『笔记』BEVDet
『笔记』BEVDet
2021年开始做BEV检测相对比较早的的一篇,使用LSS方法,做纯视觉的multi-view images的三维目标检测。在这里做一个简单记录
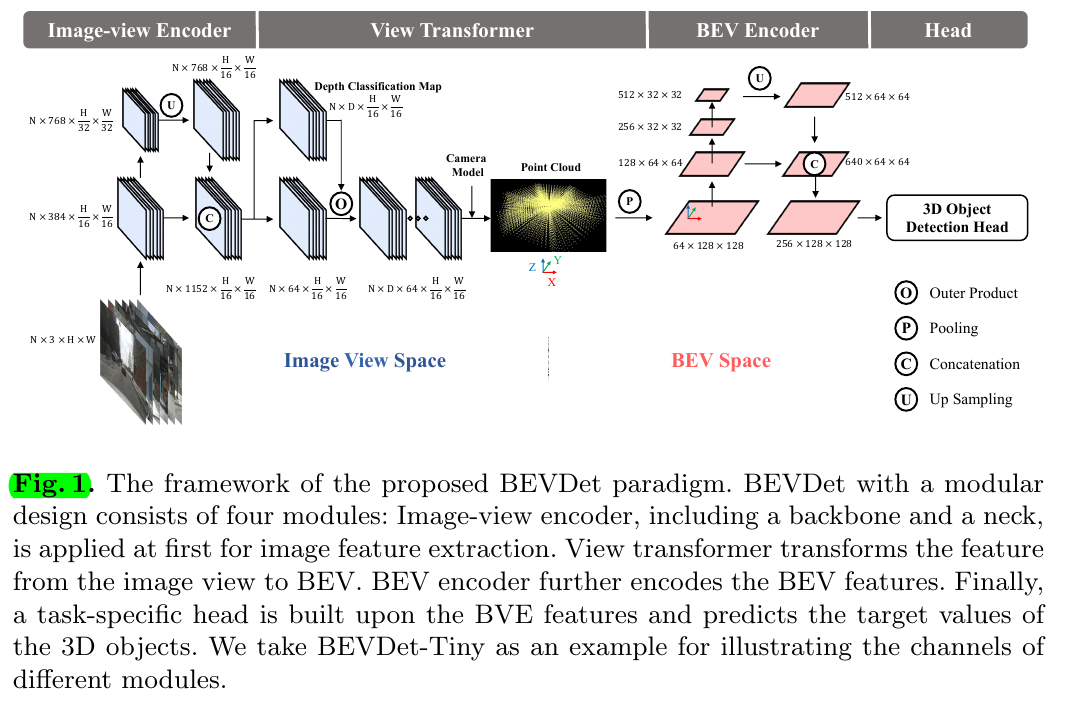
3 Methodology
3.1 Network Structure
Image-view Encoder By default, we use the classical ResNet [14] and the up-to-date attention-based SwinTransformer. We use the classical FPN [22] and the neck structure proposed in [LSS], which is named FPN-LSS in the following. FPN-LSS simply upsamples the feature with 1/32 input resolution to 1/16 input resolution and concatenates it with the one generated by the backbone.
View Transformer We apply the view transformer proposed in [LSS] to construct the BEVDet prototype. The adopted view transformer takes the image-view feature as input and densely predicts the depth through a classification manner. Then, the classification scores and the derived image-view feature are used in rendering the predefined point cloud
BEV Encoder We follow [LSS] to utilize ResNet [14] with classical residual block to construct the backbone and combine the features with different resolutions by applying FPN-LSS. Though the structure is similar to that of the image-view encoder with a backbone and a neck, it perceives some pivotal cues with high precision like scale, orientation, and velocity, as they are defined in the BEV space
Head We directly adopt the 3D object detection head in the first stage of CenterPoint
3.2 The Customized Data Augmentation Strategy
Specifically, given a pixel in

3.3 Scale-NMS
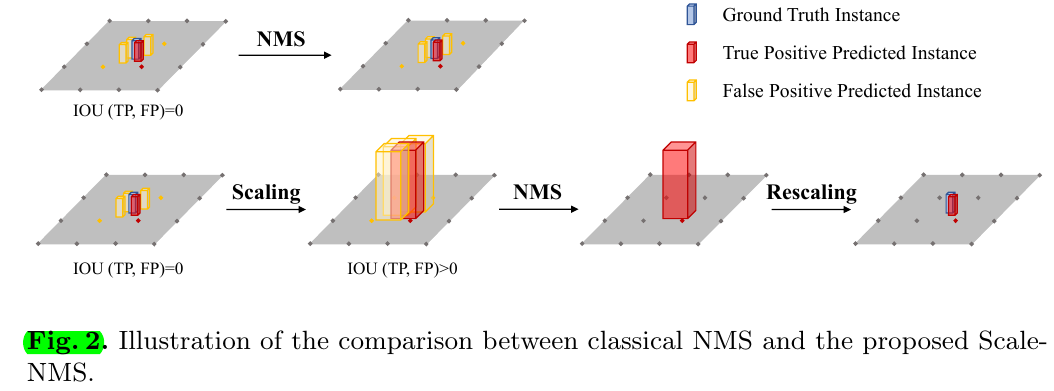
In the BEV space, the occupied areas of various classes are intrinsically different and the overlap between instances should be closed to zero. For example, as illustrated in Fig. 2, objects like pedestrians and traffic cones occupy a small area in the ground plane, which is always smaller than the out- put resolution of the algorithm (e.g., 0.8 meters in CenterPoint [56]). Scale-NMS scales up the size of each object according to its category before performing the classical NMS algorithm. In practice, we apply Scale-NMS to all categories except for the barrier as its size is various. The scaling factors are category-specific.
个人总结:非常初始朴素的LSS流派做bev目标检测的工作。两个额外的细节就是1. 在LSS的时候注意做image augmentation的处理,用inverse augmentation保持spatial consistency. 当然了,肯定要做的 2. scale-nms. 作者认为bev上做检测时,不同于图像上,大家在perspective view下的大小还是比较一致的,但是bev下小物体特别小,可能会比voxelization时的resolution还要小,在原始预测情况下其实都是围绕着一个位置出现的预测但并不会产生多大的iou,所以先scale up一下再做nms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号