『笔记』DETR3D
『笔记』DETR3D
CORL2021的一篇文章,使用DETR的检测范式来直接做multi-view images的三维目标检测
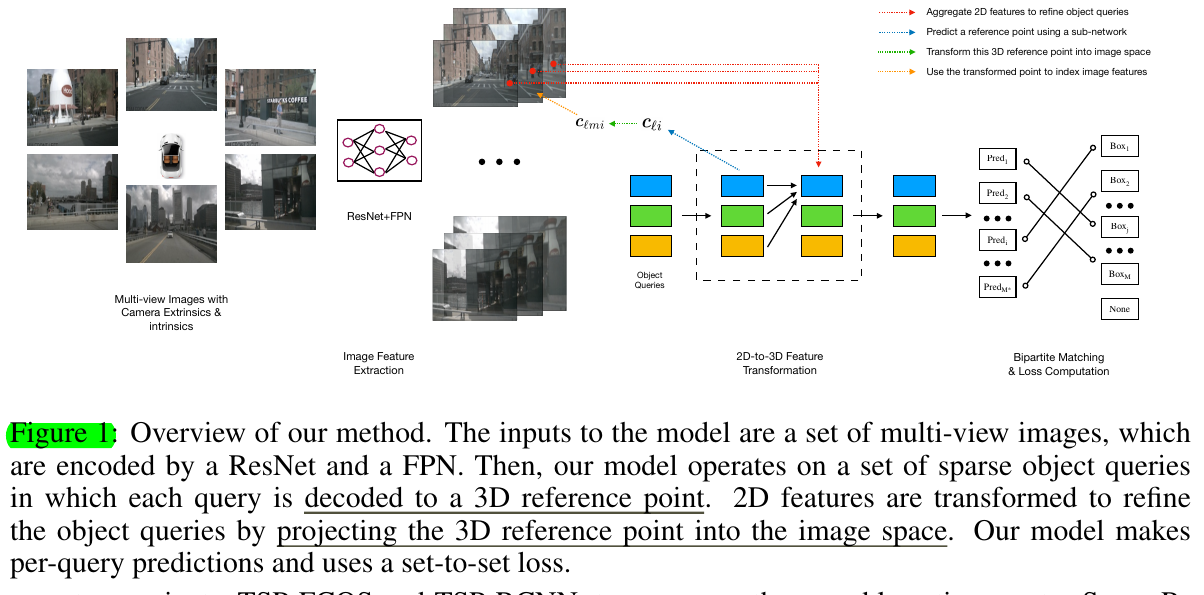
3 Multi-view 3D Object Detection


大部分还是很清楚的,符号和公式也比较多,便于理解。不过,非常让我不解的就是文章里的公式(4),将当前object query和这个feature相加,就成了下一层的query?直接甭学了,transformer跑哪去了,什么东西。说句实话,包括文章里给的Figure 1,都做的让人很难get到。于是结合作者之一在知乎的文章BEV下的纯视觉目标检测-DETR3D做一下总结吧

个人理解:其实主要idea其实就是,设置object queries,通过一个mlp映射这个object queries所对应的3d位置,即3d reference point,做投影,得到2d pixel位置,结合bilinear interpolation索出multi-view image feature maps上的features(所有有效视图上的features average到了一起),于是我们就准备好了该object query对应的图像特征。将该feature和3d reference point的PE都加到object query上,然后object queries之间做attention,个人觉得这个attention既可以说是queries之间的self-attention,又可以说是不同features之间的cross-attention. 每个decoder层结束后,像DETR一样都是每个层后都有head来输出结果,用这个结果又可以去预测delta去调整reference point,进而进行下一层。其实个人感觉bev的概念在这篇文章中并没有那么强烈,倒是也可以,可以说是体现在3d refernce point到2d pixel的这个关系中

很明显,loss设计这块是遵循DETR检测范式的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号