
从浅入深学习Taipy
从今天开始,我要好好学习Taipy了 -JohnC 2025-5-30
Taipy介绍
官网:https://taipy.io/
https://pypi.org/project/taipy/
学习手册:https://docs.taipy.io/en/latest/
官方范例集:
https://docs.taipy.io/en/latest/gallery/
https://github.com/Avaiga/taipy/tree/release/4.0/doc/gui/examples
什么是Taipy?
Taipy 是一个强大的 Python 库,专为开发和部署数据驱动的应用程序而设计。它通过提供一套丰富的工具和组件,使开发者能够快速构建和维护复杂的业务逻辑和数据交互界面。无论是金融分析、供应链管理还是任何需要高度数据交互的应用,taipy 都能提供高效的解决方案。
特性
- 基于Python的UI框架:Taipy是为Python用户设计的,特别是人工智能和数据科学领域的用户。它允许他们创建全栈应用程序,而无需学习HTML、CSS或JavaScript等额外技能。
- 用于数据管道的预构建组件:Taipy包括允许用户与数据管道交互的预构建组件,包括可视化和管理工具。
- 场景和数据管理功能:Taipy提供了管理不同业务场景和数据的功能,这对于需求预测或生产计划等应用程序非常有用。
- 版本管理和管道编排:它包括用于管理应用程序版本、管道版本和数据版本的工具,这些工具对多用户环境是有益的。
Taipy 包括 Taipy Python 库,使开发人员可以轻松地为最终用户提供以下功能:
- 用户界面生成
- 数据集成
- 管道编排
- 假设分析和场景管理
- 身份验证、角色和用户管理
- 定时作业和调度
除了 Taipy 库之外,Taipy 生态系统还包括:
- Taipy 设计器
- Taipy 工作室
- 预定义模板
- 数据平台集成
Taipy是一个集成了Tornado、asyncio和IPython的工具组合。它的目标是简化Web应用的开发过程,提供高性能和易用性。
- Tornado
Tornado 是一个异步Web框架,旨在处理高并发的网络应用程序。它使用非阻塞I/O和事件循环来实现高性能。Tornado提供了HTTP服务器和Web框架,适用于构建实时Web应用、API和长连接。 - asyncio
asyncio 是Python标准库中的异步编程框架,它使您能够编写基于事件的、非阻塞的代码。通过将asyncio与Tornado结合使用,您可以轻松处理异步操作,例如数据库访问、文件操作和网络请求。 - IPython
IPython 是一个强大的交互式Python解释器,提供了丰富的功能,如代码补全、历史记录、代码调试等。将IPython与Taipy结合使用,可以在开发Web应用时更轻松地进行调试和测试。
使用Taipy构建Web应用
要使用Taipy构建Web应用,首先需要安装Taipy和相关依赖。可以使用pip来进行安装:
安装方法
官方安装指引:https://docs.taipy.io/en/latest/tutorials/getting_started/installation/
pip安装taipy
pip install taipy
其它参考文章:
https://segmentfault.com/a/1190000044917373
https://blog.csdn.net/maoyu_dual/article/details/147684868
Taipy Studio插件安装
Taipy Studio提供了一组加速Taipy应用程序创建的工具,减少了需要手工编写的代码。
Taipy Studio是Visual Studio Code的扩展,它提供了一个完整的开发环境,包括对Python编程语言的最先进的支持。
您可以在Taipy Studio文档页面上获得此扩展的所有相关信息。
Taipy Studio会自动安装两个扩展:
Taipy Studio Configuration Builder -提供一个点击编辑环境来创建和修改Taipy配置文件。
Taipy Studio GUI Helper -提供对Taipy GUI中使用的扩展Markdown语法的支持。这包括视觉元素属性、代码导航、变量资源管理器等方面的智能感知。
Taipy Studio可用于两种主要场景:
- 构建Taipy配置文件:
如果您计划构建Taipy配置文件,您可以打开“Taipy Configs”视图并开始。该视图在“次要侧栏”中打开。
如果您当前的项目有任何配置文件(*.toml),它们将列在该视图顶部的Config files部分中。
toml配置文件的作用
在taipy中,生成.toml文件的意义是什么,有什么作用?
在 Taipy 中,.toml 文件(通常命名为 config.toml)是用于配置应用程序参数的核心文件,其主要意义和作用如下:
集中管理配置参数
.toml 文件提供了一种结构化的方式来定义应用程序的各种参数,例如:
页面布局(页面名称、路由、包含的组件等)
数据连接信息(数据库地址、API 端点等)
应用运行参数(端口号、调试模式等)
自定义主题、样式等
这种集中管理避免了将配置硬编码到 Python 代码中,使参数修改更灵活,无需改动代码即可调整应用行为。
简化应用结构定义
对于复杂的 Taipy 应用(如多页面仪表板),.toml 文件可以清晰定义页面之间的关系、组件的布局逻辑,以及数据节点(Data Node)、任务(Task)、管道(Pipeline)等核心概念的配置,让应用结构更直观。
例如,在 .toml 中定义页面:
toml
[
pages
]
page1 = "pages/page1.md" # 关联 Markdown 页面
page2 = "pages/page2.py" # 关联 Python 页面
支持环境隔离
通过不同环境的 .toml 文件(如 config.dev.toml、config.prod.toml),可以为开发、测试、生产等环境配置不同参数(如数据库连接、日志级别),实现环境间的无缝切换。
与代码逻辑解耦
分离配置与业务逻辑,使代码更简洁,同时便于非开发人员(如数据分析师)通过修改 .toml 文件调整应用参数,无需了解 Python 代码细节。
自动加载与验证
Taipy 会自动解析 .toml 文件,并将配置参数加载到应用中。如果配置存在错误(如参数缺失、格式错误),Taipy 会在启动时抛出明确的错误提示,便于调试。
总结来说,.toml 文件是 Taipy 应用的 “配置中枢”,通过结构化的方式简化了应用管理、增强了灵活性,并促进了配置与代码的分离。
界面样式:
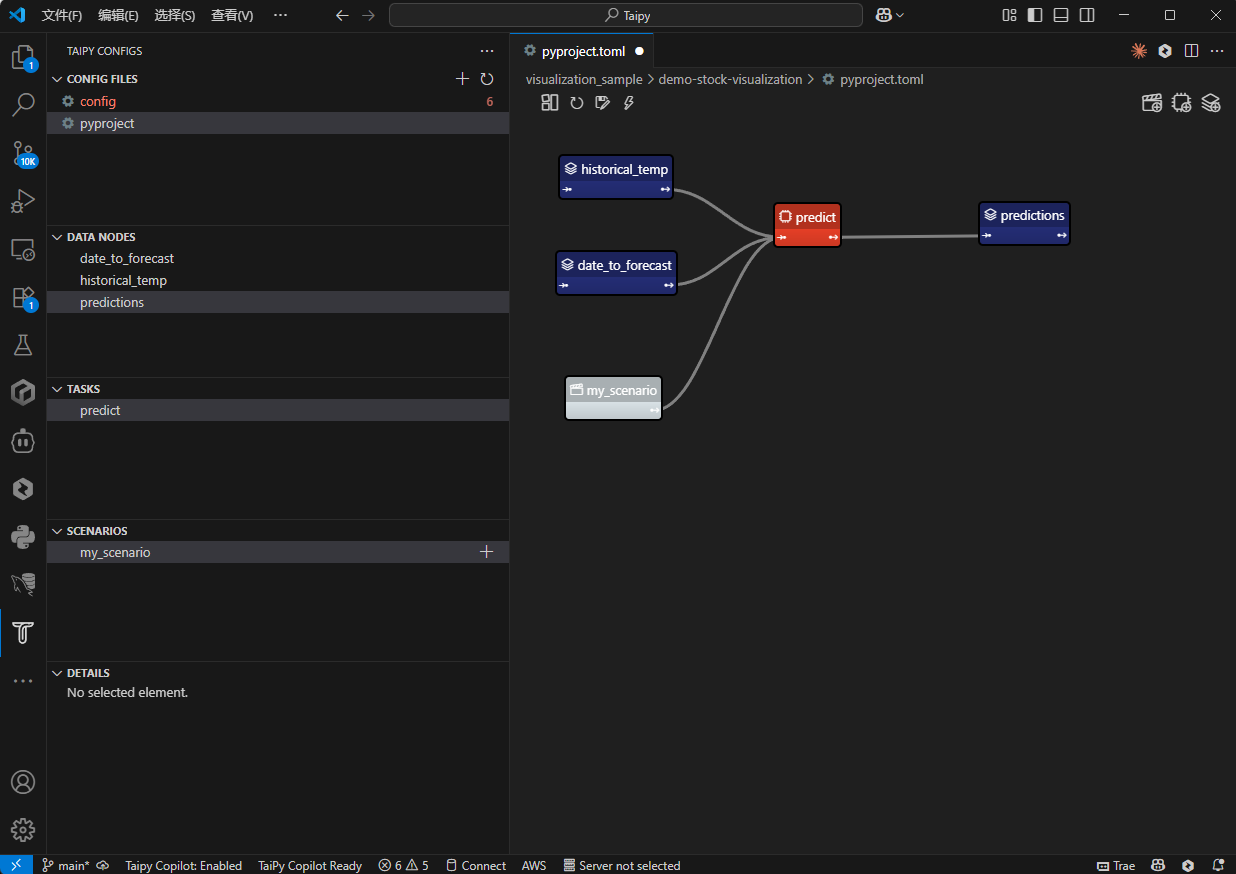
- 创建Taipy GUI页面:
如果您编辑Markdown源文件(.md)或Python源文件(.py)中的字符串,Taipy Studio将为您提供对Taipy GUI语法的支持。
有关详细信息,请参阅创建Taipy GUI页面的完整文档。https://docs.taipy.io/en/latest/userman/gui/
Taipy GUI 库提供了 Python 类,可让您在几分钟内轻松创建强大的 Web 应用程序。
在 Taipy 中,图形用户界面 (GUI) 是由 Taipy 应用程序本身或 Taipy 应用程序所依赖的 Web 服务器生成的网页制作而成。Taipy 通过其 Gui 类简化了此过程,该类管理服务器及其设置。
在 GUI 类中,你可以创建多个页面,你可以在其中放置文本和图形。这些元素可以动态显示应用程序变量的状态,为用户提供相关信息。用户可以与这些元素交互以触发应用程序代码、更改显示的信息、生成更多数据或移动到不同的页面。
网页由你提供的模板文本文件构建,其中包含显示应用程序数据的占位符。这些视觉和交互元素称为视觉元素(Visual Elements)。
在TRAE中如何安装 Taipy Studio插件
在application.extensionMarketUrl设置中,直接把 https://open-vsx.trae.com.cn/换成 https://marketplace.visualstudio.com/
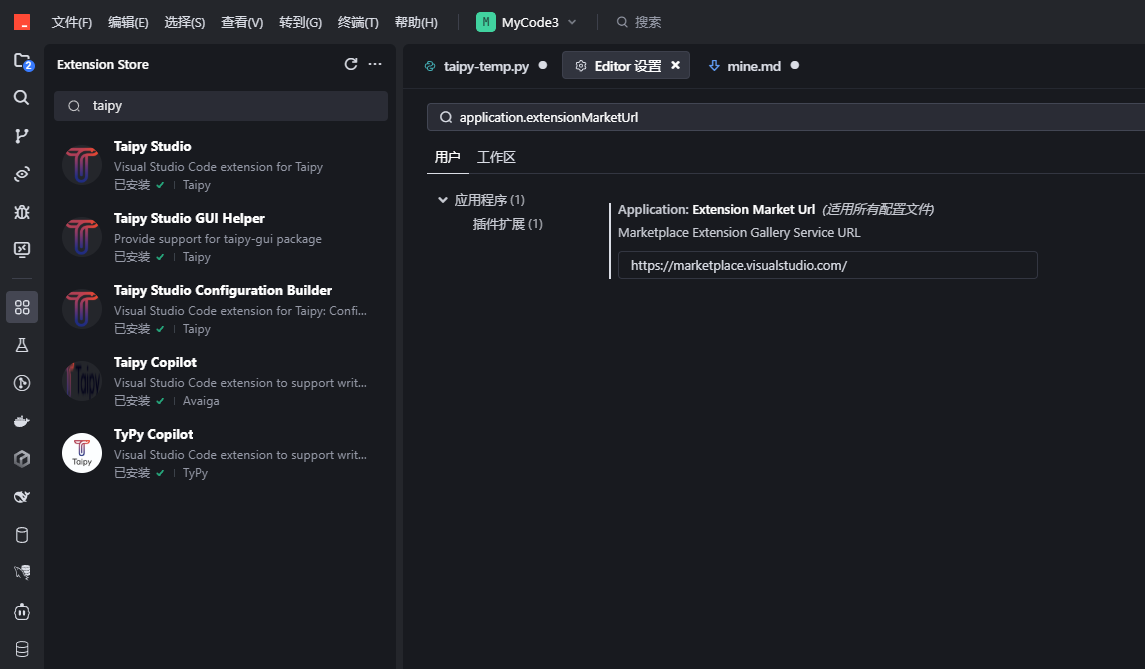
安装后,Taipy Studio 在以下条件下变为活动状态:
当前项目包含任何带有 .toml 扩展名的文件(假定为 Taipy 配置文件)。
当前项目包含任何带有 .md 扩展名的文件(假定为 Taipy GUI 页面定义页面)。
当前项目包含任何带有 .py 扩展名的文件(可能包含定义 Taipy GUI 页面的字符串的 Python 源文件)。
使用“视图 > 打开视图…”菜单选项明确打开 Taipy 配置视图时。
在Taipy中,创建GUI有两种代码方式:Markdown 和 Python,可参考:https://docs.taipy.io/en/latest/tutorials/getting_started/#__tabbed_1_1
Taipy 支持两种模板格式,由 Markdown 和 Html 类处理,用于描述页面内容。基本思想是根据需要创建页面,为它们分配名称以便于访问,并将它们提供给应用程序中的 GUI 实例。
当你使用 GUI 的 run() 方法时,它会启动一个 Web 服务器,允许客户端连接并请求页面。然后 Taipy 将创建的页面转换为发送回客户端的 HTML 内容,使用户能够查看并与应用程序界面交互。
Taipy核心概念
Taipy可对任何类型的数据进行建模:输入、中间或输出数据、内部或外部数据、本地或远程数据、历史数据、一组参数、经过训练的模型等。
视觉元素(Visual Elements, 控件)
视觉元素是显示在给定页面上的用户界面对象。它们反映了一些应用程序数据或为页面提供了一些结构或布局信息。大多数视觉元素允许用户与页面内容交互。
有两种类型的视觉元素:
- 控件(Controls or Generic controls)通常表示用户可以与之交互的用户数据。通用控件在通用控件部分中列出。场景管理控件(Scenario Management controls)部分提供了一些专用于场景和数据管理的控件。
- 块(Blocks) 在块元素部分中列出。它们允许您在页面中组织控件(或块),以提供最佳的用户体验。
![]()
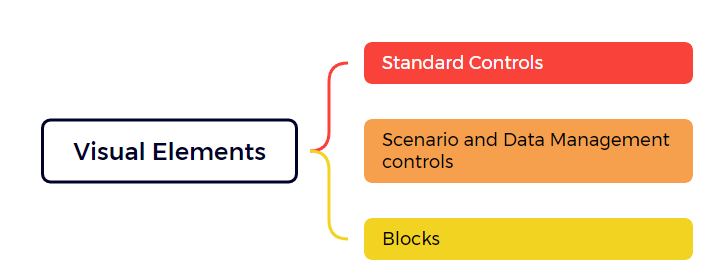
Taipy 提供了各种可视化元素,允许定义应用程序页面的视觉元素(Visual elements,也就是我们常说的“控件”)。
在需要用户界面的所有情况下都可以使用通用控件。这些控件是表示通用数据的元素。添加视觉元素的语法是 如下:
#Markdown
<|{variable}|visual_element_name|param_1=param_1|param_2=param_2| ... |>
#python
tgb.visual_element_name("{variable}", param_1=param_1, param_2=param_2, ...)
变量的包含告诉Taipy显示和使用变量的实时值。Taipy不是重新执行整个脚本,而是智能地调整GUI的必要元素来反映更改,确保响应性和性能优化的用户体验。
更多控件,如按钮和滑块,以及更高级的图形控件,如选择器、表格和图表等,可参考:https://docs.taipy.io/en/latest/refmans/gui/viselements/
这些元素可以与你的 Python 变量和 环境。它允许您显示变量、修改变量并与应用程序交互。
鉴于可用的视觉元素种类繁多,手动输入所有内容可能会很麻烦。Taipy Studio 提供代码完成功能,以帮助填充元素定义文本片段。
检测 Markdown 文本中的拼写错误和错误可能具有挑战性。 Taipy Studio 会识别这些问题并在“问题”视图中报告它们,通常会提供“快速修复”操作以快速解决语法问题。
在需要用户界面的所有情况下都可以使用通用控件。这些控件是表示通用数据的元素,以及更高级的图形控件,如选择器、表格和图表。
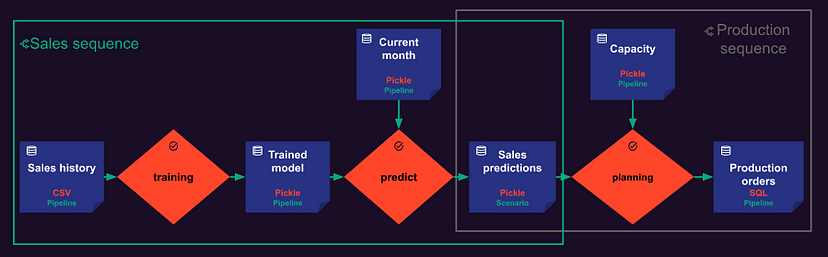
场景(Scenario或管道)
为了理解场景(Scenario), 需要先了解 Data Nodes(数据节点) 和 Task (任务)概念。
- Data Nodes:表示Taipy中的一个变量。数据节点不包含数据本身,但指向数据并知道如何检索数据。这些数据节点可以指向不同类型的数据源,如CSV文件、Pickle文件、数据库等,它们可以表示各种类型的Python变量,如整数、字符串、数据帧、列表等。它们是完全通用的,可用于表示数据集、参数、kpi、中间数据或任何变量。
- Tasks:是Taipy中函数的转换,其中它们的输入和输出是数据节点。
- Scenario:场景是将 Data Nodes 和 Task 组合在一起,从而创建场景,形成一个映射执行流的图形。每个场景都可以提交,从而执行其任务。
最终用户经常需要修改各种参数来反映不同的业务情况。Taipy提供了在不同情况下执行各种场景的框架(即最终用户设置的各种数据/参数值)。
![]()
以上图例通过配置三个数据节点(historical_temperature、date_to_forecast 和 predictions)。任务 predict 通过 Python 函数链接三个 Data Nodes。

例:使用Taipy Studio进行配置场景,通过观看下面的动画,您可以看到如何使用Taipy Studio创建此配置。
实际上,Taipy Studio是一个特定于Taipy的TOML文件编辑器。它允许您编辑和查看将在我们的代码中使用的TOML文件。
参考页面:https://docs.taipy.io/en/latest/tutorials/articles/scenario_management_overview/#__tabbed_1_2
场景的比较:https://docs.taipy.io/en/latest/tutorials/articles/scenario_comparison/
Taipy 场景表示具有一致数据和参数的业务问题。它是一种强大的工具,可用于根据不同的假设创建业务问题的不同版本。这对于决策过程中的假设分析特别有用,允许用户在单个应用程序中生成、保存、编辑和运行具有各种参数的多个场景。
每个场景都包含一个可提交执行的有向无环图 (DAG)。此 DAG 是一组连接数据节点的任务,可以通过定义序列将其进一步划分为较小的图以供执行。序列是来自场景任务集的连接任务的子集,形成可独立提交的较小的可执行 DAG。此外,场景可能包含不属于场景 DAG 的额外数据节点,表示与场景相关的额外数据。但是,场景的执行不会计算这些额外的数据节点。
用户分析了初始场景后,他们可能想要调整输入数据节点(不包括中间节点和输出节点),重新运行相同的序列或整个场景,并比较结果。这涉及创建新场景、调整输入数据、执行该场景,然后将结果与第一个场景进行比较。
此迭代过程可以在多个场景中重复,从而可以彻底探索和分析问题的各种版本。
场景管理,参考:https://docs.taipy.io/en/latest/tutorials/articles/scenario_management_overview/#__tabbed_3_1
Taipy场景根据所选类型过滤数据,对类型选择的任何修改都会触发场景的自动运行
Taipy 场景的特点:
- 它注册每个场景的执行,使用户能够监控一段时间内的 KPI 并对不同的运行进行基准测试,提供假设场景。
- Taipy 包含用于场景交互的即用型 UI 组件,允许输入和参数的选择、场景的执行和跟踪,以及结果可视化。
- Taipy 有效地管理计算,避免了对未更改数据进行不必要的重新运行。
- Taipy 可轻松与大多数流行的数据源集成。
- 它支持并发计算,从而提高处理速度和可扩展性。
配置是定义场景的结构。 它作为我们有向无环图的蓝图,并对数据源进行建模。 参数和任务。定义后,配置的功能类似于超类,并且是 用于生成各种场景实例。
Data Nodes (数据节点)
表示 Taipy 中的一个变量。 数据节点不包含数据本身,不保存实际数据,但指向数据并知道如何检索它。或者说,它包含访问和修改数据所需的所有基本信息——一种数据集描述符或数据引用。
这些数据节点可以指向不同类型的数据源,如 CSV 文件、Pickle 文件、数据库等,它们可以表示各种类型的 Python 变量 例如整数、字符串、数据帧、列表等。它们是完全通用的,可以是用于表示数据集、参数、KPI、中间数据或任何变量。
数据节点是一个至关重要的概念。它可以灵活地引用各种类型的数据:
- 文本
- 数值
- 参数的列表、元组、集合或字典
- 自定义 Python 对象(如数据框或数据类)
- 来自 JSON、CSV、Pickle 或 Parquet 等文件的内容
- 来自一个或多个数据库表的数据
- 任何其他形式的数据
其目的是对各种数据类型进行建模,无论它们是输入、中间或输出数据、内部或外部、本地或远程、历史数据、一组参数、经过训练的模型等等。
Tasks(任务)
Task 是Taipy中函数的转换,task的输入和输出是Data Nodes (数据节点)。
也可以这样理解:
Taipy中的任务是开发人员打算执行的 Python 函数。它表示开发人员打算在序列中实现的步骤之一。
例如,任务可能是负责清理初始数据集的预处理函数。或者,它可能是一个涉及训练机器学习模型的更复杂的函数。
鉴于任务代表一个函数,它可以接收一组参数作为输入并产生一组结果作为输出。每个输入参数和输出结果都被视为一个数据节点。
任务的特征(包括输入数据节点、输出数据节点和 Python 函数)由任务配置 (TaskConfig) 指定。创建新任务时必须提供此配置。(有关配置的更多详细信息,请参阅配置文档。)
Config files(配置文件)
配置文件是定义场景的结构。 它作为我们的有向无环图的蓝图,并为数据源、参数和任务建模。在定义之后,配置的功能类似于超类,并用于生成各种场景的实例。
作业
可以发送任务、序列和场景等实体以供执行。提交场景时,它会启动其包含的所有任务的提交。同样,提交序列会触发该序列内所有任务的执行。
每次提交任务以供执行时,都会生成一个新的作业。作业代表任务的单一执行实例。它包含与任务执行相关的所有相关信息,例如创建日期、执行状态、用户函数日志消息以及可能发生的任何异常堆栈跟踪。
Frequency (周期)
数据应用程序通常解决遵循特定时间周期的重复性业务挑战。
示例包括:
商店 X 的每周销售数据预测。
公司 A 的供应链的每月总体规划。
为了满足这一需求,Taipy 引入了“周期”(或工作周期)的概念,表示这种时间模式的单次迭代。 每个周期都有一个开始日期和持续时间,由场景的选定时间频率决定。
在 Taipy 中,场景可以具有以下频率:
Frequency.DAILY
Frequency.WEEKLY
Frequency.MONTHLY
Frequency.QUARTERLY
Frequency.YEARLY
创建新场景时,它会链接到与其频率和创建日期相匹配的特定周期。
Scope(范围)
数据节点的范围由具有以下值的枚举确定:
- Scope.SCENARIO(默认值):每个方案都有一个数据节点。
- Scope.CYCLE :通过在给定周期的所有场景中共享数据节点来扩展范围。
- Scope.GLOBAL : 最后,将范围扩展到全球(涵盖所有周期的所有场景)。例如,初始/历史数据集通常由所有场景/周期共享。它在整个应用程序中是唯一的。
配置数据节点时,开发人员指定每个数据节点的类型或格式及其范围。
存储类型:指定数据节点的存储类型,例如 CSV 文件、Pickle 文件等。例如,初始数据集是 storage_type=“csv” 的 CSV 文件。
每个数据节点都拥有一个范围,这是由 DataNodeConfig 定义的属性,指示数据节点在实体图中的可见性。在此图中,每个节点都是一个或多个父节点的一部分。数据节点与单个周期内的至少一个场景相关联。
![image]()
简而言之:
具有 Scope.SCENARIO 的数据节点可以由单个场景中的多个任务和序列使用,但不能成为另一个场景的任务或序列的一部分。
Scope.CYCLE 的数据节点可以在一个周期内的所有任务、序列和场景之间共享,但不能与不同周期的任务、序列或场景共享。
Scope.GLOBAL 的数据节点可以由任何任务、序列和场景共享,无论它们的周期如何。
Taipy 可用控件列表(UI 视觉元素)
以下是Taipy 中可用控件的列表:
文本/按钮/输入/数字/滑块/切换/日期/文件下载/文件选择器/图像/指示器/菜单/导航栏/选择器/状态/表格/对话框/树/图表/
以下是Taipy 中所有可用块元素的列表:
零件
可展开
布局
窗格
Taipy项目的基本结构
安装完Taipy, 可在VS code或 Trae的开发环境下,运行:taipy create --application default 来创建一个程序的基架
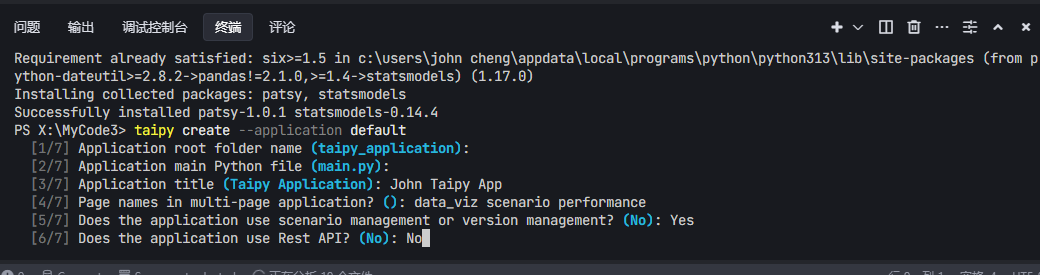
1. Taipy 的典型项目目录结构
如下:
.
├── main.py # 主应用程序文件
└── main.css # 应用程序样式文件
main.py: 这是你的核心代码所在,用于定义应用逻辑和界面元素。
main.css: 你可以在此文件中自定义应用程序的样式。
2. 项目的启动文件介绍
main.py 是你的项目启动文件,它包含了使用 Taipy 构建的 Web 应用的核心组件。下面是一个简单的 main.py 文件示例:
from taipy import *
# 创建一个页面
page = Page(title="我的 Taipy 应用")
# 添加控件
genre_slider = Slider(value=1, min=1, max=5)
chart = BarChart()
# 定义布局
row = Row([genre_slider], width='20%', flex_grow=0)
column = Column([chart], width='80%', flex_grow=1)
# 将布局添加到页面
page.add(row, column)
# 启动应用
run_app(page)
在这个例子中,我们创建了一个页面并添加了一个滑块和一个柱状图,然后定义了它们在页面上的布局。最后,我们调用 run_app 来启动 Web 应用。
3. 项目的配置文件介绍
Taipy 默认不使用特定的配置文件,但你可以在你的应用程序中设置环境变量来改变某些行为。例如,你可以通过 TAIPY_SERVER_PORT 环境变量来指定服务器运行的端口:
export TAIPY_SERVER_PORT=5000
此外,如果你的应用需要数据库连接或外部服务的配置,通常建议将这些配置作为单独的 JSON 或 YAML 文件管理,并在 main.py 中加载。这不属于 Taipy 自身的特性,但可以通过第三方库如 PyYAML 或 json 模块实现。
请注意,虽然上述信息基于提供的文档,但可能需要根据实际项目结构进行调整。对于更具体的配置选项和用法,建议查阅 Taipy 的官方文档和示例项目。
Taipy基本功能
taipy库主要为数据驱动的应用提供快速开发能力,包括构建用户界面、数据绑定和事件处理等
表的运用
详见:https://docs.taipy.io/en/latest/tutorials/articles/using_tables/
接受回调函数(Callback,其实我觉得叫:反馈更合适)
在 Taipy 中,当应用程序中的某些变量被修改时,on_change 回调会触发一个 Python 函数的执行。此回调用于在用户执行某些操作(例如拖动滑块以定义某个参数的值或在输入框中输入某些文本)之后实现某些行为。
代码网址:https://docs.taipy.io/en/latest/tutorials/articles/callbacks/
请注意,Taipy 支持多种类型的回调函数,它们各自有不同的用途,尽管本提示仅关注其中一种。这些回调函数是:
- on_change(此提示的主题)
- on_action
- on_init
- on_navigate
- on_exception
让我们来看看两种不同类型的 on_change 回调函数:
Example 1: 本地(或受控绑定的)on_change 回调函数;以及Example 2: 全局 on_change 回调函数。
这个流程图清晰地展示了 Taipy 如何确定会调用哪个 on_change 函数的过程。
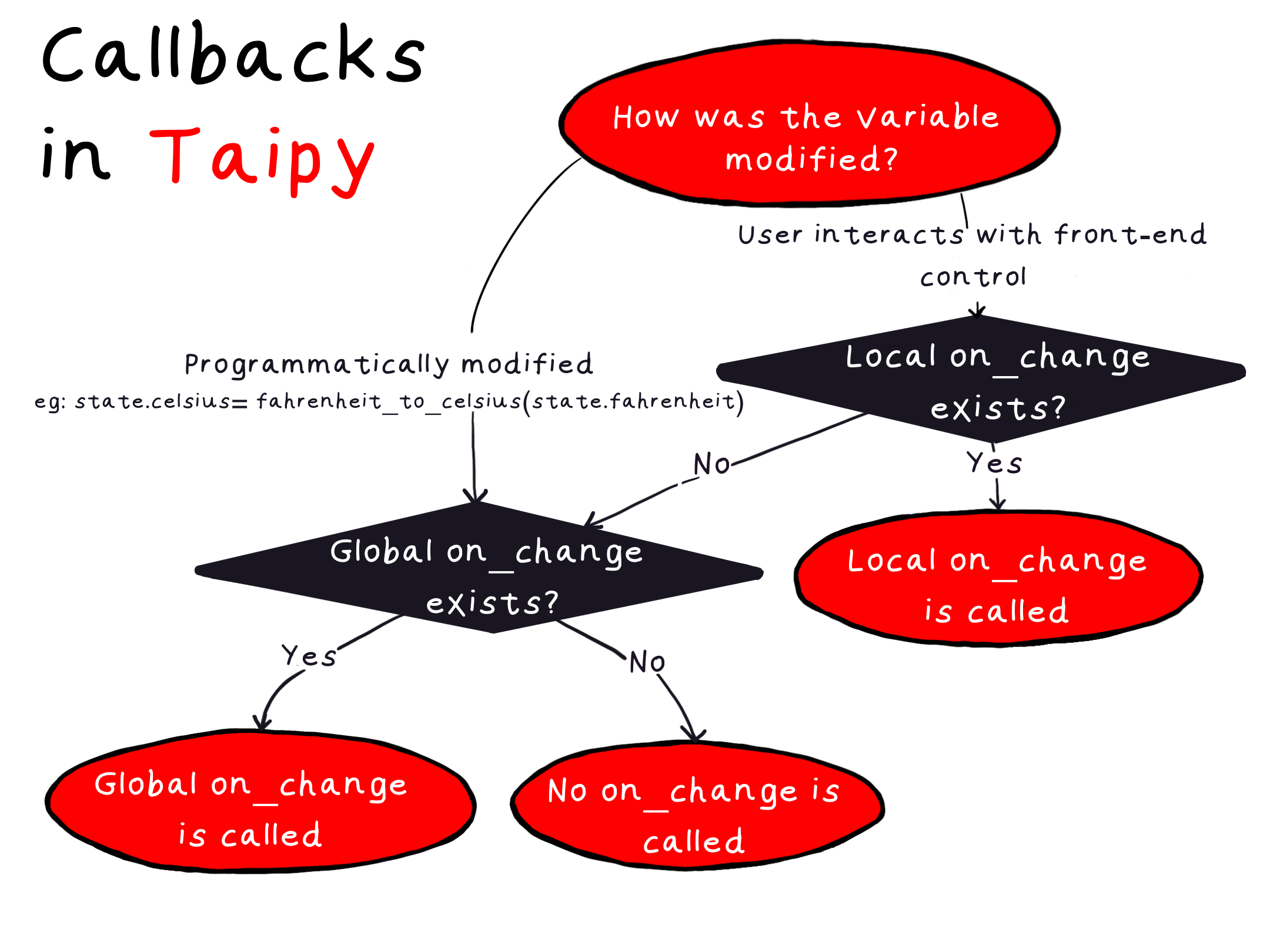
Example 1: Fahrenheit to Celsius (Local Callback)
在本例中提及回调时,我们仅指 on_change 回调,仅此就足以构建从简单到复杂的网络应用程序!
本地回调函数是绑定到特定 Taipy 控件(一种视觉元素)的函数。当用户与该控件进行交互时,此函数就会被调用。例如,在 Taipy 中,这可能发生在以下情况:
拖动滑块控件来选择某个数字;使用日期控件选择一个日期;或者从选择器控件中选择一项。
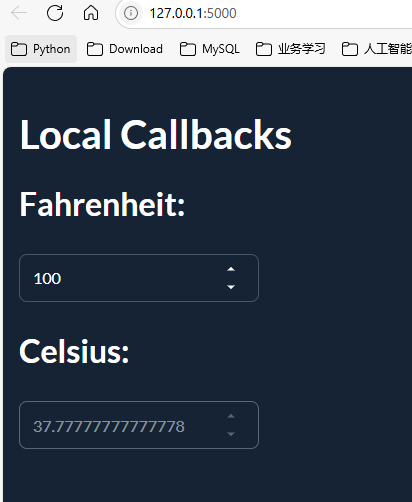
from taipy.gui import Gui, Markdown
def fahrenheit_to_celsius(fahrenheit):
return (fahrenheit - 32) * 5 / 9
def update_celsius(state):
state.celsius = fahrenheit_to_celsius(state.fahrenheit)
if __name__=="__main__":
fahrenheit = 100
celsius = fahrenheit_to_celsius(fahrenheit)
md = Markdown("""
# Local Callbacks
## Fahrenheit:
<|{fahrenheit}|number|on_change=update_celsius|>
## Celsius:
<|{celsius}|number|active=False|>
""")
Gui(page=md).run()
这里相关的行是第 12 行,我们在那里使用了 Taipy 构造语法定义了一个数字控件。我们将用它来选择以华氏度表示的温度,我们希望将其自动转换为摄氏度。
上述结构由 3 个部分组成(被管道分隔开来):
{华氏度}:与该数字控件相关联的变量;
“数字”:泰皮控件的名称;并且on_change="更新摄氏温度": 将此控件的 on_change 局部回调函数设置为 update_celsius 函数
第 18 行定义的 update_celsius 本地回调函数接收一个参数,我们通常将其命名为 state 。
我们可以在函数中使用这个状态对象来访问和修改应用程序中使用的运行时变量,我们也将这些变量称为状态变量。因此,在第 19 行我们更新了 celsius 的值。
现在,当用户与数字控件进行交互时,名为“update_celsius”的本地回调函数会计算并更新“celsius”状态变量的值,并显示其新的数值。
Example 2: Celsius to Kelvin (Global Callback)
本程序是另一个简单的改进:添加一个新的数字控件来显示以开尔文 Kelvin为单位的温度。
在第 22 行,我们在应用程序中添加了一个新的数字控件,该控件与“开尔文”变量相关联。
之前的代码(即当“华氏度”值发生变化时更新“摄氏度”的代码)保持不变。
本例我们现在要实现的行为是:每当摄氏温度的值发生变化时,就更新开尔文温度的值。
这是一个非常适合使用全局“on_change”回调函数的示例。请看这个简洁明了的流程图,它能确定将会调用哪种“on_change”函数:
from taipy.gui import Gui, Markdown
def fahrenheit_to_celsius(fahrenheit):
return (fahrenheit - 32) * 5 / 9
def celsius_to_kelvin(celsius):
return celsius + 273.15
def update_celsius(state):
state.celsius = fahrenheit_to_celsius(state.fahrenheit)
def on_change(state, var_name, var_value):
if var_name == "celsius":
state.kelvin = celsius_to_kelvin(state.celsius)
if __name__=="__main__":
fahrenheit = 100
celsius = fahrenheit_to_celsius(fahrenheit)
kelvin = celsius_to_kelvin(celsius)
md = Markdown("""
# Local and Global Callbacks
## Fahrenheit:
<|{fahrenheit}|number|on_change=update_celsius|>
## Celsius:
<|{celsius}|number|active=False|>
## Kelvin:
<|{kelvin}|number|active=False|>
""")
Gui(page=md).run(dark_mode=False)
在这个示例中,我们的“更新摄氏温度”函数执行了以下代码:
state.celsius = fahrenheit_to_celsius(state.fahrenheit)
我们称这种操作为通过程序方式修改“摄氏温度”变量。从上面的流程图来看,如果存在全局的“on_change”函数,那么该函数将会被调用。
全局回调函数应具有确切的名称“on_change”,以便 Taipy 能自动识别它。
全局“on_change”函数的参数通常按以下方式命名:
- 状态:该“状态”对象允许我们访问和修改运行时变量;
- 变量名:被修改的变量的名称;并且var_value:被修改的变量的值
请注意,在第 33 行,我们在对“kelvin”进行更新之前先添加了一个“if var_name == 'celsius'"”的代码块。在“on_change”函数中,我们几乎总是希望在“if”块内进行操作,以避免通过“on_change”函数产生意外的无限递归。
请记住,通过编程方式修改“kelvin”或其他任何变量也会调用“on_change”函数,不过由于我们设置了“if”块,这种执行不会产生任何变化。
您可能还会注意到,这一部分的功能其实也可以通过使用现有的 update_celsius 本地回调函数来实现。而且在这种特定情况下,添加全局回调并非必要之举。不过,您可能会遇到一些情况,即仅使用本地回调可能无法解决问题,此时使用全局回调可能是更好的选择。
Example 3: No Callbacks (掌握无回调的缺点)
下面这个例子没有使用任何Callbacks:
from taipy.gui import Gui, Markdown
def fahrenheit_to_celsius(fahrenheit):
return (fahrenheit - 32) * 5 / 9
def celsius_to_kelvin(celsius):
return celsius + 273.15
if __name__=="__main__":
fahrenheit = 100
celsius = fahrenheit_to_celsius(fahrenheit)
kelvin = celsius_to_kelvin(celsius)
md = Markdown("""
# Global Callbacks
## Fahrenheit:
<|{fahrenheit}|number|>
## Celsius:
<|{fahrenheit_to_celsius(fahrenheit)}|number|active=False|>
## Kelvin:
<|{celsius_to_kelvin(fahrenheit_to_celsius(fahrenheit))}|number|active=False|>
""")
Gui(page=md).run()
无需使用任何回调函数,我们只是将要计算的表达式直接插入到度数(摄氏度和开尔文)控件的花括号中——就像使用 f 字符串一样!由于表达式中存在华氏度状态变量,Taipy 知道每当华氏度被修改时,该表达式都应重新计算。
然而,这种方法的一个缺点是函数“fahrenheit_to_celsius”会被执行两次。对于像这样简单的函数来说,这个缺点并不严重。但是,如果这是一个复杂且不可缓存的函数,我们肯定希望避免不必要的执行。
创建界面
taipy允许开发者通过定义布局描述来创建用户界面。布局使用简单的字符串格式,可以快速构建出包含多种元素的页面。
from taipy.gui import Gui
#创建GUI对象
gui = Gui()
# 添加页面和布局
gui.add_page(name="main_page", layout="""
# 使用Markdown定义界面元素
# 欢迎使用taipy
- 输入你的名字: <|input|>
- 你好, <|{name}|>
""")
#运行GUI应用
gui.run()
在这个例子中,定义了一个包含文本输入和显示的简单界面。用户输入的内容将实时更新到屏幕上。
数据绑定
taipy强大的数据绑定功能允许开发者将界面组件直接与数据模型链接。这意味着当数据更新时,界面也会自动更新,无需额外的代码。
from taipy.gui import Gui, state
gui = Gui()
# 定义状态变量
@state
def get_data():
return {"name": "未命名"}
# 页面布局与状态绑定
gui.add_page(name="main_page", layout="""
# 更新名字
- 请输入你的名字: <|input value={name}|>
- 你好, <|{name}|>
""", data=get_data())
# 运行GUI应用
gui.run()
在此代码中,使用@state装饰器定义了一个名为get_data的函数,该函数返回包含名字的字典。这个状态与输入组件和显示文本绑定,因此用户的输入将实时反映在界面上。
事件处理
taipy还支持事件处理,使得开发者可以响应用户的操作,如按钮点击或输入更改,来执行特定的逻辑。
from taipy.gui import Gui, state
gui = Gui()
# 状态和事件处理器
@state
def get_data():
return {"counter": 0}
def increment_counter(data):
data["counter"] += 1
# 页面布局和事件绑定
gui.add_page(name="counter_page", layout="""
- 当前计数: <|{counter}|>
- <|button text="增加" on_click=increment_counter|>
""", data=get_data())
# 运行GUI应用
gui.run()
这个例子创建了一个简单的计数器,每次用户点击“增加”按钮时,计数值就会增加。这通过increment_counter函数实现,该函数作为按钮的点击事件处理器。
Taipy应用范例
1,生成一个图形
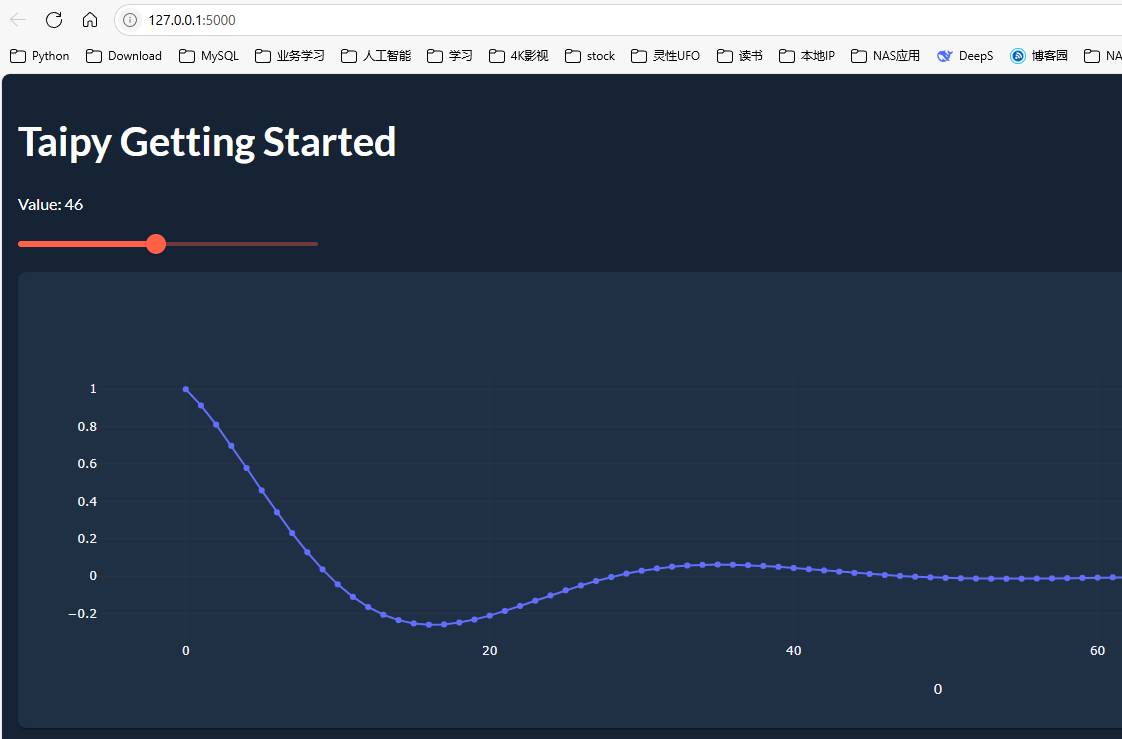
代码如下:
from taipy.gui import Gui
import taipy.gui.builder as tgb
from math import cos, exp
value = 10
def compute_data(decay:int)->list:
return [cos(i/6) * exp(-i*decay/600) for i in range(100)]
def slider_moved(state):
state.data = compute_data(state.value)
with tgb.Page() as page:
tgb.text(value="# Taipy Getting Started", mode="md")
tgb.text(value="Value: {value}")
tgb.slider(value="{value}", on_change=slider_moved)
tgb.chart(data="{data}")
data = compute_data(value)
if __name__ == "__main__":
Gui(page=page).run(title="Dynamic chart")
遇到一个问题:TypeError: Can't replace canonical symbol for 'firstlineno' with new int value 615

解决办法:
pip uninstall taipy-gui sqlalchemy
pip install taipy-gui sqlalchemy
2,生成速度表
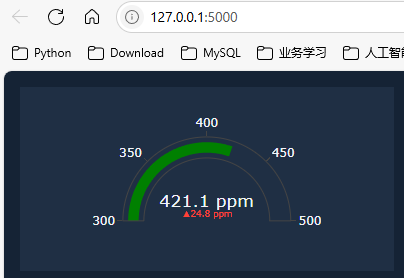
from taipy.gui import Gui
# Source: https://gml.noaa.gov/ccgg/trends/gl_gr.html
# Estimated Global Trend on january 1st:
co2_2014 = 396.37
co2_2024 = 421.13
delta = co2_2024 - co2_2014
page = """
<|{co2_2024}|metric|delta={delta}|delta_color=invert|format=%.1f ppm|delta_format=%.1f ppm|min=300|max=500|>
"""
if __name__ == "__main__":
Gui(page).run(title="Metric - Delta color")
3,一个完整的例子
参考:https://docs.taipy.io/en/latest/tutorials/articles/complete_application/
代码:https://docs.taipy.io/en/latest/tutorials/articles/complete_application/src/src.zip
步骤:
- “数据可视化”页面
- 使用的算法
- 场景配置
- “方案”页
- “性能”页面
创建 Data Visualization 页面的指南。该页面包括 用于展示 CSV 文件中的数据的交互式视觉元素。
4.BI站上的一个教学视频 (受益菲浅)+ GPU加速运行pandas
【2024.12.04 【Python Simplified】使用 Taipy 场景创建数据仪表板 GUI 应用程序 - 分步 Python 教程】https://www.bilibili.com/video/BV1WFiXYnEw6?vd_source=4c755e004efbb8d0663a70c50a73a511
课程效果:
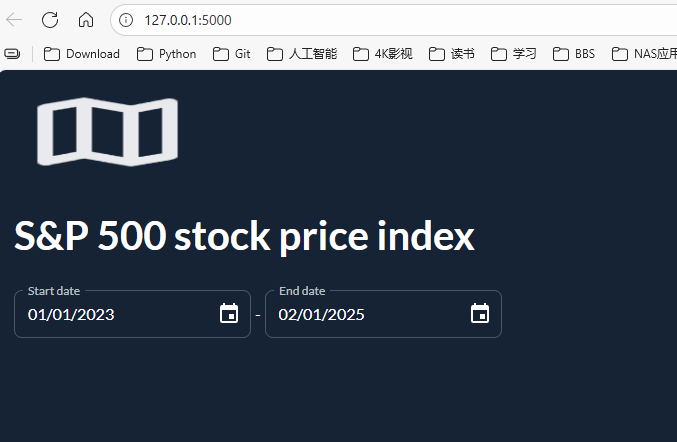
课程代码:
import taipy as tp
import taipy.gui.builder as tgb
from taipy.gui import icon
from taipy.gui import config
import datetime
dates = [
datetime.date(2023, 1, 1),
datetime.date(2025, 2, 1),
]
#create page
with tgb.Page() as page:
# This is a part"
with tgb.part("text-certer"):
tgb.image("images/map.png", width="10vw", height="10vh ")
tgb.text(
"# S&P 500 stock price index",
mode="md"
)
tgb.date_range(
"{dates}",
label_start="Start date",
label_end="End date"
)
if __name__ == "__main__":
gui = tp.Gui(page)
gui.run(
title="Data Science Dashboard",
use_reloader=True
)
RAPIDS GPU加速运行pandas
1.安装
用户指南 - RAPIDS 文档 https://docs.rapids.ai/install/
Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit
RAPIDS 数据科学框架是用于完全在 GPU 上运行端到端数据科学管道的库集合。该交互旨在具有熟悉的 Python作外观和感觉,但在后台利用了优化的 NVIDIA® CUDA® 基元和高带宽 GPU 内存。
cuDF 是一个 Python GPU DataFrame 库(基于 Apache Arrow 列式内存格式构建),用于使用 pandas 风格的 DataFrame 样式 API 加载、连接、聚合、过滤和以其他方式作表格数据。
Dask 是一个灵活的 Python 并行计算库,可使您的工作流程横向扩展变得顺畅而简单。在 CPU 上,Dask 使用 Pandas 在 DataFrame 分区上并行执行作。
Dask cuDF 在必要时扩展 Dask,以允许使用 cuDF GPU DataFrame 而不是 Pandas DataFrames 处理其 DataFrame 分区。例如,当您调用 时,集群的 GPU 会通过调用 来解析 CSV 文件的工作。dask_cudf.read_csv(...)
所有RAPIDS包现在都可以在 Anaconda, Docker and cloud-based solutions (如谷歌Colaboratory)上免费使用。
RAPIDS结构是基于不同的库来实现数据科学从一端到另一端的加速(图2),其主要组成部分为:
• cuDF =用于执行数据处理任务(如Pandas)。
• cuML =用于创建机器学习模型(如Sklearn)。
• cuGraph =用于执行绘图任务(图论Graph Theory)。
RAPIDS还结合了:用于深度学习的PyTorch & Chainer,用于可视化的Kepler GL,以及用于分布计算的Dask。
- py程序配置
#使用下面的顺序
import cudf.pandas
cudf.pandas.install()
import pandas as pd
Taipy高级功能
自定义组件
Taipy支持开发者创建自定义组件,使得可以根据特定需求设计独特的界面元素,提供更灵活的用户界面选项。
from taipy.gui import Gui, Component
# 创建自定义组件
class CustomComponent(Component):
def render(self, props):
# 返回带有样式的HTML元素
return f"<div style='background-color:{props.color};padding:10px;'>{props.text}</div>"
gui = Gui()
# 注册自定义组件
gui.add_custom_component("my_custom_component", CustomComponent())
# 使用自定义组件
gui.add_page(name="main_page", layout="""
## 使用自定义组件
- <|my_custom_component text="这是一个自定义组件!" color="lightblue"|>
""")
# 运行GUI应用
gui.run()
在这个例子中,定义了一个CustomComponent类,它接受颜色和文本作为属性,并渲染一个带有特定背景色和内填充的HTML div元素。这种方式可以让开发者在taipy应用中实现高度自定义的界面元素。
异步数据处理
taipy支持异步操作,使得应用可以处理耗时的数据操作而不阻塞用户界面,提升用户体验。
from taipy.gui import Gui, state
import asyncio
gui = Gui()
# 定义异步函数获取数据
async def fetch_data():
await asyncio.sleep(2) # 模拟数据加载
return "从服务器加载的数据"
# 使用状态管理异步数据
@state
async def get_data():
return await fetch_data()
gui.add_page(name="main_page", layout="""
## 异步数据加载
- 数据加载中...
- <|{get_data()}|>
""")
# 运行GUI应用
gui.run()
在此代码示例中,使用async定义了异步函数fetch_data,该函数模拟了一个耗时的数据加载过程。通过@state装饰器,将其与GUI状态绑定,实现了数据的异步加载和显示。
高级数据绑定
taipy还提供高级数据绑定选项,允许开发者控制数据的更新和渲染方式,适用于处理复杂的数据逻辑和大量数据的情况。
from taipy.gui import Gui, state
gui = Gui()
# 定义复杂数据处理逻辑
@state
def complex_data_operations():
large_dataset = [i**2 for i in range(10000)]
return sum(large_dataset)
gui.add_page(name="main_page", layout="""
## 复杂数据处理展示
- 计算结果: <|{complex_data_operations()}|>
""")
# 运行GUI应用
gui.run()
这个示例中,定义了一个执行复杂数据操作的函数,该函数处理一个大数据集并计算其元素的平方和。通过taipy的高级数据绑定,这些计算可以在后台执行,而不会影响界面的响应性。
Taipy的高级特性,除了基本的Web应用构建功能,Taipy还具有许多高级特性,使其成为一个强大的工具。
- WebSocket支持
Taipy内置了对WebSocket的支持,这使得构建实时Web应用和聊天应用变得非常容易。
以下是一个简单的WebSocket示例:
import taipy
import tornado.websocket
class WebSocketHandler(tornado.websocket.WebSocketHandler):
def open(self):
print("WebSocket opened")
def on_message(self, message):
self.write_message(f"You said: {message}")
def on_close(self):
print("WebSocket closed")
def make_app():
return taipy.Application([
(r"/websocket", WebSocketHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
taipy.ioloop.IOLoop.current().start()
在上述示例中,创建了一个WebSocketHandler处理器,它继承自tornado.websocket.WebSocketHandler。open方法在WebSocket连接建立时调用,on_message方法用于处理消息,on_close方法在连接关闭时调用。这可以构建实时的双向通信应用程序。
- 异步数据库访问
Taipy与异步数据库访问库(如aiomysql、aiopg等)集成得很好,可以轻松地进行异步数据库查询。
以下是一个使用aiomysql进行异步数据库查询的示例:
import taipy
import tornado.web
import aiomysql
async def fetch_user_from_db():
conn = await aiomysql.connect(host='localhost', user='user', password='password', db='mydb')
async with conn.cursor() as cursor:
await cursor.execute('SELECT * FROM users')
result = await cursor.fetchall()
conn.close()
return result
class DatabaseHandler(tornado.web.RequestHandler):
async def get(self):
users = await fetch_user_from_db()
self.write(f"Users: {users}")
def make_app():
return taipy.Application([
(r"/database", DatabaseHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
taipy.ioloop.IOLoop.current().start()
在上述示例中,定义了一个异步函数fetch_user_from_db,它使用aiomysql库连接到数据库并执行查询。在DatabaseHandler处理器中,使用await关键字调用fetch_user_from_db来获取数据库中的用户数据。
- 中间件支持
Taipy可以使用中间件来添加全局功能,例如身份验证、日志记录和性能监控。可以创建自定义中间件,并将它们添加到应用程序中,以在请求处理过程中应用它们。
import taipy
import tornado.web
class MyMiddleware(tornado.web.RequestHandler):
async def prepare(self):
# 在请求处理前执行的代码
pass
def on_finish(self):
# 在请求处理后执行的代码
pass
def make_app():
return taipy.Application([
(r"/", MainHandler),
], middleware=[MyMiddleware])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
taipy.ioloop.IOLoop.current().start()
在上述示例中,创建了一个名为MyMiddleware的自定义中间件,并将其添加到应用程序中。prepare方法在请求处理之前执行,on_finish方法在请求处理之后执行。这可以在全局范围内添加和管理中间件,以实现各种功能。
总结
Taipy是一个功能强大的Web应用构建工具,它集成了Tornado、asyncio和IPython,为开发者提供了高性能和便利性。通过本文,了解了Taipy的各个组成部分以及如何使用它们来构建现代Web应用。无论是初学者还是有经验的开发者,Taipy都可以帮助大家轻松创建高性能的Web应用,实现各种高级功能。
其它学习或参考网站
http://www.bimant.com/blog/taipy-magical-tool-for-building-ai-apps/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号