『笔记』CenterPoint
『笔记』CenterPoint
CenterPoint也算是鼎鼎有名了,但是感觉论文的方法那里写得实在是敷衍,可能确实主要是用了一下CenterNet的head思路,没什么好说的吧。
4. CenterPoint
The first stage of CenterPoint predicts a class-specific heatmap, object size, a sub-voxel location refinement, rotation, and velocity.
Center heatmap head. This head produces a K-channel heatmap \(\hat{Y}\) , one channel for each of \(K\) classes. During training, it targets a 2D Gaussian produced by the projection of 3D centers of annotated bounding boxes into the map-view.
直接把CenterNet中相关部分拿过来放在这里:


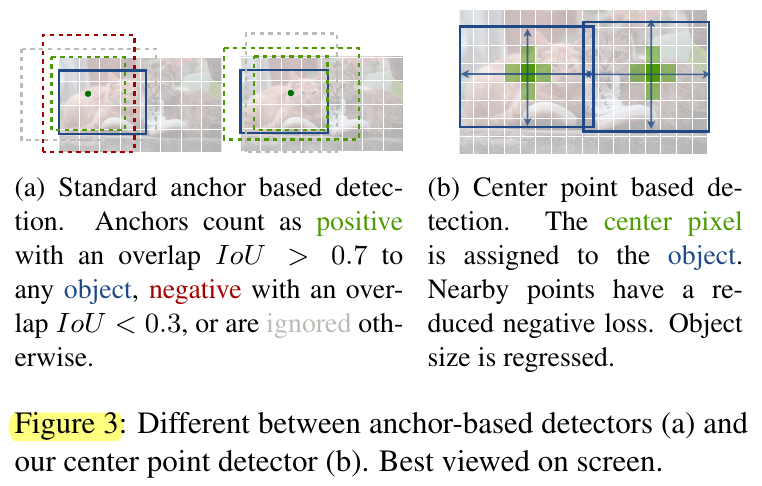
总得来说,思路简单得不行。分类heatmap是一个值都在0到1之间的类别C个channels的map,可以想象就是个千层饼,每一层表示对该类在这个map上的分布预测情况。target制作根据实际gt中心位置,用gaussian distribution的密度函数来画,方差也就是半径大小根据实际这个object box的尺寸而定。计算loss使用pixel-wise的focal loss,也就是说每个channel层每个值都是一个类binary CE(by类,I mean标签不是纯0或1,按照1或0分的两个讨论,即那个\(p_t\),而是1或其他值). 另外,CenterPoint这里就是简单的纯focal loss了,而可以看到CenterNet的损失函数那里,除了常规的focal loss,也就是预测地太好的不给参与loss,平衡easy-hard,对于非1的情况还加了一个weight项,可以看出是把真正的center附近的值的loss降低了,intuitively来感受也就是说,虽然这些既然不是exactly的那个center位置,其实算是“负”样本,但是能预测到这里也不错了,别加太大loss. 有点相当于平衡了下positive-negative
另外,方差的那个值的确定是object size-adaptive,还以为有什么公式,CenterNet继续导向了其基于的CornerNet,所以去CornerNet那里找了一下,是这样的:
We determine the radius by the size of an object by ensuring that a pair of points within the radius would generate a bounding box with at least t IoU with the ground-truth annotation (we set t to 0.3 in all experiments). [...] σ is 1/3 of the radius.
然后,相比纯2D时候CenterNet的implementation,在CenterPoint这里具体来说稍微有点不同的就是:Objects in a top-down map view are sparser than in an image. We increase the positive supervision for the target heatmap \(Y\) by enlarging the Gaussian peak rendered at each ground truth object center. We set the Gaussian radius to \(σ = \max(f (wl), τ )\), where \(τ = 2\) is the smallest allowable Gaussian radius, and \(f\) is a radius function defined in CornerNet [29]
另外,该图取自CenterNet,画得不错,解释这个ground truth方式:
Regression heads. object size \(s \in \mathbb{R}^3\), a sub-voxel location refinement \(o \in \mathbb{R}^2\), height-above-ground \(h_g \in \mathbb{R}^1\), rotation \((\sin(\alpha),\cos(\alpha)) \in \mathbb{R}^2\)
所以值得注意的是,所有class都是share这些regression值的
Velocity head and tracking. Predict a two-dimensional velocity estimation \(v \in \mathbb{R}^2\)
4.1. Two-Stage CenterPoint
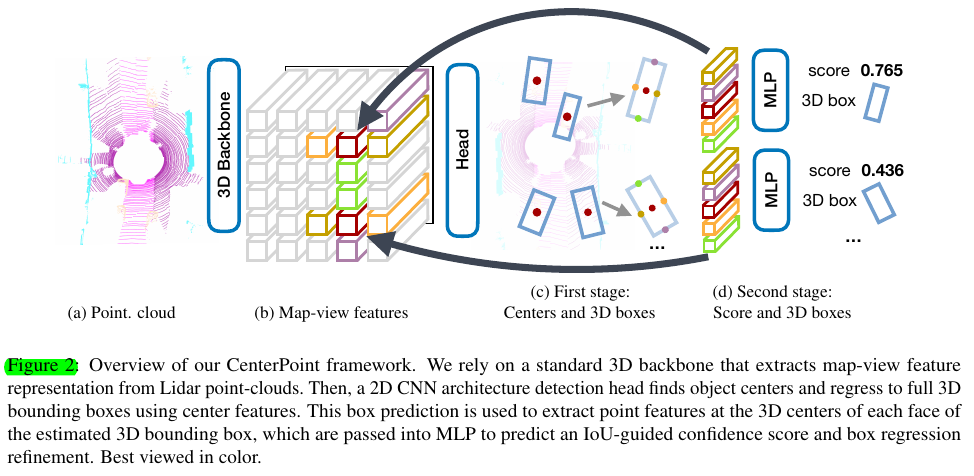
作者还为CenterPoint设计了two stage的方案做refinement. 动机来自于:in autonomous driving, the sensor often only sees the side of the object, but not its center.
We extract one point-feature from the 3D center of each face of the predicted bounding box. Note that the bounding box center, top and bottom face centers all project to the same point in map-view. We thus only consider the four outward-facing box-faces together with the predicted object center. For each point, we extract a feature using bilinear interpolation from the backbone map-view output M. Next, we concatenate the extracted point-features and pass them through an MLP.
可以看到,以two stage方法的角度来看这个环节,也算是个比较硬的索features的方式了。后面head的class-agnostic confidence score prediction和loss和PV-RCNN那里经典的方式保持一致(利用IoU制作target,binary CE计算loss),然后,如果测试时候,这个prediction box的score会由第一阶段heatmap那个值和这里第二阶段的confidence head一起相乘开平方得到最终值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号