『记录』Transfusion调试
调试记录:Transfusion
"args": [
"configs/transfusion_nusc_pillar_LC.py",
"--gpu-ids=2",
]
数据部分:关于Nuscenes
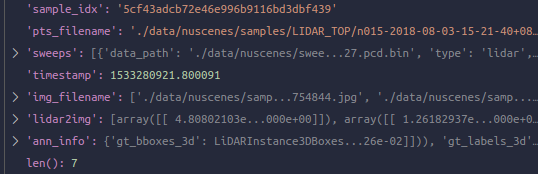
在get_data_info之后:
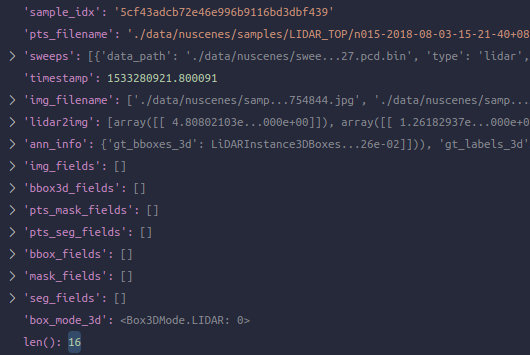
在pre_pipeline之后:
在pipeline中,在这里自己仅对之前调试MVX-Net时其使用kitti时没有用到过的loading模块调试
- LoadPointsFromMultiSweeps: 'points'得到更新为 [381984, 5]. 在这之前其还是一个单帧为 [34720, 5]
- LoadMultiViewImageFromFiles: 关于image的fields得到更新,在这里'img'是一个长度为6的list,每个image尺寸为[900, 1600, 3]
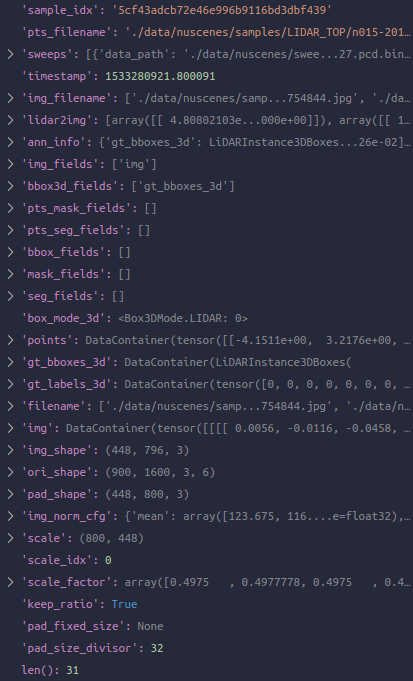
在通过pipeline大部分后,Collect3D之前:
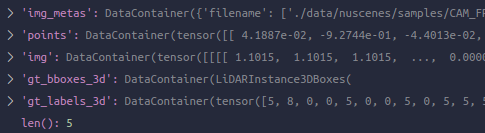
Collect3D后得到新的data dict:
推理部分:Base3DDetector的forward
输入进来的数据(kwargs)为:
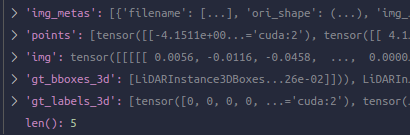
其中,'img'为[2, 6, 3, 448, 800]的tensor,'points'为长度为2的list,含两个tensor[338334, 5]和[370131, 5],'gt_bboxes_3d'为长度为2的list,含两个LiDARInstance3DBoxes,'gt_labels_3d'为长度为2的list,含两个tensor [14], [38],'img_metas'为长度为2的list,含两个dict保存收集的额外信息,以第一个为例:
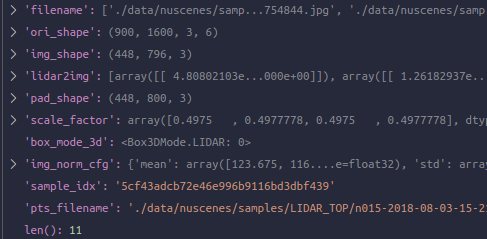
进入TransFusionDetector的forward_train
开始真正进入当前model类型TransFusionDetector + 训练模式的推理
通过head前的部分:常规的extract_img_feat + extract_pts_feat
通过extract_img_feat将图像经过了img_backbone和img_neck. 图像输入'img'的尺寸为[2, 6, 3, 448, 800],得到了'img_feats',其是一个长度为5的list,表示FPN输出的各尺度的特征图。在这里是ResNet50 + FPN,得到的各尺寸为[12, 256, 112, 200], [12, 256, 56, 100], [12, 256, 28, 50], [12, 256, 14, 25], [12, 256, 7, 13]. 显然,12即2的batch size乘6的camera个数(num_views)
然后进入extract_pts_feat. 依然值得注意的是,extract_pts_feat虽然名字看起来是只做点云特征的提取,其参数其实是带了刚刚得到的img_feats的,这个函数也可以承担着融合的过程,就像之前调试MVX-Net的时候,在其DynamicVFE的config就是传入了PointFusion进行了融合。而在这里,没有在前面融合,所以其实传进来的img_feats和img_metas是unused的
进入extract_pts_feat. 点云的'pts'是一个长度为2的list,包含[338334, 5]和[370131, 5]
- 通过voxelize(pts_voxel_layer):得到voxels [49681, 20, 5], num_points [49681,], coors [49681, 4]
- 通过PillarFeatureNet:得到voxel_features [49681, 64]
- 通过PointPillarsScatter:得到x [2, 64, 512, 512]
- 通过SECOND:得到x为一个长度为3的list,表示SECOND-FPN的降采样部分的三个尺度的特征图[2, 64, 256, 256],[2, 128, 128, 128],[2, 256, 64, 64]
- 通过SECONDFPN:得到x为一个长度为1的list,尺寸为[2, 384, 128, 128]
回到TransFusionDetector的forward_train,准备开始head和得到loss等诸多重磅事务
创建losses字典,准备存储所有存在的loss. 根据刚刚返回的pts_feats和img_feats是否存在随之调用forward_pts_train和forward_img_train,它们代表着head的forward和最终loss的计算,返回就是一个loss字典,得到后更新到我们这里的losses
通过点云的head并计算loss:forward_pts_train
包含两部分的进行:self.pts_bbox_head通过head的推理部分,以及通过同一个head所包含的self.pts_bbox_head.loss通过刚刚的输出以及传过来的ground truth计算loss
通过TransFusionHead的forward(未完成)
进入了TransFusionHead的forward,其采用mmdet.core的multi_apply对传入的组织为list的多尺度features们分别调用类内的另一个forward_single,真正进行forward. 于是进入TransFusionHead的forward_single
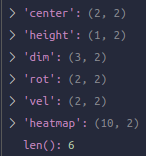
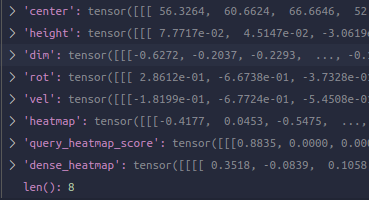
通过TransFusionHead的loss函数
主要分为两部分,第一个依然是target assigner,在这里也就是要使用TransFusionHead的get_targets,其中依然是multi_apply了自己的get_targets_single,在那里执行了真正核心的部分,其中包括把现在当前的预测用bbox coder给decode,使用train_cfg中的HungarianAssigner3D进行assign,如果有的话使用train_cfg中的sampler进行sampling,以及最终制作target,包括用于分类的labels,回归的bbox_targets,标志该位置是否参与分类和回归的权重label_weights和bbox_weights(关于正负样本),iou的目标ious,正样本数量,平均的iou值,以及我们特殊的heatmap的目标。在这里显然还有很多内容可以去深下去看源码,不过精力有限,自认为通过之前理论的学习以及看openpcdet时pointpillars那里相对基础的target assigner已经可以知道发生了什么,在这里直接看一下get_targets输出制作好的target情况
- labels:[2, 200],保存类别编号,以这里为例,很多的值都是10
- label_weights:[2, 200],在这里我能看到的值都是1,因为正负样本都有分类的loss
- bbox_targets:[2, 200, 10],在这里大部分都是0,存在gt的部分会出现值。10是因为box coder的code size就是10,其包含了所有的center, height, rot, dim, vel
- bbox_weights:[2, 200, 10],大部分0,因为只有正样本有regression的loss. 出现的那个10-d vector都是1
- ious:[2, 200],大部分为0,出现了一个0.0222
- num_pos:一个值52
- matched_ious:一个值0.00114
- heatmap:[2, 10, 128, 128],大部分都是0
然后开始第二部分计算loss,用这些targets和前面算好的preds_dict的各项
- 计算heatmap的loss:GaussianFocalLoss
- 计算classification的loss:FocalLoss
- 计算box regression的loss:L1Loss
- 计算iou的loss:CrossEntropyLoss,但是注意这里其实并没有使用,都被comment掉了
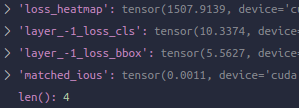
最终得到的losses字典为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号