语义分割中的nonlocal[1]-DAnet

takeaway:
使用self attention分别对channel 及 spatial两个维度进行特征聚合,以使网络获得所谓的context
https://github.com/junfu1115/DANet/
网络的结构比较简明,如下图,是将non local用在semantic segmentation方面的早期工作之一
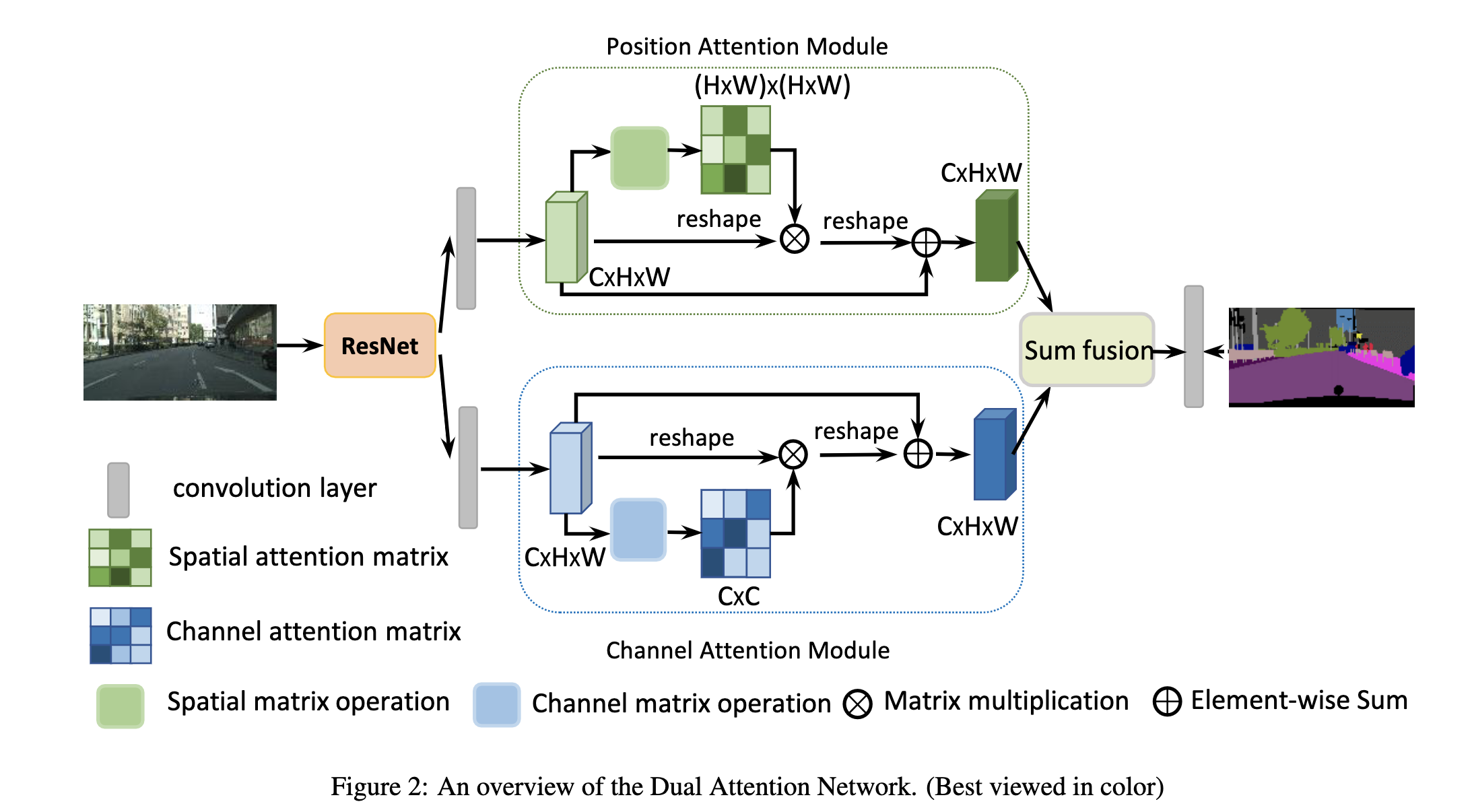
其中的位置注意力和通道注意力结构如下:
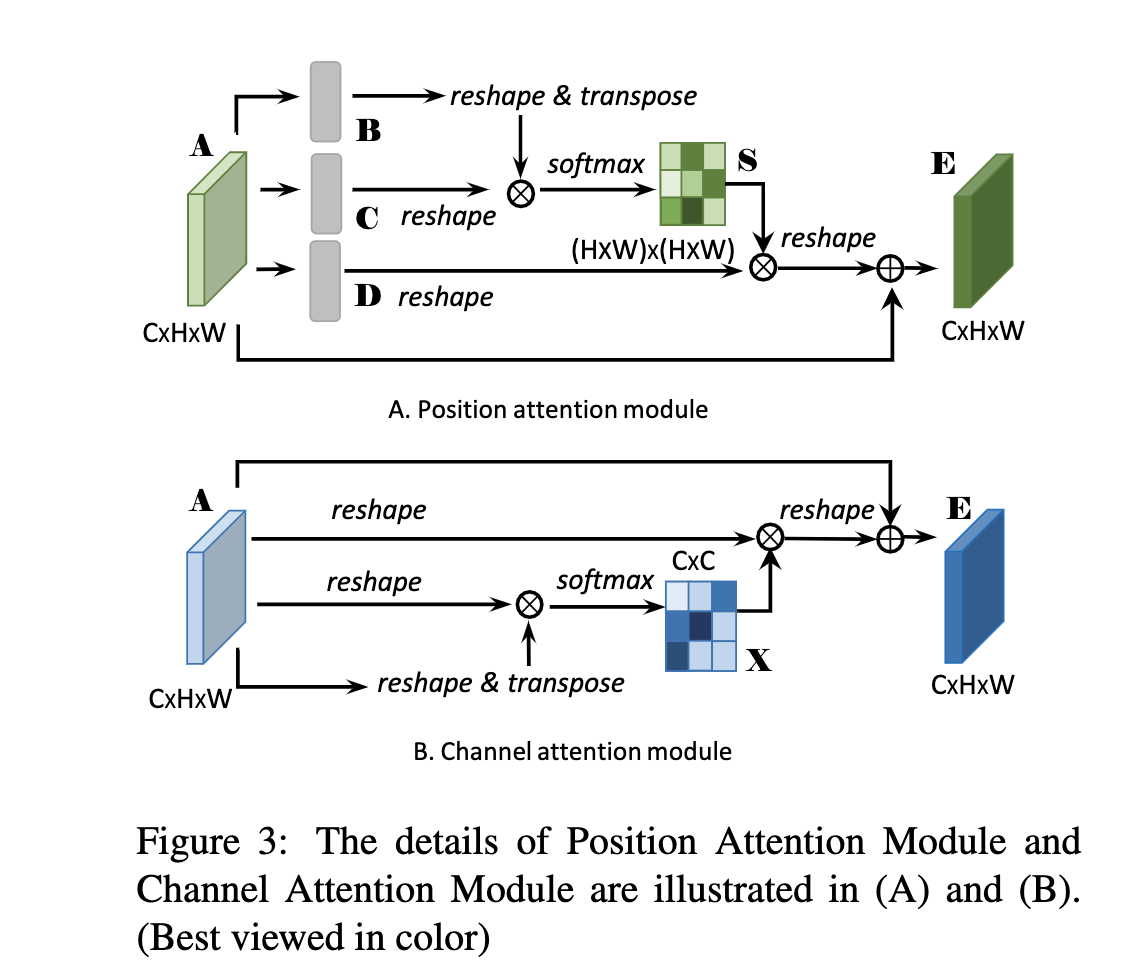
这里就是近似于原本的self-attention实现,在上图中的softmax之前没有除以variance,另外在于A相加之前学了一个比例gamma
其中实现代码已经摘抄在文章后面
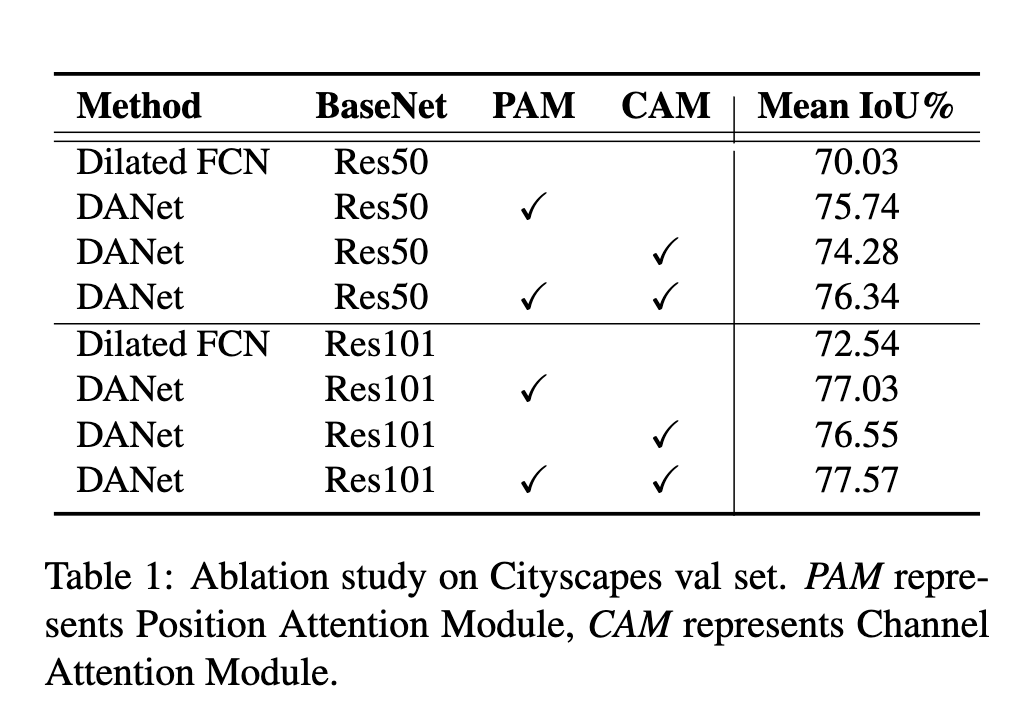
效果如下:
class PAM_Module(Module):
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out

 浙公网安备 33010602011771号
浙公网安备 33010602011771号