
ScreenCoder – 开源的智能UI截图生成前端代码工具
ScreenCoder是什么

ScreenCoder ScreenCoder 是由香港中文大学团队开发的开源项目,开源的智能 UI 截图转代码系统,支持将任何设计截图快速转换为整洁、可编辑的 HTML/CSS 代码。ScreenCoder用模块化多智能体架构,结合视觉理解、布局规划和代码合成技术,生成高精度、语义化的前端代码。用户根据需求轻松修改布局和样式,实现设计与开发的无缝衔接,适用快速原型设计和像素级完美界面构建,大大提升前端开发效率。其创新性地融合了视觉理解、布局规划和自适应代码生成技术,支持对生成代码进行二次定制,解决了传统设计稿转代码的保真度与灵活性难题。

ScreenCoder的官网地址
- GitHub仓库:https://github.com/leigest519/ScreenCoder
- arXiv技术论文:https://arxiv.org/pdf/2507.22827
- 在线体验Demo:https://huggingface.co/spaces/Jimmyzheng-10/ScreenCoder
性能数据:
在WebUI基准测试中,CLIP得分比GPT-4V高38.6% · 代码可维护性提升5倍
ScreenCoder的主要功能
1.UI 截图转代码:支持将任何 UI 截图或设计原型快速转换为整洁净、可编辑的 HTML/CSS 代码。
2.高精度代码生成:生成的代码与原始设计高度一致,视觉对齐且忠实还原语义。
3.自定义修改:支持用户根据需求调整布局和样式,方便二次开发。
4.多模型支持:支持 Doubao、Qwen、GPT、Gemini 等多种生成模型,用户能根据需求选择。
5.快速部署:生成的代码能直接用于生产环境,支持快速原型设计和像素级完美界面构建。
ScreenCoder的技术原理
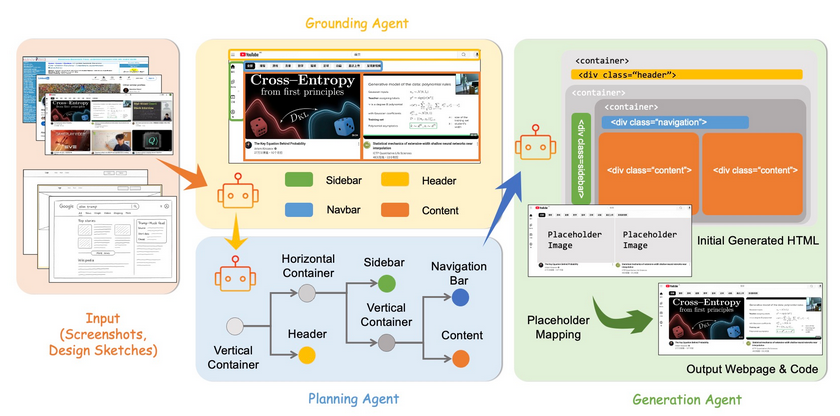
定位阶段(Grounding Agent):定位阶段基于视觉语言模型(VLM)识别并标记 UI 图像中的主要结构组件,如侧边栏、头部和导航栏等。用文本提示引导模型检测特定组件,返回其边界框和语义标签。为确保检测结果的准确性和可靠性,系统进行去重、冲突解决及回退恢复等操作,并推断出主内容区域。最终输出布局字典,为后续的布局规划和代码生成提供基础信息。
规划阶段(Planning Agent):在规划阶段,根据定位阶段的输出构建层次化的布局树,为代码生成提供结构上下文。用简单的空间启发式规则和组合规则,将检测到的组件组织成树状结构。系统创建填充视口的根容器,为每个顶级区域生成绝对定位的 .box 元素,必要时插入内层 <div class=”container grid”> 实现 CSS Grid 布局。每个节点都标注网格模板配置和排序元数据,便于直接编译为 HTML/CSS 代码。
生成阶段(Generation Agent):生成阶段将语义化的布局树转换为可执行的 HTML/CSS 代码。ScreenCoder 用自然语言提示驱动的生成过程,为布局树中的每个组件构建适应性提示,通过语言模型生成对应的代码。提示中包含组件的语义标签和布局上下文,用户指令(如果提供)会附加到提示中。生成的代码根据布局树的结构进行组装,保留层次结构、顺序和布局配置。系统将生成代码中的灰色占位符替换为原始截图中的实际图像,恢复视觉和语义的一致性。
ScreenCoder的应用场景
*前端开发加速:快速将 UI 设计截图转换为高质量 HTML/CSS 代码,显著缩短前端开发周期,帮助开发团队提高效率并减少手动编码工作量。
*设计与开发协作:将设计截图直接转换为操作代码,促进设计与开发团队之间的无缝协作,减少沟通成本,确保设计意图的准确传达。
*快速原型制作:能即时将设计概念转化为可交互的前端原型,加速产品设计的早期验证和用户测试过程,支持快速迭代和优化用户体验。
*教育与培训:作为教育工具,帮助学生和新手开发者直观理解 UI 设计与前端代码的关系,加速学习过程并提高实践技能。
*小型团队与创业公司:为资源有限的小型团队和创业公司提供高效代码生成解决方案,助力快速推出产品原型或最小可行产品(MVP),降低开发成本并加速市场进入。
十分钟快速部署
1. 基础环境准备
git clone https://github.com/leigest519/ScreenCoder
cd ScreenCoder
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
2. API密钥配置
以通义千问为例
echo "your_api_key_here" > qwen_api.txt
3. 模型选择(修改代码文件)
在block_parsor.py中设置
接入私有大模型:
# 修改html_generator.py
def call_local_llm(prompt):
response = requests.post("http://local-llm:8000/generate",
json={"prompt": prompt})
return response.json()['code']
应用场景实例
案例1:设计稿转响应式页面
输入:Figma导出的电商首页设计图
操作流:
python main.py --input figma_mockup.png
案例2:移动端截图转H5
特殊需求:保留图片中的手写批注
定制命令:
python image_replacer.py --retain_annotations
实现原理:
通过OpenCV识别墨迹区域,转换为标签+CSS滤镜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号