『论文』Transfusion
『论文』Transfusion
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
总结下来,整体架构就是以DETR的decoder这样的范式做目标检测,用两个decoder,第一个的kv是lidar bev fmp,然后接的第二个的kv是image fmp,另外所包含一些设计,主要有:
- (object) query的初始化设计为Input-dependent: 1. lidar bev fmp上预测类别heatmap取local maximum + top-N,结合2. image guidance: lidar bev fmp作为q与image features collapse作为kv的attention结果预测heatmap的两个的average. 更有针对性的初始化使得比起random initialized不需要更多的decoder layer
- (object) query的初始化category-aware: 加入category embedding. 为后面提供了一点side infomation
- 第二个decoder处的SMCA:第二个decoder的attention真正与image做fusion,使用与CenterNet类似的circular gaussian mask对以每个query位置的image plane投影位置为中心做weight. 使得query不必attend to visual regions unrelated to the bounding box to be predicted
1 Introduction
Existing LiDAR-camera fusion methods roughly fall into three categories: result-level, proposal-level, and point- level
- Result-level: F-PointNet, RoarNet. Use off-the-shelf 2D detectors to seed 3D proposals, followed by a PointNet
- Proposal-level: MV3D, AVOD. Perform fusion at the region proposal level by applying RoIPool in each modality for shared proposals
These coarse-grained fusion methods show unsatisfactory results since rectangular regions of interest (RoI) usually contain lots of background noise.
- Point-level: PointPainting, FusionPainting (cat with segmentation scores); EPNet, MVX-Net, PointAugmenting, MoCa (cat with CNN features); PI-RCNN, 3D-CVF: first project a point cloud onto the bird’s eye view (BEV) plane and then fuse the image features with the BEV pixels.
Point-level fusion methods suffer from two major problems:
- Performance degrades seriously with low-quality image features
- Finding the hard association between sparse LiDAR points and dense image pixels not only wastes many image features with rich semantic information, but also heavily relies on high-quality calibration between two sensors, which is usually hard to acquire due to the inherent spatial-temporal misalignment
3 Methodology
3.1 Preliminary: Transformer for 2D Detection
DETR, Deformable DETR.
In our work, each object query contains a query position providing the localization of the object and a query feature encoding instance information, such as the box’s size, orientation, etc.
3.2 Query Initialization
Input-dependent.
- 在之前的工作中,object query往往是random initialized的,需要多层decoder layer来学到这个慢慢移动到真正的gt位置。最近有工作证明更好地initalization可以让单layer就可以达到之前6-layer的效果,所以本文设计了input-dependent的策略对query初始化
- 方法:在lidar的bev fmp (X, Y, d)上,预测一个heat map (X, Y, K),K表示类别数量。在heatmap上结合local maximum的策略选取top-N的candidates作为initial object queries
Category-aware.
- 对object queries都epuip (在query的features上sum)上一个category embedding,其来自于该candidate的category的one-hot经过一个linear projection得到的和features同样d维的vector
3.3 Transformer Decoder and FFN
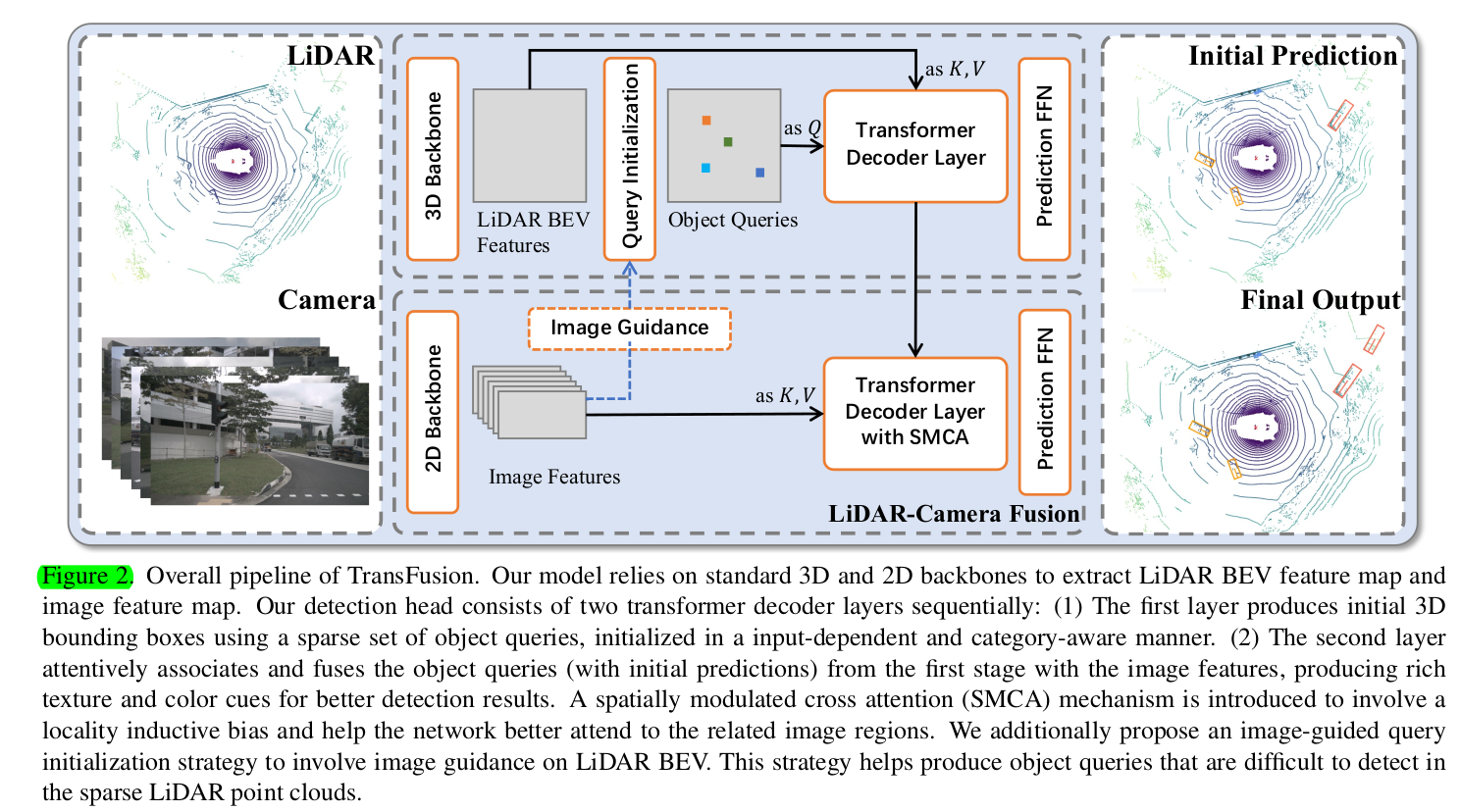
The decoder layer follows the design of DETR
- The cross attention between object queries and the feature maps (either from point clouds or images) aggregates relevant context onto the object candidates
- The self attention between object queries reasons pairwise relations between different object candidates
The FFN:

- We adopt the auxiliary decoding mechanism, which adds FFN and supervision after each decoder layer.
Hence, we can have initial bounding box predictions from the first decoder layer. We will leverage such initial predictions in the LiDAR-camera fusion module next.
3.4. LiDAR-Camera Fusion
Image Feature Fetching.
- 虽然在之前利用point-level fusion的工作挺不错,但是performance仍然会限制于lidar的sparsity,只能在hard-association的操作下对对应的image pixels来fetch很少一部分features,所以我们与image的fusion是利用第二个decoder做cross-attention,采取一种sparse-to-dense的manner
SMCA for Image Feature Fusion.
- We design a spatially modulated cross attention (SMCA) module, which weighs the cross attention by a 2D circular Gaussian mask around the projected 2D center of each query.
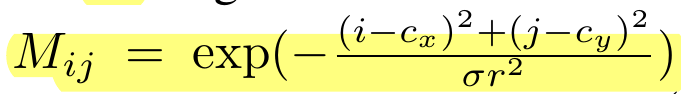
我对这里还是不太清楚
3.5 Label Assignment and Losses
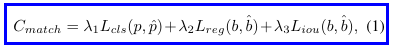
另外有heatmap预测时同CenterPoint的penalty-reduced focal loss
3.6 Image-Guided Query Initialization
前面已经有用lidar bev feature map通过预测heatmap的方式进行query初始化的方案了,这里进一步想用image features升级这种初始化。
We propose an image-guided query initialization strategy, which selects object queries leveraging both the LiDAR and camera information.
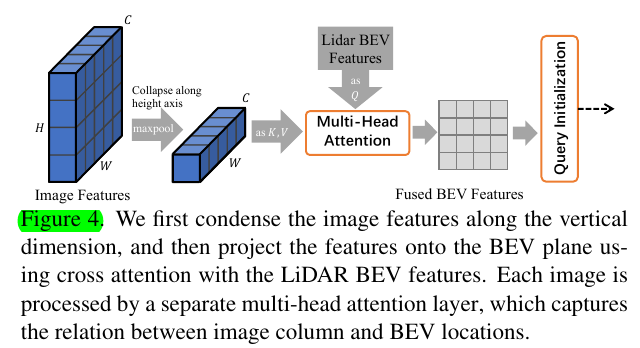
方式就是又用了个attention把lidar bev fmp作为query,image的信息作为kv的sequence,而image的信息则是由image features直接做了一个collapse
- Usually there is at most one object along each image column. 所以直接高度上
然后用这个结果又预测了一个heatmap,和前面那个策略的结果做average得到最终结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号