数据库原理 - 序列4 - 事务是如何实现的? - Redo Log解析(续)
2019-04-12 14:39 travis2046 阅读(434) 评论(0) 收藏 举报> 本文节选自《软件架构设计:大型网站技术架构与业务架构融合之道》第6.4章节。 作者微信公众号:
> 架构之道与术。进入后,可以加入书友群,与作者和其他读者进行深入讨论。也可以在京东、天猫上购买纸质书。
## 6.5.5 Redo Log Block结构
Log Block还需要有Check sum的字段,另外还有一些头部字段。事务可大可小,可能一个Block存不下产生的日志数据,也可能一个Block能存下多个事务的数据。所以在Block里面,得有字段记录这种偏移量。
图6-9展示了一个Redo Log Block的详细结构,头部有12字节,尾部Check sum有4个字节,所以实际一个Block能存的日志数据只有496字节。
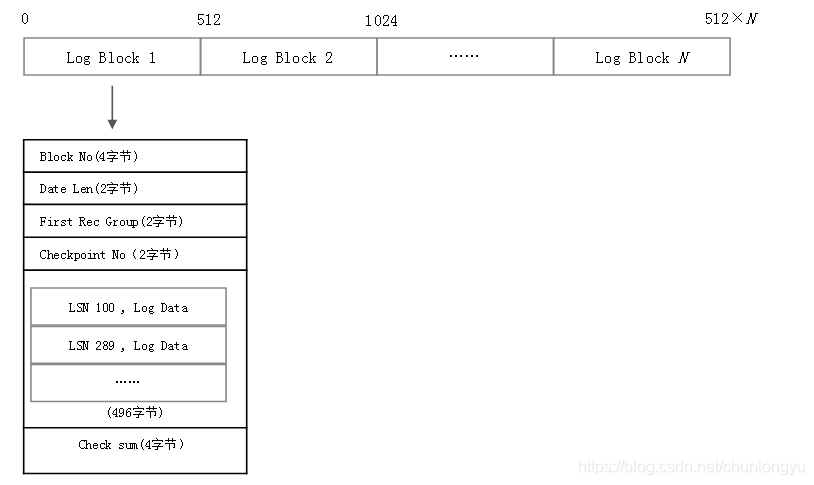
图6-9 Redo Log Block详细结构
头部4个字段的含义分别如下:
Block No:每个Block的唯一编号,可以由LSN换算得到。
Date Len:该Block中实际日志数据的大小,可能496字节没有存满。
First Rec Group:该Block中第一条日志的起始位置,可能因为上一条日志很大,上一个Block没有存下,日志的部分数据到了当前的Block。如果First Rec Group = Data Len,则说明上一条日志太大,大到横跨了上一个Block、当前Block、下一个Block,当前Block中没有新日志。
Checkpoint No:当前Block进行Check point时对应的LSN(下文会专门讲Checkpoint)。
## 6.5.6 事务、LSN与Log Block的关系
知道了Redo Log的结构,下面从一个事务的提交开始分析,看事务和对应的Redo Log之间的关联关系。假设有一个事务,伪代码如下:
start transaction
update 表1某行记录
delete 表1某行记录
insert 表2某行记录
commit
其产生的日志,如图6-10所示。应用层所说的事务都是“逻辑事务”,具体到底层实现,是“物理事务”,也叫作Mini Transaction(Mtr)。在逻辑层面,事务是三条SQL语句,涉及两张表;在物理层面,可能是修改了两个Page(当然也可能是四个Page,五个Page……),每个Page的修改对应一个Mtr。每个Mtr产生一部分日志,生成一个LSN。
这个“逻辑事务”产生了两段日志和两个LSN。分别存储到Redo Log的Block里,这两段日志可能是连续的,也可能是不连续的(中间插入的有其他事务的日志)。所以,在实际磁盘上面,一个逻辑事务对应的日志不是连续的,但一个物理事务(Mtr)对应的日志一定是连续的(即使横跨多个Block)。
图6-11展示了两个逻辑事务,其对应的Redo Log在磁盘上的排列示意图。可以看到,LSN是单调递增的,但是两个事务对应的日志是交叉排列的。
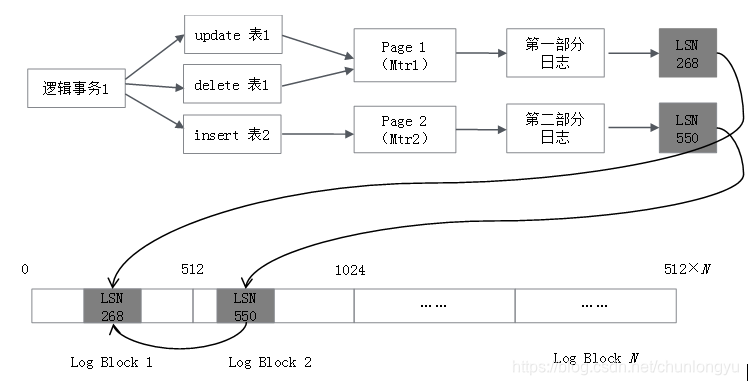
图6-10 事务与产生的Redo Log对应关系
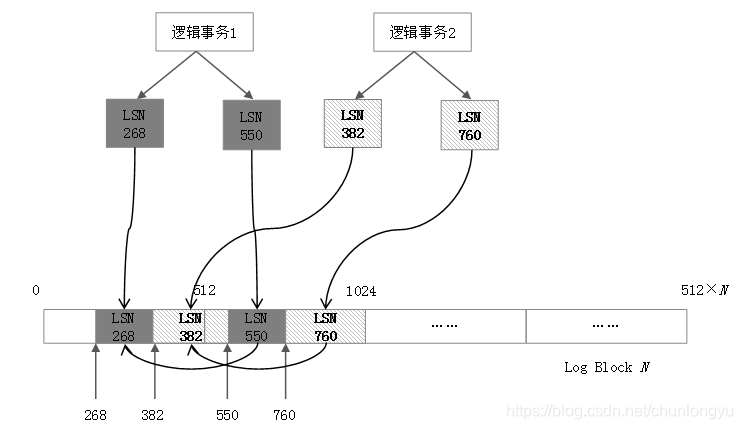
图6-11 两个逻辑事务的Redo Log在磁盘上排列示意图
同一个事务的多条LSN日志也会通过链表串联,最终数据结构类似表6-9。其中,TxID是InnoDB为每个事务分配的一个唯一的ID,是一个单调递增的整数。
表6-9 Redo Log与LSN和事务的关系

## 6.5.7 事务Rollback与崩溃恢复(ARIES算法)
**1.未提交事务的日志也在Redo Log中**
通过上面的分析,可以看到不同事务的日志在Redo Log中是交叉存在的,这意味着未提交的事务也在Redo Log中!因为日志是交叉存在的,没有办法把已提交事务的日志和未提交事务的日志分开,或者说前者刷到磁盘的Redo Log上面,后者不刷。比如图6-11的场景,逻辑事务1提交了,要把逻辑事务1的Redo Log刷到磁盘上,但中间夹杂的有逻辑事务2的部分Redo Log,逻辑事务2此时还没有提交,但其日志会被“连带”地刷到磁盘上。
所以这是ARIES算法的一个关键点,不管事务有没有提交,其日志都会被记录到Redo Log上。当崩溃后再恢复的时候,会把Redo Log全部重放一遍,提交的事务和未提交的事务,都被重放了,从而让数据库“原封不动”地回到宕机之前的状态,这叫Repeating History。
重放完成后,再把宕机之前未完成的事务找出来。这就有个问题,怎么把宕机之前未完成的事务全部找出来?这点讲Checkpoint时会详细介绍。
把未完成的事务找出来后,逐一利用Undo Log回滚。
**2.Rollback转化为Commit**
回滚是把未提交事务的Redo Log删了吗?显然不是。在这里用了一个巧妙的转化方法,把回滚转化成为提交。
如图6-12所示,客户端提交了Rollback,数据库并没有更改之前的数据,而是以相反的方向生成了三个新的SQL语句,然后Commit,所以是逻辑层面上的回滚,而不是物理层面的回滚。

图6-12 一个Rollback事务被转换为Commit事务示意图
同样,如果宕机时一个事务执行了一半,在重启、回滚的时候,也并不是删除之前的部分,而是以相反的操作把这个事务“补齐”,然后Commit,如图6-13所示。

图6-13 宕机未完成的事务被转换成Commit事务
这样一来,事务的回滚就变得简单了,不需要改之前的数据,也不需要改Redo Log。相当于没有了回滚,全部都是Commit。对于Redo Log来说,就是不断地append。这种逆向操作的SQL语句对应到Redo Log里面,叫作Compensation Log Record(CLR),会和正常操作的SQL的Log区分开。
**3.ARIES恢复算法**
如图6-14所示,有T0~T5共6个事务,每个事务所在的线段代表了在Redo Log中的起始和终止位置。发生宕机时,T0、T1、T2已经完成,T3、T4、T5还在进行中,所以回滚的时候,要回滚T3、T4、T5。
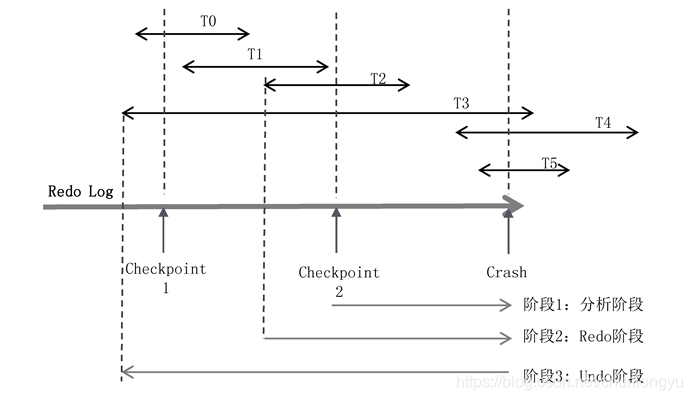
图6-14 ARIES算法示意图
ARIES算法分为三个阶段:
**(1)阶段1:分析阶段**
分析阶段,要解决两个核心问题。
第一,确定哪些数据页是脏页,为阶段2的Redo做准备。发生宕机时,虽然T0、T1、T2已经提交了,但只是Redo Log在磁盘上,其对应的数据Page是否已经刷到磁盘上不得而知。如何找出从Checkpoint到Crash之前,所有未刷盘的Page呢?
第二,确定哪些事务未提交,为阶段3的Undo做准备。未提交事务的日志也写入了Redo Log。对应到此图,就是T3、T4、T5的部分日志也在Redo Log中。如何判断出T3、T4、T5未提交,然后对其回滚呢?
这就要谈到ARIES的Checkpoint机制。Checkpoint是每隔一段时间对内存中的数据拍一个“快照”,或者说把内存中的数据“一次性”地刷到磁盘上去。但实际上这做不到!因为在把内存中所有的脏页往磁盘上刷的时候,数据库还在不断地接受客户端的请求,这些脏页一直在更新。除非把系统阻塞住,不再接受前端的请求,这时Redo Log也不再增长,然后一次性把所有的脏页刷到磁盘中,叫作Sharp Checkpoint。
Sharp Checkpoint的应用场景很狭窄,因为系统不可能停下来,所以用的更多的是Fuzzy Checkpoint,具体怎么做呢?
在内存中,维护了两个关键的表:活跃事务表(表6-10)和脏页表(表6-11)。
活跃事务表是当前所有未提交事务的集合,每个事务维护了一个关键变量lastLSN,是该事务产生的日志中最后一条日志的LSN。
表6-10 活跃事务表

脏页表是当前所有未刷到磁盘上的Page的集合(包括了已提交的事务和未提交的事务),recoveryLSN是导致该Page为脏页的最早的LSN。比如一个Page本来是clean的(内存和磁盘上数据一致),然后事务1修改了它,对应的LSN是LSN1;之后事务2、事务3又修改了它,对应的LSN分别是LSN2、LSN3,这里recoveryLSN取的就是LSN1。
表6-11 脏页表

所谓的Fuzzy Checkpoint,就是对这两个关键表做了一个Checkpoint,而不是对数据本身做Checkpoint。这点非常巧妙!因为Page本身很多、数据量大,但这两个表记录的全是ID,数据量很小,很容易备份。
所以,每一次Fuzzy Checkpoint,就把两个表的数据生成一个快照,形成一条Checkpoint日志,记入Redo Log。
基于这两个关键表,可以求取两个问题:
问题(1):求取Crash的时候,未提交事务的集合。
以图6-14为例,在最近的一次Checkpoint 2时候,未提交事务集合是{T2,T3},此时还没有T4、T5。从此处开始,遍历Redo Log到末尾。
在遍历的过程中,首先遇到了T2的结束标识,把T2从集合中移除,剩下{T3};
之后遇到了事务T4的开始标识,把T4加入集合,集合变为{T3,T4};
之后遇到了事务T5的开始标识,把T5加入集合,集合变为{T3,T4,T5}。
最终直到末尾,没有遇到{T3,T4,T5}的结束标识,所以未提交事务是{T3,T4,T5}。
图6-15展示了事务的开始标识、结束标识以及Checkpoint在Redo Log中的排列位置。其中的S表示Start transaction,事务开始的日志记录;C表示Commit,事务结束的日志记录。每隔一段时间,做一次Checkpoint,会插入一条Checkpoint日志。Checkpoint日志记录了Checkpoint时所对应的活跃事务的列表和脏页列表(脏页列表在图中未展示)。
问题(2):求取Crash的时候,所有未刷盘的脏页集合。
假设在Checkpoint2的时候,脏页的集合是{P1,P2}。从Checkpoint开始,一直遍历到Redo Log末尾,一旦遇到Redo Log操作的是新的Page,就把它加入脏页集合,最终结果可能是{P1,P2,P3,P4}。
这里有个关键点:从Checkpoint2到Crash,这个集合会只增不减。可能P1、P2在Checkpoint之后已经不是脏页了,但把它认为是脏页也没关系,因为Redo Log是幂等的。
图6-15 事务在Redo Log上排列示意图
阶段2:进行Redo
假设最后求出来的脏页集合是{P1,P2,P3,P4,P5}。在这个集合中,可能都是真的脏页,也可能是已经刷盘了。取集合中所有脏页的recoveryLSN的最小值,得到firstLSN。从firstLSN遍历Redo Log到末尾,把每条Redo Log对应的Page全部重刷一次磁盘。
关键是如何做幂等?磁盘上的每个Page有一个关键字段——pageLSN。这个LSN记录的是这个Page刷盘时最后一次修改它的日志对应的LSN。如果重放日志的时候,日志的LSN <= pageLSN,则不修改日志对应的Page,略过此条日志。
如图6-16所示,Page1被多个事务先后修改了三次,在Redo Log的时间线上,分别对应的日志的LSN为600、900、1000。当前在内存中,Page1的pageLSN = 1000(最新的值),因为还没来得及刷盘,所以磁盘中Page1的pageLSN = 900(上一次的值)。现在,宕机重启,从LSN=600的地方开始重放,从磁盘上读出来pageLSN = 900,所以前两条日志会直接过滤掉,只有LSN = 1000的这条日志对应的修改操作,会被作用到Page1中。
图6-16 pageLSN实现Redo Log幂等示意图
这点与TCP在接收端对数据包的判重有异曲同工之妙!在TCP中,是对发送的数据包从小到大编号(seq number),这里是对所有日志从小到大编号(LSN),接收的一方发现收到的日志编号比之前的还要小,就说明不用重做了。
有了这种判重机制,我们就实现了Redo Log重放时的幂等。从而可以从firstLSN开始,将所有日志全部重放一遍,这里面包含了已提交事务和未提交事务的日志,也包含对应的脏页或者干净的页。
Redo完成后,就保证了所有的脏页都成功地写入到了磁盘,干净页也可能重新写入了一次。并且未提交事务T3、T4、T5对应的Page数据也写入了磁盘。接下来,就是要对T3、T4、T5回滚。
阶段3:进行Undo
在阶段1,我们已经找出了未提交事务集合{T3,T4,T5}。从最后一条日志逆向遍历,因为每条日志都有一个prevLSN字段,所以可以沿着T3、T4、T5各自的日志链一直回溯,最终直到T3的第一条日志。
所谓的Undo,是指每遇到一条属于T3、T4、T5的Log,就生成一条逆向的SQL语句来执行,其执行对应的Redo Log是Compensation Log Record(CLR),会在Redo Log尾部继续追加。所以对于Redo Log来说,其实不存在所谓的“回滚”,全部是正向的Commit,日志只会追加,不会执行“物理截断”之类的操作。
要生成逆向的SQL语句,需要记录对应的历史版本数据,这点将在分析Undo Log的时候详细解释。
这里要注意的是:Redo的起点位置和Undo的起点位置并没有必然的先后关系,图中画的是Undo的起点位置小于Redo的起点位置,但实际也可以反过来。以为Redo对应的是所有脏页的最小LSN,Undo对应的是所有未提交事务的起始LSN,两者不是同一个维度的概念。
在进行Undo操作的时候,还可能会遇到一个问题,回滚到一半,宕机,重启,再回滚,要进行“回滚的回滚”。
如图6-17所示,假设要回滚一个未提交的事务T,其有三条日志LSN分别为600、900、1000。第一次宕机重启,首先对LSN=1000进行回滚,生成对应的LSN=1200的日志,这条日志里会有一个字段叫作UndoNxtLSN,记录的是其对应的被回滚的日志的前一条日志,即UndoNxtLSN = 900。这样当再一次宕机重启时,遇到LSN=1200的CLR,首先会忽略这条日志;然后看到UndoNxtLSN = 900,会定位到LSN=900的日志,为其生成对应的CLR日志LSN=1600;然后继续回滚,LSN=1700的日志,回滚的是LSN=600。
这样,不管出现几次宕机,重启后最终都能保证回滚日志和之前的日志一一对应,不会出现“回滚嵌套”问题。
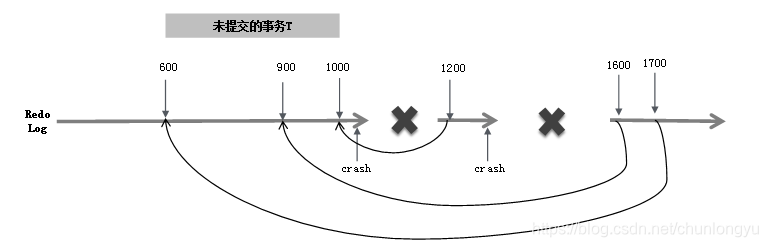
图6-17 回滚过程中出现宕机后再次重启回滚
到此为止,已经对事务的A(原子性)和D(持久性)有了一个全面的理解,接下来将讨论I的实现。在此先对Redo Log做一个总结:
(1) 一个事务对应多条Redo Log,事务的Redo Log不是连续存储的。
(2) Redo Log不保证事务的原子性,而是保证了持久性。无论提交的,还是未提交事务的日志,都会进入Redo Log。从而使得Redo Log回放完毕,数据库就恢复到宕机之前的状态,称为Repeating History。
(3) 同时,把未提交的事务挑出来并回滚。回滚通过Checkpoint记录的“活跃事务表”+ 每个事务日志中的开始/结束标记 + Undo Log 来实现。
(4) Redo Log具有幂等性,通过每个Page里面的pageLSN实现。
(5) 无论是提交的、还是未提交的事务,其对应的Page数据都可能被刷到了磁盘中。未提交的事务对应的Page数据,在宕机重启后会回滚。
(6) 事务不存在“物理回滚”,所有的回滚操作都被转化成了Commit。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号