语义分割中的nonlocal[4]-OCRnet

https://arxiv.org/abs/1909.11065
https://git.io/HRNet.OCR
通过获取pixel与object region之间的关系得到 object-contextual representation,具体看下图
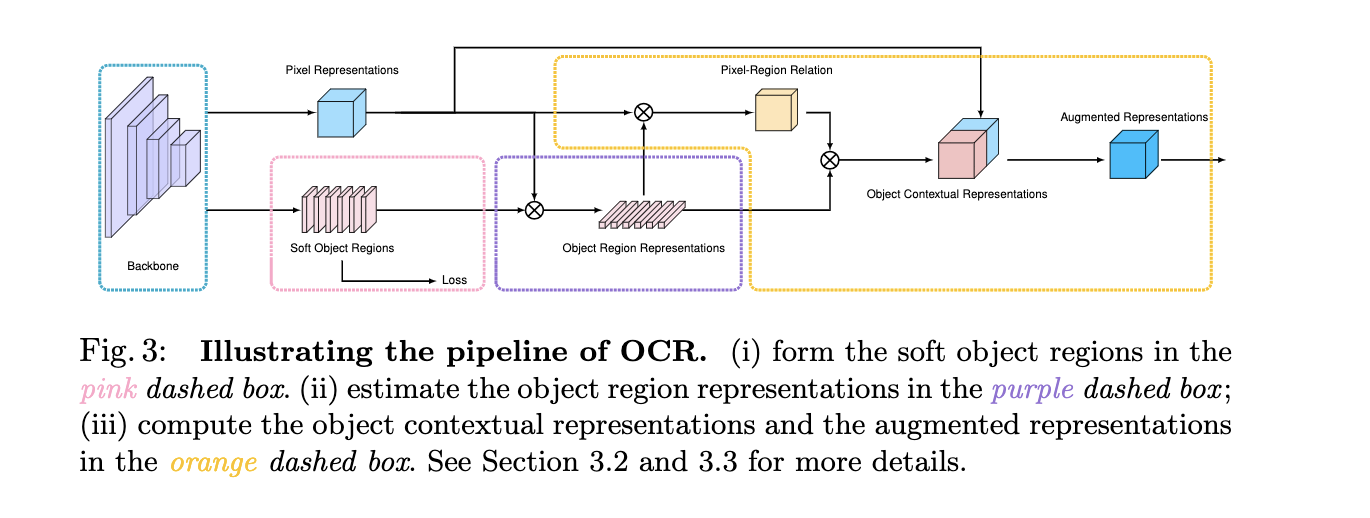
可能只看上面的pipeline并不能直接与non-local联系起来,但是如果结合下图来看,就可以明白,这里其实可以看成是改了key,value的纬度,原来(hw)x(hw)的affinity map 变成了现在的(hw)xc,故而计算量也是大大减少了,原来是点两两之间的关系,现在成为了pixel与每个region的关系,这里的region可以理解为不同channel表达特定类别的region
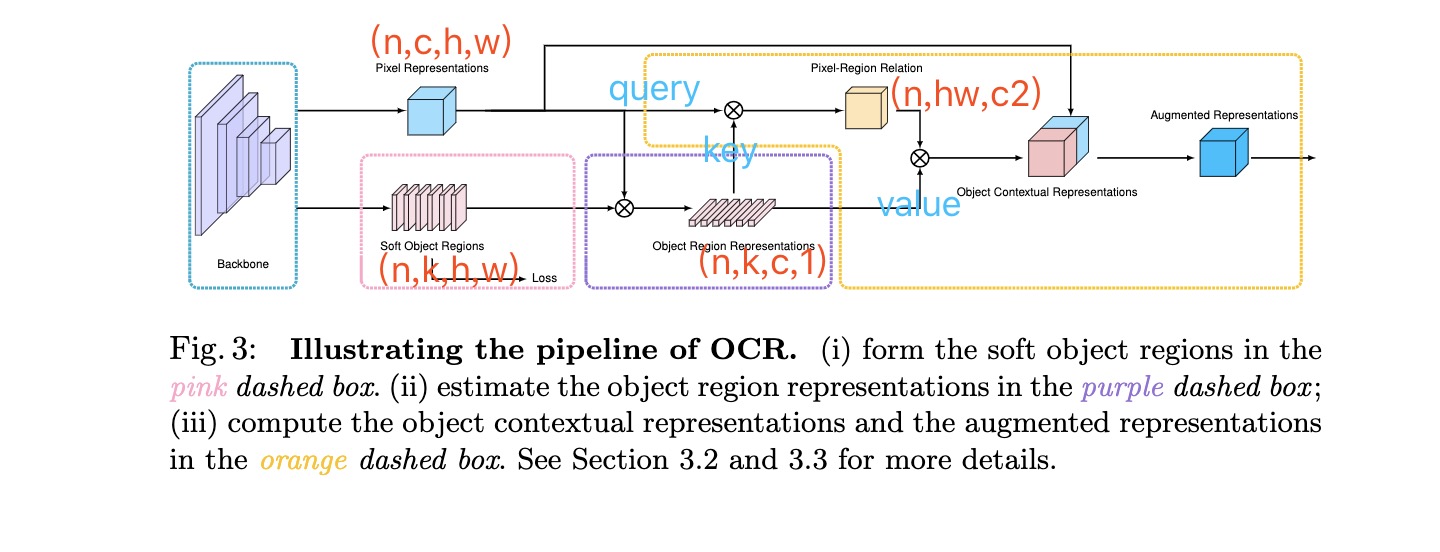
结合上图论文中提出的三个部分就好理解了
- 红色虚线框部分,提取soft object regions
红色部分采用celoss监督,这里的loss有两个点的提升,还是很重要的。feature上在每个channel上做softmax ,得到特定类别(对应channel)的相应区域
2.紫色虚线框部分,估计object region representations
使用上一步经过softmax normalize的结果,对每个位置的representation 做aggregation,也就是矩阵乘 得到object region representation
3.黄色框计算object contextual representations 然后augmented representations (non-local)
首先通过query和key得到,每个pixel与region之间的关系(affinity map,也是通过softmax来做norm),然后通过value与affinity map矩阵乘得到object contextual representation
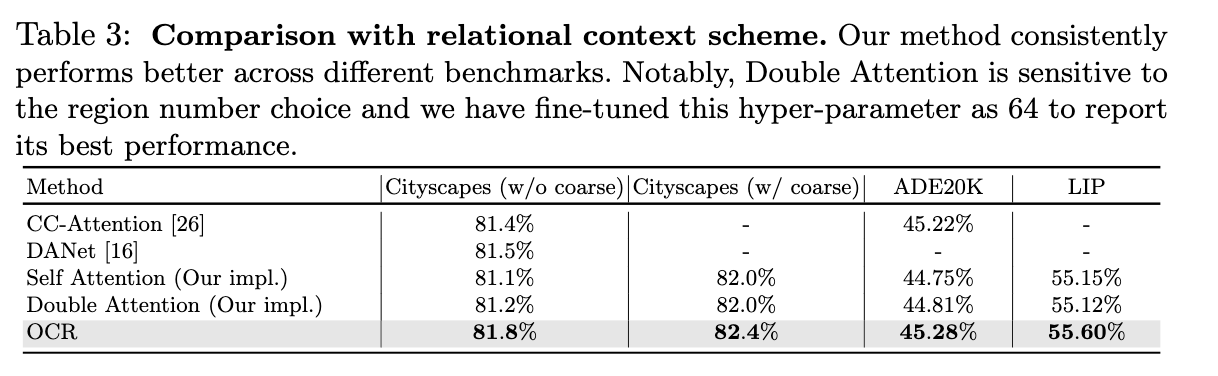
看下结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号