『笔记』PointAugmenting
『笔记』PointAugmenting
一个point-level fusion的方法,主要有两个点:1. 使用camera feature paint点云,但经过voxel encoding后的3d conv是对于lidar的feature和cat过来的camera feature分别进行的,然后在2d bev后再cat,2. 设计了gt-paste的升级版,对于lidar,采取near-to-far的方式不断过滤点,使得场景合理(原gt-paste的方式为规定不能collision),以及对于camera,采取far-to-near的方式paste图像patch
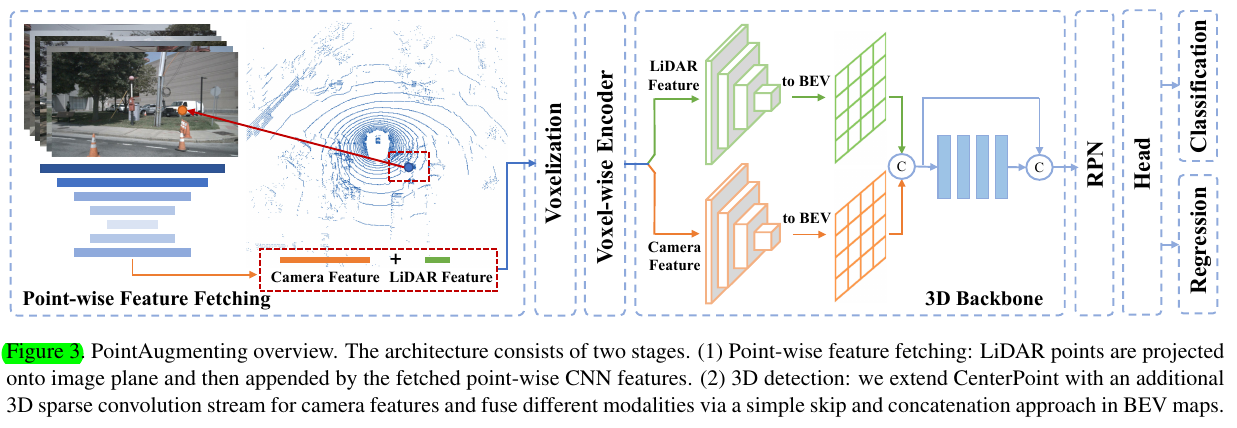
3. PointAugmenting
3.1. Cross-Modal Fusion
High dimensional CNN features perform better than segmentation scores. To extract the point-wise image features, we use an off-the-shelf network trained for 2D object detection rather than semantic segmentation.
Con- sidering the modality gap and different data characteristics between LiDAR and cameras, unlike point-wise concatena- tion used by PointPainting, we employ a late fusion mech- anism across modalities. After the voxel-wise feature encoder, we use two separate 3D sparse convolution branches to process the LiDAR and camera fea- tures
3.2. Cross-Modal Data Augmentation
We attempt to simultaneously attach an image patch to images when pasting LiDAR points of a virtual object into current 3D scene. The main challenge lies in the preservation of the consistency between camera and LiDAR data. To address this issue, we identify the occlusion relationships between foreground objects and filter those occluded LiDAR points from the observer's per- spective.
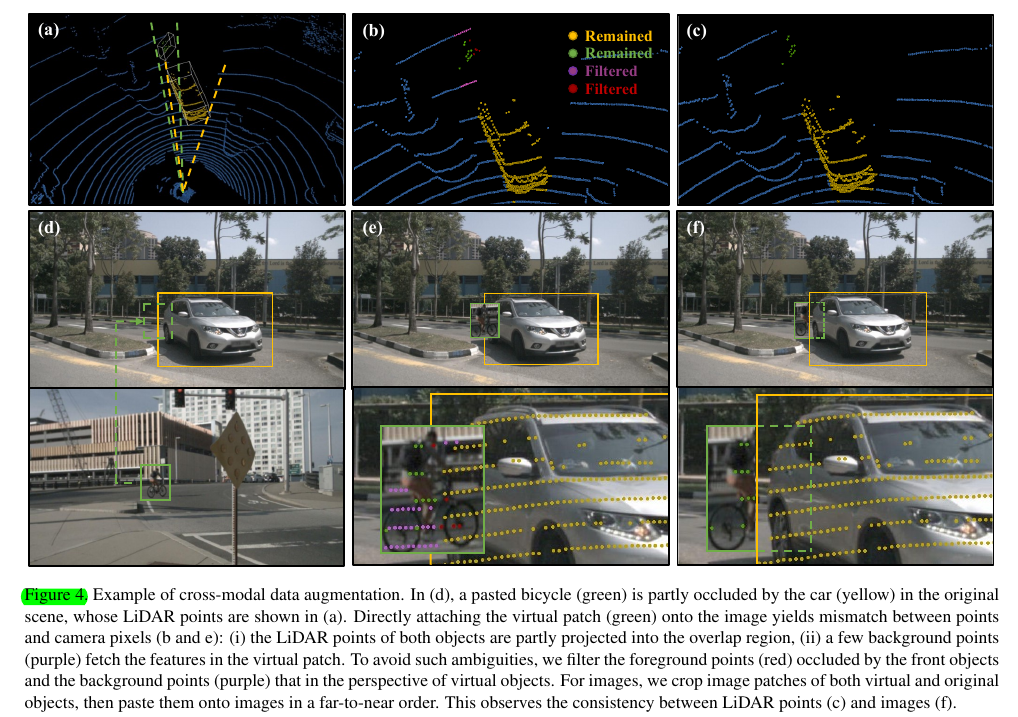
Augmentation for LiDAR Points.
我们将 LiDAR 点 (x, y, z) 转换为 LiDAR 球面坐标系为 (r, θ, φ) 并使用 θ 和 φ 的范围表示对象的透视图,其中最小值和最大值θ 和 φ 的值是从其真实框的八个角获得的。在选择虚拟对象时,原 GT-Paste 要求避免对象的碰撞。我们的方法还限制了对象之间的透视重叠,以免过滤过多的前景点。然后将选定的虚拟对象粘贴到当前场景中,我们从观察者的角度过滤遮挡点。具体来说,给定当前场景中的原始和粘贴的虚拟对象,我们以从近到远的顺序处理每个对象。如果取一个原始对象,我们只丢弃那些属于更远粘贴对象的遮挡点。如果处理了一个粘贴的对象,所有比这个对象更远的被遮挡点都将被处理掉。因为原始对象只遮挡了远处的虚拟对象,而粘贴的虚拟对象遮挡了所有远处的对象以及背景点。
Augmentation for Camera Images.
为了匹配 LiDAR 和摄像头之间的一致性,对于粘贴到 LiDAR 场景中的每个虚拟对象,我们将其对应的补丁在 2D 边界框内附加到图像上。 2D 边界框是从 3D 真实投影中获得的。为了确定粘贴的位置,我们注意到虽然虚拟点被粘贴在 LiDAR 场景中的原始位置,但由于相机外部参数的抖动,虚拟斑块并不完全位于相机平面的原始位置。我们需要通过当前相机外部校准重新计算2D边界框的位置,然后通过平移和缩放来变换原始补丁。此外,我们不是直接粘贴虚拟补丁,而是抓住虚拟和原始对象的补丁,并以远到近的顺序粘贴它们。这样,根据激光雷达场景中对象之间的遮挡关系,背景对象被图像中的前景对象遮挡。
Fade Strategy.
尽管性能提升很大,但数据增强违反了真实数据分布,特别是对于我们跨 LiDAR 点和相机图像的数据。 为此,我们在模型接近收敛时禁用数据增强,从而使我们的模型从真实场景中学习。 该策略在 1/8 nuScenes 数据集上进一步提高了 +1.3% 的 mAP(参见表 5)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号