『记录』BEVFusion和CenterPoint调试
『记录』BEVFusion和CenterPoint调试
数据准备
跳过数据准备部分,和别的一样。
推理特征
进入extract_feat
跳过forward和forward_train之类的一些传递,跳过本函数内首先进行的extract_img_feat和extract_pts_feat,和别的一样。看一下目前得到的东西:
得到了'img_feats',其是一个长度为5的list,各尺寸为[12, 256, 112, 200], [12, 256, 56, 100], [12, 256, 28, 50], [12, 256, 14, 25], [12, 256, 7, 13]. 显然,12即2的batch size乘6的camera个数(num_views),第一个tensor[12, 256, 112, 200]将会作为后续输入,即fpn的融合了各层特征的降采样最小的层
得到'pts_feats'为一个长度为1的list,尺寸为[2, 512, 180, 180]. 显然180是由54.0*2的范围除以0.075的voxel size得到的1440经过8倍降采样而来
经过LSS
首先获取一下img_metas里的lidar2img信息inverse一下来得到lss中需要用到的calibration. 得到rots [2, 6, 3, 3]和trans [2, 6, 3],分别是每个sample时每个camera到lidar的cam2lidar变换
进入LiftSplatShoot的forward.
准备好frustum grids(几何位置)
在初始化时类内部已经准备好了变量self.frustum [41, 112, 200, 3],其表示lss中的[D, H, W, 3],是一个类内不需要梯度的nn.Parameter,其实它正是lss的源头,即密集的相机视野内所定义的可能深度区间内的所有假设点云,或者说grids,或者甚至其实有点像anchors中心. 其在spatial上与即将现在传过来的image feature的尺寸保持一致,是在初始化时传入了图像原尺寸(900, 1600)和降采样倍数8所得的,在深度上遵循所指定的(4.0, 45.0, 1.0),表示深度的范围和生成步长。不过注意其中具体的值仍然是一些grid棋盘尺度下的值,也就是从(0, 0, 4.0)到(1599.0, 899.0, 44.0)这样的值(毕竟我们初始化的时候没有calibration信息),即x和y在像素单位下,深度z是正常的三维尺寸。所以其实在这一步正是要把它变成真正的点云们
于是,在本步处理的步骤大概为:1. 若前面进行过,inverse变换image augmentation 2. lidar2cam + intrinsics(即lidar2img)3. 若进行过,执行变换lidar augmenation. 值得注意的是,PEU版本的BEVFusion并未进行任何augmentation,且nuscenes的数据准备在'lidar2img'中已经将intrinsics融进去,所以在这里直接使用即可,而MIT版本的则设计了可能有图像或点云augmentation的处理,可以看到,其将image的aug作为lss原本的使用方法pos_rot和pos_trans传入,并另外设计了名为extra_rots和extra_trans来为了传入lidar的aug
结束后,得到准备好的frustum grids[2, 6, 41, 112, 200, 3],通过检查可以确认其中的坐标值范围和尺度是正常的
准备好frustum grid所有的特征
将图像特征传入CamEncode,即lss主要的lift操作,[12, 256, 112, 200]经过conv2d得到[12, 41 + 64, 112, 200],64是预设的这里想要的特征通道数,41同frustum grid的深度尺寸一致,表示每个深度的预测。取出深度预测部分softmax一下,然后broadcast加权了特征得到输出:[12, 1, 41, 112, 200] * [12, 64, 1, 112, 200]得到[12, 64, 41, 112, 200],于是frustum grid上每个点云位置都配备了一个特征向量。值得注意的是,来自同一个像素的ray上的不同depth的特征来源于同一个预测特征,由深度预测加权而得。
处理一下维度得到输出[2, 6, 41, 112, 200, 64],另外把depth [2, 6, 41, 112, 200]当时的预测也一块输出一下,用于后面对其计算loss
执行voxel pooling
(执行voxel pooling,一番操作之后)得到组织在voxel内的features [2, 64, 13, 180, 180],在x和y上同即将的lidar一致,均是54*2/0.075=1440/8倍降采样得到的180,在这里则是直接传入了grid参数为0.6(即0.075*8,在已经降采样的图上做划分相当于原来尺寸上的voxel变得大了一些)来做voxel的划分。在高度上是一个道理,为8/0.6=13. 然后,在高度上进行压缩,得到[2, 832, 180, 180],至此得到bev的特征图
注意这里做voxel pooling的一番操作,就是PointPillars思路 + 使用cumsum trick做sum这样的形式,在lss文章中有解释,记得看
We follow the pointpillars [18] architecture to convert the large point cloud output by the “lift” step. “Pillars” are voxels with infinite height. We assign every point to its nearest pillar and perform sum pooling to create a C × H × W tensor.
Just as OFT [29] uses integral images to speed up their pooling step, we apply an analagous technique to speed up sum pooling. Instead of padding each pillar then performing sum pooling, we avoid padding by using packing and leveraging a “cumsum trick” for sum pooling. This operation has an analytic gradient that can be calculated efficiently to speed up autograd as explained in subsection 4.2.
推理一下bev features
首先用一个conv2d降一下维回到初始的64维:[2, 64, 180, 180],然后进入bev encoder,先用resnet18的层进行encode到[2, 256, 23, 23],然后upsample interpolate四倍到[2, 256, 90, 90],和前面的特征cat之后继续encode到[2, 256, 90, 90],然后再upsample两倍再encode回来,最终输出[2, 256, 180, 180]
融合图像和lidar的bev特征
首先把两个bev特征直接cat,得到[2, 512 + 256, 180, 180],推理回lidar通道数的特征 [2, 512, 180, 180]. 至此就得到了特征图输出,下面就可以进入head了。
经过head
经过head推理
进入CenterHead的forward,对传来的feats列表进行multi_apply的forward_single(应该是适用于多尺度特征图的情况,在这里,feats长度只是1). 经过一个shared conv block,得到[2, 64, 180, 180],也就是执行下一步推理不同task的分head之前先用这个降一下维
本次是是用了CenterHead搭配包装DCNSeparateHead的检测头,为了清晰,把完整config放在这里:
点击查看代码
pts_bbox_head=dict(
type='CenterHead',
in_channels=512,
tasks=[
dict(num_class=1, class_names=['car']),
dict(num_class=2, class_names=['truck', 'construction_vehicle']),
dict(num_class=2, class_names=['bus', 'trailer']),
dict(num_class=1, class_names=['barrier']),
dict(num_class=2, class_names=['motorcycle', 'bicycle']),
dict(num_class=2, class_names=['pedestrian', 'traffic_cone'])
],
common_heads=dict(
reg=(2, 2), height=(1, 2), dim=(3, 2), rot=(2, 2), vel=(2, 2)),
share_conv_channel=64,
bbox_coder=dict(
type='CenterPointBBoxCoder',
post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
max_num=500,
score_threshold=0.1,
out_size_factor=8,
voxel_size=[0.075, 0.075],
code_size=9,
pc_range=[-54, -54]),
separate_head=dict(
type='DCNSeparateHead',
init_bias=-2.19,
final_kernel=3,
dcn_config=dict(
type='DCN',
in_channels=64,
out_channels=64,
kernel_size=3,
padding=1,
groups=4)),
loss_cls=dict(type='GaussianFocalLoss', reduction='mean'),
loss_bbox=dict(type='L1Loss', reduction='mean', loss_weight=0.25),
norm_bbox=True),
其主要是这样的结构:
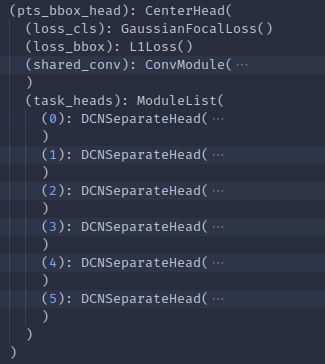
真正的head们在这里也就放在了DCNSeparateHead中,DCN其实就是加了两个DeformConv2dPack层:
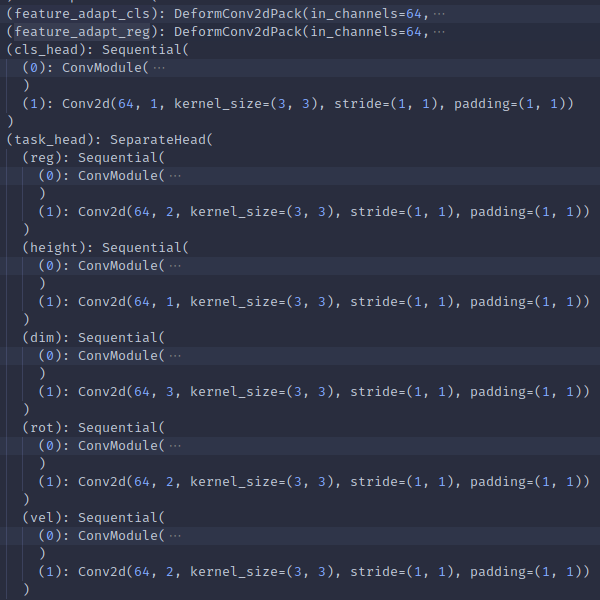
可以看到,tasks是很重要的一个参数,其把10个类分成了6组,那么1. 首先我们就会有6个separate head,然后2. 在每个separate head内再有各目标的head,它们的预测功能和输出维度分别为cls: sep head内负责类别数/reg: 2/height: 1/dim: 3/rot: 2/vel: 2). 这些每个像叶子一样的小head都是先一个conv2d稍微推理一下,然后归到输出维度上。所以总得来说,是有6x6=36个小head的
而这里用到的DCNSeperateHead,就是输到叶子前中间又增了一步把输入分别推理成给1个cls头和所有5个回归的头所输的两个不同特征,使用DeformConv2dPack,依然是得到[2, 4, 180, 180]和[2, 4, 180, 180]
然后输cls,得到[2, sep head内负责类别数, 180, 180]. 输回归的各head(它们又被组织到了一个SeperateHead类,显然,如果没用DCN分化cls和回归的各位,连上cls head的所有都是在一个SeperateHead里),尺寸不言而喻。然后得到存储6个输出的字典:
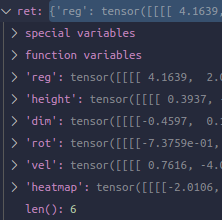
上面这是对一个sep head的,全部完成就得到了一个长度为6的包含每个head输出字典的列表。
制作targets + 计算loss
制作targets
第一步自然还是根据gt值们制作targets. 阅读了代码后,简要叙述一下思路。首先也是multi_apply到get_targets_single,正式进行。先把gt值们按照我们tasks的设定分散开来组织好,然后遍历每个task,遍历每个该task内的object,首先
- 制作heatmap,根据长宽真值转换到其在特征图的尺度(先除voxel size再除降采样倍数),根据该信息计算画heatmap该热点处的gaussian radius,根据位置真值转换到特征图上位置(offset到角落原点,除voxel size再除降采样倍数,取int值)。然后把该热点附近处的位置画好gaussian
- 制作回归target,组织方式是放在所定义的最多可能的目标数所容纳的矩阵内,所以聚在前面小部分的会置上我们真正的objects,mask表示是否有真正object的boolean. ind表示object所在的特征图上flatten后的索引值(以此存储了object位置),回归target计算为:
ind[new_idx] = y * feature_map_size[0] + x
if self.norm_bbox:
box_dim = box_dim.log()
anno_box[new_idx] = torch.cat([
center - torch.tensor([x, y], device=device),
z.unsqueeze(0), box_dim,
torch.sin(rot).unsqueeze(0),
torch.cos(rot).unsqueeze(0),
vx.unsqueeze(0),
vy.unsqueeze(0)
])
可以看到,位置回归量是真正值到转int后该grid位置的offset,dim回归量是其log值,rot回归量是其sin和cos
于是最终得到值,都是长度为6的list,然后每个元素分别是heatmaps [2, sep head内负责类别数, 180, 180],anno_boxes [2, 500, 10],inds [2, 500],masks [2, 500]
其实这样看来,这种anchor box free形式的方法反而更加简洁,因为哪个grid作为正样本就直接由object位置所直接确定了,由于regression只计算于正样本,其实只要我们能管理好classification这件事就万事大吉了,而很明显这确实需要一些设计,因为一下就能想到正负样本数量差距会很大。比如在这里,centerpoint/centernet的思路就是heatmap,然后之前有印象FCOS就是所有object box范围内都是正样本,都去回归到边框的距离,另外还有印象为YOLOv1的objectness预测,以及focal loss,都是与这点相关的。
计算loss
遍历tasks,
- 计算heatmap loss,对heatmap prediction做clip sigmoid,然后输入GaussianFocalLoss计算即可
- 计算回归的loss,首先把那5个分散的prediction输出组织一下成为[2, 10, 180, 180],然后继续组织为[2, 32400, 10],于是即可使用该pred和准备好多ind通过gather()索得了这一次有真值object位置处的的当前网络对它们的预测,当然由于inds是一个以zeros初始化的容器,还会索出来一大堆重复的原点位置的预测在后面,很明显,我们有mask所以完全ok. 然后用mask乘上预先定义的code weights作为权重,就结合了筛选有正样本的grid位置,并对各回归量之间加权。于是,一起和预测和真值放进L1Loss计算,得到了结果
值得注意的是,我们知道在mmdet3d中整个模型的config除了各层外后面还有两个train_cfg和test_cfg,在这里面往往就会分别定义训练时的target assigner部分的信息和测试时后处理的信息,即score threshold和nms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号