『笔记』CBGS
『笔记』CBGS
1. Introduction
Finally, our contributions in this challenge can be concluded as follows:
• We propose class-balanced sampling strategy to handle extreme imbalance issue in the nuScenes Dataset.
• We design a multi-group head network to make categories of similar shapes or sizes could benefit from each other, and categories of different shapes or sizes stop interfere with each other.
• Together with improvements on network architecture, loss function, and training procedure, our method achieves state-of-the-art performance on the challenging nuScenes Dataset [2].
2. Methodology
2.1. Input and Augmentation
Class-balanced sampling
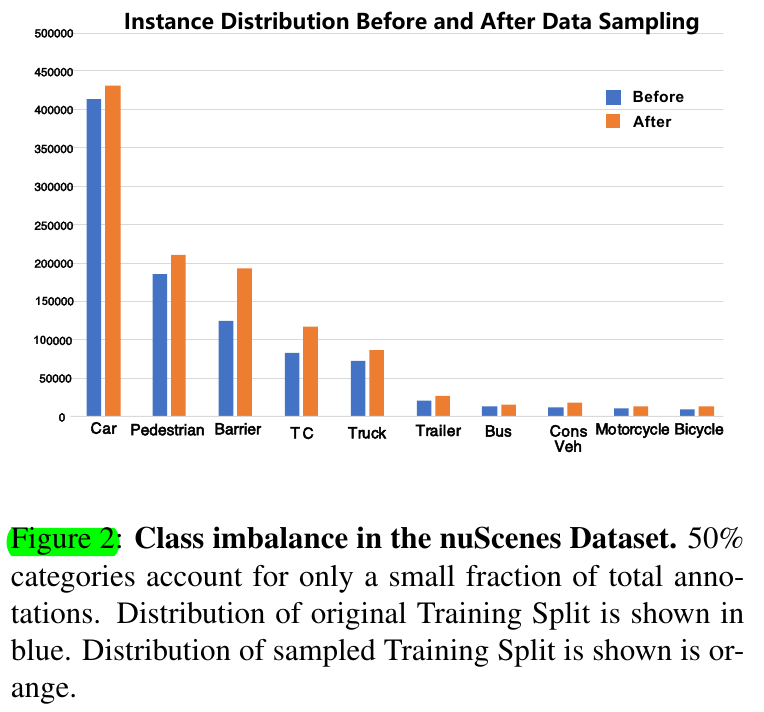
To alleviate the severe class imbalance, we propose DS Sampling, which generates a smoother instance distribution as the orange columns indicate. To this end, like the sampling strategy used in the image classification task, we firstly duplicate samples of a category according to its fraction of all samples. The fewer a category's samples are, more samples of this category are duplicated to form the final training dataset.
More specifically, we first count total point cloud sample number that exists a specific category in the training split. Samples of all categories are summed up to 128106 samples. Note that there exist duplicates because multiple objects of different categories can appear in one point cloud sam- ple. Intuitively, to achieve a class-balanced dataset, all categories should have close proportions in the training split. So we randomly sample 10% of 128106 (12810) point cloud samples for each category from the class-specific samples mentioned above. As a result, we expand the training set from 28130 samples to 128100 samples, which is about 4.5 times larger than the original dataset.
个人觉得作者说得真的很不清楚。总得来说,其方式为,首先统计好所有包含每个类的samples们,然后以这个数量的10%来randomly取每个类的samples放入training set. 也就是说,idea是认为只要一个sample里有这个类的object,就认为这个sample对于提高这个类的比例是有用的,所以只要包含,就有可能作为代表被加入该类的那10%. 自然,这个sample中也有可能包含其它的类,尤其是car这种大类,不过我不管,只要包含,它就贡献这个小类。
To conclude, DS Sampling can be seen as improving the average density of rare classes in the training split. Apparently, DS Sampling could alleviate the imbalance problem effectively, as shown in orange columns in Figure 2.
Ground-truth sampling
Besides, we use GT-AUG strategy as proposed in SECOND [28] to sample ground truths from an annotation database, which is generated offline, and place those sampled boxes into another point cloud. Note that the ground plane location of point cloud sample needs to be computed before we could place object boxes properly. So we utilize the least square method and RANSAC [6] to estimate each sample's ground plane, which can be formulated as \(Ax + By + Cz + D = 0\)
2.3. Class-balanced Grouping
Car accounts for 43.7% annotations of the whole dataset, which is 40 times the number of bicycle, making it difficult for a model to learn features of tail classes sufficiently. If instance numbers of classes sharing a common head, the corresponding head will be dominated by the major classes, resulting in poor performance on rare classes.
-
Classes of similar shapes or sizes should be grouped.
-
Instance numbers of different groups should be bal- anced properly. We separate major classes from groups of similar shape or size. For example, Car, Truck and Construction Vehicle have similar shape and size, but Car will dominate the group if we put the 3 classes together, so we take Car as a single group.
In the final settings we split 10 classes into 6 groups: (Car), (Truck, Construc- tion Vehicle), (Bus, Trailer), (Barrier), (Motorcycle, Bicy- cle), (Pedestrian, Traffic Cone).
思路同样很简单除了data preparation时使用的class-balanced sampling,在detection head的时候有了第二个设计就是分group的head,其中group的划分按照了两点:1. 相似size和shape的放在一组 2. 类别样本数量过多的单独一组,不然会overwhelm掉同组其他小类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号