语义分割中的nonlocal[13]- Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers

Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
https://fudan-zvg.github.io/SETR/
类似于VIT,该文用transformer搞segmentation
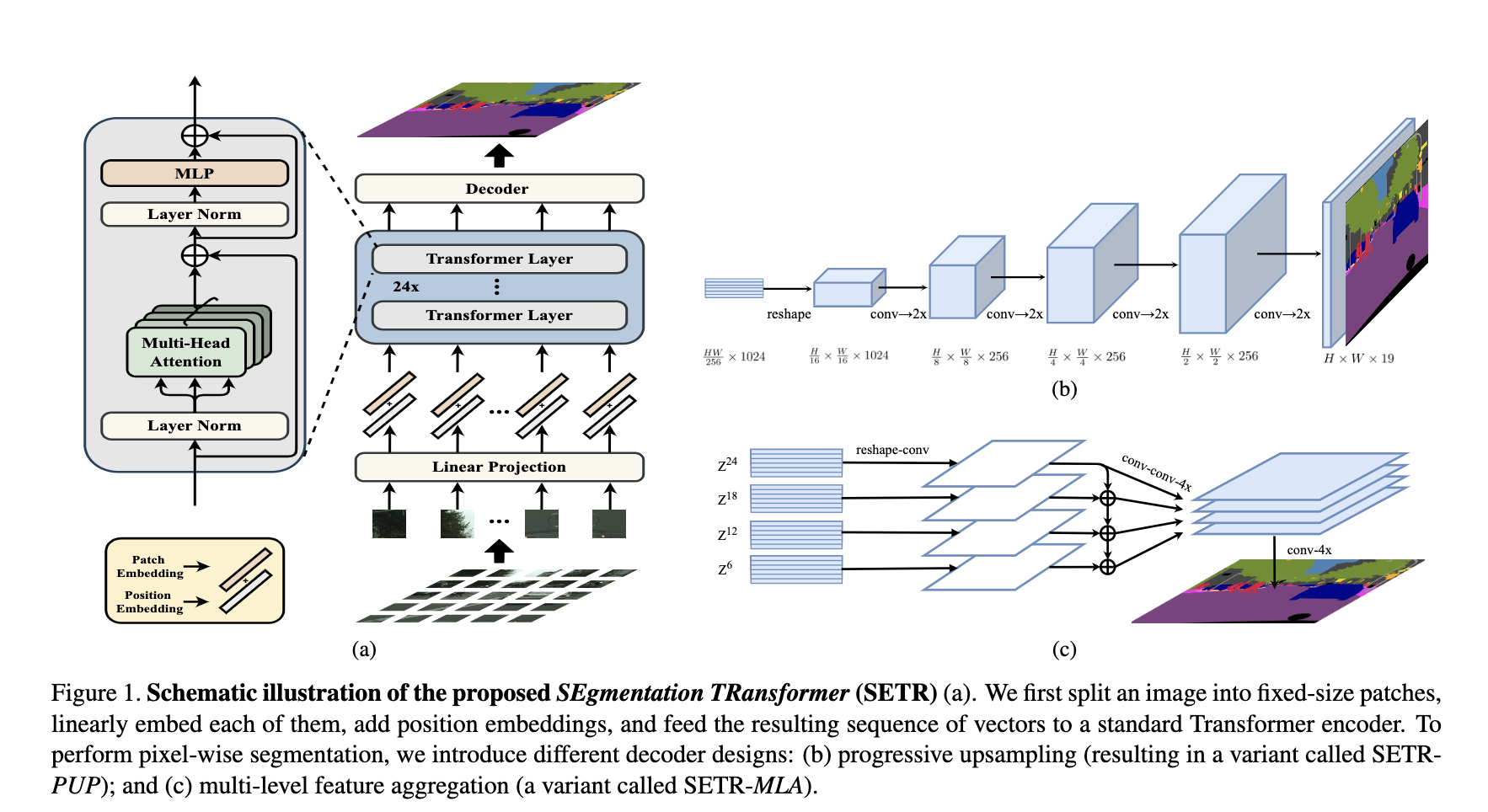
如上图a,将图像分为若干小格子,每个小格字做linear projection,加上position embedding 之后concat一起做transformer,文中用了24层。
之后接一个decoder,作者试了两种1是图b中逐步上采的(PUP),另外一种是c中融合了不同level的transformer输出(MLA)
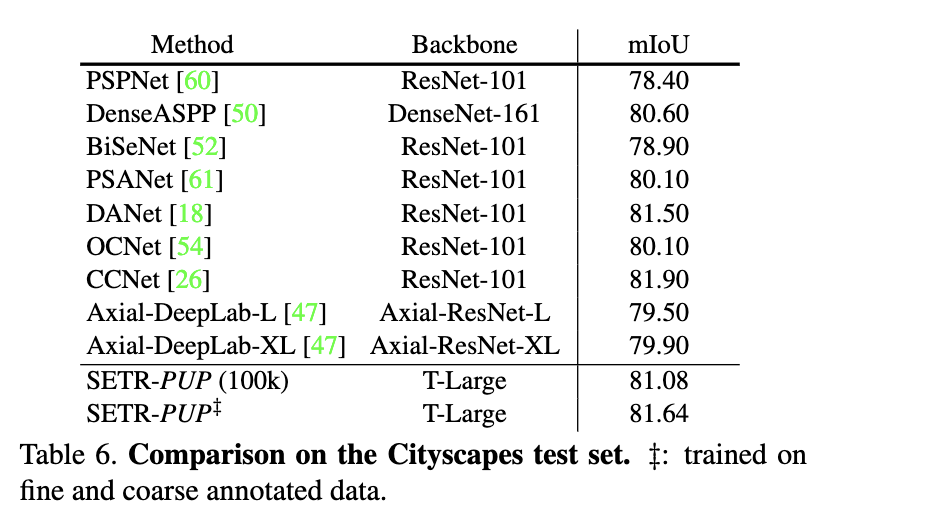
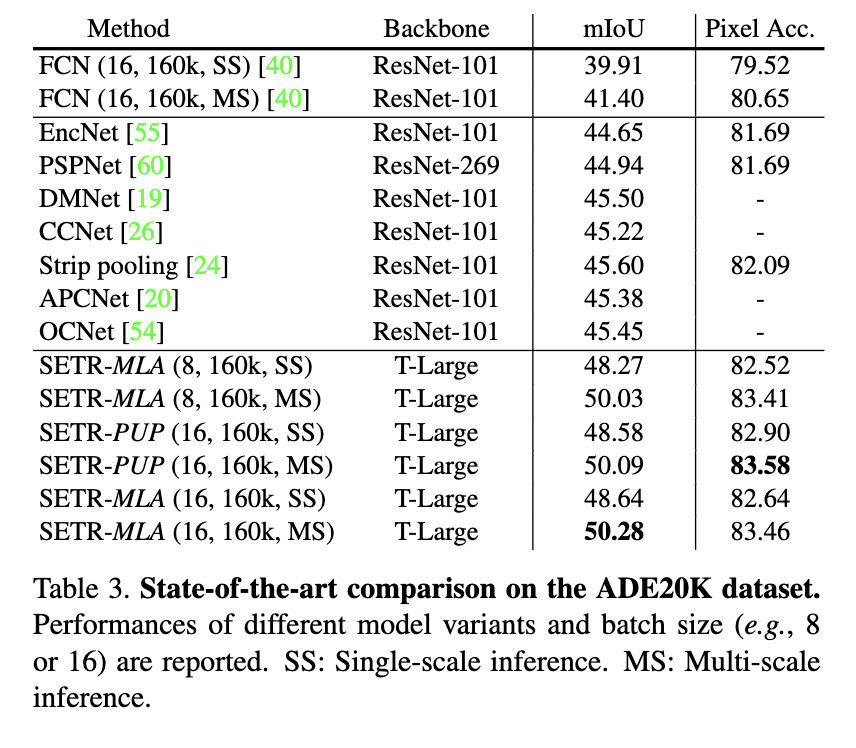
结果还是挺好的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号