『论文』SSD
『论文』SSD
The Single Shot Detector (SSD; Liu et al, 2016) is one of the first attempts at using convolutional neural network’s pyramidal feature hierarchy for efficient detection of objects of various sizes.
Image Pyramid
SSD uses the VGG-16 model pre-trained on ImageNet as its base model for extracting useful image features. On top of VGG16, SSD adds several conv feature layers of decreasing sizes. They can be seen as a pyramid representation of images at different scales. Intuitively large fine-grained feature maps at earlier levels are good at capturing small objects and small coarse-grained feature maps can detect large objects well. In SSD, the detection happens in every pyramidal layer, targeting at objects of various sizes.
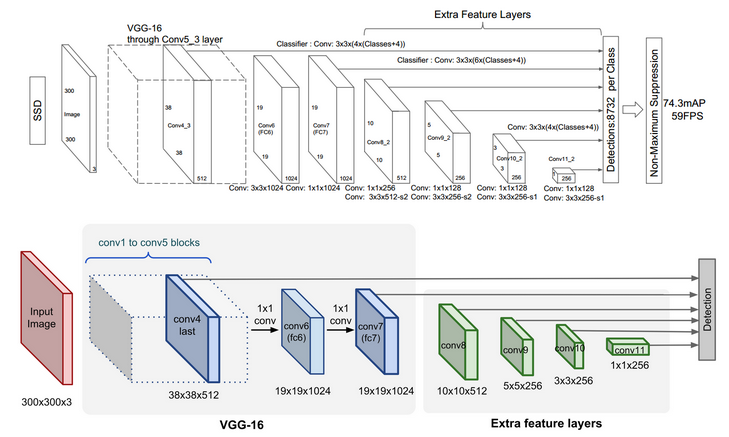
- SSD300中default box的数量:(38*38*4 + 19*19*6 + 10106 + 5*5*6 + 3*3*4 + 1*1*4)= 8732。也就是一趟prediction最后那个地方输出来的就是8732个box
Workflow
Unlike YOLO, SSD does not split the image into grids of arbitrary size but predicts offset of predefined anchor boxes (this is called “default boxes” in the paper) for every location of the feature map. Each box has a fixed size and position relative to its corresponding cell. All the anchor boxes tile the whole feature map in a convolutional manner.
Feature maps at different levels have different receptive field sizes. The anchor boxes on different levels are rescaled so that one feature map is only responsible for objects at one particular scale. For example, in Fig. 5 the dog can only be detected in the 4x4 feature map (higher level) while the cat is just captured by the 8x8 feature map (lower level).
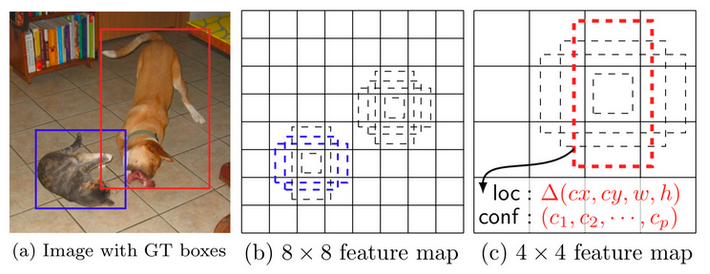
- Note: 可以看出,SSD和YOLO不同的一点是没有用objectness,而是就是classification和regression。所以这应该也是YOLO的一个特点,或者说灵魂。Kissrabbit也对此有过讨论。
The width, height and the center location of an anchor box are all normalized to be (0, 1). At a location (i,j) of the ℓ-th feature layer of size m×n, i=1,…,n,j=1,…,m, we have a unique linear scale proportional to the layer level and 5 different box aspect ratios (width-to-height ratios), in addition to a special scale (why we need this? the paper didn't explain. maybe just a heuristic trick) when the aspect ratio is 1. This gives us 6 anchor boxes in total per feature cell.

-
Note: 所以这里引起了我的一点思考,对之前心里的理解的一点拨乱反正。所以anchor们,就是理解为定在那个或者说每个最后的feature map上grids的,其尺寸,也是固定pixels的(或者说像这里SSD一样是这样根据每层来确定其相对该层的比例,但总得来说,在绝对大小上是差不多的),于是这样固定大小的anchors们对于其所在的feature map,就有大有小了(浅层小,深层大),对于深层来说于是cover到了更大的面积,或者从另一个角度理解,就是有更大的receptive field(其反推回去就是在原image上有着大的coverage)。那么心里还有几个疑问,就是做正负样本的时候具体这个anchor和prediction的IoU是怎么算的呢,是把prediction映回原image还是把原ground-truth映到对应的feature map呢,个人目前觉得是后者,毕竟那些loss function画图的时候(targets们,offset)都是一张grids上画的,按前面这个意思那就是在对应的feature map上,但是如果这样,不同尺度feature map上这样去算差距,岂不是不太公平?所以感觉又是前者。真的需要具体去看一下代码。而且感觉这也和Kissrabbit提到过的根据IoU分配时不同尺度的预测自然而然会去找到自己适合的ground-truth box的归属,所以更感觉是回到前者了。而且感觉这个问题和Faster R-CNN 那块搞proposals的targets需要找附近gt也是一个道理。另外第二个问题,同样的来由,那所谓通过在数据集上k-means得到anchors初始值,具体是怎么得的呢,如果是在原image,岂不是这个anchor box的尺寸在所有feature map上的感受物体的区域都比真正的物体大了,因为feature map都是降维了的,只有最初始的image是那么大。这个问题也需要去具体看一下代码。
-
Note: 看过了,看的是YOLOv3知乎Kissrabbit的代码。确实是在feature map上求的loss,自己的那个问题也是对的,所以其实在最后的loss计算时对于位置和尺寸的loss是有weight的!大的map给的weight小,这样平衡了各不同尺度的map本来就会有的差距。记得评论里也是有人提过。
另外,最重要的,还是注意anchor匹配机制,既然叫做anchor匹配,就是去匹配anchors。在training时在样本输入之前,也就是准备工作中就把我网络目标输出的那些targets准备好了(因为它们就是代表着,每个grid的每个anchor的5+C输出,也即是offsets们)。具体来说,gt和anchors们初始都是在image上,现在都投到对应的feature map上(具体实现中,gt往往是由一个0到1的比例表示的,反而是要乘对应的feature map的grids数量 / feature map尺寸,anchors就是一堆尺寸,就是除strides得到feature map上的anchor们,也就是尺寸们)。然后根据gt位置的floor,得到对其负责的grid位置,那么这个grid的三个anchors就是有可能负责检测它的candidates,然后通过机制做样本的分配,目前依据的是IoU,但也在知乎看到YOLOv5就改进成了某种长宽比之类的方法。如此就可以得到正负样本的分配,也就是正样本(们)IoU,负样本们因为objectness就是0所以objectness x IoU 直接是零(可以想象没有得到gt分配的grids们大家应该也都是负样本),然后regression是位置根据grids的偏移,尺寸基于该anchor的尺寸上scale,classification该class为1其他为0,大概如此。在inference得到predictions后,就可以把结果直接和targets做loss了。相当于输出prediction就是去逼近早已准备好的anchors得到的targets。
另外,在输出时还可以把这些offset结果根据anchors还原成box,再还原成image上的,和原始的label中的image上的框算IoU(但其实这个IoU在后面的loss中没用到),可能可以做一些操作。个人认为,就可以动态地把这个IoU作为当前predict出来的offsets所代表的prediction box们的objectness预测,而不是1或者0,这个在之前自己有讨论过。这也就相当于objectness的这个target在”动态地“根据输出的prediction生成。
总之,anchors在feature map上的每个pixel上,ground-truth投过来在这上面做文章,位置的回归基础就是grid(所以其实很早就可得到,before prediction),尺寸的回归基础是anchors,然后loss中有相对于map尺寸的weights。
-
Note: 自己目前其实还有一个问题,就是关于每个grid能够检测的objects数量。目前来讲,其所介绍的YOLO肯定是只能一个的,因为只有最大的IoU得到分配视为正样本。不过大概想一下,其实肯定是能设计个策略的,正如这里评论再次提到的,各自去找适合自己的这个grid里的anchor就可以,不过目前确实是没有的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号