
NAS空间损毁救治
问题来了,绝望三连:
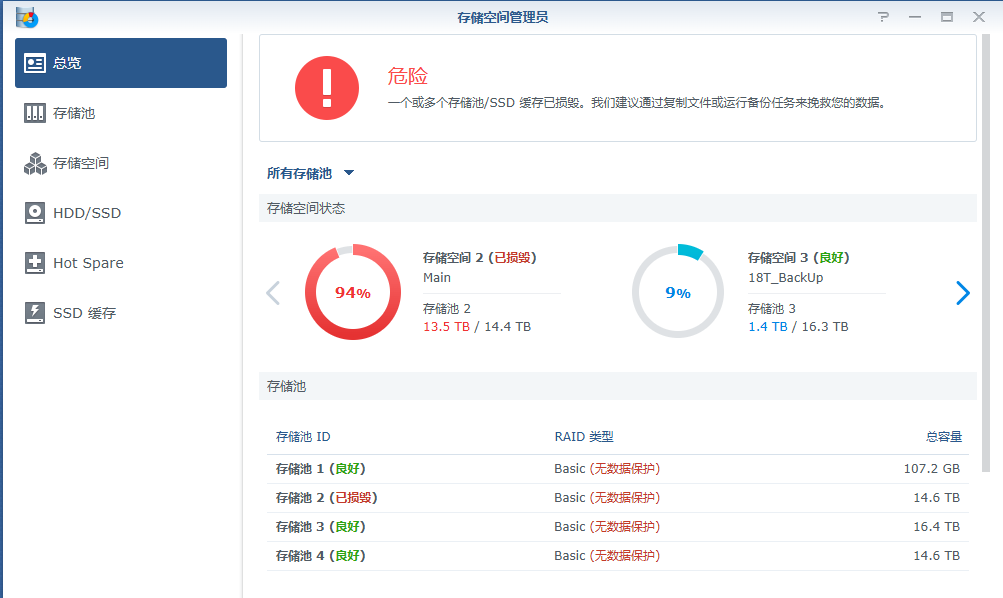
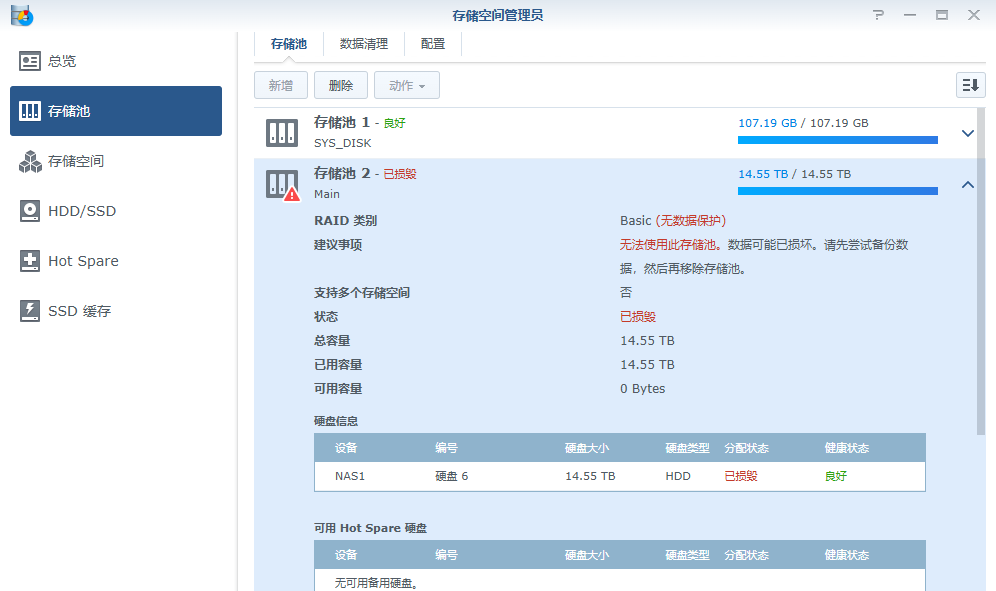
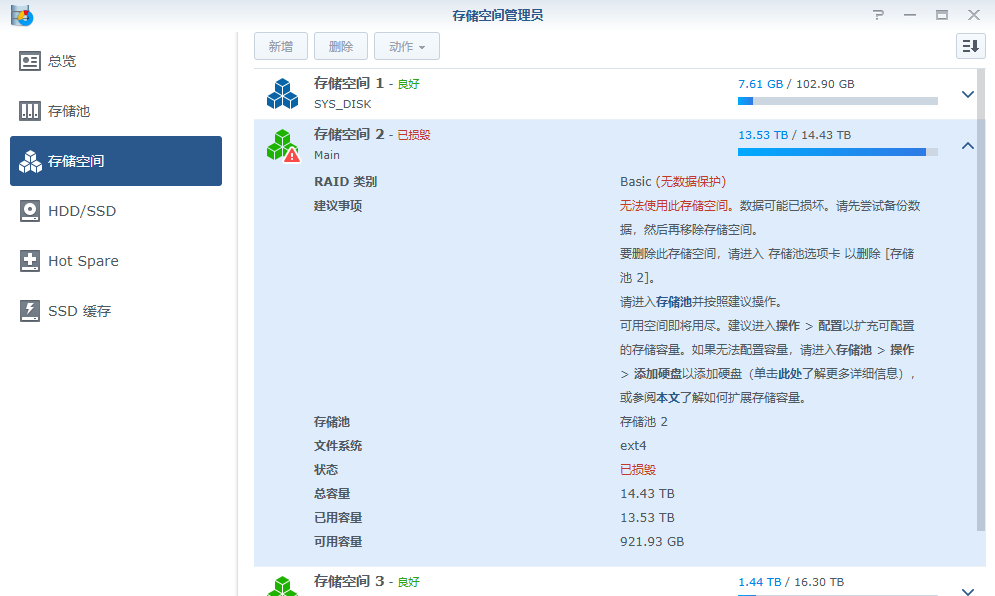
解决方案
我觉得有用的两个文章:
https://zhuanlan.zhihu.com/p/659651836
https://blog.csdn.net/weixin_42763067/article/details/134403248
观察各个md设备的情况
咋办呢?
用Putty连接NAS,在命令行下运行:cat /proc/mdstat
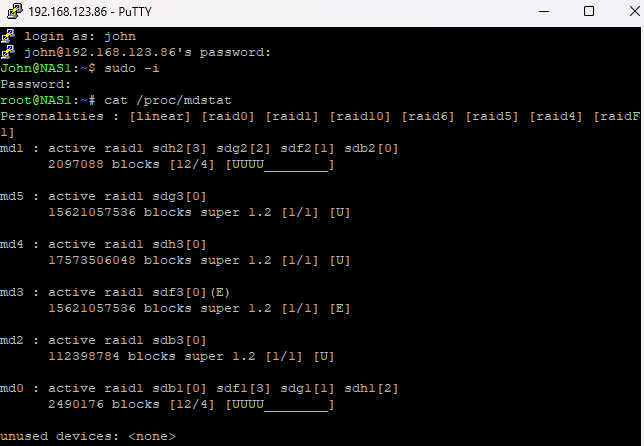
解读:
首先,观察各个md设备的情况:
md4是active raid1,使用sdh3,状态是[U],正常,只有一个成员,可能没问题。
md3是active raid1,但成员是sdf3,标记为(E),状态是[E],这可能意味着设备有问题。E通常代表错误或移除状态。
md2是active raid1,sdb3,状态[U],正常。
md5是active raid1,sdg3,状态[U],正常。
md1和md0都是raid1,有四个成员,但显示[12/4],这说明可能有配置问题,因为RAID1通常需要镜像,但成员数一般是2或更多。这里的[12/4]可能意味着总共有12个设备中的4个是活动的,但这种情况不太常见,可能配置错误或者某些设备被移除了。不过这两个md设备的状态显示[UUUU________],即前四个是Up,后面的可能缺失或失败。
现在,用户提到volume2已经损毁,通常NAS中的volume对应某个md设备或者由多个md设备组成。需要确定volume2对应哪个md设备。例如,可能md3对应volume2,因为md3的状态显示为(E),即错误状态,这可能导致volume2损坏。
在md3的描述中,它使用了sdf30,这里的(E)可能表示该设备被标记为错误或失效。RAID1需要至少一个正常设备,但如果所有设备都失效,阵列就会失败。但这里md3显示[1/1] [E],说明这个阵列只有一个成员,且该成员处于错误状态。这可能意味着sdf3出现了问题,导致md3无法正常工作,进而导致volume2损坏。
关键问题定位
关键问题定位:md3 (Volume2) 故障
/dev/sdf3 被标记为 faulty,但 SMART 检测显示硬盘物理健康(无坏道、无重定位扇区、无 pending 错误)。
故障原因可能是 RAID 元数据损坏(dmesg 提示 invalid raid superblock magic on sdf3)。
用命令查看故障盘的状态:mdadm -D /dev/md3
root@NAS1:~# mdadm -D /dev/md3
/dev/md3:
Version : 1.2
Creation Time : Thu Feb 16 01:25:05 2023
Raid Level : raid1
Array Size : 15621057536 (14897.40 GiB 15995.96 GB)
Used Dev Size : 15621057536 (14897.40 GiB 15995.96 GB)
Raid Devices : 1
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Fri Mar 21 23:12:21 2025
State : clean, FAILED
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name : NAS1:3 (local to host NAS1)
UUID : ff662d18:02f09dee:653614a3:d422f366
Events : 53
Number Major Minor RaidDevice State
0 8 83 0 faulty active sync /dev/sdf3
运行命令:fdisk -lu
点击查看fdisk -lu代码
root@NAS1:~# fdisk -lu
Disk /dev/sdb: 111.8 GiB, 120034123776 bytes, 234441648 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: dos
Disk identifier: 0xf7e31565
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 4982527 4980480 2.4G fd Linux raid autodetect
/dev/sdb2 4982528 9176831 4194304 2G fd Linux raid autodetect
/dev/sdb3 9437184 234236831 224799648 107.2G fd Linux raid autodetect
Disk /dev/sdf: 14.6 TiB, 16000900661248 bytes, 31251759104 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 41794060-A8AF-412E-BA11-AADBD68CAFF3
Device Start End Sectors Size Type
/dev/sdf1 2048 4982527 4980480 2.4G Linux RAID
/dev/sdf2 4982528 9176831 4194304 2G Linux RAID
/dev/sdf3 9437184 31251554303 31242117120 14.6T Linux RAID
Disk /dev/sdg: 14.6 TiB, 16000900661248 bytes, 31251759104 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: CE4C4EB9-6A61-EC11-A406-78AA82CFE3F6
Device Start End Sectors Size Type
/dev/sdg1 2048 4982527 4980480 2.4G Linux RAID
/dev/sdg2 4982528 9176831 4194304 2G Linux RAID
/dev/sdg3 9437184 31251554303 31242117120 14.6T Linux RAID
Disk /dev/sdh: 16.4 TiB, 18000207937536 bytes, 35156656128 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 9A6CBAEA-DB71-464F-9B02-3DB862AA3B9B
Device Start End Sectors Size Type
/dev/sdh1 2048 4982527 4980480 2.4G Linux RAID
/dev/sdh2 4982528 9176831 4194304 2G Linux RAID
/dev/sdh3 9437184 35156451327 35147014144 16.4T Linux RAID
Disk /dev/md0: 2.4 GiB, 2549940224 bytes, 4980352 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
GPT PMBR size mismatch (102399 != 61439999) will be corrected by w(rite).
Disk /dev/synoboot: 29.3 GiB, 31457280000 bytes, 61440000 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: B3CAAA25-3CA1-48FA-A5B6-105ADDE4793F
Device Start End Sectors Size Type
/dev/synoboot1 2048 32767 30720 15M EFI System
/dev/synoboot2 32768 94207 61440 30M Linux filesystem
/dev/synoboot3 94208 102366 8159 4M BIOS boot
Disk /dev/zram0: 1.1 GiB, 1229979648 bytes, 300288 sectors
Units: sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/zram1: 1.1 GiB, 1229979648 bytes, 300288 sectors
Units: sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/zram2: 1.1 GiB, 1229979648 bytes, 300288 sectors
Units: sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/zram3: 1.1 GiB, 1229979648 bytes, 300288 sectors
Units: sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/md2: 107.2 GiB, 115096354816 bytes, 224797568 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/md3: 14.6 TiB, 15995962916864 bytes, 31242115072 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/md4: 16.4 TiB, 17995270193152 bytes, 35147012096 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/md5: 14.6 TiB, 15995962916864 bytes, 31242115072 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/md1: 2 GiB, 2147418112 bytes, 4194176 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
root@NAS1:~#
我的恢复步骤
先备份数据(可选但建议)
本来我是想用cp命令来复制的,但是太慢了,文件量大容易断,于是就想着有个同步工具就好了,没想到NAS内置了rsync命令,真棒!
rsync 文件夹同步命令
rsync -av --ignore-existing --exclude='#recycle' /volume2/homes /volume4 #把/volume2/homes文件夹与/volume4目录同步,如有相同点则忽略,并排除'#recycle'这个文件夹
16T我差不多同步了三天三夜没关机 T_T
关机拔下重启热插,重建存储池
1,关机,把问题硬盘拔下来,重启,进入NAS,再回去把问题硬盘热插入,系统提示:此硬盘未初始化
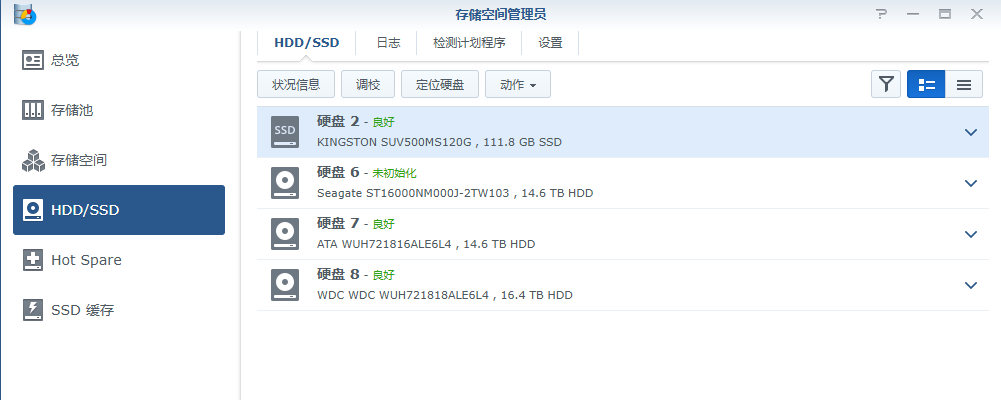
2,建立存储池,根据某人的建议,只建立存储池,不建立存储空间(因为我的数据都在原来的存储空间里,一新建存储空间,这些数据都会被清空)
后来修复了的事实证明,这一步是正确的,也很关键
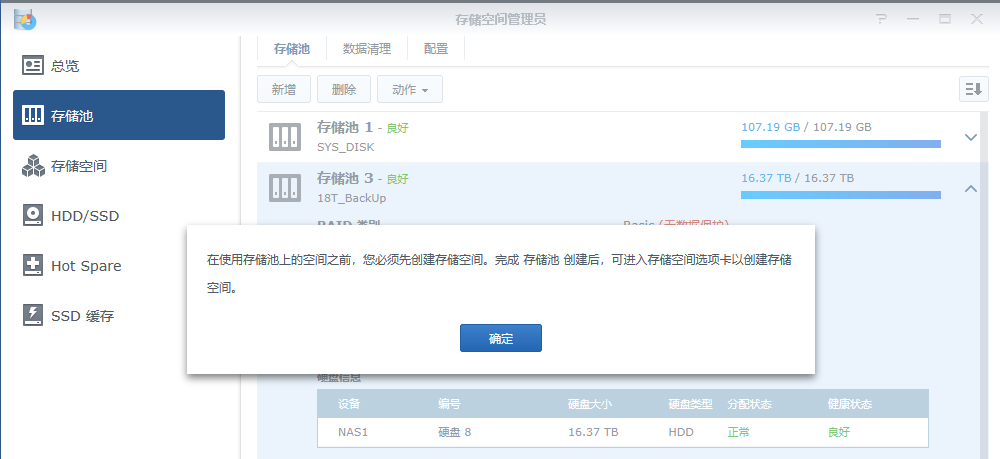
参考文章:https://zhuanlan.zhihu.com/p/659651836
接下来是我做的:运行这个命令:cat /proc/mdstat
root@NAS1:~# cat /proc/mdstat #这个命令是我把问题硬盘拔下后重启NAS登录上来查看的
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]
md4 : active raid1 sdh3[0]
17573506048 blocks super 1.2 [1/1] [U]
md2 : active raid1 sdb3[0]
112398784 blocks super 1.2 [1/1] [U]
md5 : active raid1 sdg3[0]
15621057536 blocks super 1.2 [1/1] [U]
md1 : active raid1 sdb2[0] sdg2[2] sdh2[3]
2097088 blocks [12/3] [U_UU________]
md0 : active raid1 sdb1[0] sdg1[1] sdh1[2]
2490176 blocks [12/3] [UUU_________]
unused devices: <none>
root@NAS1:~# cat /proc/mdstat #这个命令是我把问题硬盘热插上S登录后台看到的,注意,它显示了recovery = 22.9%的进度
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]
md4 : active raid1 sdh3[0]
17573506048 blocks super 1.2 [1/1] [U]
md2 : active raid1 sdb3[0]
112398784 blocks super 1.2 [1/1] [U]
md5 : active raid1 sdg3[0]
15621057536 blocks super 1.2 [1/1] [U]
md1 : active raid1 sdf2[12] sdb2[0] sdg2[2] sdh2[3]
2097088 blocks [12/3] [U_UU________]
[====>................] recovery = 22.9% (480960/2097088) finish=27.9min speed=963K/sec
md0 : active raid1 sdf1[12] sdb1[0] sdg1[1] sdh1[2]
2490176 blocks [12/3] [UUU_________]
[>....................] recovery = 0.1% (3968/2490176) finish=7341.6min speed=5K/sec
unused devices: <none>
等到进度跑完,回到NAS控制台的“存储空间管理员”会看到存储池多了一个:
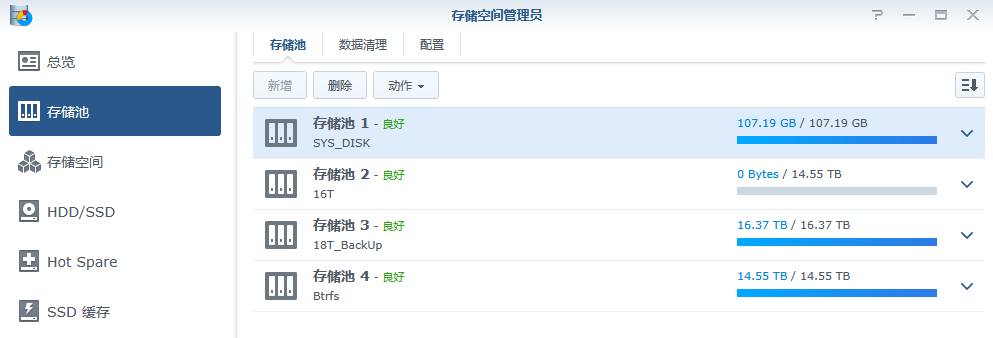
但是存储空间没增加
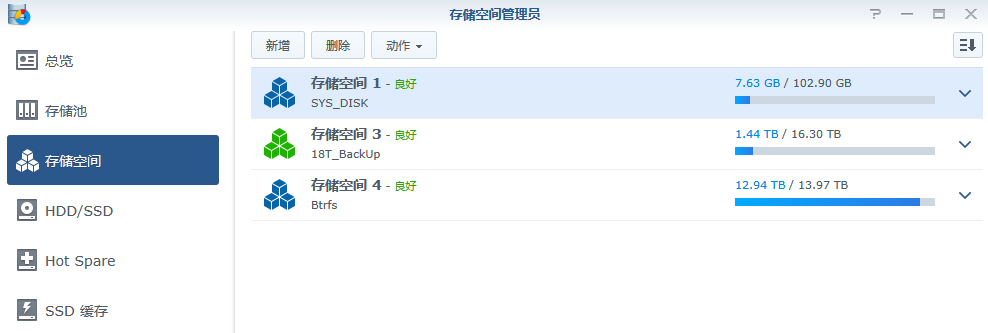
在群晖ssh内使用mdadm创建raid1组
关键步骤:
接下来,要在群晖ssh内使用mdadm创建raid1组
从ssh登录群晖,切换到root账户,然后使用下面的命令在第三分区创建raid1组
我打算这么做:mdadm -Cf /dev/md3 -e1.2 -n1 -l1 /dev/sdf3 -u"bdb92375:30b508b8:14fb5186:bda444cb"
参数解释:
-C: 创建新阵列。
-f: 强制覆盖现有元数据。
-e1.2: 元数据版本(必须与原阵列一致)。
-n1: 单盘 RAID1(临时配置,后续需添加冗余盘)。
-l1: RAID 级别为 1。
root@NAS1:~# mdadm -D /dev/md3 #先找出-e对应的version:1.2和UUID
/dev/md3:
Version : 1.2 # 需要注意这个
Creation Time : Sat Mar 22 02:49:07 2025
Raid Level : raid1
Array Size : 15621057536 (14897.40 GiB 15995.96 GB)
Used Dev Size : 15621057536 (14897.40 GiB 15995.96 GB)
Raid Devices : 1
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Sat Mar 22 02:52:58 2025
State : clean
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name : NAS1:3 (local to host NAS1)
UUID : bdb92375:30b508b8:14fb5186:bda433cb #等下要用这个
Events : 1
Number Major Minor RaidDevice State
0 8 83 0 active sync /dev/sdf3 # 需要注意这个
root@NAS1:~# cat /proc/mdstat #再看一眼当前的硬盘状态
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]
md3 : active raid1 sdf3[0]
15621057536 blocks super 1.2 [1/1] [U]
md4 : active raid1 sdh3[0]
17573506048 blocks super 1.2 [1/1] [U]
md2 : active raid1 sdb3[0]
112398784 blocks super 1.2 [1/1] [U]
md5 : active raid1 sdg3[0]
15621057536 blocks super 1.2 [1/1] [U]
md1 : active raid1 sdf2[1] sdb2[0] sdg2[2] sdh2[3]
2097088 blocks [12/4] [UUUU________]
md0 : active raid1 sdf1[3] sdb1[0] sdg1[1] sdh1[2]
2490176 blocks [12/4] [UUUU________]
unused devices: <none>
root@NAS1:~# mdadm -Sf /dev/md3 # 停止异常的存储池,参数解释:f强制S停止
mdadm: stopped /dev/md3
root@NAS1:~# mdadm -D /dev/md3 # 停止后该池无法查看
mdadm: cannot open /dev/md3: No such file or directory
##最最关键的一步来了
# 创建新的raid设备,参数解释:C创建f强制e元数据格式n磁盘数量l raid等级u uuid,这里的UUID需要变更,不能和上面一致,把上面的复制下来随便改几个数字就行
root@NAS1:~# mdadm -Cf /dev/md3 -e1.2 -n1 -l1 /dev/sdf3 -u"bdb92375:30b508b8:14fb5186:bda444cb" #UUID要变更,不要和上面的一致!我改成了:6da444cb
mdadm: /dev/sdf3 appears to be part of a raid array:
level=raid1 devices=1 ctime=Sat Mar 22 02:49:07 2025
Continue creating array? yes #输入yes继续
mdadm: array /dev/md3 started.
root@NAS1:~# mdadm -D /dev/md3
/dev/md3:
Version : 1.2
Creation Time : Sat Mar 22 10:35:38 2025
Raid Level : raid1
Array Size : 15621057536 (14897.40 GiB 15995.96 GB)
Used Dev Size : 15621057536 (14897.40 GiB 15995.96 GB)
Raid Devices : 1
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Sat Mar 22 10:35:38 2025
State : clean
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name : NAS1:3 (local to host NAS1)
UUID : bdb92375:30b508b8:14fb5186:bda444cb
Events : 1
Number Major Minor RaidDevice State
0 8 83 0 active sync /dev/sdf3
# 重启设备
root@NAS1:~# reboot
重启登录
重启之后,再登录NAS管理界面,先把提示放一边,直接进“”可以看到:
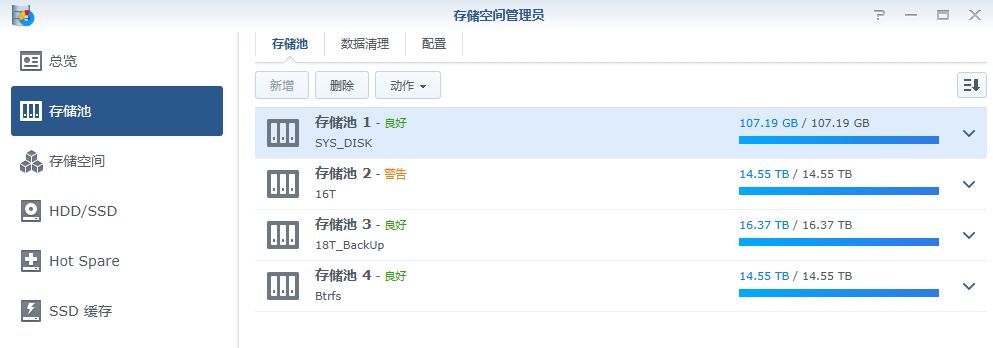
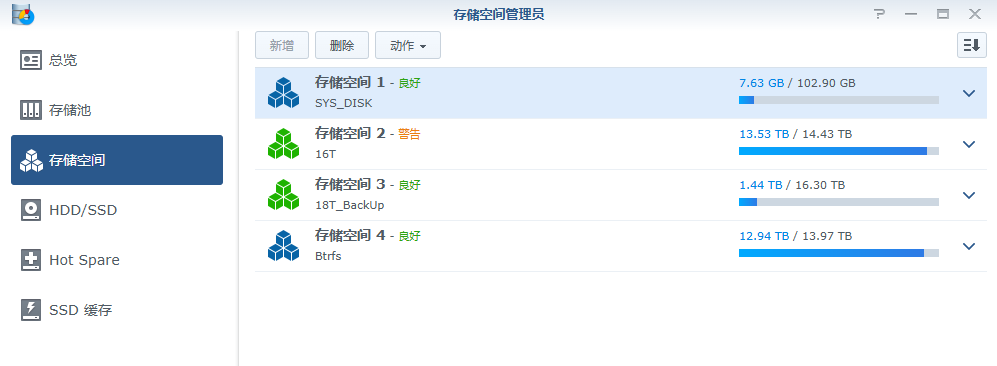
哈哈哈,都回来了
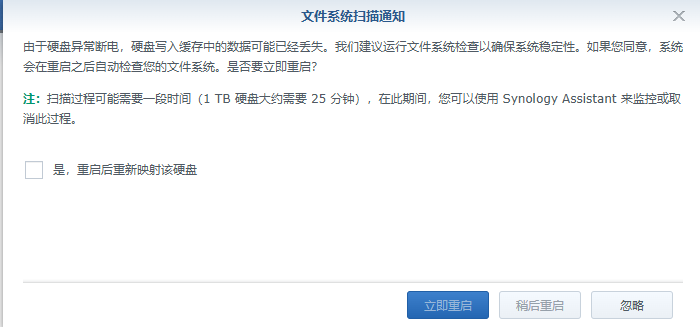
再根据它的提示,重启一下
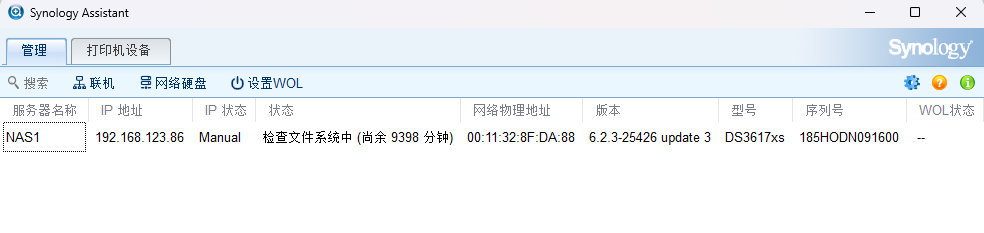
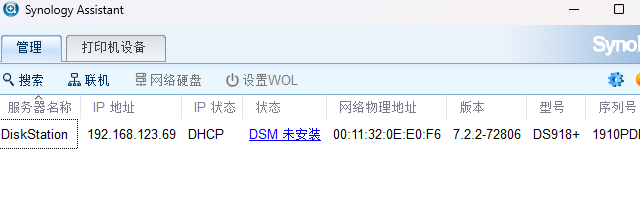
然后可以用Synology Assistant监控整个进度:
下面几个步骤我还没做。。。等重启完成再看吧
4,ubuntu中扫描重组raid组
记得此时要使用synopoweroff或者从web网管来关闭群晖,防止硬盘又变为损毁状态,再把硬盘插回到ubuntu系统中
mdadm --assemble --scan --verbose
上面的扫描重组命令执行完成后,理论上在/proc/mdstat内就能看到active状态的raid组了,使用mount挂载raid组就可以读取数据了
5,启动所有停止的套件
登录群晖面板,如果发现此时存储池由损毁变成只读,需要手动转换
root@DiskStation:~# synopkg list --name | xargs -I"{}" synopkg start "{}"
总结
此方法可通过重建 RAID 元数据修复逻辑层损坏,但需确保:
- 硬盘物理健康(SMART 正常)。
- 严格匹配元数据版本和分区位置(如 sdi3 对应原 sdf3)。
- 操作后添加冗余盘并监控同步状态。
- 若仍有疑虑或数据敏感,建议联系专业数据恢复服务。
注意事项
硬盘设备名可能变化:
DSM 重启后硬盘的 /dev/sdX 名称可能改变,操作前务必通过 fdisk -lu 确认。
元数据版本必须匹配:
若 -e 参数与原 RAID 版本不一致(如误用 1.0 代替 1.2),可能导致数据无法识别。
数据完整性验证:重建后运行文件系统检查(我没用这一步,这是DS建议的):
fsck -y /dev/md3 # ext4
btrfs check /dev/md3 # Btrfs
DS建议的创建新 RAID 设备方法(关键步骤)
(这方法看起来也没问题,只不过我是读取旧的UUID,然后手工改了几位)
# 生成新 UUID(在原 UUID 基础上修改末几位)
OLD_UUID="ff662d18:02f09dee:653614a3:d422f366"
NEW_UUID="${OLD_UUID%:*}:$(openssl rand -hex 4 | sed 's/../&/g')" # 示例生成新 UUID
# 创建新 RAID 设备(保持元数据版本和硬盘分区一致)
mdadm -Cf /dev/md3 -e1.2 -n1 -l1 /dev/sdf3 -u"$NEW_UUID"
参数解释:
-C: 创建新阵列。
-f: 强制覆盖现有元数据。
-e1.2: 与原 RAID 元数据版本一致。
-n1: 单盘 RAID1(后续需添加冗余盘)。
-l1: RAID 级别为 1。
-u: 新 UUID(避免与原配置冲突)。
遇到新问题
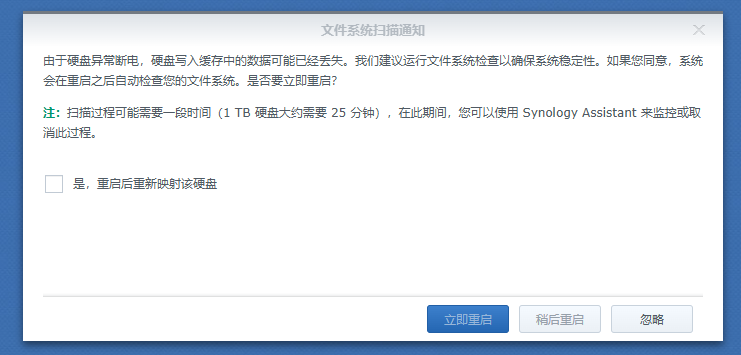
我的黑裙上有3个盘,volume1是SSD,启动盘,128G,volume2 16G (homes和NAS的插件都安在这里), volume3 18G, 前两天volume2提示空间不足,我就买个新的16G,作为volume4。但还没启用,volume2就提示损毁。于是一番救治,终于找了回来。但是现在一开机,系统就提示我:文件系统扫描通知。我已经选YES重启过4次了,但是还是有这个提示。
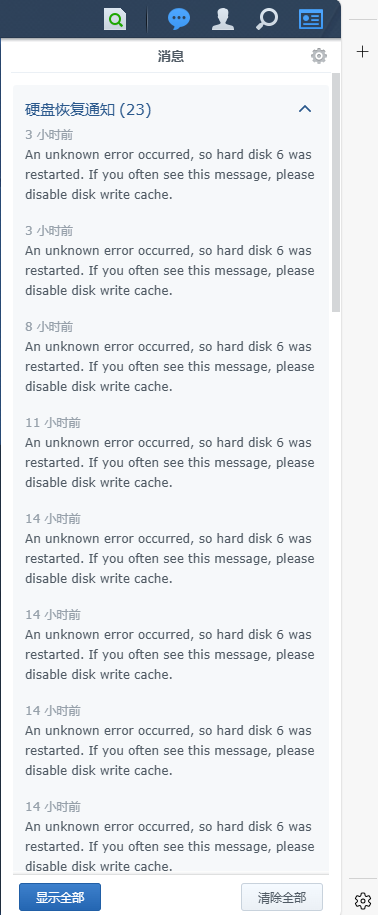
消息上是这么说的,让我disable disk write cache,我查了一下,远程登录,执行这个命令:sudo hdparm -W0 /dev/sdg
root@NAS1:~# sudo fdisk -l | grep "Disk /dev/sd"
GPT PMBR size mismatch (102399 != 61439999) will be corrected by w(rite).
Disk /dev/sdb: 111.8 GiB, 120034123776 bytes, 234441648 sectors
Disk /dev/sdf: 14.6 TiB, 16000900661248 bytes, 31251759104 sectors
Disk /dev/sdg: 14.6 TiB, 16000900661248 bytes, 31251759104 sectors
Disk /dev/sdh: 16.4 TiB, 18000207937536 bytes, 35156656128 sectors
root@NAS1:~# sudo hdparm -W /dev/sdg
/dev/sdg:
write-caching = 1 (on)
root@NAS1:~# sudo hdparm -W /dev/sdf
/dev/sdf:
write-caching = 1 (on)
root@NAS1:~# sudo hdparm -W0 /dev/sdg
/dev/sdg:
setting drive write-caching to 0 (off)
write-caching = 0 (off)
不知道等一会儿它还会不会继续提示我硬盘6重启
另外一种方法关闭硬盘缓存:
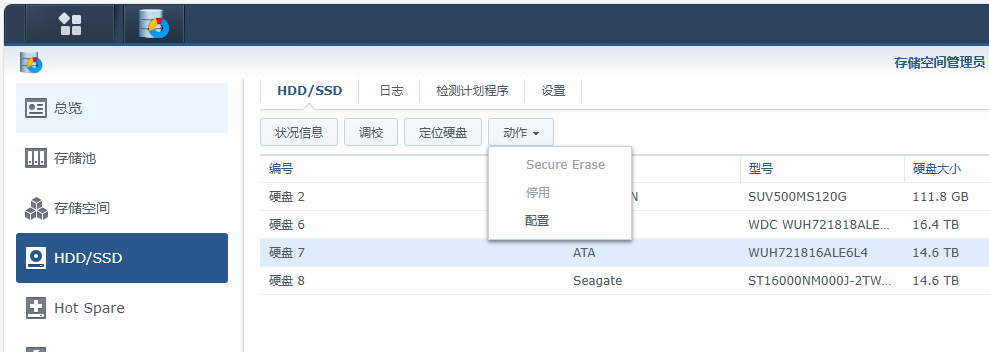
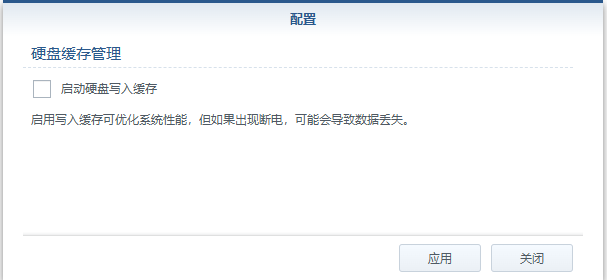
官方指引:
https://kb.synology.cn/zh-cn/DSM/tutorial/Frequently_asked_questions_about_Storage_Manager
https://kb.synology.cn/zh-cn/DSM/tutorial/How_can_I_recover_data_from_my_DiskStation_using_a_PC
终级大法:重装NAS系统
文档参考:https://www.ypojie.com/12010.html
群晖官网 https://www.synology.cn/zh-cn/support/download/DS920+
直接用RR的IMG
太方便了:https://github.com/RROrg/rr/releases/tag/25.3.3
直接烧好的U盘内容:
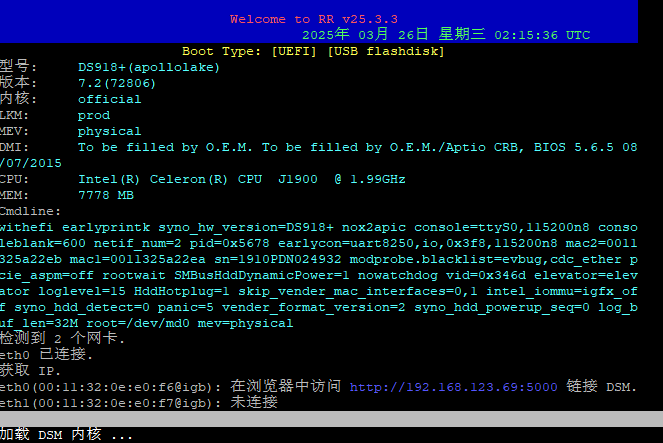
启动:menu.sh后的主菜单:
先升级一下:
退回升级model:
一路继续:
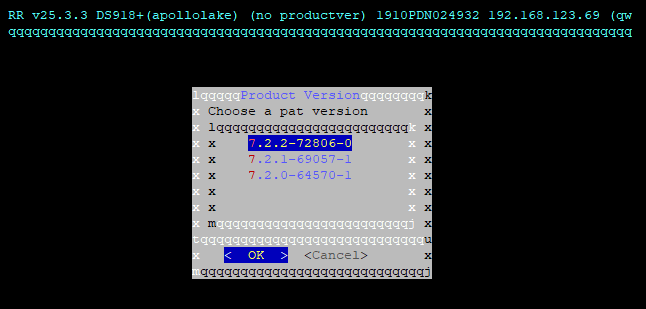
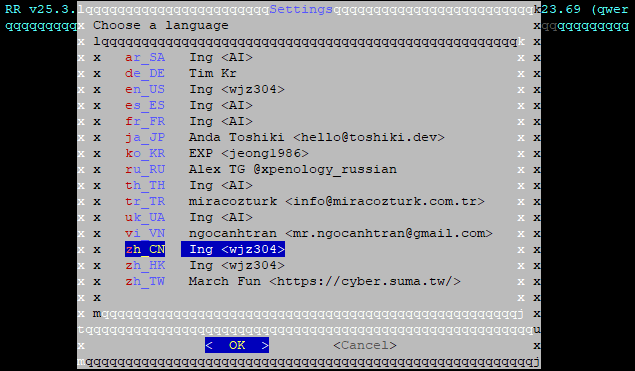
当然也可以在setting menu里设置语言为中文:
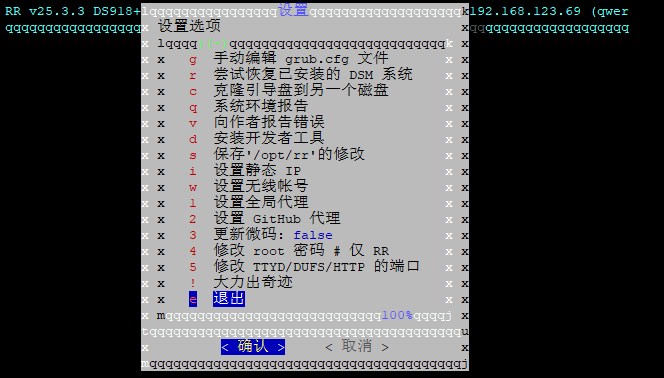
编译引导:
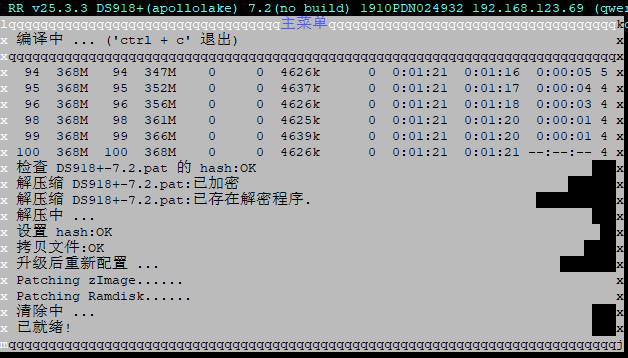
我用前面的那个就下载不了PAT了,因为连不上,这次用RR的版本引导,它可以用镜像,加速完成!怒赞!!!
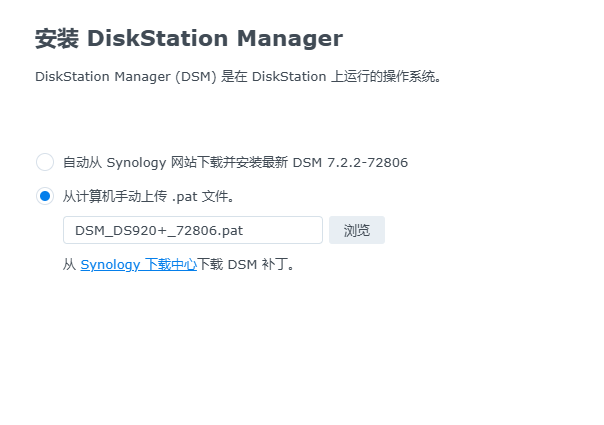
然后就进入了安装主页:

然后定位到本地硬盘上下载好的文件,开始安装:
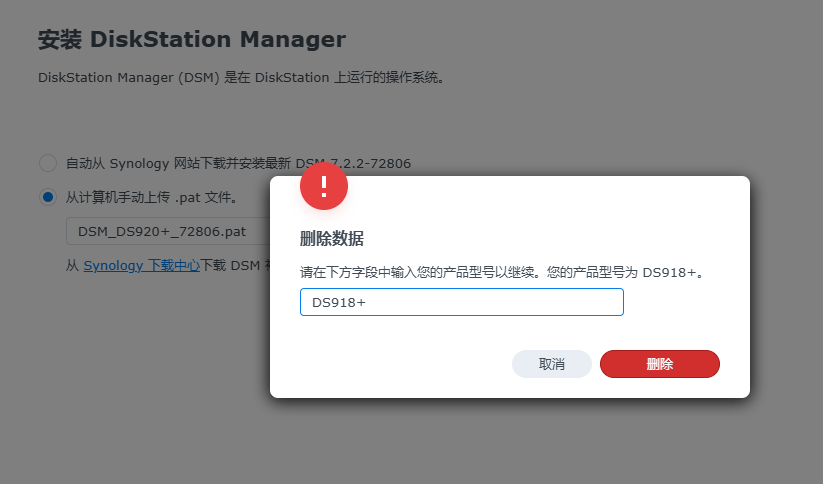
哈哈哈 哈
本来想还原,但我一看内容,我好像都没有

不知道这个版本能不能自动更新,保险起见,先选手动吧

synology账户?我先跳过吧
重装后的大问题
套件一个都打不开
查看了一下已安装折套件,发现QuickConnect赫然在列,难道是因为它?把我给封了?
我明明记得刚刚安装完DSM的时候,我的套件都是能打开的,可过了没多久,就一个都打不开了
但在套件页面,QuickConnect只有运行,没有卸载的按钮
于是我只能进入后台操作了:
root@NAS1:/var/packages/QuickConnect# ps -ef | grep quick #把带quick的进程都列一下
root 17842 16126 0 01:00 pts/0 00:00:00 grep --color=auto quick
root@NAS1:/var/packages/QuickConnect# ls
conf enabled etc home INFO scripts share target tmp var
root@NAS1:/var/packages/QuickConnect# sudo synopkg uninstall QuickConnect #这次好像没成功
{"action":"prepare","error":{"code":268,"deppkg":"SupportService","description":"failed to uninstall a package who has dependers installed"},"stage":"prepare","success":false}
root@NAS1:/var/packages/QuickConnect# sudo synopkg uninstall quickconnect #这次好像成功了
{"action":"prepare","error":{"code":0},"stage":"prepare","success":true}
root@NAS1:/var/packages/QuickConnect# ls
conf enabled etc home INFO scripts share target tmp var
root@NAS1:/var/packages/QuickConnect# cd ..
root@NAS1:/var/packages# rm -r QuickConnect #一不做二不休,直接删除目录
root@NAS1:/var/packages# ls
ActiveInsight Node.js_v18 Python2 StorageManager SynologyDrive
cpolar Node.js_v20 ScsiTarget SupportService SynoOnlinePack_v2
FileStation OAuthService SecureSignIn SynoFinder UniversalViewer
HybridShare PHP8.2 SMBService SynologyApplicationService
再一看,目录下面没有了,套件那里QuickConnect也找不到了,于是reboot看看
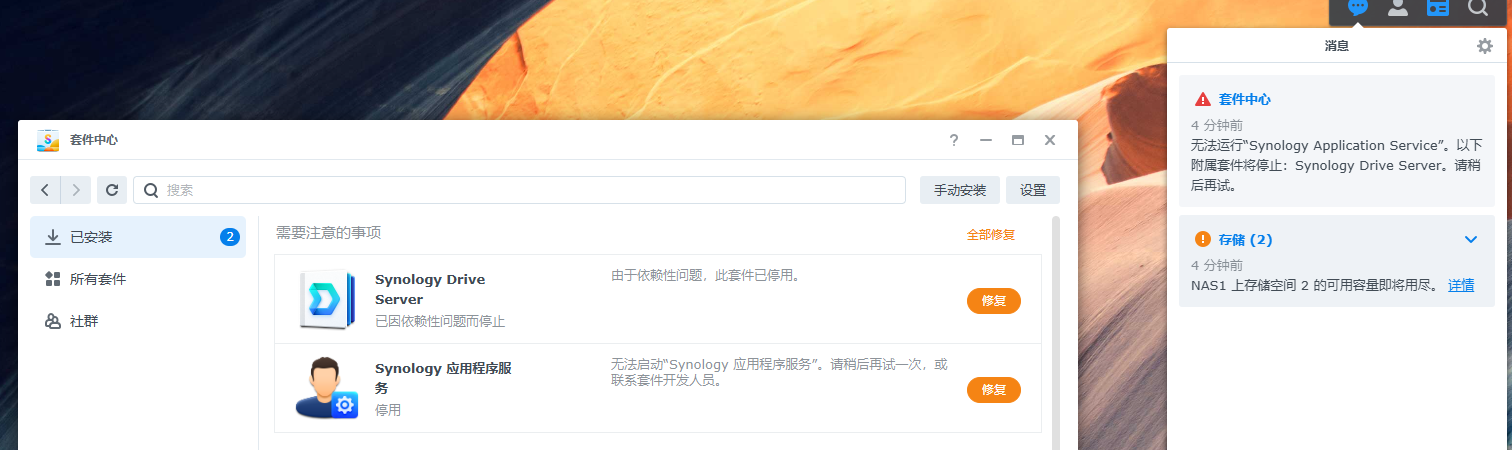
刚回来就发现这两个套件用不了了,难道,这个QC是我当初安装这两个套件的时候自动安上的?难不成我现在得重装系统?
过了个把月,这个盘时不时停电,读写也常有i/o错误,我一怒之下,想把它格了,从ext4格式,改为brfts格式:
用这个套件可以用来移动已安装的套件(比如:从volume1移动到volume2)
https://zhuanlan.zhihu.com/p/709709205
https://github.com/007revad/Synology_app_mover/releases

 浙公网安备 33010602011771号
浙公网安备 33010602011771号