is defined collector36.sources.avro-in.channels = mem-channel collector36.sources.avro-in.type = avro collector36.sources.avro-in.bind = 192.168.32.36 collector36.sources.avro-in.port = 12888 # Each sink's type must be defined collector36.sinks.kafka-out.type = org.apache.flume.sink.kafka.KafkaSink collector36.sinks.kafka-out.kafka.bootstrap.servers = 192.168.32.36:9092,192.168.32.37:9092 collector36.sinks.kafka-out.kafka.topic = nginx-accesslog collector36.sinks.kafka-out.kafka.producer.acks = 1 collector36.sinks.kafka-out.channel = mem-channel # Each channel's type is defined. collector36.channels.mem-channel.type = memory
flume 主要是收集日志,flume 本身就支持多种日志接收方式,例如常见的通过 rsyslog 发送日志。日志经过 flume 收集汇总后写入到 kafka 集群中。kafka、jstorm、hadoop 这些集群需要 zookeeper 来管理,所以准备了四台机器搭建一个 zookeeper 集群。其中一台的配置文件如下
# The number of milliseconds of each tick tickTime=3000 The number of ticks that the initial synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/zookeeper/mydata # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.33=192.168.32.33:2888:3888 server.35=192.168.32.35:2888:3888 server.36=192.168.32.36:2888:3888
在 kafka 中创建一个 topic:nginx-accesslog,flume 汇总的 accesslog 全部写入该 topic 中。kafka 的主要目的是暂存所有的日志,随后,jstorm 会去 kafka 读取需要的日志并进行处理。
bin/kafka-topics.sh --create --zookeeper 192.168.32.33:2181,192.168.32.34:2181,192.168.32.35:2181,192.168.32.36:2181/kafka --replication-factor 3 --partitions 4 --topic nginx-accesslog
随后的 jstorm 和 spark 才是日志分析的关键所在。jstorm 被定义为实时日志分析,每条日志会作为一个单独的个体被分析,所以在 jstorm 中主要是漏洞 POC 匹配的规则,例如 sql 注入,XSS 等规则。而 spark 中主要运行统计分析规则,这些规则需要基于多条日志进行分析,例如 3 分钟内,某个 IP 访问量超过 N 次或者非 200 响应次数超过 M 次等。
jstorm 主要有 3 台服务器组成一个集群。目前运行一个 demo 程序,demo 程序首先会把读取到的 accesslog 写入到 hbase 库中,随后依次检测 SQL 注入、XSS、远程目录包含、本地目录包含四大类漏洞,如果判定某条日志存在安全风险,则写入 ES 中。

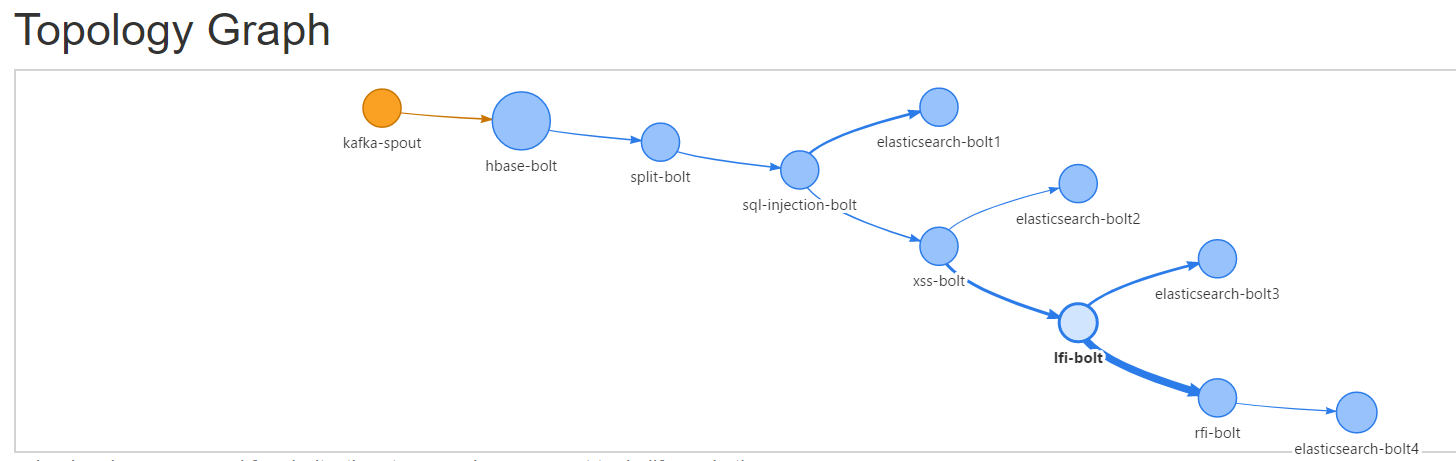
目前是一条日志直接写入到 hbase 的一条记录,不做拆分。Hbase 中的 rowkey 采用 yyyy-MM-dd'T'HH:mm:ssZZ + i。AccessHbaseBolt 代码如下:
package com.jiyufei.hlas.bolt; import java.io.IOException; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Locale; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; /* *Created by jiyufei on 2017年3月27日 上午9:46:08 . */ public class AccessHbaseBolt extends BaseRichBolt { private static final long serialVersionUID = 4431861248787718777L; private final Logger logger = LoggerFactory.getLogger(this.getClass()); private OutputCollector collector; private TableName tableName; private Connection connection; private String columnFamily = "access"; private Table table; private Integer i; @Override public void execute(Tuple tuple) { String log = tuple.getString(0); String rowKey = null; Date time = null; SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ssZZ"); SimpleDateFormat sdf = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss ZZ",Locale.ENGLISH); String pattern = "((\\d+\\.){3}\\d+)\\s(\\S+)\\s\\[(.+)\\]\\s(.*)"; Matcher m = Pattern.compile(pattern).matcher(log); if(m.find()){ try { time = sdf.parse(m.group(4)); rowKey = sdf2.format(time); } catch (ParseException e1) { e1.printStackTrace(); } }else{ rowKey = sdf2.format(new Date()); } Put put = new Put(Bytes.toBytes(rowKey + "|" + i)); put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("info"), Bytes.toBytes(log)); try { table.put(put); } catch (IOException e) { //e.printStackTrace(); logger.error("[AccessHbaseBolt.execute]" + e.getMessage()); } collector.emit("accesslogStream",tuple,new Values(log)); collector.ack(tuple); if(i > 99999){ i = 10000; }else{ i++; } } @Override public void prepare(@SuppressWarnings("rawtypes") Map config, TopologyContext context, OutputCollector collector) { this.collector = collector; tableName = TableName.valueOf("accesslog2"); Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.quorum", "192.168.32.33,192.168.32.34,192.168.32.35,192.168.32.36"); configuration.set("hbase.zookeeper.property.clientPort", "2181"); i = 10000; try { connection = ConnectionFactory.createConnection(configuration); Admin admin = connection.getAdmin(); if(admin.tableExists(tableName)){ System.out.println("table exists"); }else{ HTableDescriptor tableDescriptor = new HTableDescriptor(tableName); tableDescriptor.addFamily(new HColumnDescriptor(columnFamily)); admin.createTable(tableDescriptor); } table = connection.getTable(tableName); //BufferedMutatorParams params = new BufferedMutatorParams(tableName); //mutator = connection.getBufferedMutator(params); } catch (IOException e) { //e.printStackTrace(); logger.error("[AccessHbaseBolt.prepare]" + e.getMessage()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declareStream("accesslogStream",new Fields("accesslog")); } public void cleanup(){ try { table.close(); connection.close(); } catch (IOException e) { logger.error("[AccessHbaseBolt.cleanup]" + e.getMessage()); } } }
Hbase 中目前的存储结果:

下一个 bolt 是 split-bolt 主要负责拆分一个 String 类型的 accesslog 为一个类 AccessLog,会将 accesslog 各个字段赋值到 AccessLog 中的相应字段。该类中目前有 vulType,vulTypeId,msg,logType 四个字段分别表示该日志触发何种漏洞规则,规则编号,提示信息,日志类型。
AccessLog 类
package com.jiyufei.hlas.util; import java.io.Serializable; public class AccessLog implements Serializable{ private static final long serialVersionUID = 7078625027459628744L; private String vulType; private String vulTypeId; private String msg; private String logType; private String clientIp; private String clientUser; private String time; private String method; private String url; private String version; private String requestBody; private String status; private String httpBytes; private String requestTime; private String referer; private String userAgent; //private String hostIp; //private String indexName; //private String business; public String getVulType() { return vulType; } public void setVulType(String vulType) { this.vulType = vulType; } public String getVulTypeId() { return vulTypeId; } public void setVulTypeId(String vulTypeId) { this.vulTypeId = vulTypeId; } public String getMsg() { return msg; } public void setMsg(String msg) { this.msg = msg; } public String getLogType() { return logType; } public void setLogType(String logType) { this.logType = logType; } /* public String getHostIp() { return hostIp; } public void setHostIp(String hostIp) { this.hostIp = hostIp; } */ /* public String getIndexName() { return indexName; } public void setIndexName(String indexName) { this.indexName = indexName; } public String getBusiness() { return business; } public void setBusiness(String business) { this.business = business; } */ public String getClientIp() { return clientIp; } public void setClientIp(String clientIp) { this.clientIp = clientIp; } public String getClientUser() { return clientUser; } public void setClientUser(String clientUser) { this.clientUser = clientUser; } public String getTime() { return time; } public void setTime(String time) { this.time = time; } public String getMethod() { return method; } public void setMethod(String method) { this.method = method; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getVersion() { return version; } public void setVersion(String version) { this.version = version; } public String getRequestBody() { return requestBody; } public void setRequestBody(String requestBody) { this.requestBody = requestBody; } public String getStatus() { return status; } public void setStatus(String status) { this.status = status; } public String getHttpBytes() { return httpBytes; } public void setHttpBytes(String httpBytes) { this.httpBytes = httpBytes; } public String getRequestTime() { return requestTime; } public void setRequestTime(String requestTime) { this.requestTime = requestTime; } public String getReferer() { return referer; } public void setReferer(String referer) { this.referer = referer; } public String getUserAgent() { return userAgent; } public void setUserAgent(String userAgent) { this.userAgent = userAgent; } @Override public String toString() { return "AccessLog [vulType=" + vulType + ", vulTypeId=" + vulTypeId + ", msg=" + msg + ", logType=" + logType + ", clientIp=" + clientIp + ", clientUser=" + clientUser + ", time=" + time + ", method=" + method + ", url=" + url + ", version=" + version + ", requestBody=" + requestBody + ", status=" + status + ", httpBytes=" + httpBytes + ", requestTime=" + requestTime + ", referer=" + referer + ", userAgent=" + userAgent + "]"; } }
后面四个 bolt 主要是进行 POC 检测,如果命中某个 POC,则判定该日志有风险,会写入到 ES 中。在 SqlModule 类中主要存放一些规则,会将 url 和 requestBody 两个字段进行比较。
AccessSqlInjectionBolt 类
package com.jiyufei.hlas.bolt; import java.util.Map; import com.jiyufei.hlas.module.SqlModule; import com.jiyufei.hlas.util.AccessLog; import com.jiyufei.hlas.util.ModuleUtil; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class AccessSqlInjectionBolt extends BaseRichBolt { private static final long serialVersionUID = 8359035500983257762L; private OutputCollector collector; private SqlModule sqlModule; private Integer status; public void execute(Tuple tuple) { AccessLog accessLog = (AccessLog)tuple.getValueByField("accesslog"); status = 0; ModuleUtil sqlModuleUtil = null; if(accessLog.getRequestBody().compareTo("-") != 0){ sqlModuleUtil = sqlModule.check(accessLog.getRequestBody()); if(sqlModuleUtil != null){ accessLog.setVulTypeId(String.valueOf(sqlModuleUtil.getVulTypeId())); accessLog.setVulType("SQL注入"); accessLog.setMsg(sqlModuleUtil.getMsg()); status = 1; } } if(status != 1){ sqlModuleUtil =sqlModule.check(accessLog.getUrl()); if(sqlModuleUtil != null){ accessLog.setVulTypeId(String.valueOf(sqlModuleUtil.getVulTypeId())); accessLog.setVulType("SQL注入"); accessLog.setMsg(sqlModuleUtil.getMsg()); status = 1; }else{ accessLog.setVulType("0"); accessLog.setVulType(""); accessLog.setMsg(""); } } if(status == 1){ collector.emit("finalStream",tuple,new Values(accessLog)); collector.ack(tuple); }else{ collector.emit("accesslogStream",tuple,new Values(accessLog)); collector.ack(tuple); } } public void prepare(@SuppressWarnings("rawtypes") Map stormConfig, TopologyContext context, OutputCollector collector) { this.collector = collector; this.sqlModule = new SqlModule(); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declareStream("accesslogStream",new Fields("accesslog")); declarer.declareStream("finalStream",new Fields("accesslog")); } public void cleanup(){ //logFile.close(); } } 写入 ES 的类如下,使用 jest。 package com.jiyufei.hlas.bolt; import io.searchbox.client.JestClient; import io.searchbox.client.JestClientFactory; import io.searchbox.client.config.HttpClientConfig; import io.searchbox.core.Index; import java.io.IOException; import java.util.Map; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.jiyufei.hlas.util.AccessLog; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; public class ElasticSearchBolt extends BaseRichBolt { private static final String ES_IP = "http://192.168.32.32:9200"; private static final long serialVersionUID = 145040226237959431L; private JestClient client; private OutputCollector collector; private static Logger logger = LoggerFactory.getLogger(ElasticSearchBolt.class); private AccessLog accessLog; public void execute(Tuple tuple) { accessLog = (AccessLog)tuple.getValueByField("accesslog"); logger.info("[ElasticSearchBolt.execute]tuple:" + accessLog.toString()); Index index = new Index.Builder(accessLog).index("access-log").type(accessLog.getVulType()).build(); try { client.execute(index); collector.ack(tuple); } catch (IOException e) { logger.error("[ElasticSearchBolt.execute]" + e.getMessage()); } } public void prepare(@SuppressWarnings("rawtypes") Map config, TopologyContext context, OutputCollector collector) { this.collector = collector; JestClientFactory jestClientFactory = new JestClientFactory(); jestClientFactory.setHttpClientConfig(new HttpClientConfig.Builder(ES_IP).multiThreaded(true).build()); client = jestClientFactory.getObject(); } public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
main 函数示例
BrokerHosts brokerHosts = new ZkHosts(zks,"/kafka/brokers"); SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, topic, zkRoot,id); spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); spoutConfig.zkServers = Arrays.asList(new String[]{"192.168.32.33","192.168.32.34","192.168.32.35","192.168.32.36"}); spoutConfig.zkPort = 2181; spoutConfig.forceFromStart = false; KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout(KAFKA_SPOUT_ID, kafkaSpout,1); /* builder.setBolt(SPLIT_BOLT_ID, accessSplitBolt,1).shuffleGrouping(KAFKA_SPOUT_ID); builder.setBolt(HBASE_BOLT_ID, accessHbaseBolt,1).shuffleGrouping(SPLIT_BOLT_ID,"accesslogStream"); */ builder.setBolt(HBASE_BOLT_ID, accessHbaseBolt,2).shuffleGrouping(KAFKA_SPOUT_ID); builder.setBolt(SPLIT_BOLT_ID, accessSplitBolt,1).shuffleGrouping(HBASE_BOLT_ID,"accesslogStream"); builder.setBolt(SQL_INJECTION_BOLT_ID, accessSqlInjectionBolt,1).shuffleGrouping(SPLIT_BOLT_ID,"accesslogStream"); builder.setBolt(XSS__BOLT_ID, accessXssBolt,1).shuffleGrouping(SQL_INJECTION_BOLT_ID,"accesslogStream"); builder.setBolt(LFI_BOLT_ID, accessLFIBolt,1).shuffleGrouping(XSS__BOLT_ID,"accesslogStream"); builder.setBolt(RFI_BOLT_ID, accessRFIBolt,1).shuffleGrouping(LFI_BOLT_ID,"accesslogStream"); //builder.setBolt(HBASE_BOLT_ID, accessHbaseBolt,1).shuffleGrouping(RFI_BOLT_ID,"accesslogStream"); //builder.setBolt(MYSQL_BOLT_ID,accessMysqlBolt,1).globalGrouping(RFI_BOLT_ID,"accesslogStream"); builder.setBolt("elasticsearch-bolt1", elasticSearchBolt).globalGrouping(SQL_INJECTION_BOLT_ID,"finalStream"); builder.setBolt("elasticsearch-bolt2", elasticSearchBolt).globalGrouping(XSS__BOLT_ID,"finalStream"); builder.setBolt("elasticsearch-bolt3", elasticSearchBolt).globalGrouping(LFI_BOLT_ID,"finalStream"); builder.setBolt("elasticsearch-bolt4", elasticSearchBolt).globalGrouping(RFI_BOLT_ID,"finalStream");
ES 采用两台服务器的集群,创建一个 indices,名称为 access-log,jstorm 和 spark 处理后的日志写入其中。


注意:创建完 access-log 后,在写入数据前,需要运行以下命令,"time" 为时间字段,"vulType" 为_type
curl -XPUT '192.168.32.32:9200/access-log?pretty' -H 'Content-Type: application/json' -d' { "mappings": { "vulType": { "properties": { "time": { "type": "date", "format": "date_time_no_millis" } } } } } '
伪造一些日志,可以在 kibana 中看到 jstorm 执行后的结果
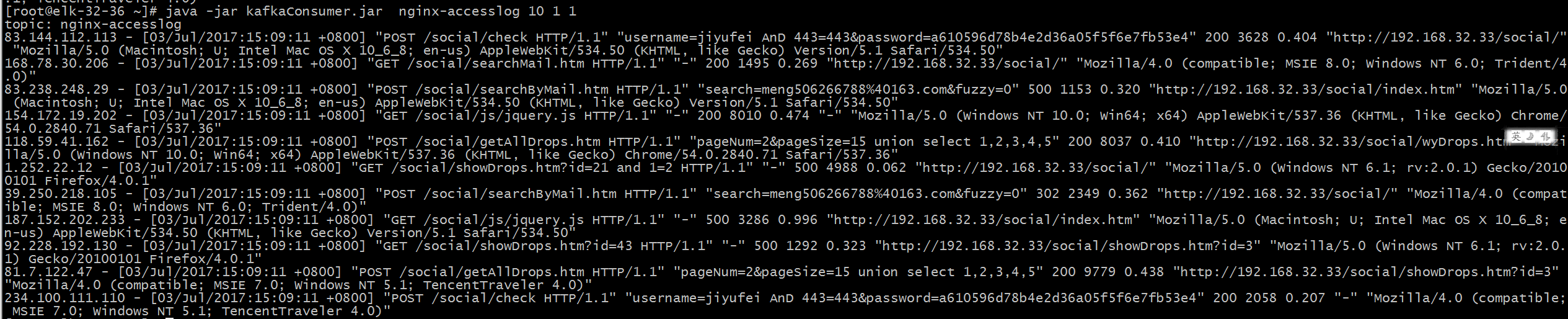
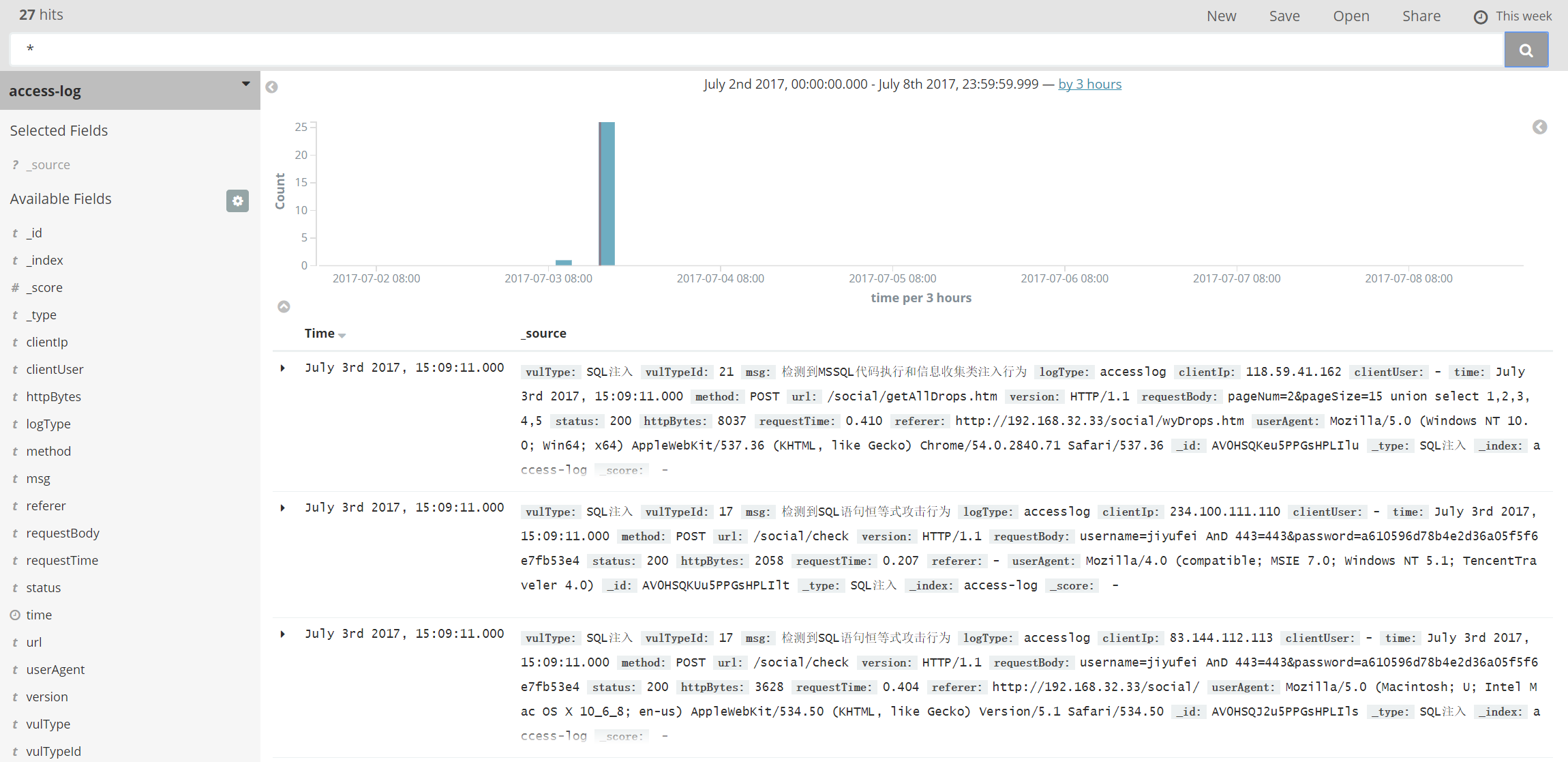
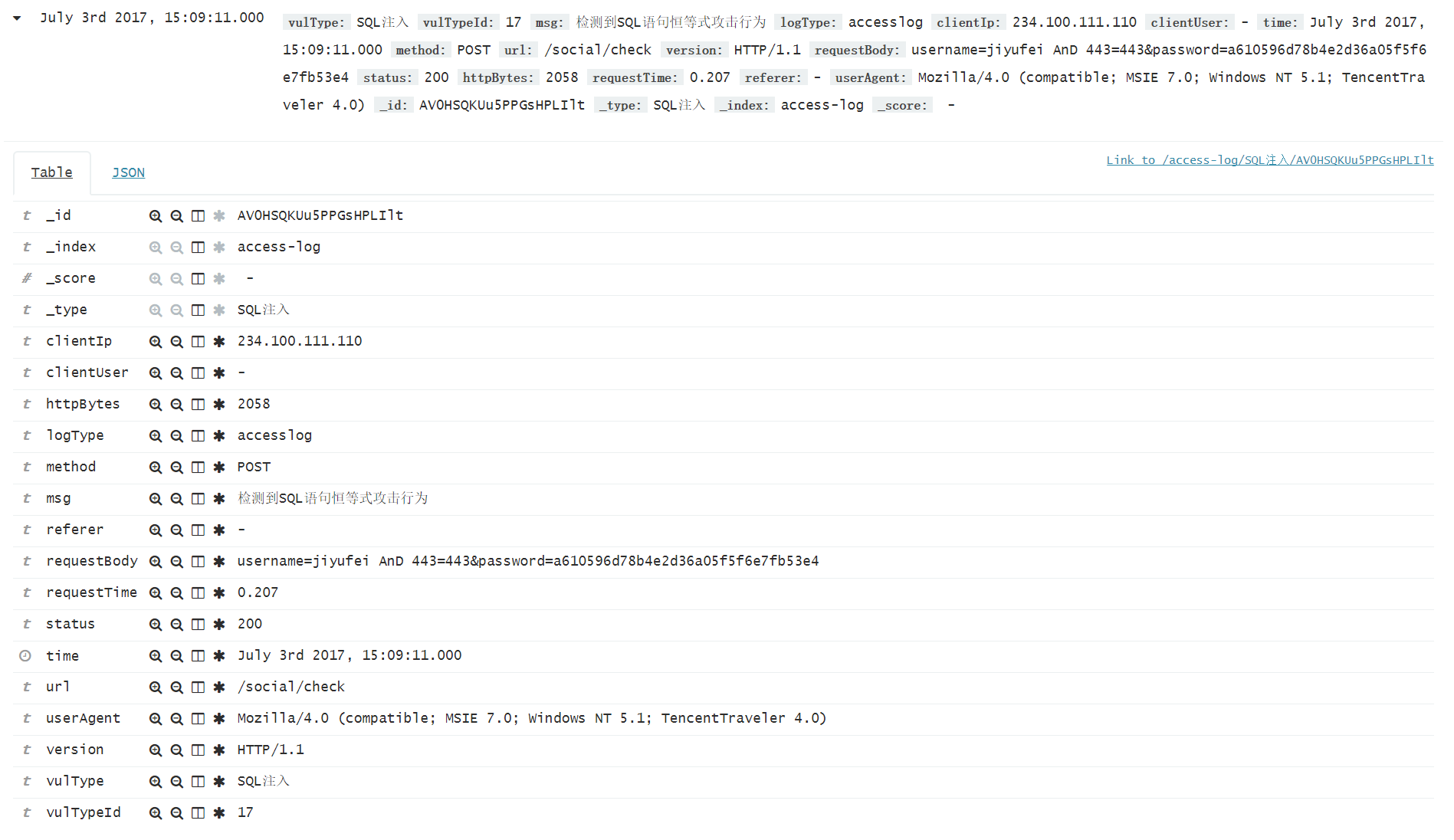
以上是 jstorm 实时检测的流程。还有一路是 spark 通过 MR 分析多条日志,进行统计规则的检测。
spark 首先去 hbase 中读取数据,随后进行 Map/Reduce,统计出触发风险规则的日志。例如测试统计三分钟内访问次数超过 10 次的 IP。
获取 hbase 中的 accesslog
public List<String> getTableByDate(String startRow,String endRow){ Scan s = new Scan(); List<String> logList = new ArrayList<String>(); s.setStartRow(Bytes.toBytes(startRow)); s.setStopRow(Bytes.toBytes(endRow)); try { ResultScanner resultScanner = table.getScanner(s); for(Result rs:resultScanner){ NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> navigableMap = rs.getMap(); for(Map.Entry<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> entry:navigableMap.entrySet()){ NavigableMap<byte[], NavigableMap<Long, byte[]>> map =entry.getValue(); for(Map.Entry<byte[], NavigableMap<Long, byte[]>> en:map.entrySet()){ NavigableMap<Long, byte[]> ma = en.getValue(); for(Map.Entry<Long, byte[]>e: ma.entrySet()){ logList.add(Bytes.toString(e.getValue())); } } } } } catch (IOException e) { e.printStackTrace(); return null; } return logList;
随后将 accesslog 映射到类 AccessLog 中
public void analysesLog(String startKey,String endKey){ logList = hbaseOperator.getTableByDate(startKey, endKey); listLength = logList.size(); accesslogList = new ArrayList<AccessLog>(listLength); String patternstr = "((\\d+\\.){3}\\d+)\\s(\\S+)\\s\\[(.+)\\]\\s\"((\\S+)\\s(.*)\\s(\\S+))\"\\s\"(.*)\"\\s(\\d+)\\s(\\d+)\\s(\\S+)\\s\"(.*)\"\\s\"(.*)\""; pattern = Pattern.compile(patternstr); for(int i=0;i<listLength;i++){ m = pattern.matcher(logList.get(i)); if(m.find()){ AccessLog accessLog = new AccessLog(); accessLog.setLogType("access-log"); accessLog.setClientIp(m.group(1)); accessLog.setClientUser(m.group(3)); SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ssZZ"); SimpleDateFormat sdf = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss ZZ",Locale.ENGLISH); Date time = null; try { time = sdf.parse(m.group(4)); accessLog.setTime(sdf2.format(time)); } catch (ParseException e) { accessLog.setTime(sdf2.format(new Date())); //logger.error("[LogSplit.execute]:" + e.getMessage()); } accessLog.setMethod(m.group(6)); accessLog.setUrl(m.group(7)); accessLog.setVersion(m.group(8)); accessLog.setRequestBody(m.group(9)); accessLog.setStatus(m.group(10)); accessLog.setHttpBytes(m.group(11)); accessLog.setRequestTime(m.group(12)); accessLog.setReferer(m.group(13)); accessLog.setUserAgent(m.group(14)); accesslogList.add(accessLog); } } analysesIp(); }
映射完成后调用 analysesIp () 进行 Map/Reduce 操作,并将命中的 IP 写入到 ES 中
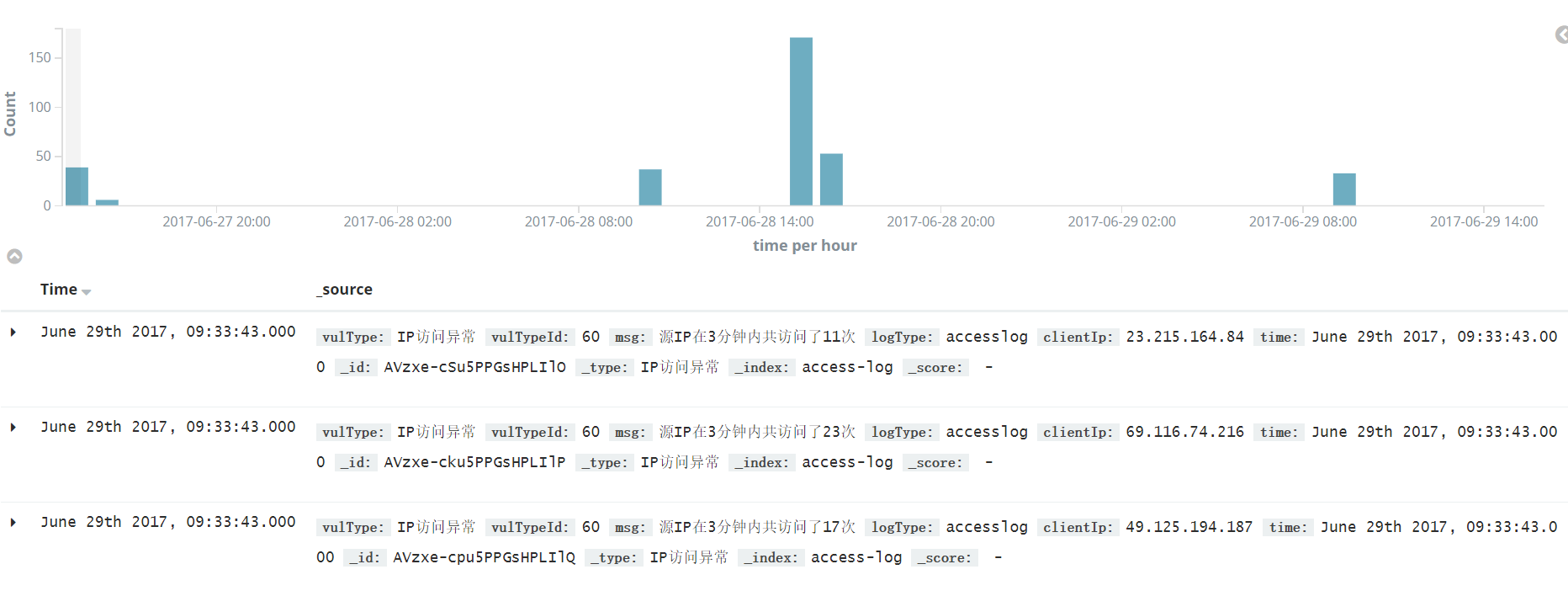
public void analysesIp(){ if(!accesslogList.isEmpty()){ List<String> ipList = new ArrayList<String>(listLength); Iterator<AccessLog> iterator = accesslogList.iterator(); while (iterator.hasNext()) { ipList.add(iterator.next().getClientIp()); } JavaRDD<String> ipRdd = sparkContext.parallelize(ipList); JavaPairRDD<String, Integer> clientIpRdd = ipRdd.mapToPair(initCount); JavaPairRDD<String, Integer> sumRdd = clientIpRdd.reduceByKey(sum); Map<String, Integer> ipMap = sumRdd.collectAsMap(); SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ssZZ"); AccessLog accessLog = new AccessLog(); accessLog.setLogType("accesslog"); accessLog.setVulType("IP访问异常"); accessLog.setVulTypeId(Integer.toString(RuleLength.START_RULE_LENGTH)); for(Entry<String, Integer> entry:ipMap.entrySet()){ if(entry.getValue() > 30){ accessLog.setTime(sdf2.format(new Date())); accessLog.setClientIp(entry.getKey()); accessLog.setMsg("源IP在3分钟内共访问了" + entry.getValue() + "次"); elasticSearch.inputData(accessLog); } } } }
用到两个简单的 map/reduce 函数,一个进行初始化,将单个 IP 初始化一个元组(IP,1)
第二个将相同的 IP 进行累加,并记录出现的次数,累加后的效果为(IP1,10) (IP2,3)
private static PairFunction<String, String, Integer> initCount = new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = -6290488020645730311L; public Tuple2<String, Integer> call(String x){ return new Tuple2<String, Integer>(x, 1); } }; private static Function2<Integer, Integer, Integer> sum = new Function2<Integer, Integer, Integer>() { /** * */ private static final long serialVersionUID = 391813718009018019L; @Override public Integer call(Integer x, Integer y) throws Exception { return x + y; } };
写入 ES 后,可看到的效果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号